
大数据下基于Spark的电商实时推荐系统的设计与实现
2016-10-17 01:13:48岑凯伦于红岩杨腾霄
现代计算机 2016年24期
岑凯伦,于红岩,杨腾霄
(1.上海海事大学信息工程学院,上海201306;2.上海海事大学交通运输学院,上海 201306;3.上海纽盾科技有限公司研发部,上海 200092)
大数据下基于Spark的电商实时推荐系统的设计与实现
岑凯伦1,于红岩2,杨腾霄3
(1.上海海事大学信息工程学院,上海201306;2.上海海事大学交通运输学院,上海201306;3.上海纽盾科技有限公司研发部,上海200092)
0 引言
随着互联网规模的迅速增长,导致用户在面对海量的互联网信息时,无法从中获取自己真正感兴趣的信息,产生“信息超载”问题。个性化推荐在此问题上弥补了搜索引擎的不足,即代替用户评估其所有未看过的产品,并通过分析用户的兴趣爱好和历史行为,主动推荐符合用户喜好的项目。目前个性化推荐系统已在电子商务、电影、音乐网站等领域取得了显著的成功。
根据IDC发布的数字宇宙报告显示,至2020年数字宇宙将超出预期,达到40ZB,相当于地球上人均产生5247GB的数据[1]。面对未来如此巨大规模的数据量,传统单机环境下的推荐系统存在着两大问题:一是单机节点的推荐模型训练由于单机硬件条件的限制,无法存储所有需要运算的数据量;二是由于训练数据集规模的增大,单机节点进行训练的时长不断增长。传统单机环境下的推荐系统无法满足大数据时间推荐的需求,Hadoop[2]平台能够处理高达上TB级别的海量数据。目前有大量的学者对单机的机器学习算法使用Hadoop平台编写进行扩展以实现对大规模数据集的处理。江小平[3]等基于MapReduce编程模型对朴素贝叶斯文本分类算法进行并行化扩展。刘义[4]等基于Map-Reduce编程模型在Hadoop平台上实现了基于R-树的k-近邻连接算法。对于推荐内容的计算,大量的学者将推荐系统和Hadoop平台进行集成,Yu[5]等采集用户之间传递的信息以及发表的游记文本作为训练数据,利用Hadoop平台构建旅游推荐系统。 Walunj[6]等利用基于MapReduce实现的Mathout算法库构建电子商务推荐系统,该算法库集成了协同过滤算法,具有更好的操作性。
Hadoop平台解决了海量数据计算推荐模型的问题,但是Hadoop平台在并行计算时必须将中间结果存储在磁盘中,并且需要从磁盘中再次读取,导致Hadoop平台构建的推荐系统存在如下不足:一是离线推荐模型在面对海量数据时会出现训练时间较长的问题;二是无法对用户的实时日志行为做出实时处理。由于基于Hadoop平台构建的推荐系统存在的不足,无法满足实时推荐的需求,使得用户对于电商网站的推荐反馈速度提出了更高的要求。Spark是新兴的大数据处理引擎,其很好地解决了Hadoop平台在计算时需要将运算的中间结果存入磁盘所导致的计算速度缓慢问题。从2009年Spark诞生至今,作为开源项目已经在流处理、图计算、机器学习、结构化数据查询等各个方面,取得了很多重要的成果[7]。Spark平台为迭代式数据处理提供更好的支持,每次迭代的数据可以保存在内存中,而不是写入文件。Spark平台提供了集群的分布式内存抽象,即RDD[8],一个不可变的带分区集合,以实现数据操作方式的多样性。目前针对Spark平台的相关研究论文较少,Lu[9]等利用远程内存提升Spark平台在处理大数据时的速度。Qi[10]等利用Spark平台将用于配对测试检测的基因算法进行两阶段并行处理,提升了配对测试的体积大小和计算的效率。Yang[11]等基于Spark平台提出了分批处理的梯度下降算法,并对深度置信网络进行训练,提升了收敛速度。国内对于Spark平台的研究目前主要集中在一些互联网行业,如阿里巴巴、百度、腾讯、网易、搜狐等。腾讯公司数据仓库已经大量使用 Spark平台替代原来的Hadoop平台的MapReduce,并使系统性能大大提高。曹波[12]等将传统关联分析中的FP-Growth算法在Spark平台实现了并行处理,解决了识别大数据的伴随车辆组问题。王虹旭[13]等设计了在Spark平台上的并行数据分析系统,来解决海量数据分析问题。严玉良[14]等提出了一种基于Spark的大规模单图频繁子集挖掘算法,通过次优树构建并行计算的候选子图,在给定最小支持度时挖掘出所有的频繁子图。王诏远[15]等基于Spark平台提出一种并行蚁群优化算法,通过将蚂蚁转换为弹性分布式数据集,由此给出一系列转换算子,实现蚂蚁构造过程的并行化。
