
基于预判筛选的高效关联规则挖掘算法
2016-10-14 01:32赵学健孙知信
电子与信息学报 2016年7期
赵学健 孙知信 袁 源
基于预判筛选的高效关联规则挖掘算法
赵学健*①②③孙知信①②袁 源③
①(南京邮电大学物联网学院 南京 210003),②(南京邮电大学江苏省通信与网络技术工程研究中心 南京 210003),③(江苏省邮电规划设计院有限责任公司 南京 210006)
关联规则分析作为数据挖掘的主要手段之一,在发现海量事务数据中隐含的有价值信息方面具有重要的作用。该文针对Apriori 算法的固有缺陷,提出了AWP (Apriori With Prejudging) 算法。该算法在Apriori 算法连接、剪枝的基础上,添加了预判筛选的步骤,使用先验概率对候选频繁项集集合进行缩减优化,并且引入阻尼因子和补偿因子对预判筛选产生的误差进行修正,简化了挖掘频繁项集的操作过程。实验证明AWP算法能够有效减少扫描数据库的次数,降低算法的运行时间。
数据挖掘;关联规则;事务数据库;预判筛选;Apriori
1 引言
在大数据技术发展如火如荼的今天,人们逐渐意识到数据即是财富,尤其是对商业数据的分析更具有巨大的实用价值。关联规则分析作为数据挖掘的主要手段之一,是数据挖掘技术中不可或缺的一个重要组成部分,主要用于发现大型事务数据库中隐含的有价值的令人感兴趣的联系及规则[1,2]。因此,对关联规则算法的研究具有非常重要的意义。
早在1993年,IBM的计算机科学家Agrawal等人在顾客交易数据库中发现了顾客在购买商品时的购买规律,提出了事务之间的相关性模式,即最初的关联规则。关联规则通常是一种不复杂但实用性却很高的规则。通过关联规则分析,我们可以将事务项集与项集之间的关系挖掘出来。关联规则分析最典型的应用是购物篮数据分析,比如经典的{啤酒}→{尿布}规则。除了可以应用于购物篮数据之外,关联规则分析在其它领域的应用也十分广泛,如电子商务个性化推荐,金融服务,广告策划,生物信息学及科学数据分析等。比如说在电子商务个性化推荐中,关联规则可以帮助电子商务网站向具有相似消费行为的顾客进行一些他们可能感兴趣的商品推荐,这样有助于电子商务网站提升用户体验,增加盈利等。
关联规则分析算法较多,其中最经典实用性最好的是Apriori算法及其改进算法。Apriori算法是由文献[6]于1994 年提出的第1个关联规则算法,应用广泛,该算法通过重复循环执行连接、剪枝生成频繁项目集,从而建立关联规则。基于Apriori算法,文献[7]提出了Apriori-TFP算法,该算法在关联规则挖掘过程中,将原始数据进行预处理并存储在局部支持树中,最后生成关联规则。该算法通过有效的预处理,降低了关联规则挖掘的时间,但是需要扫描数据库的次数仍然较多。文献[8]提出了GP-Apriori算法,GP-Apriori算法采用图形处理器(Graphical Processing Unit, GPU)进行并行化的支持度计数,并将垂直交易列存储为线性有序阵列。GPU通过遍历该有序阵列,并执行按位交叉实现支持度计算,并将结果复制回内存。与传统CPU上运行的Apriori算法相比,GP-Apriori算法由于采用了先进的GPU提高了运行速率,但是复杂性反而有所增长。文献[9]提出了Apriori的改进算法(Apriori Mend Algorithm)。该算法使用哈希函数生成项目集,用户必须指定最小支持度以删除不需要的项集。该算法具有比传统Apriori算法更好的效率,但是执行时间有所增加。文献[10]基于MapReduce框架实现了Apriori算法的并行化。该算法在处理海量数据集时具有良好的可扩展性和效率,但是该算法需要强大的计算和存储能力支撑,通常运行在集群环境中。文献[11]尝试将Apriori算法应用于多维数据分析,探讨了在多维数据中建立关联规则更加具体有效的方法。文献[12]对Apriori算法进行了改进,引入了事务尺寸和事务规模的概念以消除非重要项目的影响。文献[13]提出了一种基于矩阵的Apriori算法,该算法通过矩阵有效地表示数据库的各种操作,并用基于矩阵的AND操作得到最大的频繁项目集。算法虽然大大减少了扫描数据库的次数,但是空间复杂度较高。文献[14]对Apriori算法进行了改进,提出了M-Apriori算法,该算法在寻找频繁项目集的过程中,对包含项集的事务集合进行记录,在验证项集是否频繁时,不再扫描整个数据库,而是仅需扫描数据库中部分事务,从而提高时间效率。文献[15]提出了一种Map-Reduce框架下的分布式幂集Apriori算法。实验结果表明,该算法并行运算能力强,在低虚警率和漏检率的情况下,具有较好的检测率。文献[16]提出一种基于Apriori的改进算法,通过减少候选2项集的剪枝操作从而提高效率,但实验结果表明算法性能提升非常有限。
上述基于Apriori的改进算法大多继承了Apriori算法需要大量扫描数据库和占用大量内存的缺点[17]。本文针对经典 Apriori 算法的固有缺陷,提出了AWP(Apriori With Prejudging) 算法,该算法在Apriori算法连接、剪枝的基础上,添加了预判筛选的步骤,通过使用先验概率对候选频繁项集集合进行缩减优化,并且引入阻尼因子和补偿因子对预判筛选产生的误差进行修正,以减少扫描数据库的次数,降低算法的运算时间,提高算法的运算效率。
2 AWP算法
2.1 理论基础
证明 因为

