
改进的K-means算法在客户分类中的应用
2016-10-17 01:13:44崔晓云王欢欢钱慎一
现代计算机 2016年24期
崔晓云,王欢欢,钱慎一
(1.河南省烟草公司郑州市公司卷烟配送中心,郑州450000;2.郑州轻工业学院计算机与通信工程学院,郑州 450000)
改进的K-means算法在客户分类中的应用
崔晓云1,王欢欢2,钱慎一2
(1.河南省烟草公司郑州市公司卷烟配送中心,郑州450000;2.郑州轻工业学院计算机与通信工程学院,郑州450000)
0 引言
面对异常激烈的市场竞争,企业无论在生存还是在发展上均受到了严峻的考验。目前,有许多著名的研究所表明,企业开发客户虽然很难,但维持一个客户会更难。此外,帕累托理论显示,企业的绝大部分的利润是由企业20%的客户创造的,而这20%就是企业最重要客户。说明虽然很少但很重要。此外,另外一些研究结果表明,高成本顾客抵消掉了企业一半的利润[1]。因此,企业在进行客户关系管理时挖掘出哪些是企业最重要的客户、哪些是不重要的客户是至关重要的。
数据挖掘技术一直是值得学习的一门知识。从大量数据中用数据挖掘的方法发现其中潜在的信息和人们感兴趣的数据模式成为了人们的一种一般需求。随着数据挖掘的不断发展,挖掘的方法层出不穷,其中最基本的方法是聚簇。k-means算法在聚簇方法中,是最著名也是最常用的划分法之一[2]。再许多实际的问题中,聚类分析在都有着很重要的应用,如:在股票市场,用此方法把具有相似价格浮动的股票进行分组;用于客户关系管理中的客户价值划分等[3]。在生物学和医学领域里,将有相似功能的蛋白质和基因分组;K-means聚类算法是目前最为传统也最为经典的聚类算法,通过不断地调整更新,整合离中心点相邻数据的均值,将数据聚类。该算法具有算法速度快,稳定性好,原理简单等优点,被广泛的应用于科学研究和工商业等领域[4]。
1 客户价值理论
客户的价值是指能为企业带来的最大的效益,为了能获得更大的利润企业就需要对客户进行分门别类的管理,利用合理的营销策略激发客户的购买热情,使其更好地为企业服务,创造出更多的价值。
如果客户对某种服务或者产品者生产不太满意,他们会很快转移把目标和兴趣,重新发现或者关注其他的产品,甚至更换产品供应商,从而给企业带来巨大损失。因此,企业要将客户的满意度提高,就不得不对客户进行分门别类的管理[5]。
2 K-means算法[6]
2.1K-means算法原理
K-means算法,也被称之为K-均值。该算法首先人任意地抽取几个对象作为初始的质心;然后将剩余的每个对象,根据其与各个质心的距离赋给最近的簇,然后对每个簇的质心进行重新计算;不断重复这个过程,直到准则函数不再发生任何变化。通常采用的准则函数为,SSE(Sum of the Squared Error),其定义如下:
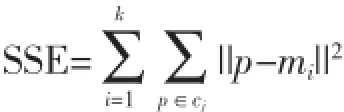
2.2初始中心的确定
对聚类结果产生较大影响的是对初始聚类中心的选择,如果选择的不好,将无法得到有效的聚类结果。可以通过多对一些不同初值的设置,将最后的运算结果进行对比,如果结果一直趋于稳定,则说明选取恰当,但比较浪费资源且耗时比较大。本文通过建立MTA数据模型,通过V值对数据进行初始值处理,确定的初始质心,可以得到良好的聚类效果。
在《大数据》书中曾提到两种方法对初始质心点的选取[8]:(1)选择点时彼此尽可能远(2)用Canopy算法或者层次聚类算法进行聚类,然后,从得到K个簇中选择一个点,该点可以是距离类簇中心点最近的那个点或者是该类簇的中心点。
3 在某公司客户价值细分中的应用
3.1数据清洗[7]
本文所使用的数据来源于郑州市金水区烟草物流公司近一年的134万订单数据,在数据库中一共六张与顾客购买记录相关的数据表。数据表中的记录为主要研究对象包含了订单代码、客户编码、订单日期、商品编号、商品数量、商品金额、购买次数、线路编号等50个字段。