目前基于Hadoop平台的推荐系统解决了推荐模型并行训练的问题,但离线训练速度慢。通过对Spark平台的研究,Spark平台拥有比Hadoop平台更强大的计算能力,能更快速地处理并行数据,但目前的研究仅是针对大数据下电商网站离线推荐系统的设计,并未提出基于Spark平台的实时推荐流程和算法。本文设计和实现了应对大数据的基于Spark平台的电商实时推荐系统,设计了实时推荐系统流程,提出了分布式日志实时采集、分布式日志实时传输、实时日志过滤和基于Spark平台的实时推荐模型的关键技术。实验结果表明,本系统具有高可靠性和稳定性,能够满足大数据下实时推荐的需求。
1 系统架构设计与关键技术
1.1系统架构设计
(1)设计思想
电商网站存在着大量的用户隐式行为 (例如用户浏览商品、用户下单、用户取消订单、用户将商品加入购物车和用户将商品从购物车删除),此外,由于电商系统规模的扩大和各个业务系统的拆分,使得系统日志文件散落在各个服务器上。传统基于Hadoop平台的推荐系统无法有效地汇总用户隐式行为日志,并对隐式行为日志进行有效分析,无法满足系统实时推荐的需求。本文的设计思想是根据电商网站的显式用户行为相对稀缺这一特点,采用用户隐式行为来构建用户评分,并在隐式数据源的基础上将传统基于Hadoop平台构建的推荐系统移植到Spark平台,同时在传统离线推荐的基础上结合用户实时点击流,实时分析用户行为,并融合离线推荐模型,以反馈最适合当前用户的实时推荐列表。本文设计的基于Spark平台的电商实时推荐系统架构,如图1所示。
在图1中,基于Spark平台的电商实时推荐系统架构分为3层:离线处理层、服务层和实时处理层。在服务层,首先系统将访问各个业务系统的请求交由多台应用网关进行下发,在应用网关集群前通过HTTP服务器进行负载均衡。然后通过构建分布式日志框架,在应用网关服务器上安装分布式日志采集Agent,采集访问各个业务系统的日志信息。由于电商网站的日志产出量巨大,需要可靠的消息传送中间件作为模型训练与数据源采集之间的纽带,系统构建了基于Kafka集群的消息分发中间件,实现日志数据的统一下发。由于日志数据中包含着各个业务系统的日志以及用户点击流的日志,在进入离线或实时推荐阶段前,需经过统一的数据清洗。与以往将日志数据存储于某一固定介质、统一做离线批处理完成清洗不同,本系统采用Spark平台的Spark Streaming技术实现日志的实时处理。Spark Streaming技术可以按照时间分片,对固定时间间隔内收到的数据进行统一批处理,能达到实时处理的效果,并具有很高的吞吐量。
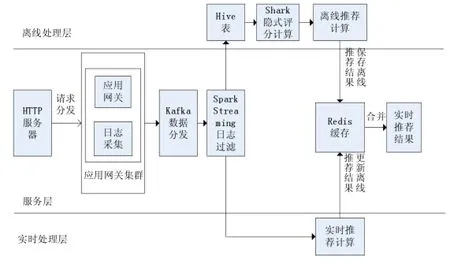
图1 基于Spark平台的电商实时推荐系统架构
在离线处理层,作为实时推荐的数据源收集完毕后,对数据源中的用户行为进行权重的分级,得到用户对于某商品的基本评分,并输入推荐模型训练。传统的方案是使用Hadoop平台的离线推荐模型训练,但Hadoop平台存在三个问题:一是抽象层次低,需要编写很冗余的代码完成操作;二是Hadoop平台只提供Map和Reduce两个操作,表达能力欠缺;三是处理中间结果存储在HDFS文件系统中,使得计算迭代式任务速度缓慢。本设计采用的Spark平台利用RDD进行抽象,实现的数据逻辑相比Hadoop平台更简短,同时提供多种转换和操作,具有很强的表达力。同时,相对于Hadoop平台,Spark平台的中间计算结果可以缓存在内存中,对于需要很多迭代计算的推荐任务,提高了计算效率。此外,基于Spark计算框架和Spark Mlib机器学习库提供了ALS推荐模型,可以构建新的离线推荐系统,并且将电商网站所有用户推荐列表写入Redis缓存系统中,缓解电商网站系统压力。