故

则有
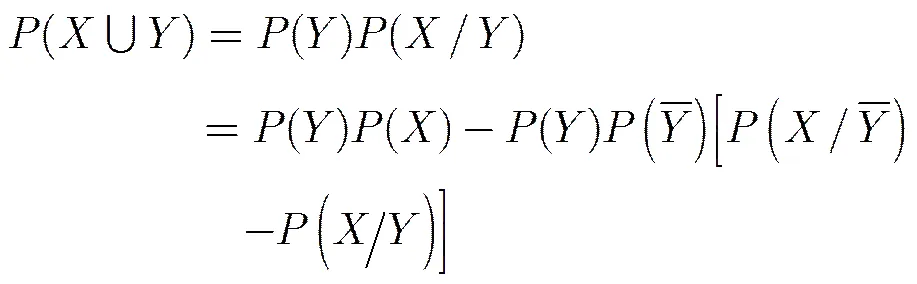
证毕
AWP算法尝试在连接、剪枝步骤后,通过计算先验概率的方法对候选频繁项集集合中的项目集进行缩减优化,而不是直接通过扫描数据库进行判断,从而减少扫描数据库的次数,降低算法运行时间,提高算法运算效率。由定理1可知,若直接采用独立事件概率公式对的概率进行计算,在预判筛选过程中难免出现虚警(把非频繁项目集视为频繁项目集)和漏检(把频繁项目集视为非频繁项目集)的情况。因此,AWP算法引入阻尼因子和补偿因子对预判筛选产生的虚警率和漏检率进行控制。若阻尼因子和补偿因子严格根据定理1进行设置,可保证虚警率和漏检率均为0,但是算法性能会受到严重影响。为追求更佳的算法性能,并且保证一定的虚警率和漏检率的前提下,算法将采用实验验证的方法对阻尼因子和补偿因子进行了设置。
2.2 算法描述
AWP算法为实现关联规则的挖掘,同样包含两个步骤:(1)找出所有的频繁项集;(2)由频繁项集产生强规则。
为了解决Apriori算法存在的技术问题,精简候选项目集中的元素,简化算法挖掘频繁项集以及规则的操作过程,减少扫描数据库的次数,AWP算法根据定理1在Apriori算法连接、剪枝步骤后添加了预判筛选环节,算法找出所有频繁项集的过程如下:
步骤3 利用Apriori性质[5](任一频繁项集的所有非空子集也必须是频繁的,如果某个候选的非空子集不是频繁的,那么该候选肯定不是频繁的)对候选项集集合进行剪枝。剪枝过程如下:对候选项集集合的成员,的所有非空子集的支持度进行判断,若该成员存在支持度小于预设的最小支持度的非空子集,根据Apriori性质可判定该成员不是频繁项目集,将其从中删除;反之,将该成员保留在候选项集集合中;
步骤6 重复执行上述步骤2~步骤5,直到不能发现更大的频繁项目集为止;
AWP算法由频繁项集产生强规则的过程与Apriori算法类似。若最终AWP算法获得的频繁项目集为,则可产生关联规则,为频繁项目集集合中任意成员的非空子集,为的补集,即,且,其中为频繁项目集集合包含的成员数目。比如说若集合是频繁项目集集合的成员,则可产生如下关联规则:,,,,,。
3 实验分析
本文采用8组事务数据库对AWP算法的性能进行了分析,8组数据库分别包含5×102, 1×103,2×103, 5×103, 8×103, 1×104, 2×104, 4×104个事务。由于AWP算法增加了预判筛选的步骤,该步骤通过独立事件概率公式计算候选项集集合中成员,的先验概率,以减少扫描数据库的次数,这容易导致虚警和漏检的情况发生。为此,AWP算法在预判筛选步骤中引入了阻尼因子和补偿因子两个参数,通过合理设置阻尼因子和补偿因子可有效降低虚警率和漏检率。根据虚警率和漏检率的概念可知,所谓虚警是指本不是频繁项目集却纳入到频繁项目集的范畴;所谓漏检是指本应是频繁项目集却没有纳入到频繁项目集的范畴。在现实情况中,为了尽可能地挖掘出所有的强关联规则,对算法的漏检率要求应该更加严格。因此,本文中要求算法的虚警率低于5%,而漏检率低于2%。在分析AWP算法性能之前,首先通过实验对阻尼因子和补偿因子的取值进行分析。
表1 阻尼因子-虚警率分析表()

