
制造资源本体的语义相似度计算方法研究
2016-10-17 02:19罗俊丽
现代计算机 2016年22期
罗俊丽
(许昌学院信息工程学院,许昌 461000)
制造资源本体的语义相似度计算方法研究
罗俊丽
(许昌学院信息工程学院,许昌461000)
0 引言
制造行业市场竞争日趋激烈,市场不断细化,企业需要进一步深化合作和资源共享,提高部门之间、企业之间、地区之间制造资源的共享。而制造资源本身呈现异构性、多样性,分布性、海量性等特点,这给企业在检索和匹配制造资源时带来困难。本体是一种共享概念的形式化的清晰的规范描述,它使用概念及概念间的关系来表示信息,使用本体来描述统一制造资源可以帮助达到制造资源共享,具体过程是将制造资源封装成本体,然后计算它们之间的语义相似度,从而完成制造资源的匹配,其中本体相似度计算是制造资源检索和匹配的中的重要环节[1]。本文主要研究制造资源概念的语义相似度计算方法。
1 本体
目前被学者广泛接受的本体定义是Studer的“本体是共享概念模型的明确的形式化说明”,此定义包括下面几层含义[2]:(1)共享:本体不是面向整体,其是共同认可的概念,是公认的知识的集合。(2)明确:本体中明确定义了使用的概念和概念的约束。(3)概念化:本体中的概念模型是客观世界抽象出来的,其与具体环境没有关系。(4)形式化:本体是计算机方便处理的。
2 常用的语义相似度计算方法
概念相似度指的是本体在语义上的相似程度,目前常用的语义相似度计算方法有:基于属性的计算方法,基于信息内容的计算方法,基于距离的方法。用S(ci,cj)表示两个本体概念的相似度,其需要满足以下几个原则[4]:(1)相似度是一个取值范围在[0,1]间的实数,数值越大表示相似度越大,反之亦然。相似度为1表示两个概念完全相等,相似度为0表示两个概念完全不相关。(2)满足对称性S(ci,cj)=S(cj,ci)。(3)相似度计算方法应综合考虑制造资源间的各种影响因素,而计算公式本身应该简洁,易于计算。
2.1基于距离的概念语义相似度计算
基于距离的计算方法是使用本体树形模型中的两个概念的最短路径长度来衡量概念之间的语义相似度。距离越近,相似度越大;距离越大,相似度越小。该方法计算简单,复杂性小,但是缺点也比较明显。因为该方法已经假设本体树形图中所有边的重要程度是一致的,即所有边的权重相同。而事实上,树形模型中边的重要程度与其位置、类型等多种因素都有关系,所以这种假设是不成立的。文献[5]根据概念在本体模型中的位置设置权重,对两个概念词汇的路径中带权值的边求和,进而得到两个概念词汇的距离,用这个距离表示两个概念的相似度,计算方法如下[5]:
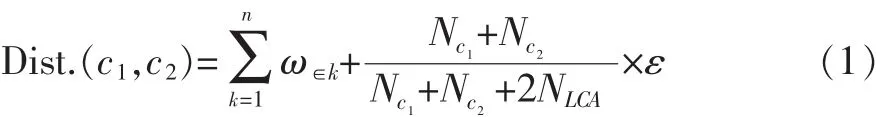
2.2基于信息内容的概念语义相似度计算