在电商网站中,如果只进行离线的模型训练,用户当天的访问行为并不能实时地反映在推荐列表上,无法更好地满足用户需求以及提高电商网站商品的转化率。因此,在实时处理层,系统需要对实时的用户行为进行处理,将其与离线推荐的结果进行混合,从而提高实时推荐的效果。Hadoop平台由于存储的特性,只适用于批处理的场景,而采用了Spark Streaming(Spark流技术)的Spark平台,针对用户的每次访问,可以实时过滤日志信息,抽出所需要的信息,获得与该商品相似的前N位商品列表,并与离线模型进行混合处理,进行重排序,使得电商网站可以感知到用户最新的行为,提升电商网站的转化率。
与以往基于Hadoop平台的离线推荐系统相比,本文构建的基于Spark平台的电商实时推荐系统具有比以往更快的反馈速度和训练速度。
(2)实时推荐系统流程
基于以上设计思想,系统从Spark Streaming端获取所需要的数据,并复用了日志数据源端提供的数据,经过数据聚合、数据传输和数据过滤后,进行离线和实时推荐,返回融合了离线推荐和实时推荐结果的推荐列表。系统设计的实时推荐流程如下。
步骤1:计算隐式评分。电商网站通过HTTP服务器Nginx,根据配置好的响应规则,将用户的请求分发到多台应用网关中,由应用网关完成向各个业务系统的请求调用,如购物车、交易以及商品系统。在应用网关中植入分布式日志采集工具Agent,收集发向各个业务系统的日志信息,并汇集后发向Kafka消息集群。Kafka集群会接入Spark Streaming实时处理框架进行日志过滤,抽取出用户交易行为、用户浏览行为和用户对购物车操作行为,并写入Hive表。使用Shark读取Hive表。其中Shark是基于Spark平台上且兼容Hive语法的SQL执行引擎,其底层调用Spark并行实现。在调用Shark时,系统赋予每一种用户行为的不同权重,利用Shark计算用户对商品的评分。
步骤2:离线推荐模型训练。计算完隐式评分,即可以得到(用户ID-商品ID-评分)三元组,作为离线推荐模型的数据源,由于单一用户在网站上的购买数据占商品总量很低,因此使用交替最小二乘(ALS)算法,计算出隐式因子,填补用户未购买的商品的预测评分,然后训练出离线推荐模型。
步骤3:生成离线推荐列表。将电商网站上的用户依次输入模型,得到所有电商网站注册用户的离线推荐列表,设置推荐列表长度,为了减低数据库访问的压力,系统将所有的推荐列表放入Redis缓存系统中,同时提供获取推荐列表的接口,供PC端、移动网页端和移动App端调用。其中Redis是一款基于内存存储的,可持久化的键值对数据库。
步骤4:生成实时推荐列表。首先利用 Spark Streming技术,将Kafka集群传来的日志信息过滤出日志点击流,从中抽取出用户产生行为操作的商品ID和用户ID。然后根据步骤2训练好的离线推荐模型,进行商品相似度排序,可得到相似度排名前5的商品。最后根据得到的用户ID和商品ID的推荐列表,构建商品ID和用户ID的列表,即商品被推荐到用户的键值对,定位到相关用户ID,并将用户推荐列表的前5个替换为步骤5得到的TOP 5商品,以此减少Redis的更新次数,来优化系统的响应速度。
1.2系统架构设计
本文设计和实现的基于Spark平台的电商实时推荐系统,主要会经历如下阶段:日志数据的采集;日志数据的聚合;日志数据的传输;日志数据的过滤;用户隐式行为的实时推荐。
(1)分布式日志的实时采集
电商实时推荐系统需要大量隐式的用户行为作为基础数据,而且每种用户行为的源日志信息分布在不同的业务系统中,需要构建分布式日志汇总系统将日志进行收集,以备后续流程使用。本系统基于开源的分布式日志收集工具Logstash,实现对各业务子系统的日志进行收集。分布式日志采集模块如图2所示。
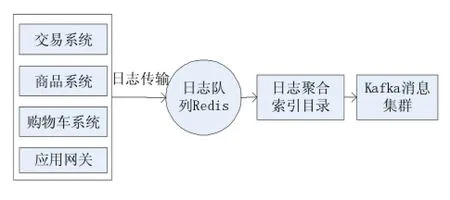
图2 分布式日志采集模块
在图2中,系统植入在应用网关处的日志监控可以实时监测日志文件的变化,并根据偏移量,读取来自交易系统、商品系统和购物车系统的最新日志信息,然后将日志输出到Redis中缓存起来。日志聚合索引目录是日志的存储者,负责从Redis缓存中收集日志,并格式化处理,输出给所需要的用户。分布式日志采集模块的自定义输出为Kafka消息集群。
