
大数据环境下基于K-means的用户画像与智能推荐的应用
2016-10-17 01:13李冰王悦刘永祥
现代计算机 2016年24期
李冰,王悦,刘永祥
(1.中国烟草总公司北京市公司,北京100122;2.浪潮软件股份有限公司,济南 250000)
大数据环境下基于K-means的用户画像与智能推荐的应用
李冰1,王悦1,刘永祥2
(1.中国烟草总公司北京市公司,北京100122;2.浪潮软件股份有限公司,济南250000)
0 引言
2015年以来,中国烟草行业逐步开始进行市场化取向改革。卷烟营销市场化取向改革是以满足消费者需求为核心,以改革卷烟订单采集方式为抓手,以营销流程再造为重点,保障零售客户自主经营权,层层传导市场力量,优化营销资源配置,促进品牌优胜劣汰,充分发挥改革乘数效应,全面增强行业整体竞争实力。
截至2015年12月31日,烟草行业市场化已经初见成效,基本实现了订单采集集中化、业务流程标准化、营销过程可视化,完成市场化改革的单位覆盖卷烟市场容量1764万箱,占全国卷烟销量的35.4%,实现批发销售收入5010亿元,占全国卷烟销售收入的35.2%,涉及零售客户165万户,占全国正常经营零售客户总数的34%。
随着市场化改革范围的扩大和深入,原来计划体制下的卷烟营销方式逐渐难以满足快速变化的市场需求。与此同时,随着中国经济进入“新常态”以及北京市人口疏解工作的不断推进,北京市场的卷烟销售压力日益增加。因此北京烟草对如何准确洞悉市场信息、把握卷烟消费者和零售户的需求从而实现精准营销提出了更高的要求。
北京烟草经过十数年信息化建设,系统中存储着接近十年的海量交易数据。如何充分利用这些海量数据资源、把大数据技术及互联网企业的成功实践经验引入到北京烟草的信息化建设当中并成为市场化取向改革的强大助力,已成为北京烟草当前亟待解决的课题。本文实现了一种大数据技术的应用,即通过采集历史数据样本,建立聚类模型对卷烟零售户的特征进行画像,测算出零售户属性和卷烟属性中的相关性,并基于这些结果在卷烟零售客户订货时根据其特征推荐相关的卷烟产品。该方式一方面可以把市场中成熟的销售经验传递给新入网的零售户,另一方面可以促进北京烟草合理组织货源,主动为零售户提供了适销对路的商品,提高市场营销的准确度。
1 大数据技术与聚类算法
1.1大数据技术简介
学界与工业界对于所谓的“大数据”并没有一个统一的定义。如2011年McKinsey的研究报告[1]中将大数据定义为“超过了典型数据库软件工具捕获、存储、管理和分析数据能力的数据集”,而美国国家标准和技术研究院NIST认为“大数据是指数据的容量、数据的获取速度或者数据的表示限制了使用传统关系方法对数据的分析处理能力,需要使用水平扩展的机制以提高处理效率”[2]。随着大数据技术的持续演进,其内涵与外延也不断得到发展,现在通常认为“大数据”包含海量结构化、半结构化以及无结构化数据,因此大数据相关技术与传统关系型数据库相比在处理非结构化数据和无结构化数据方面无论是在处理速度还是存储容量上均有较大优势。
大数据价值链可以分为四个阶段:数据生成、数据获取、数据存储和数据分析[3]。其中“数据生成”的工作主要是由相关业务系统或设备来完成,因此目前主流大数据技术主要负责后三个阶段的工作。其中Apache Software Foundation于2005年启动的Hadoop项目最为引人关注[4]。Hadoop源自于对Google Map/Reduce和Google File System的开源模拟,也正是由于其开源特性,吸引了各国优秀计算机专家与工程师投身其中,不断对其丰富完善,现已发展为包含Spark和Storm等多个模块在内的既能实现离线大数据分析也能完成流式计算的主流大数据解决方案[5],并在各行业中均有落地。