表1 阻尼因子-虚警率分析表()
事务数虚警率(%) =0.5=0.4=0.3=0.2=0.1 5×1023.934.575.216.858.76 5×1033.594.245.016.268.13 1×1043.223.884.315.446.59 2×1042.743.313.674.915.63 4×1041.562.653.113.754.76
表2 补偿因子-漏检率分析表()

表2 补偿因子-漏检率分析表()
事务数漏检率(%) =0.25=0.20=0.15=0.10=0.05 5×1020.861.342.894.528.51 5×1030.731.151.922.875.38 1×1040.550.820.971.944.63 2×1040.390.660.841.373.25 4×1040.170.490.670.981.46
在确定了算法的阻尼因子和补偿因子分别如式(4)和式(5)所示后,第2组实验对算法的运行时间随事务数的变化情况进行了分析。在最小支持度设置为0.04时,算法运行时间随事务数变化曲线如图1所示。由于数据库包含的事务数变化较大,因此图1横坐标采用了对数坐标轴,纵坐标依然为普通坐标轴。由图1可以看出,随着数据库中事务数的增多,Apriori算法、M-Apriori算法和AWP算法的运行时间均逐渐增大。但是,AWP算法相对于Apriori算法和M-Apriori算法来说,运行时间得到了大幅缩短。当事务数据库包含4×104条记录时,AWP算法的运行时间为34.48 s,比Apriori算法和M-Apriori分别降低48.9%和17.1%。

图1 算法运行时间随事务数变化曲线

图2 扫描数据库次数随事务数变化曲线
最后一组实验,针对事务数为104的数据库,分析了算法运行时间随最小支持度的变化情况,如图3所示。由图可以看出,3种算法的运行时间均随最小支持度的增大而减小。这是因为当最小支持度增大时,候选项目集集合中的成员逐渐减少,因此扫描数据库进行比较的次数减少,运行时间自然降低。在最小支持度相同的情况下,AWP算法比Apriori算法和M-Apriori算法降低了运行时间,并且当最小支持度越小的时候,效果愈发明显。