(2)基于Kafka集群的数据传输
通过构建分布式日志实时采集模块,完成了用户行为日志的采集。但是在进入日志过滤阶段之前,由于日志流并发产生且数量很大,如何保证数据的实时性以及尽量减少数据丢失,这些都给隐式用户行为日志数据的收集带来了巨大的挑战。LinkedIn公司开发了一套专用的分布式消息订阅和发布系统——Kafka,于2010年开源,并且成为Apache的开源项目之一。本文设计和实现的电商实时推荐系统中,构建Kafka集群,来承载上千万的用户行为日志信息,为后续的日志过滤阶段提供了安全可靠的消息传输。由于Kafka集群是一套分布式系统,其吞吐量可以随着集群的扩展而线性增加。图3为基于Kafka集群的数据分发架构。

图3 基于Kafka集群的数据传输
在图3中,Kafka集群由三个部分构成:生产者(Producer),代表日志的来源;代理(Broker),代表消息的中间存储层;消费者(Consumer),代表消息的使用者。其中,Producer负责将消息收集并推送(Push)到Broker,而Broker则负责接收Producer发送来的消息,并将消息本地持久化,Consumer则是消息的真正使用者,从Broker拉取(Pull)消息并进行处理。系统中植入在应用网关的 Logstash日志监控会将处理完的日志发送至LogStash日志聚合索引,由LogStash日志聚合索引作为生产者将日志数据发送至Kafka集群,Spark节点作为消费者,启动Spark Spreaming处理实时传来的日志流,并根据实时推荐的需求做不同的过滤处理。
(3)基于Spark Streaming的日志过滤
数据传输后,系统统一使用Spark Streaming过滤数据,并根据流程将日志做不同的处理,实现离线和实时推荐的复用的日志过滤模块。Spark Streaming接收到的是实时收集到的日志信息,含有很多的噪声数据,需要从中抽取出所需要的信息。在实时推荐流程中,需要获取点击流的日志数据,从中抽取出用户ID和商品ID。用户点击商品所调用的接口方法用于获取商品详情,根据预先定义的日志信息的主题,从Kafka代理层中拉取日志信息。其中在日志信息中记录了用户这次请求调用的接口。LogStash展示的是商品详情查看源日志的格式化日志,具体如表1所示。
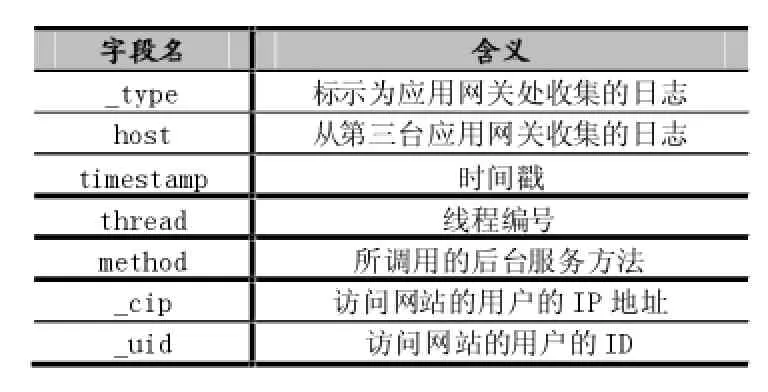
表1 LogStash的格式化日志
由于表1只是LogStash提供的前端展现,在系统流程中,需要调用Spark Sreaming对所有接受到的日志调用filter函数,将消息中包含获取商品详情方法的日志过滤出来,过滤后得到所有的商品详情的请求日志,在消息中解析变量字段对应的内容,从中获得itemId,即商品ID,然后获取用户行为字段,并从字段对应的内容中获取_cip(用户IP),_uid(用户id)等关键信息,为后续的实时推荐提供了数据源。
(4)基于Spark平台的实时推荐算法
本文设计的大数据电商实时推荐系统主要分为离线处理和实时处理两个不同的流程,基于Spark平台对已有离线推荐系统进行优化,并且在实时性上进一步加强,将离线推荐的结果和实时推荐的结果进行融合,实现电商网站的实时推荐。系统首先进行离线模型的训练,离线推荐主要基于对用户隐式行为的挖掘,如支付、未支付、增删购物车和浏览详情等操作,因而需要获得用户的隐式行为,得到用户对商品的隐式评分。隐式用户行为表如表2所示。

表2 隐式用户行为表
基于Spark平台的实时推荐算法如下:
(1)读取用户行为表。系统运用Shark从Hive中获取3个用户行为表,即用户交易表、用户购物车数据表和用户浏览商品记录表。
(2)构建训练数据源。读入用户行为表,根据用户点击行为的权重,得到(用户ID,商品ID),评分)键值对。读入交易表,对支付行为以及非支付行为进行分别处理,根据对应的权重,得到(用户ID,商品ID),评分)键值对。读入购物车数据表,因为购物车有多种不同的行为,本系统只需要增加物品至购物车,以及从购物车删除商品,购物车表进行过滤,筛选出需要的记录,得到(用户ID,商品ID),评分)。读入用户浏览商品记录表,根据对应的权重,得到(用户ID,商品ID),评分)键值对。