该方法使用两个概念词汇间共享信息的多少来表示语义相似度。如果概念词之间共享信息越少,则它们相似度越小;如果它们之间共享信息越多,则相似度越大。Lord使用树形图中概念词的最近公共父节点概念词包含信息量的多少来表示概念词间的语义相似度[5-6]。
2.3基于属性的相似度计算
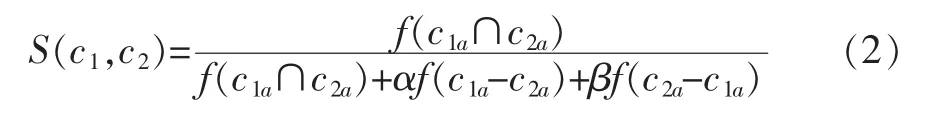
其中,c1a和c2a分别是本体概念词c1和c2的属性集合;c1和c2的属性集交集c1a∩c2a表示它们之间相同属性集合;c1a-c2a为c1和c2属性集的差集,即包含在c1a中的属性但是没有包含在c2a中的属性的集合,同理,c2a-c1a表示包含在c2a中的属性但是没有包含在c1a中的属性的集合。
基于属性的相似度计算基于这样的思想:若两个概念词有非常多相同的属性,则认为这两个概念相似度高,反之亦然。Tversky在文献[7]中给出了计算方法:
3 基于制造资源本体的语义相似度计算
上述几类方法从不同角度出发,给出了相似度计算方法,但是这些方法没有将本体距离、节点密度、属性、信息内容等影响因素综合考虑。下面我们用一个实例来说明。
如图1所示,以带权重的距离计算方法,图中的“c8锻压设备”和“c9焊接设备”两个概念,与“c10传动件”和“c11连接件”两个概念的带权重距离相等,这是因为c8和c9的深度为4,有共同的父节点c4;而c10与c11也有共同的父节点c7,且他们的深度也为4,另外这4个节点有共同的祖先节点c0,所以,他们的带权重的距离也是相等的。但是直观上我们认为“c8加工锻压设备”与“c9焊接设备”的相似度比“c10传动件”和“c11连接件”的相似度要小。所以,使用距离等单一的计算方法不能精确地反映概念间的相似度,还需综合考虑其他因素,下面我们来分析影响概念语义相似度的各个因素。
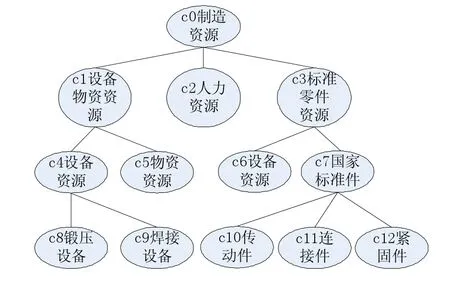
图1 制造资源本体图

其中P(ci)是概念ci在资料中的出现频率统计,使用上面两个公式,我们可以得到两个概念间的相似度计算方法:

(1)制造资源本体概念信息量
由信息理论得知,概念包含的信息量与该概念出现的频率相关,概念的信息量计算公式为[2]:
其中,IC(Anc.(c1,c2)表示概念c1和c2最近公共祖先的信息量。
(2)制造资源本体概念节点密度
通常一个概念节点的密度反映了该概念的具体化程度,若两个概念节点密度都比较大,则这两个概念的语义相似度通常会比较大。
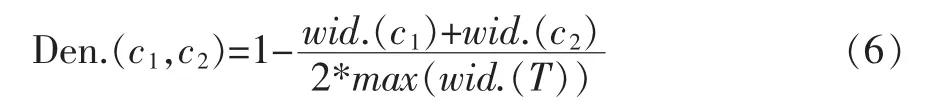
其中wid.(c1)表示概念节点c1的兄弟节点个数,以此来表示该节点的密度,max(wid.(T))是本体树形图中最大节点密度的值[4]。
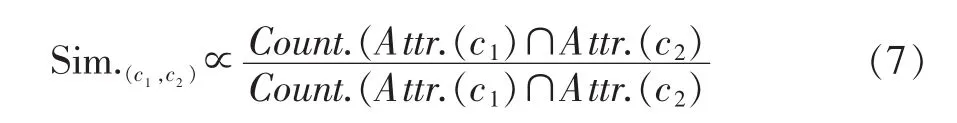
