
语言构造机制的逻辑语义学研究
2016-10-09 06:05邹崇理
安徽大学学报(哲学社会科学版) 2016年5期
邹崇理
语言构造机制的逻辑语义学研究
邹崇理
自然语言的计算机信息处理要求电脑对人脑构造或理解语言的机制进行模拟,这种模拟首先需要逻辑语义学对语言构造机制的先期研究。简言之,语言构造机制显示出两个特征:1.有穷多的词条作为出发点;2.依据有穷多规则去构造和理解无穷多的语句。多年来,逻辑语义学各分支不同程度地描述了语言构造机制的两个特征,但对其中特征1的刻画却不充分,而语言学对此却有不俗的表现。于是逻辑语义学和语言学形成互补局面,“互补”产生了组合范畴语法CCG。本文揭示了CCG对语言构造机制两个特征的兼容并举,从而展示逻辑语义学在理论上对电脑模拟人脑构造语言机制工作的指导作用。
语言构造机制;逻辑语义学;组合范畴语法CCG
2016年是人工智能正式提出60周年的日子。新近,AlphaGo与韩国围棋高手李世石的对局大战引起学界、产业界和公众的极大关注,结果人以1:4告负。由此引起思考热议的话题是:电脑的智力是否已超过人脑?人类是否将被机器统治?
电脑的博弈功能是对人脑博弈机制的模拟,AlphaGo在多大程度上模拟了人脑的围棋博弈能力?从逻辑思维认知科学角度看,AlphaGo的模拟虽然取得很大成功,但弱点和不足也是显然的。
AlphaGo的工作原理分为线下学习和在线对弈。线下学习显示AlphaGo对人脑学习能力的模拟。AlphaGo利用3万多专业棋手对局的棋谱来训练策略网络和快速走棋策略,此外还通过大量的自我对弈,产生并存储了3000万盘棋局,用作训练其估值网络。与之比较,人脑记忆的对局数量远远少于机器,人记不了多少完整对局,仅仅掌握布局阶段的各种定式和收官阶段的计算模式,也不过成百上千。其次,从AlphaGo在线对弈的5步流程中看出它对人脑博弈能力的模拟:人脑下棋的思考模式就是自己跟自己下棋,在思考下一步怎么走时,在头脑里设置黑白两方你一步我一步的对弈。与此类似,AlphaGo在设置的走棋过程中不断进行形势判断,给出胜负概率的评估。线下学习和在线对弈的原理表明AlphaGo模拟人脑博弈机制获得巨大成功。
AlphaGo具有超快的计算速度,其策略网络的走子速度是3毫秒一步,而快速走棋策略能达到2微秒的走子速度,又提高了1000多倍。人类的走棋速度比机器慢很多,通常的快棋比赛限于30秒一步棋。跟“大数据云计算”时代计算机的存储容量、运算速度和计算准确性相比较,人脑差之甚远!
人脑能够与各方面处于强势的机器对决,一定还有独特的机制机器暂时没有模拟到。我们从AlphaGo的在线对弈流程中看出其弱点:针对当前局面,其策略网络处理黑白对弈下一步的多种可能的时候存在一定困难。由于自我对弈至局部终结的步数多,搜索下去获得的可能数目就非常大。搜索空间急剧加大,得到的解的精度就会降低。而人脑的思考则通过选择舍弃绝大部分可能的着法而缩小搜索空间,可以集中思考价值最高、基于全局意识关联多个局部棋局的着法。人脑具有独特的选择、关联和全局意识能力,在无穷无尽变化多端的中盘战斗中发挥了巨大作用。人脑的这个机制机器没有完全模拟到。
AlphaGo的弱点导致:面临多个棋局的交叉关联时,容易出错(这需要全局意识的关联思维);面对复杂的打劫局面也感到困惑(棋局的关联难度进一步加大)。一些人工智能的专家断言,AlphaGo没有完全攻克围棋这个难题,并没有具备真正的思维能力。
回到正题,计算机人工智能时代还有另一个重要的任务就是自然语言的计算机信息处理,这个任务也应该受到关注。自然语言的计算机信息处理的情况是类似的,机器需要模拟人脑构造和理解语言的机制。
人工智能提出60年来,计算机对人脑构造语言机制的模拟取得很大进展,但这种模拟也存在弱点。如2015年北京大学某篇博士论文认为*秦一男:《一种英文句法结构解析的新方法》,北京:北京大学,2015年。,对下述英文复杂句:
(1)That men who were appointed didn’t bother the liberals wasn’t remarked upon by the press.