(3)离线推荐模型训练。处理完3个用户行为表,调用union函数,将用户行为表中得到的(用户ID,商品ID),评分)键值对进行融合,去掉重复键值对,并构建Spark Mlib机器学习库中基于ALS的协同过滤算法的数据源,即(用户ID,商品ID,评分)三元组。设置ALS迭代的次数以及相关参数,ALS算法会对用户-商品评分矩阵进行分解,利用隐语义因子进行表达,同时用于预测缺失的元素。
(4)实时推荐模型。离线模型训练完毕后,首先电商网站将网站所有的用户输入模型,将推荐列表写入Redis缓存系统,优化网站性能。然后启动实时推荐任务,根据从点击流中取得的商品ID,利用离线推荐模型,取得与之最相似的前5个商品。最后在Redis缓存系统中找到对应用户ID的推荐列表,剔除原有列表的最后5个,将第2步中得出的5个商品放入Redis中推荐列表的队首。
通过上述离线推荐与实时推荐的融合,完成基于Spark平台的实时推荐模型,达到实时响应用户请求,实现实时推荐反馈的目的。
2 实验分析与结果
本文的实验环境如下:基于Spark平台的电商实时推荐系统搭建了3台云服务器,托管在阿里云上,承担每日的用户访问;每台服务器配置8核CPU,16GB内存和300GB硬盘。软件配置如下:采用Spark 1.5.2版本用于大数据处理;Java 1.8版本用于编写Spark程序;Logstash 2.1.1版本用于分布式日志采集;Kafka 0.8.2.2版本用于分布式日志数据传输;此外Hadoop 2.6版本用于分布式文件系统并与Spark平台进行测试对比。本文对分布式日志采集、分布式日志传输、实时日志过滤和实时推荐等系统关键技术进行实验。
2.1分布式日志采集
大数据下电商网站每天为大量的用户提供服务,图4显示了电商网站的每天采集的日志总量,达到1600 万/天的日志吞吐量。海量的用户行为日志数据为实时推荐提供了足量的训练数据。本文所构建的分布式日志采集模块解决了大数据电商网站跨系统收集用户访问日志的问题。

图4 电商网站每天日志总量
2.2分布式日志数据传输
分布式日志采集系统每天会采集到1600万的日志信息,其中绝大部分会交给Kafka集群进行传递,作为实时推荐的数据源,因此需要对Kafka集群进行吞吐量的测试,以保证数据可靠、实时传输。多个Producer可同时向同一个主题发送数据,在Broker负载饱和前,Producer数量越多,集群每秒收到的消息量越大,并且呈线性增涨,不同个数Producer时的总吞吐率如图5所示。
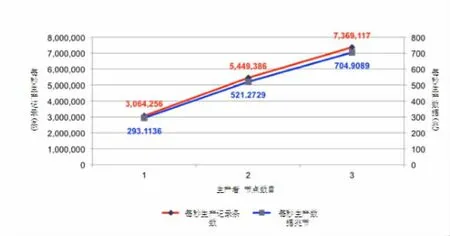
图5 Kafka集群的生产者性能实验
由图5可以看出,单个Producer每秒可成功发送约128万条负载为100字节的消息,并且随着Producer个数的提升,每秒总共发送的消息量线性提升。系统中有4台Producer,每天产生的日志总量是1600万。系统构建的Kafka集群,经实验证明,足以接收稳定传输分布式采集到的数据。在稳定接收的前提下,对Kafka集群又进行消费测试,在集群中已有大量消息的情况下,使用1-3个Consumer时的Kafka集群总吞吐量如图6所示。
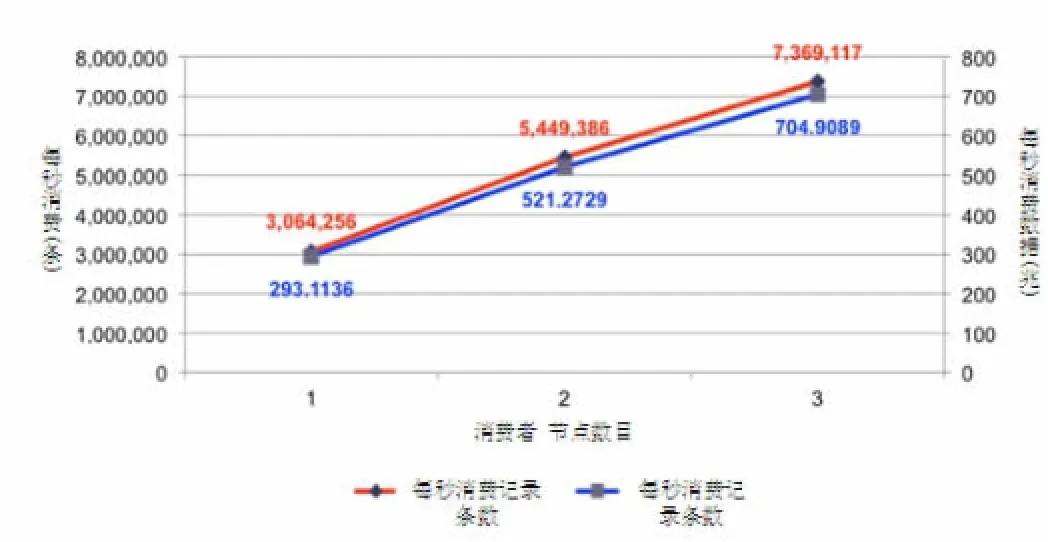
图6 Kafka集群的消费者性能实验
由图6可知,单个Consumer每秒可消费306万条消息,该数量远大于单个Producer每秒可消费的消息数量,这保证了在默认配置下,消息可被及时处理。并且随着Consumer数量的增加,系统集群的总吞吐量呈线性增加,能够满足用户访问量增大,日志传输量增大的需求。
2.3基于Spark Streaming的日志过滤
Kafka集群可以稳定负载本文构建的实时推荐系统的日志传输量,因此需要对Spark Streaming实时处理日志,对提取出所需要数据的力进行测试。Spark-
Streaming处理日志速率如图7所示。