数据清洗通过对数据进行一致性检查,缺失值和无效值的处理,发现并纠正数据文件中可识别的错误。根据每个变量的相互关系和合理取值范围进项一致性检查,检查此数据是否合乎要求。本文首先对数据进行了一致性检查,发现本次数据并无超出正常范围而且逻辑上合理或者不存在矛盾的数据。之后对数据进行了缺失值的检查,将存在缺失值的数据删除。
3.2数据整合
数据整合的目的就是将同一个客户的不同记录进行合并。本文针对客户12个月的订单数据进行了整合。首先,我们 从数据库中抽取出客户购买次数、购买数量、消费金额、订单编码客户编码五个字段。之后将提取出的客户在12个月中的消费金额汇总得到购买总金额。将客户的购买编号进行计数,得到购买次数。其次,将每月 31号设置为截止日期,提取出每个客户每个月最后一次购买时间,并将这个时间与截止日相减,得到最后总的购买数量。
3.3建立客户价值细分模型
综合前述客户价值划分理论,建立二维客户价值细分矩阵。根据客户价值评价指标体系矩阵,客户价值评价指标体系具有三个象限,综合客户的当前价值和潜在价值,分别根据客户当前价值和潜在价值的不同,得出客户总价值。将公司客户细分为三类,分别是:高价值客户、低价值价值、潜在价值客户。
3.4指标及其权重的确定
根据随机抽取的21个客户,选择次数、金额和数量作为指标体系,三个指标的权重系数分别为:0.3,0.2 和0.5.采用下面的公式计算客户价值,初步用V值进行分类,并对其排序。如表1所示:
v=0.5×(数量/数量平均值)+0.3×(次数/次数平均值)+0.2×(金额/金额平均值)
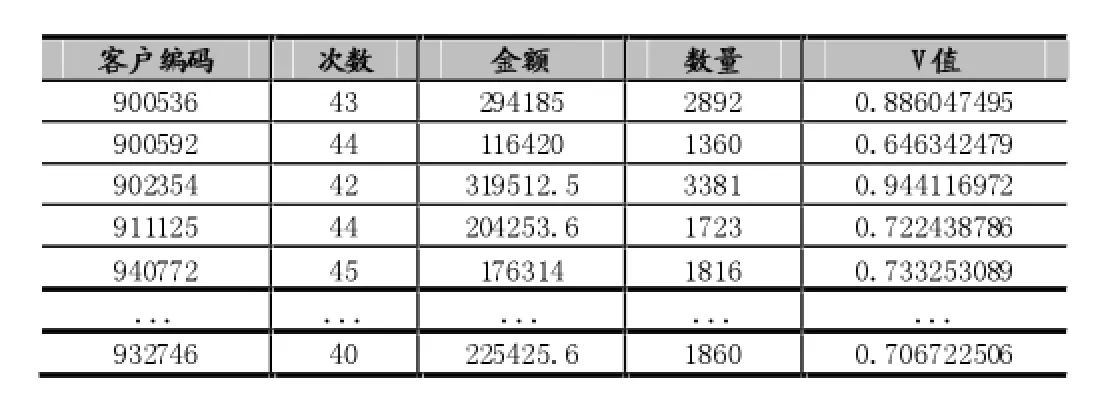
表1 客户指标数据
3.5聚类迭代分析
对初步处理后的数据进行规格化处理后,设k=3,即将这21个客户分成三个集团。抽取客户编号为900536、926329和932746的值作为三个初始运算点,即初始化三个中心为:
A:{0.9285714,0.501555772,0.286658528}
B:{0.6870329 0.0638110870.654634025}
C:{0.909090909,0.014509259,0.014509259}
期间不断调整三个中心点,利用K-means算法进行三次运算后,得到如图1所示客户价值分布图:
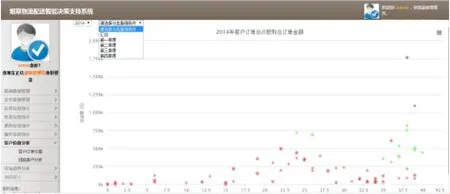
图1 客户价值分布图
3.6基于优化K-means聚类的客户细分效果
利用以上优化的K-means算法,我们利用MATLAB软件,将客户分为三部分,其中红色部分为最重要的客户,蓝色部分为次重要的客户,黑色部分为隐含的客户,从图上不但可以直观地看出客户价值的分布情况,同时还可以得出处在每个价值区间的客户数量,聚类效果清晰明了。聚类效果图如图2所示。
3.7决策的制定
具有较高价值的客户,公司需要加大关注力度以防流失,稳固为主提升为辅。提高他们的活跃程度,加长存留期。一般来说,低价值客户,公司可以从客户的爱好、习惯、生活背景等多角度进行分析。找出购买力度低的主要原因,制定针对性的策略提高他们的购买频率。对于潜在客户则要想法挖掘,同时不能流失,在关注的同时想法激发起活跃度,使其有潜在客户转型为高价值客户。
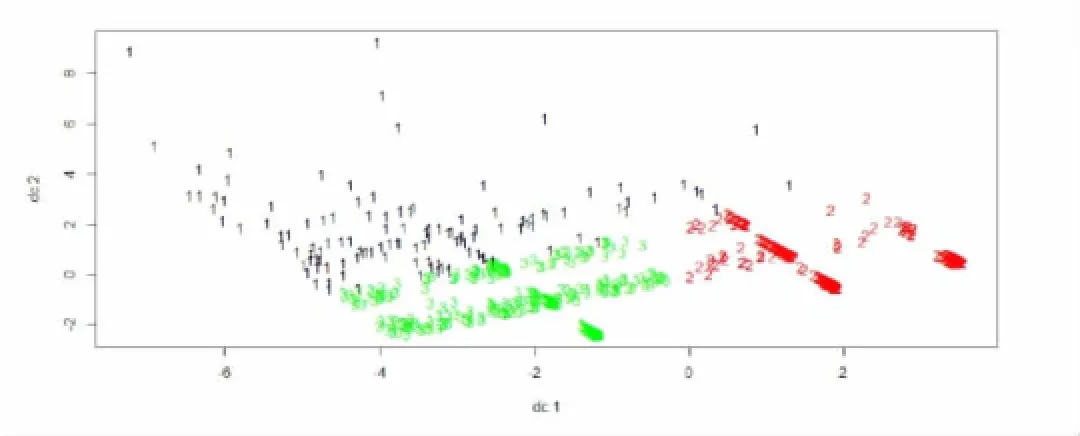
图2 基于K-means的聚类效果图
4 结语
通过对该系统数据的分析,可以得知该公司的发展规模和基本情况,可以进行有针对性的管理,该算法在其中发挥了良好的作用,具有很好的实用性。通过对比不同情况下的分布图可知,结果比较稳定,符合了实际情况。
[1]范明,孟小峰译.数据挖掘概念与技术——聚类分析[M].北京:机械工业出版社,2001.223-258.