(2)That everything you learned about America’s history is wrong is known to the public.
当今计算机界公认的两种世界上非常先进的自然语言句法结构的解析装置,即伯克利解析器(Berkeley Parser)和斯坦福解析器(Stanford Parser),直到2015年1月25日18时36分,给出的仍然是错误的分析。就例句(1)而言,其错误分析是:
①That men didn’t bother
②who were appointed
③the liberals wasn’t remarked upon by the press
①是全句的核心,核心的主谓搭配。③是①的宾语从句。②是定语从句,修饰“men”。“That”是限定词,修饰“men”。而例句(1)的正确分析是:把握住“That”导引的主语从句, “That men who were appointed didn’t bother the liberals”是全句的主语从句,“wasn’t remarked upon by the press”才是全句的中心谓语。
机器对人脑关于这种语言现象的构造机制的模拟不能令人满意。这类语句的构造生成规则似乎应从主语从句的循环镶嵌机制去考虑:
NP VP
That NP VP VP
That that NP VP VP VP
上述主语子句的循环镶嵌现象是人脑构造语言机制的体现。自然语言中还有多重宾语从句的镶嵌和多重定语从句的叠置也体现了这样的机制,如:
(3)张三知道李四知道张三考上大学。
(4)The man such that he loves a woman such that she hates a boy chants.
(5)Mary likes a man such that he has a son such that he admires a girl such that she hates a boss.
说到自然语言的循环镶嵌机制,就使人联想到上世纪发起语言学界“哥白尼式革命”的美国语言学大师乔姆斯基(N. Chomsky)的著名思想:人脑先天具有构造生成语言的创造能力。德国学者洪堡特(W. Humboldt)早就认为语言绝不是产品,而是一种创造性活动。语言实际上是心智不断重复的活动,人类语言知识的本质就是语言知识如何构成的问题,其核心是有限手段的无限使用。
人脑构造(表述)和理解语言的机制可以概括成两个特征:
1.有穷多的词条作为出发点;
2.依据有穷多规则去构造和理解无穷多的语句。
人脑具有构造和理解自然语言的机制,人就能够构造表述从来没有见过的句子,也可以理解从来没有听过的句子,人脑能够构造或理解的句子是无穷多的。要想机器模拟人脑构造理解自然语言的机制,首先需要理论上的先期研究。这就是理论语言学(包括计算语言学)和逻辑语义学的任务。
逻辑语义学探索人脑构造语言机制的特征,其价值作用在于帮助机器更好地模拟人脑的语言机制,使其能够正确识别理解自然语言中诸如(1)—(5)那样的复杂句子。简言之,针对语言构造机制的两个特征,逻辑语义学从20世纪70年代开始,进行了持久深入的研究。我们在最早的蒙太格语法的PTQ语句系统、Barwise和Cooper确立的广义量词理论的语句系统、Kamp等构建的DRT语句系统以及范畴语法的Lambek演算那里,都可以看到对语言构造机制两个特征的刻画,语句系统中的词库表现特征1,而语句系统中的规则揭示特征2。总括如下:
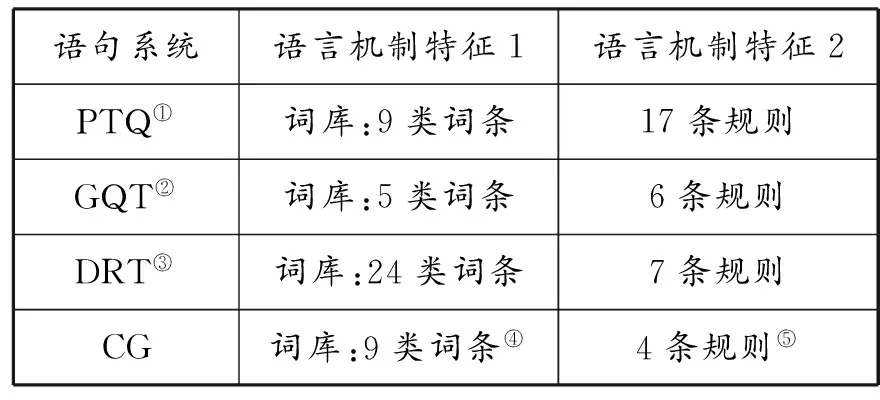
表1 逻辑语义学对语言构造机制两个特征的刻画
①MG的语句系统限于处理自然语言量化式、命题态度句和内涵动词句, 参见R. Montague, The Proper Treatment of Quantification in Ordinary English, ed. by R. Thomason,FormalPhilosophy, New Haven: Yale University Press, 1974, pp. 247-270。
②GQT的语句系统仅限于描述自然语言的量化表达式,参见J. Barwise, R. Cooper, Generalized Quantifiers and Natural Language,LinguisticsandPhilosophy, vol. 4, no. 2(1981), pp. 159-219。
③DRT的语句系统仅关注照应回指现象,涉及名词的单数复数、代词的性和数,参见H. Kamp, U. Reyle,FromDiscoursetoLogic, Dordrecht: Kluwer, 1993, pp. 53-56。
④兰贝克演算最初的论文列出9类词条作为指派范畴的词库示例,参见J. Lambek, The Mathematics of Sentence Structure,AmericanMathematicalMonthly, vol. 65, no. 3(1958), pp. 154-170。
⑤类型逻辑语义学作为范畴语法的延伸,从兰贝克演算的定理选出4条作为推演规则,参见B. Carpenter,Type-LogicalSemantics, Cambridge/London: MIT Press, 1997, pp. 138-139。
我们以逻辑语义学的奠基理论蒙太格语法MG为例,按照MG为刻画语言机制特征2而设立的规则,循环镶嵌句(5)的句法构造和逻辑语义分别为:
[Mary [likes [a [man such that [he [has [a [son such that [he[admires[a [girl such that [she [hates [a [boss]]]]]]]]]]]]]]]].
应该指出,范畴语法CG与前面几种语句系统最大的不同是:用逻辑系统提供的定理替代揭示语言构造机制特征2所需要的自然语言句法规则,仅仅4条定理对应的规则,就可以据此构造生成无穷多句子,范畴语法“极为深刻”地揭示了自然语言所谓“有限手段的无限使用”这个机制。范畴语法CG还最早开启了逻辑语义学面向自然语言计算机处理的研究思路。20世纪30—40年代,波兰逻辑学家Ajduciewicz提出了CG,50年代计算语言学之父Bar-Hillel 和数学家Lambek使CG同机器翻译领域关联起来,80年代至今,CG的新版本范畴类型逻辑CTL持续发展。
CTL不仅是分析自然语言的句法语义的生成过程的工具,更重要的是,CTL作为传承延伸逻辑理性主义精神的产物,从理论角度深入讨论逻辑工具本身的性质。如CTL的公理表述解决系统的可靠性和完全性,CTL的Gentzen表述解决系统的可判定性,CTL的ND表述使得CTL的推演和证明网技术关联起来而获得计算机的实现,等等。