1.2聚类算法
聚类分析是数据挖掘中的一种重要算法。聚类的目标是在没有任何先验知识的前提下,根据数据的相似性将数据聚合成不同的类(或簇),使得相同类中的元素尽可能相似,而不同类中的元素差别尽可能的大,因此又称为非监督分类(Unsupervised Classification)[6]。早在20世纪70年代,学界就对聚类算法有了比较深入的研究[7-8],聚类的方法包括统计学方法和机器学习方法。
目前存在着多种聚类算法,其可以分为如下几类:基于划分的方法(Partitioning Method)、基于层次的方法 (Hierarchical Method)、基于密度的方法 (Density-Based)、基于网格的方法(Grid-Based)和基于模型的方法(Model-Based)等[9]。
K-means算法由Mac Queen于1967年首先提出,该算法是目前为止在工业界和科学应用中一种极有影响的聚类算法[10]。K-means是基于划分的方法中的一种,是典型的基于原型的目标函数聚类方法的代表[11]。K-means聚类的目标就是在给定分类组数k(k≤n)值的条件下,通过聚类把样本点按聚集程度分成若干个簇,在同一个簇内具有较高的相似度,而在簇间的相似度较低。即对簇集合S={S1,S2,…,Sk},在数值模型上,对以下表达式求最小值,其中μi表示分类Si的平均值:
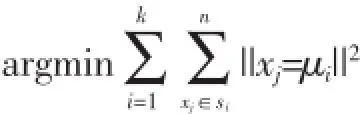
具体算法流程如下:
(1)从 n个数据对象任意选择 k个对象作为初始聚类中心;
(2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的相异度,将这些元素分别划归到相异度最低的簇;
(3)重新计算每个(有变化)聚类的均值(中心对象);
(4)循环(2)到(3)直到每个聚类不再发生变化为止;
(5)输出结果。
通过每天的销售记录中的客户编码和卷烟编码把客户属性和卷烟属性关联在一起组成一条记录,获取到拥有n条数据记录的集合(x1,x2,…,xn),并且每个xi为d维的向量,即xi(xi1,xi2,…,xid),其中xi1~xid为客户属性和卷烟属性。
2 大数据环境下基于K-means的用户画像与商品智能推荐模型
2.1大数据平台技术架构
由于北京烟草现有信息系统中存储了大量历史交易数据,因此使用传统关系型数据库难以在可接受时间内完成对海量数据的分析与处理。北京烟草与浪潮软件股份有限公司共同搭建了基于Hadoop的大数据处理平台,将原有数据中心的历史数据保存到HDFS之中,并通过MapReduce/SPARK实现海量数据计算。
2.2数据挖掘工具的选取
本文中所采用的数据挖掘工具为WEKA。WEKA的全名是怀卡托智能分析环境 (Waikato Environment for Knowledge Analysis),WEKA作为一个公开的数据挖掘工作平台,集成了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理、分类、回归、聚类、关联规则以及在新的交互式界面上的可视化。WEKA可以与基于Hadoop的大数据平台相结合,实现较为完整的大数据分析解决方案。
2.3基于K-means的用户画像
整个画像过程分为六个步骤,包括:
(1)确定业务场景