[2]Andrea Vattani.k_means Requires Exponentially Many Iterations[J].Discrete Comput Geom,2011(45).
[3]Ching-Hsue Cheng.Classifying the Segmentation of Customer Value Via RFM Model and RS theory[J].Expert Systems with Applications,2009(36).
[4]于辉,廖小红.客户细分方法综述[J].中小企业管理与科技(下旬刊),2014,11:17-18.
[5]Wishart D.K-meansClustering with Outlier Detection[C].Proc.of the 25th Annual Conf.of the German Classification Society.Munich,Germany:University of Munich Press,2001:14-16.
[6]詹海亮,薛惠锋,苏锦旗.基于人工免疫系统的克隆——K均值算法[J].计算机仿真,2008,25(11):191-195.
[7]张建萍,刘希亚.基于聚类分析的K-Meams算法研究与应用[J].计算机应用研究,2007,24(5):166-168.
[8]袁方,周志勇,宋鑫.初始聚类中心优化的K-Means算法[J].计算机工程,2007,33(3):5-66.
Customer Value;K-means Algorithm;Customer Relationship Management
Application of Optimized K-means Algorithm in Customer Value Segmentation
CUI Xiao-yun1,WANG Huan-huan2,QIAN Shen-yi2
(1.Henan Tobacco Companies Zhengzhou Company Cigarette Distribution Center,2.School of Computer and Communication Engineering,Zhengzhou University of Light Industry,Zhengzhou 450000)
1007-1423(2016)24-0025-04DOI:10.3969/j.issn.1007-1423.2016.24.006
崔晓云(1977-),女,河南郑州人,本科,高级物流师,研究方向为物流管理
王欢欢(1989-),女,河南汝州人,硕士研究生,研究生,研究方向为数据挖掘
钱慎一(1975-),男,江苏扬州人,硕士,副教授,硕士生导师,CCF会员,研究方向为数据库与信息集成、计算机应用技术
2016-03-22
2016-08-15
对客户价值的划分,可以为企业进行准确的客户定位,制定良好的市场营销战略。利用优化K-means算法初始值的选取,建立客户潜在价值和客户当前价值表,并以某物流公司现有的实际数据为基础进行实证分析。将所有客户分为重要客户、次重要客户、隐含价客户三类,分析各类客户的消费特性,提出针对性的客户营销及管理方式。
客户价值;K-means算法;客户关系管理
河南省烟草公司科技研究项目,河南省科技攻关项目(No.122102210024)
Customer value for enterprise,can accurate positioning,establish a good marketing strategy.Selects K-means optimization algorithm of the initial value,builds customer potential value and customer current value table,and makes the actual data of a logistics company based on existing empirical analysis.All customers are divided into three types:high value customers,low value customers,potential value customers,analyzes the various types of customer consumption characteristics,and puts forward the targeted customer marketing and management.
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
现代营销(创富信息版)(2018年2期)2018-02-10 05:20:50
电子测试(2017年15期)2017-12-18 07:19:27
知识经济·中国直销(2017年7期)2017-07-24 14:12:42
电力与能源(2017年6期)2017-05-14 06:19:37
山东青年(2016年2期)2016-02-28 14:25:41
智能系统学报(2015年4期)2015-12-27 09:38:39
信息通信技术(2015年6期)2015-12-26 01:16:46
电子设计工程(2015年6期)2015-02-27 12:04:53
时代英语·高三(2014年5期)2014-08-26 20:03:59