人脑关于语言构造机制的两个特征是密不可分的,但科学研究却可以对此抽象取舍。从某种角度看,通常语言学和基于统计的计算语言学大都擅长并偏重语言构造机制特征1的研究。人类要使用语言,必须掌握构造语言的原子材料——单词或词条,这是我们学习一门语言首先要懂得的知识。一门语言单词常用的有几千条,总数是几万乃至几十万条,语言学在浩如烟海的文献中搜集这些词条,统计它们出现的频率,归纳它们的各种用法含义,编撰各种各样的词典。而基于统计的自然语言计算机处理系统则建立了海量的大型语料数据库。
通常语言学的研究对掌握语言机制来说是必要且重要的工作,但是其对语言构造机制特征2的研究显示出一定程度的缺失。由于句子的数量是无穷多的,句子的意义是开放的,所以无法编撰囊括所有句子意义的“句典”。句子甚至短语的意义都不是给定的,而是通过组合推演获得的。怎样组合推演?这方面恰构成通常的语言学研究的软肋。
尽管如此,比较语言学视角研究取得的成果,我们看出逻辑语义学研究语言机制的短板,即对特征1的研究很不充分。自然语言中词条的具体使用丰富多彩,多义词歧义词比比皆是。逻辑语义学构建的语句系统中的小小词库仅仅是“实验田”性质的样本,无法满足语言学和计算机自然语言系统大规模处理真实文本的需求。
如PTQ语句系统的微型词库:
BIV= {run, walk, talk, rise, change}
BT= {John, Mary, Bill, ninety, he0, he1,...}
BTV= {find, lose, eat, love, date, be, seek, conceive}
BIV/IV= {rapidly, slowly, voluntarily, allegedly}
BCN= {man, woman, park, fish, pen, unicorn, price, temperature}
Bt/ t= {necessarily}
B(IV/IV)/T= {in, about}
BIV/T= {believe that, assert that}
BIV//IV= {try to, wish to}
Be= Bt= Ø
该词库仅仅包含为数很少的9类语词,且一词条只能归入一类,这远远不能覆盖自然语言丰富多样的词条用法。
针对上述不足,逻辑语义学需要弥补调整。擅长描述语言构造机制特征1的语言学研究与善于揭示语言构造机制特征2的逻辑语义学研究是可以互补的。“互补”催生了逻辑语义学的新模式组合范畴语法CCG(Combinatory Categorial Grammar)。
CCG是作为逻辑语义学重要理论CG的另一新版本。为弥补以往逻辑语义学研究的不足,CCG在探索语言机制特征1上下了不少的工夫。不仅如此,CCG还延续逻辑语义学的演绎精神,较成功地揭示了语言机制的特征2。CCG目前在自然语言的计算机信息处理领域,尤其在国外的这一领域备受关注。如国外的宾州CCG库*参见M. Steedman, CCGbank: User’s Manual, Department of Computer & Information Science Technical Reports (CIS), 2005。和国内的清华CCG库*参见宋彦、黄昌宁等《中文CCG树库的构建》,《中文信息学报》2012年第3期。以及笔者主持的国家重大课题的成果社科CCG库*参见2016年国家社科基金重大课题“自然语言信息处理的逻辑语义学研究”结项报告附录。的情况分别是:

宾州英文CCG库清华中文CCG库社科中文CCG库特征175669词条(929552词例)23641词条(约35万词例)46085词条(722790词例)特征248934个语句32737个句子25694个句子