图7 SparkStreaming处理日志速率
在图7中,Spark Streaming平均每秒处理202条记录,且运行状况良好。同时根据系统运行15小时的日志显示,Spark Streaming一共完成18557次实时批处理,提取了13533355条记录,能够满足实时日志的处理需求。
利用Spark Streaming对实时日志流进行实时过滤,从日志中抽取出对应的商品ID和用户ID,供实时推荐流程使用,抽取出的日志信息如表3所示。

表3 实时抽取的日志信息
2.4基于Spark平台的实时推荐
由于Spark平台在处理任务上相对于Hadoop平台的优越性,本文采用Spark以及其生态系统中的ALS模型作为实时推荐平台的计算平台与训练模型。为了测试Hadoop平台与Spark平台在处理计算任务时的性能差异,本系统选用了电商平台采集的数据集对Spark平台与Hadoop平台的MapReduce在执行作业性能上做了对比实验。Spark与Hadoop执行作业时间对比如图8所示。
从图8中可以看出,Spark平台在进行不同作业类型的计算时,性能都相对于Hadoop平台的MapReduce平均提升4倍以上。但对于WordCount、UserBased及ItemBased此类迭代次数不多的任务时,相对于Hadoop平台的MapReduce计算速率提升幅度较小,平均提升3倍以上。
在进行本系统所使用的ALS模型训练时,因为其需要多次迭代运算,性能提升非常显著。ALS模型在Hadoop平台及Spark平台上训练性能对比,如图9所示。
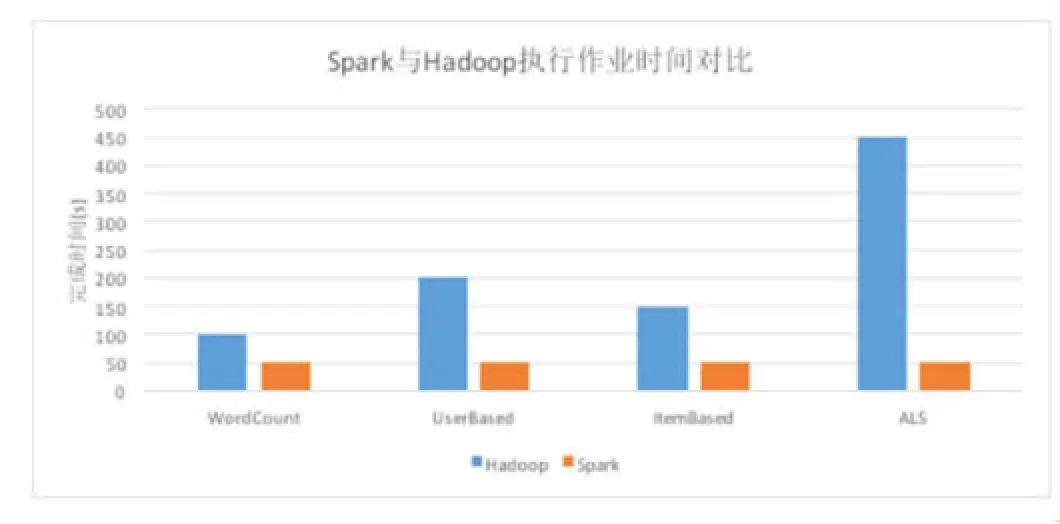
图8 Spark平台与Hadoop平台执行作业时间对比
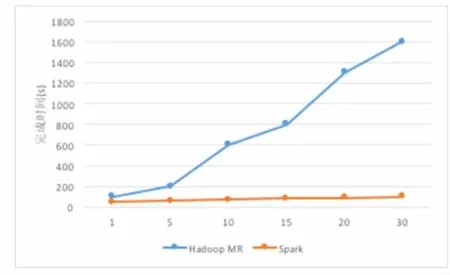
图9 ALS模型在Hadoop及Spark平台上训练性能对比
从图9中可以发现,在多次迭代后,Spark平台的效率相比Hadoop平台要提高10倍以上,这是由于Hadoop平台的Mapreduce每次迭代后,都要重新读取HDFS,使得作业完成的时间和迭代次数成线性增长,而Spark平台由于其将中间结果缓存在内存中,即使进行多次迭代,时间也不会出现明显增加。
图8和图9的对比实验显示了Spark平台作为推荐平台的基础架构相对于传统推荐系统的优越性。实验最后对离线推荐的结果进行了测试。图10显示的是在移动App端基于测试用户的用户行为的离线推荐结果。当测试用户点击了巧克力的类目,通过实时获取用户访问的信息,实时推荐模块会启动,抽取出与该商品最相似的商品,并与离线推荐列表进行融合,产生实时推荐列表。测试用户的实时推荐结果如图11所示。

图10 离线推荐结果

图11 实时推荐结果
图10和图11的实验结果验证了本文设计的基于Spark的电商实时推荐系统能够有效承载网站的日志信息,并根据用户的实时用户行为做出实时推荐反馈,优化了用户体验,提升了网站的销售额。根据日志采集系统,电商网站推荐模块的交易转化率提升了5%,有效优化了用户体验。
3 结语
基于Hadoop实现的推荐系统存在着离线训练速度慢,并且无法对用户实时行为做出推荐反馈,不能满足大数据时代用户对实时推荐系统的需求。以往研究表明,Spark平台在并行处理大数据上拥有比Hadoop平台更强的运算性能,但目前未有一套完整的实现流程解决Spark平台下针对用户隐式行为日志做出实时推荐的问题。本文设计和实现了大数据下基于Spark平台的电商实时推荐系统;提出了一套新的实时推荐流程;针对跨系统用户隐式行为日志的收集及传输的需求,设计并实现了分布式日志采集模块和分布式日志传输模块;并且通过基于Spark Streaming的日志实时过滤模块完成日志数据的过滤。在统一数据源的基础上,本文创新地提出了大数据下电商网站的实时推荐算法,将离线推荐推荐的推荐结果和实时流计算出的推荐结果进行融合,生成实时推荐列表。最后用实验验证了系统的可靠性、稳定性以及相对于Hadoop平台的高效性。下一步的工作将针对大数据下电商网站越来越多种类的用户行为,设计多样的数据处理方式,以提升系统的通用性。