图3 算法运行时间随最小支持度变化曲线
4 结论
[1] SINGLA S and MALIK A. Survey on various improved Apriori algorithms[J]., 2014, 3(11): 8528-8531. doi: 10.17148/ijarcce.2014.31139.
[2] MINAL G I and SURYAVANSHI N Y. Association rule mining using improved Apriori algorithm[J]., 2015, 112(4): 37-42.
[3] RAJESWARI K. Improved Apriori algorithmA comparative study using different objective measures[J].2015, 6(3): 3185-3191.
[4] ACHAR A, LAXMAN S, and SASTRY P S. A unified view of the Apriori-based algorithms for frequent episode discovery[J].&2012, 31(2): 223-250. doi: 10.1007/s10115-011-0408-2.
[5] 李鹏, 于晓洋, 孙渤禹. 基于用户群组行为分析的视频推荐方法研究[J]. 电子与信息学报, 2014, 36(6): 1484-1491. doi: 10.3724/SP.J.1146.2013.01225.
LI Peng, YU Xiaoyang, and SUN Boyu. Video recommendation method based on group user behavior analysis[J].&, 2014, 36(6): 1484-1491. doi: 10.3724/SP.J.1146.2013.01225.
[6] AGRAWAL R and SRIKANT R. Fast algorithms for mining association rules[C]. VLDB’94 Proceedings of the 20th International Conference on Very Large Data Bases, San Francisco, CA, USA, 1994: 487- 499.
[7] YANG Z, TANG W, SHINTEMIROV A,Association rule mining-based dissolved gas analysis for fault diagnosis of power transformers[J].,,:, 2009, 39(6): 597-610. doi: 10.1109/TSMCC.2009.2021989.
[8] ZHANG F, ZHANG Y, and BAKOS J D. Gpapriori: Gpu-accelerated frequent itemset mining[C]. 2011 IEEE International Conference on Cluster Computing, Austin, TX, USA, 2011: 590-594. doi: 10.1109/CLUSTER.2011.61.
[9] ANGELINE M D and JAMES S P. Association rule generation using Apriori mend algorithm for student’s placement[J].2012, 2(1): 78-86.
[10] LI N, ZENG L, HE Q,Parallel implementation of Apriori algorithm based on MapReduce[C]. 13th ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel Distributed Computing (SNPD), Kyoto, Japan, 2012: 236-241. doi: 10.1109/ SNPD. 2012.31.
[11] SULIANTA F, LIONG TH, and ATASTINA I. Mining food industry’s multidimensional data to produce association rules using Apriori algorithm as a basis of business strategy[C]. 2013 International Conference of Information and Communication Technology (ICoICT), Bandung, Indonisia, 2013: 176-181. doi: 10.1109/ICoICT.2013.6574569.
[12] ABAYA S A. Association rule mining based on Apriori algorithm in minimizing candidate generation[J].&, 2012, 3(7): 1-4.
[13] WANG Feng and LI Yonghua. An improved Apriori algorithm based on the matrix[C]. Proceedings of 2008 International Seminar on Future BioMedical Information Engineering, Wuhan, China, 2008: 152-155. doi: 10.1109/ FBIE.2008.80.
[14] MAOLEGI M A and ARKOK B. An improved Apriori algorithm for association rules[J]., 2014, 3(1): 21-29. doi: 10.5121/ijnlc.2014.3103.
[15] 葛琳, 季新生, 江涛. 基于关联规则的网络信息内容安全事件发现及其Map-Reduce实现[J]. 电子与信息学报, 2014, 36(8): 1831-1837. doi: 10.3724/SP.J.1146.2013.01272.
GE Lin, JI Xinsheng, and JIANG Tao. Discovery of network information content security incidents based on association rules and its implementation in Map-Reduce[J].&, 2014, 36(8): 1831-1837. doi: 10.3724/SP.J.1146.2013.01272.
[16] TANK D M. Improved Apriori algorithm for mining association rules[J]., 2014, 6(7): 15-23. doi: 10.5815/ijitcs.2014.07.03.
[17] RAO S and GUPTA R. Implementing improved algorithm over Apriori data mining association rule algorithm[J]., 2012, 34(3): 489-493.
An Efficient Association Rule Mining Algorithm Based on Prejudging and Screening
ZHAO Xuejian①②③SUN Zhixin①②YUAN Yuan③
①(,,210003,),②(,,210003,),③(&.,210006,)
Association rule analysis, as one of the significant means of data mining, plays an important role in discovering the implicit knowledge in massive transaction data. To overcome the inherent defects of the classic Apriori algorithm, this paper proposes Apriori With Prejudging (AWP) algorithm. AWP algorithm adds a pre-judging procedure on the basis of the self-join and pruning progress in Apriori algorithm. It reduces and optimizes the-frequent item sets using prior probability. In addition, the damping factor and compensating factor are introduced to revise the deviation caused by pre-judging. AWP algorithm simplifies the operation process of mining frequent item sets. Experimental results show that the improvement measures can effectively reduce the number of scanning databases and reduce the running time of the algorithm.
Data mining; Association rules; Transaction database; Prejudging; Apriori
TP391
A
1009-5896(2016)07-1654-06
10.11999/JEIT151107
2015-09-29;改回日期:2016-02-26;网络出版:2016-04-14
赵学健 zhaoxj@njupt.edu.cn
国家自然科学基金(61373135, 61401225, 61502252, 61201160),江苏省基础研究计划(自然科学基金)(BK20140883, BK20140894, BK20131377),中国博士后科学基金(2015M581844), 江苏省博士后科研资助计划项目(1501125B),南京邮电大学校级科研基金(NY214101, NY215147)
The National Natural Science Foundation of China (61373135, 61401225, 61502252, 61201160), Natural Science Foundation of Jiangsu Province of China (BK20140883, BK20140894, BK20131377), China Postdoctoral Science Foundation Funded Project (2015M581844), Jiangsu Planned Projects for Postdoctoral Research Funds (1501125B), NUPTSF (NY214101, NY215147)
赵学健: 男,1982年生,副教授,研究方向为数据挖掘、无线传感器网络.
孙知信: 男,1964年生,教授,研究方向为大数据、物联网.
袁 源: 女,1976年生,教授级工程师,研究方向为大数据、电信网络.
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
进出口经理人(2021年8期)2021-02-12
出版人(2020年5期)2020-11-17
河南水利年鉴(2020年0期)2020-06-09
今日农业(2019年14期)2019-01-04
天津科技大学学报(2018年4期)2018-08-22
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
中国卫生(2014年3期)2014-11-12
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