宾州英文CCG库提取有75,669个词条和48,934个语句,涉及929,552个词例。清华中文CCG库词条和句子的提取来源于包含文学、学术、新闻、应用四大体裁的平衡语料,尽可
能多地覆盖了汉语的各种语言现象*宾州英语CCG库和清华汉语CCG库分别生成的3万~4万语句是转换在先的形式语言学分析树库获得的语句“格式”,这种格式可以用于语料库外的句例分析,其句例的数量是开放的。。一方面,CCG的词汇主义思路强调语言构造机制特征1的描述,弥补了大多数逻辑语义学分支如范畴类型逻辑CTL在这方面的短板。在掌握
大规模真实文本的基础上提取了作为语言构造出发点的有穷多词条,确定这些词条在各种语境下的多种多样的范畴指派。
宾州英语CCG词库 :
清华汉语CCG词库:
社科CCG汉语词库:
CCG的词库要描述自然语言词条的多种用法,挑战逻辑语义学的“一词对应一范畴”的传统做法,采用从词条到词例的多范畴指派方法。社科CCG词库的工作表明,对应范畴数量最多的前10名词条(包括辅助符号)是:

表2 社科CCG词库对应范畴数量前10名的词条
在社科汉语CCG词库中,有些词条对应的可能范畴多达上百个以上,如“的”词条。对应数十个范畴的词也非常普遍,如“在”“是”和“有”等词条。
清华CCG词库采用从词条到词例的多范畴指派方法,对汉语词条“学”就有7种不同的范畴指派:
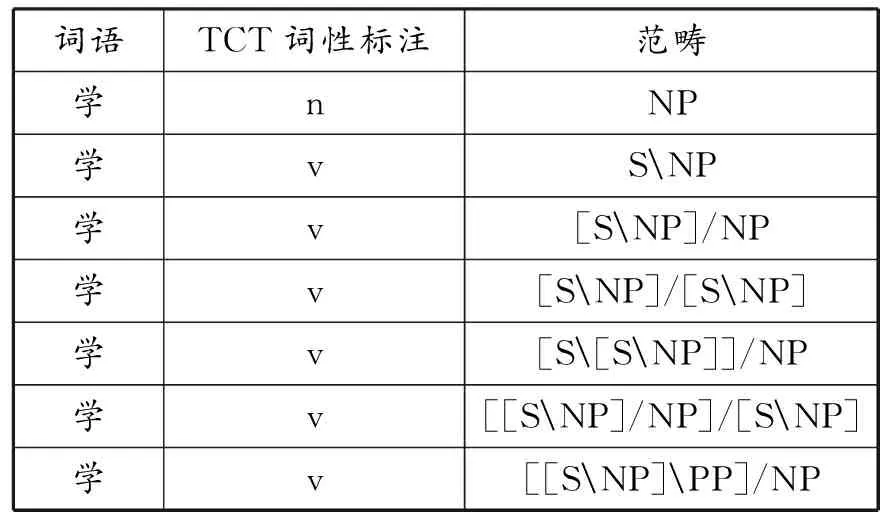
表3 清华CCG词库词条“学”的7种范畴指派
按照逻辑语义学的传统做法,“学”实际上被分别归入7个以范畴标记的基本语词类:
BNP= {..., 学, ...}
BSNP= {..., 学, ...}
B(SNP)/NP= {..., 学, ...}
B(SNP)/(SNP)= {..., 学, ...}
B(S(SNP))/NP= {..., 学, ...}
B((SNP)/NP)/(SNP)= {..., 学, ...}
B((SNP)PP)/NP= {..., 学, ...}
宋彦和黄昌宁等学者认为:在清华中文CCG词库中, 一共有10个原子范畴, 包括M (量词)、MP (数量短语)、NP(名词及名词短语)、SP (方位词及方位短语)、TP (时间短语)、PP (介词短语)、S (句子)等等,在此基础上,一共可获得763个不同的范畴类型。这样,清华中文CCG词库中就有763个以范畴标记的基本语词类:B1, B2, …… B762, B763。比较蒙太格语法的PTQ语句系统的9个基本语词类构成的小词库,CCG的词库非常大,可以覆盖自然语言词条丰富多样的用法。
另一方面,CCG基于规则的思路关注自然语言构造机制的特征2的描述。CCG的核心是一系列的函子范畴的复合规则,这些规则对应范畴逻辑CTL的结构公设,是CTL倡导的函项运算思想的延续,是CTL逻辑定理的延伸。以下是CCG的部分规则:
(1)组合规则
(2)类型提升规则
(3) 置换规则
除了规则的一般模式外,清华中文CCG库还有近1600规则例,远比PTQ系统的17条句法规则多出许多,足以覆盖汉语千姿百态的句法构造现象。以下是清华中文树库的一个语句推演树:

图1清华中文CCG库的语句推演树
就上述语句分析树而言,使用了8个规则例。