[1]IDC.The Digital Universe of Opportunities:Rich Data and the Incdreasing Value of the Internet of Things[EB/OL].[2014-04]. http://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm
[2]FERRERIA C R L,Traina J C,MACHADO T A J,et al.Clustering Very Large Multi-Dimensional Datasets with Mapreduce[C]. 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2011 ACM.San Diego:ACM Press,2011:690-698.
[3]江小平,李成华,向文等.云计算环境下朴素贝叶斯文本分类算法的实现[J].计算机应用,2011,31(9):2551-2555.
[4]刘义,景宁,陈荦,熊伟.MapReduce框架下基于R-树的k-近邻连接算法.软件学报,2013,24(8):1836-1851.
[5]YU Y,HUANG C,LEE Y.An Intelligent Touring System Based on Mobile Social Network and Cloud Computing for Travel Recommendation[C].28th International Conference on Advanced Information Networking and Applications Workshops(AINA),2014 IEEE. Victoria,Canada:IEEE Press,2014:19-24.
[6]WALUNJ S G,SADAFALE K.An Online Recommendation System for E-commerce Based on Apache Mahout Framework[C].2013 Annual Conference on Computers and People Research,2013 ACM.Cincinnati:ACM Press,2013:153-158.
[7]ZAHARIA M,CHOWDHURY M,FRANKLIN M J,et al.Spark:Cluster Computing with Working Sets[C].Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing,2010:10-10.
[8]ZAHARIA M,CHOWDHURY M,DAS T,et al.Resilient Distributed Datasets:A Fault-Tolerant Abstraction for in-Memory Cluster Computing[C].Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation.USENIX Association,2012:2-2.
[9]X.LU,M.W.U.RAHMAN,N.ISLAM,D.SHANKAR.Accelerating Spark with RDMA for Big Data Processing:Early Experiences[C]. Proceedings of the 22nd Annual Symposium on High-Performance Interconnects.2010:9-16.
[10]QI RZ,WANG ZJ,LI SY.A Parallel Genetic Algorithm Based on Spark for Pairwise Test Suite Generation[J].Journal of ComputerScience and Technology,2016,31(2):417-27.