其中,Attr.(c1)∩Attr.(c2)表示表示概念c1和c2各自属性集合的交集,Attr.(c1)∪Attr.(c2)表示概念c1和c2各自属性集合的并集。Count.()是集合中数量的统计函数,公式(7)描述了语义相似度与概念共享属性的关系。
(4)影响因素的系数
上面分析了概念信息量、概念节点密度及概念共享属性对概念之间的语义相似度的影响,综合考虑这些情况,我们定义概念间的语义相似度计算方法为:
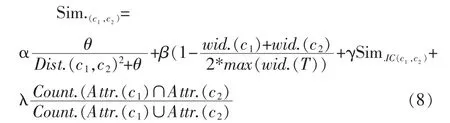
(3)制造资源本体概念属性
在前面基于属性的相似度方法中已经指出,两个概念共享的属性数量与它们的相似度成正比。据此,我们可以得出下面公式:
其中,α、β、γ、λ分别是概念节点间的距离、概率节点密度、概念节点信息量及概念节点共享属性程度这几个影响因素的系数[2]。令这四个系数之和为1,即α+ β+γ+λ=1,通常α的值比其他三个大很多,说明基于语义节点距离对概念间相似度值影响还是最大的。这几个系数的值可以由领域专家设定,也可以由研究者在具体实验环境中通过测试集训练得出。
4 实验
4.1数据集和评估方法
Miller和Charles在实验中证明人工判断语义相似度具有很高的可信度,因而研究者通常使用带人工判断结果的数据集来验证算法的有效性。从设备资源和国家标准件本体数据集中分别选择一部分概念词汇作为实验中的两个数据集,这两个数据集分别包含词汇30对和35对。通常使用皮尔森相关系数来计算人工判断和计算机算法得到的语义相似度的关联度,关联度越高表示人工判断和计算机算法结果越接近,也就表示该算法效果好[8]。例如有X1和X2两个变量,则它们之间的皮尔森相关系数为:
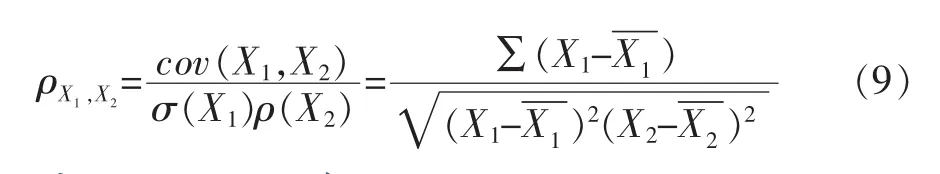
4.2实验结果与分析
实验采用文献[2,6,7]中分别介绍的基于距离的方法、基于信息内容量的方法、基于共享属性的方法和我们的方法进行测试,表1和表2分别是这几种方法在4.1中提到的两个数据集上计算皮尔森相关系数的结果:
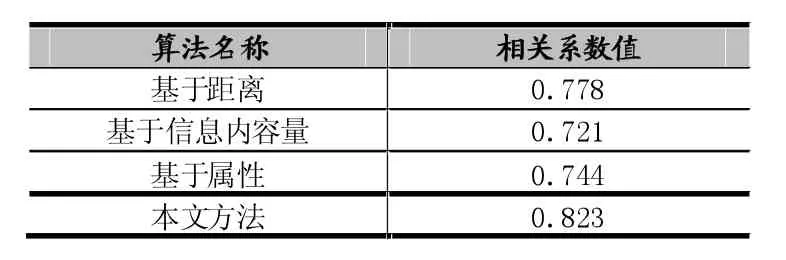
表1 部分设备资源数据集相关系数比较
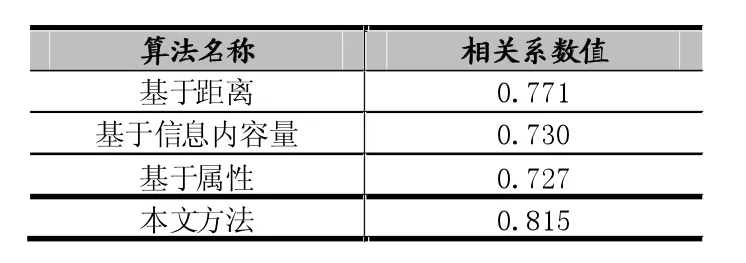
表2 部分国家标准件数据集相关系数比较
从上面的是实验结果可以看出,本文的方法因为综合考虑了距离、信息内容量、共享属性数量等多个因素,因而所得效果明显要比前三种方法好。
5 结语
本文结合制造资源的例子分析了语义相似度计算的几种方法,指出影响概念相似度的因素有多个,单纯一种方法不能到达满意结果,进而提出一种综合各个影响因素的制造资源本体概念相似度的计算方法,最后用实验验证了该方法的有效性。
[1]刘文剑,郭宁,金天国.制造资源本体的相似度计算模型[J].计算机集成制造系统,2010,16(11):2468-2474.