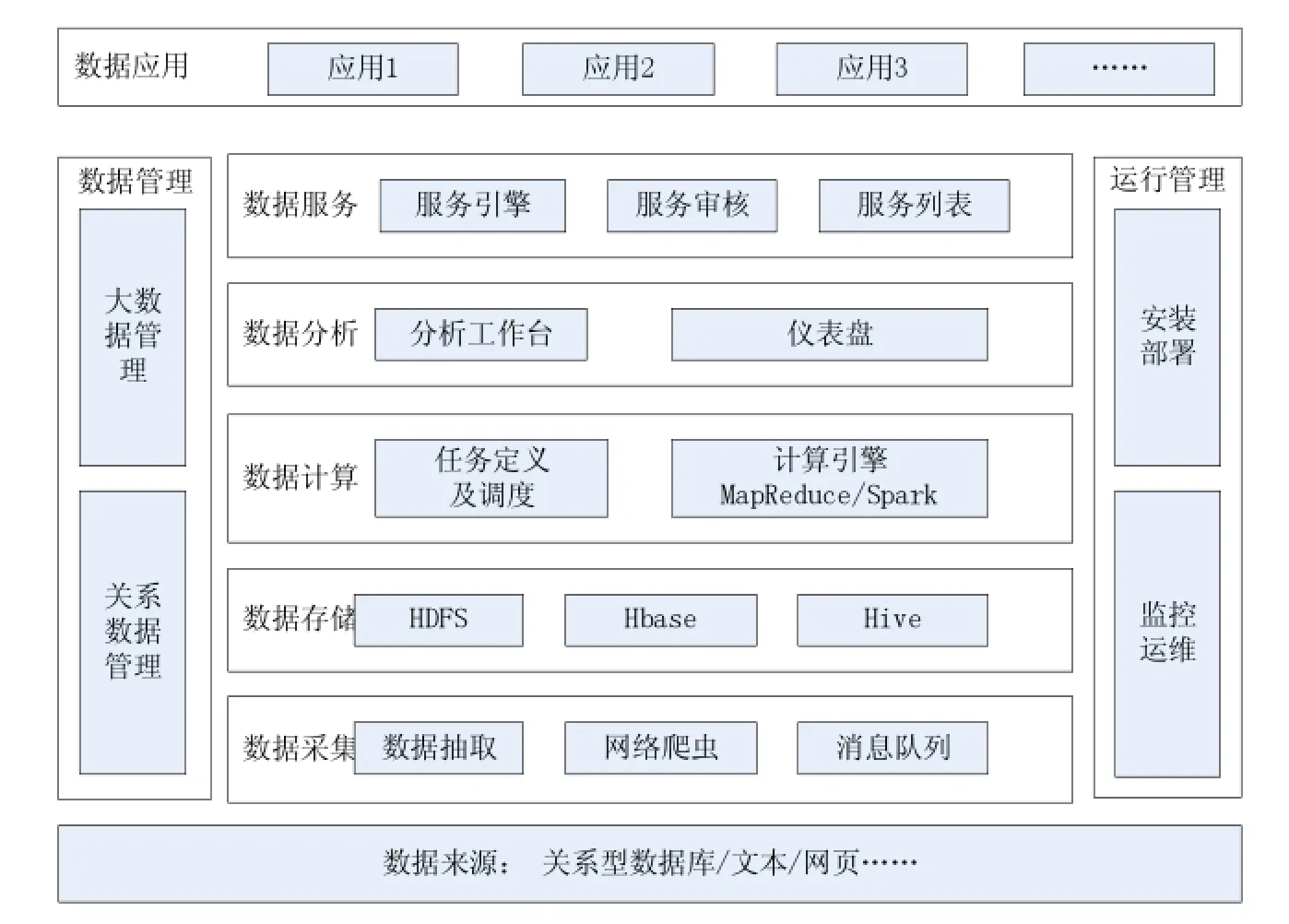
图1 北京烟草大数据平台技术架构
确定三个业务场景进行试验,三个业务场景分别为:场景1.挖掘特征客户群对于卷烟品类的倾向性;场景2.挖掘特征客户群对于产品类型的倾向性;场景3.挖掘特征客户群对于产地类型的倾向性。
(2)数据样本获取
从数据中心系统数据库中关联客户商品日销售表、客户表(通过客户编码关联)和卷烟表(通过卷烟编码关联),选取一个销售周期的数据,共获得样本数据690177条,把数据存为WEKA挖掘工具可用的csv格式,每条样本数据的字段列如下:

表1 销售数据字段列表
(3)数据预处理
数据预处理分为两步,第一步把样本中数字编码处理成字符编码,因为挖掘工具会把这些数字分类编码当成数值来处理,从而影响挖掘结果。需要处理的字段列包括:区域类型、经营规模、结算方式、订货方式、是否终端、价类、产地类别、品类、包装类型。第二步需要在WEKA预处理界面中打开样本数据集,剔出掉CUST_CODE列。
(4)算法选择
选择聚类算法K-means,依据Within cluster sum of squared errors值的大小 (越小越好)经过多次调试,把算法参数seed(随机种子数)设为100。
(5)调试
依次进行业务场景调试,初始时选择所有客户属性和与场景对应的卷烟属性进行挖掘,依据Within cluster sum of squared errors值的大小以及生成的簇间关系进行调整,调整内容包括忽略掉某个客户属性(去掉无效列)、调整预生成簇的个数和调整seed。
(6)结果分析
经过调试,最终确认的各个场景的结果如下:
场景1:挖掘特征客户群对于卷烟品类的倾向性。
零售客户特征选择:业态 (对应BASE_TYPE_ CODE)、经营规模(对应SALE_SCALE_CODE)、月均订货量档次(对应SALE_SCALE_KIND_CODE);
卷烟属性设定为卷烟品类 (对应CATEGORY_ CODE)。
聚类后,生成特征客户群,簇0和簇1。其中簇0的特征为:业态为食杂店(标识为:‘Z')的、经营规模为中的(标识为:‘2')、月均订货量在251-500条的(标识为:‘A3')零售客户倾向于订购卷烟零售价在65(含)-105之间的(标识为:‘C08')卷烟;簇1的特征为:业态为便利店(标识为:‘B')的、经营规模为中的(标识为:‘2')月均订货量在101-250条的(标识为:‘A2')零售客户倾向于订购卷烟零售价在200(含)-260元的(标识为:‘C05')卷烟。
场景2:挖掘特征客户群对于产品类型的倾向性。
零售客户特征选择:业态 (对应BASE_TYPE_ CODE)、市场类型(对应MARKET_TYPE_CODE)、区域类型 (对应AREA_TYPE_CODE)、经营规模 (对应SALE_SCALE_CODE);
卷烟属性设定为产品类型(对应 ITEM_ TYPE_CODE)。
聚类后,生成特征客户群,簇0、簇1和簇2。其中簇0的特征为:业态为食杂店(标识为:‘Z')的、市场类型为城市的(标识为:‘C')、区域类型为学区的(标识为:‘A03')、经营规模为中的(标识为:‘S2')零售客户倾向于订购烤烟型(标识为:‘IT1')卷烟;簇1的特征为:业态为便利店(标识为:‘B')的、市场类型为城市的(标识为:‘C')、区域类型为工业区的(标识为:‘A02')、经营规模为中的(标识为:‘S2')零售客户倾向于订购混合型(标识为:‘IT2')卷烟;簇2的特征为:业态为食杂店(标识为:‘Z')的、市场类型为乡村的(标识为:‘'X')、区域类型为学区的(标识为:‘A03')经营规模为大的(标识为:‘S1')零售客户倾向于订购烤烟型(标识为:‘IT1')卷烟。