[11]YANG J,HE SQ.The Optimization of Parallel DBN Based on Spark[C].Proceedings of the 19th Asia Pacific Symposium on Intelligent and Evolutionary Systems,2016:157-169.
[12]曹波,韩燕波,王桂玲.基于车牌识别大数据的伴随车辆组发现方法[J].计算机应用,2015,35(11):3203-3207.
[13]王虹旭,吴斌,刘旸.基于Spark的并行图数据分析系统[J].计算机科学与探索,2015,9(9):1066-1074.
[14]严玉良,董一鸿,何贤芒等.FSMBUS:一种基于Spark的大规模频繁子图挖掘算法[J].计算机研究与发展,2015,52(8):1768-1783.
[15]王诏远,王宏杰,刑焕来等.基于Spark的蚁群优化算法[J].计算机应用,2015,35(10):2777-2780,2797.
Big-Data;Spark Platform;Hadoop Platform;Real-Time Recommendation;Implicit User Behavior
Design and Implement of E-Commerce Real-Time Recommender System with Spark Based on Big Data
CEN Kai-lun1,YU Hong-yan2,YANG Teng-xiao3
(1.College of Information Engineering,Shanghai Maritime University,Shanghai 201306;2.College of Transport and Communications,Shanghai Maritime University,Shanghai 201306;3.Research and Department,Shanghai Newdon Technology Company Limited,Shanghai 200092)
国家自然科学基金(No.61562056)、教育部人文社科青年基金资助项目(No.13YJC630210)、2014年上海市科技型技术创新基金项目(No.1401H164800)、上海市杨浦区国家创新型试点城区建设与管理专项资金项目(No.2015YPCX03-002)
1007-1423(2016)24-0061-09DOI:10.3969/j.issn.1007-1423.2016.24.015
岑凯伦(1991-),男,上海人,硕士研究生,研究方向为云计算、大数据处理
于红岩(1979-),女,山东文登人,讲师,博士,研究方向为电子商务、云计算安全
杨腾霄(1977-),男,山西长治人,工程师,硕士,研究方向为云计算安全
2016-05-12
2016-07-25
大数据下基于Hadoop平台构建的电商推荐系统存在着计算缓慢、无法根据用户实时行为作出推荐的问题。针对以上问题,设计和实现基于Spark平台的电商实时推荐系统。与Hadoop平台构建的推荐系统相比,系统首先基于Spark平台构建了分布式日志采集模块和分布式日志数据传输模块,用于采集和传输用户隐式行为日志,解决电子商务跨系统数据源收集问题;其次在统一数据源的基础上,采用基于Spark的矩阵分解推荐模型进行离线训练,提升离线推荐训练的效率;进而在离线推荐的基础上,提出一种使用Spark Streaming实时流技术对电商日志数据做实时过滤,获取用户当前所需商品,并将离线推荐结果与实时推荐结果通过统一介质融合的方案,实现对用户隐式行为进行实时推荐反馈的功能。最后经实验证明,基于Spark平台的电商实时推荐系统相对于Hadoop平台的电商推荐系统具有更高的可靠性和稳定性,能够承载大规模数据量,离线推荐训练速度相对于Hadoop平台提高10倍,并且对用户的实时行为也能够作出实时推荐反馈,提升5%的交易转化率,增强电商网站的用户体验。
大数据;Spark平台;Hadoop平台;实时推荐;用户隐式行为
Concerns the problem that the e-commerce recommendation system which based on Hadoop platform has low computing speed and can't make recommendation based on real-time user behavior.In order to solve the problem,designs real-time e-commerce recommendation system which is based on Spark platform.What is different from the previous system is that distributed log collection module and distributed log data transmission module are designed to collect and transfer log data of implicit user behavior,which solves the problem of collecting the log data come from different system.On the basis of a unified data source,the matrix decomposition model based on Spark is used to do off-line training and Spark streaming is used to do real-time log filtering to get the most similar goods to the good which included in the log.The result of real-time recommendation and off-line recommendation is merged in the system as feedback to the realtime user behavior.The experimental results show that the system which can carry massive amounts of data has the higher reliability and stability than the system which is based on Hadoop,the training speed of the off-line recommendation is 10 times as fast as that of the Hadoop platform,can make real-time recommended feedback to real-time user behavior which increase the user experience and the percent conversion of trade can be increased 5%.
猜你喜欢
华人时刊(2021年13期)2021-11-27 09:19:02
防爆电机(2021年4期)2021-07-28 07:42:46
中国特种设备安全(2021年11期)2021-05-05 06:13:18
铁道通信信号(2020年6期)2020-09-21 09:23:34
心声歌刊(2020年4期)2020-09-07 06:37:14
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
中成药(2018年2期)2018-05-09 07:20:09
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
中国交通信息化(2017年3期)2017-06-08 06:09:28