多模态 CCG 的函子范畴的组合规则对应混合CTL 的结构公设,即由混合CTL的左右结合公设可推出多模态CCG的前向组合规则>B和后向组合规则 以下是推出过程: 从CTL那里汲取了逻辑的精神,CCG也就能够处理涉及语言构造机制特征2的循环镶嵌句。如可以生成循环镶嵌例句(3),其推演为: 更重要的是,CCG的规则还对自然语言形式理论的“硬核”问题,如语义的形式化进行探索。在CCG看来,所有的句法规则都是一定范围内语义运算的透明版本。这一原则来自于范畴语法所具备的句法与语义并行推演这一特点。在MG时期范畴与类型之间的对应关系已经提及,此后van Benthem基于范畴与类型之间的对应,为范畴语法增添了配有语义表达的版本,由于λ-演算的引入,vB-演算就给范畴语法的句法和语义的并行推演提供了理论基础。匹配了语义表达的CCG规则就是: 表4 CCG规则匹配语义的形式化描述 据此英文语句“John met and might married Mary”的句法语义并行推演就是: 从配备语义的函项应用规则可以看出,句法和语义方面同时进行了组合性的运算。CCG 继承了范畴语法中句法与语义之间的透明接口,句法范畴的运算同时匹配λ-演算,每一个范畴都对应一个λ-词项,范畴表示的是句法,λ-词项表示的是语义。 由于CCG对语言构造机制两个特征的刻画比较充分,所以基于CCG设计的计算机分析器在诸多形式语言学理论自动分析中是速度最快的。“在2009年约翰霍普金斯大学举行的夏季研讨班上,研究人员通过采用优化的句法分析算法,使CCG句法分析在维基百科语料上达到每秒超过100句的分析速度”*参见宋彦、黄昌宁等《中文CCG树库的构建》,《中文信息学报》2012年第3期。,而基于中心语驱动语法的计算机处理软件几秒钟才能完成一个语句的分析。CCG延续了语言学基于真实文本构造大规模词条语料库的风格,解决词条多种用法的问题,又延伸了逻辑语义学的递归组合精神,吸取了逻辑的演绎推导力量,解决自然语言中复杂长句子的构造问题。CCG = 语言学视角的词库 + 逻辑学视角的规则,CCG是语言学实践基础上建立的逻辑语义学的新模式,是对语言构造机制特征1和特征2进行兼顾研究的产物。 综上,自然语言的计算机信息处理要求电脑对人脑构造或理解语言的机制进行模拟。逻辑语义学各分支不同程度地描述了语言构造机制的两个特征。从语言学视角看,逻辑语义学对语言构造机制特征1的刻画不够充分,而从逻辑角度看,语言学关于语言构造机制特征2的研究显得薄弱。于是逻辑语义学和语言学形成互补局面,“互补”的结果导致组合范畴语法CCG的产生。我们从语言构造机制的两个特征来审视CCG的兼容并举,同时看到CCG对计算机模拟人脑构造语言机制的贡献。 责任编校:余沉 10.13796/j.cnki.1001-5019.2016.05.006 B81 A 1001-5019(2016)05-0041-07 国家社科基金重大课题(10&ZD073) 邹崇理,四川师范大学特聘教授(四川 成都610101),中国社会科学院研究员,博士生导师(北京100732)。


猜你喜欢
法律方法(2021年3期)2021-03-16
贵州工程应用技术学院学报(2020年2期)2020-07-24
动漫界·幼教365(大班)(2020年7期)2020-06-26
现代计算机(2019年30期)2019-12-11
逻辑学研究(2017年1期)2017-06-05
电脑爱好者(2017年5期)2017-05-04
知识经济·中国直销(2016年5期)2016-11-07
信息安全研究(2015年3期)2015-02-28
长江大学学报(社会科学版)(2015年1期)2015-02-22
网友世界(2009年12期)2009-03-05