场景3:挖掘特征客户群对于产地类型的倾向性。
零售客户特征选择:业态 (对应BASE_TYPE_ CODE)、市场类型(对应MARKET_TYPE_CODE)、月均订货量档次(对应SALE_SCALE_KIND_CODE);
卷烟属性设定为产地类别(对应MFR_TYPE)。
聚类后,生成特征客户群,簇0、簇1和簇2。其中簇0的特征为:业态为食杂店(标识为:‘Z')的、市场类型为城市的(标识为:‘C')、月均订货量在251-500条的(标识为:‘A3')零售客户倾向于订购省外(标识为:‘M1')卷烟;簇1的特征为:业态为食杂店(标识为:‘Z')的、市场类型为城市的(标识为:‘'X')、月均订货量在101-250条的(标识为:‘A2')零售客户倾向于订购省外(标识为:‘M1')卷烟;簇2的特征为:业态为便利店(标识为:‘B')的、市场类型为城市的(标识为:‘'C')、月均订货量在101-250条的(标识为:‘A2')零售客户倾向于订购省内(标识为:‘M0')卷烟。
2.4商品智能推荐模型
在完成零售户画像的基础之上,在零售客户网上订烟平台新商盟网站应用数据挖掘的结果,对符合特征的客户推荐对应特征的卷烟商品。例如向业态为食杂店的、市场类型为城市的、区域类型为学区的、经营规模为中的零售客户推荐烤烟型卷烟。
3 结语
本文基于大数据技术采用K-means实现了用户画像与智能推荐,为北京烟草市场化取向改革的进一步推进提供了新的思路和方法。但由于本方案是基于零售客户的历史订货数据而不是从周边区域消费者角度分析各类特征,如区域人口分布、性别比、消费能力等,因此零售户画像以及在此基础上实现的智能推荐在准确度上尚有不足,需要进一步改进。
[1]Manyika J,Chui M,Brown B,et al.Big Data:the Next Frontier for Innovation,Competition,and Productivity.McKinsey Global Institute,2011
[2]Cooper M,Mell P.Tackling Big Data.NIST,2012
[3]李学龙,龚海刚.大数据系统综述[J].中国科学:信息科学,2015,第45卷 第一期:1-44
[4]http://hadoop.apache.org/
[5]赵晟,姜进磊.典型大数据计算框架分析[J].中兴通讯技术.2016.4
[6]陈丽.数据挖掘中聚类算法研究[D].2007
[7]Bijne ET.Cluster analysis[M].Netherlands:Tiberg University Press,1973
[8]Everitt B.Cluster analysis[M].London:Heinemann Educational Books Ltd.,1974
[9]Jiawei Han,Micheline Kamber.数据挖掘概念与技术[M].范明,孟小峰等译.北京:机械工业出版社,2001
[10]J.B.MacQueen.Some Methods for classification and Analysis of Multivariate Observations.Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability.Berkeley,University of California Press,1:281-297