[2]魏军英.基于Web服务的中小企业制造资源共享关键技术研究[D].山东科技大学,2011.
[3]袁庆霓.基于网络化制造环境的制造资源共享服务语义关键技术研究[D].西南交通大学,2010.
[4]党亚洲.基于本体的机械零件资源库语义检索研究与应用[D].新疆大学,2015.
[5]刘宏哲.文本语义相似度计算方法研究[D].北京交通大学,2012.
[6]Shi B,Yan J Z,Wang P,et al.Ontology-based Measure of Semantic Similarity Between Concepts[C].Wri World Congress on Software Engineering.IEEE Computer Society,2009:109-112.
[7]Tversky A.Features of Similarity[J].Readings in Cognitive Science,1988,84(4):290-302.
[8]罗俊丽,王亚,路凯.基于模糊语义的本体概念相似度计算算法[J].微电子学与计算机,2013(7):128-132.
Manufacturing Resources;Semantic Similarity;Concept;Ontology;Distance
Research on Semantic Similarity Calculating Method for Manufacturing Resource Ontology
LUO Jun-li
(College of Information Engineering,Xuchang University,Xuchang 461000)
1007-1423(2016)22-0024-04DOI:10.3969/j.issn.1007-1423.2016.22.005
罗俊丽(1986-),女,河南周口人,硕士,讲师,研究方向为数据挖掘、语义信息处理
2016-07-05
2016-07-30
企业对制造资源的描述是不完全相同的,为了实现企业之间的制造资源共享,需要建立一个能够有效匹配制造企业资源的模型。通过分析现有语义相似度计算的主流方法,提出一种计算制造资源概念语义相似度的新方法。该方法综合考虑距离、共享属性、信息内容量和节点密度等因素,能够明显提高概念的语义相似度准确度。实验结果验证该方法效果要优于传统的语义相似度计算方法。
制造资源;语义相似度;概念;本体
许昌学院科研项目(No.2015090)
The description of manufacturing resources for different enterprises is not same,in order to achieve sharing manufacturing resources among enterprises,need to build an effective model for matching concept of manufacturing resources.Through analyzing the current semantic similarity computation of ontology,proposes a new method for computing the concept semantic similarity.This method synthetically considers different impact factors which include distance,shared property,content information and density of node.By this means,the accuracy of the concept semantic similarity is improved obviously.Experimental result shows that this method outperforms traditional similarity measures.
猜你喜欢
中学生数理化·八年级物理人教版(2022年5期)2022-06-05
房地产导刊(2022年1期)2022-02-28
客联(2021年5期)2021-09-10
哈哈画报(2021年10期)2021-02-28
西南交通大学学报(2018年5期)2018-11-08
制造业自动化(2017年2期)2017-03-20
成才之路(2016年18期)2016-07-08
中国医学影像学杂志(2015年9期)2015-12-15
导航定位与授时(2014年2期)2014-04-27
图书与情报(2013年1期)2013-11-16