Big Data;Intelligent Recommendation;Clustering
Application of User Portrait and Intelligent Recommendation Based on Big Data Technology and K-means
LI Bing1,WANG Yue1,LIU Yong-xiang2
(1.China National Tobacco Corp.Beijing Corp.,Beijing 100122;2.INSPUR Co.,Ltd.,Jinan250000)
1007-1423(2016)24-0011-05DOI:10.3969/j.issn.1007-1423.2016.24.03
李冰(1984-),男,北京市人,博士,工程师,研究方向为云计算与大数据
王悦(1986-),男,北京人,本科,工程师,研究方向为系统集成与大规模分布式系统
刘永祥(1974-),男,湖南人,本科,高级工程师,研究方向为烟草数据分析
2016-08-15
2016-08-20
随着中国烟草行业市场化取向改革日益深入以及计算机技术的快速发展,如何利用新技术更准确地洞察市场、了解卷烟零售客户销售特征、针对性的为零售户提供适销对路的卷烟商品成为行业内所共同关注的问题。探索一种基于大数据技术及K-means算法的卷烟零售户特征画像,并在此基础上实现对零售户订货的智能推荐。
大数据;智能推荐;聚类
With the proceeding of China tobacco industry market oriented reform and the development of computing technology,departments of tobacco sales and marketing pay more and more attention to how to use new techniques to obtain accurate information of the market,understanding the sales characteristics of tobacco retailer and provide marketable tobacco goods for the retailer.Explores a kind of tobacco retailer user portrait based on Big Data technology and K-means clustering algorithm,and provides the application of intelligent recommendation for tobacco ordering.
猜你喜欢
今日农业(2022年1期)2022-11-16
现代装饰(2022年3期)2022-07-05
物流技术与应用(2022年5期)2022-06-17
当代陕西(2021年21期)2022-01-19
消费导刊(2021年19期)2021-03-08
消费导刊(2021年1期)2021-01-29
非公有制企业党建(2020年8期)2020-08-27
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
互联网天地(2016年1期)2016-05-04
