
基于视觉注意机制和条件随机场的图像标注
2016-09-27 06:33孙庆美金聪
智能系统学报 2016年4期
孙庆美,金聪
(华中师范大学 计算机学院,湖北 武汉 430079)
基于视觉注意机制和条件随机场的图像标注
孙庆美,金聪
(华中师范大学 计算机学院,湖北 武汉 430079)
传统的图像标注方法对图像各个区域同等标注,忽视了人们对图像的理解方式。为此提出了基于视觉注意机制和条件随机场的图像标注方法。 首先,由于人们在对图像认识的过程中,对显著区域会有较多的关注,因此通过视觉注意机制来取得图像的显著区域,用支持向量机对显著区域赋予语义标签;再利用k-NN聚类算法对非显著区域进行标注;最后,又由于显著区域的标注词与非显著区域的标注词在逻辑上存在一定的关联性,因此条件随机场模型可以根据标注词的关联性校正并确定图像的最终标注向量。在Corel5k、IAPR TC-12和ESP Game图像库上进行实验并且和其他方法进行比较,从平均查准率、平均查全率和F1的实验结果验证了本文方法的有效性。
自动图像标注;视觉注意;词相关性;条件随机场
中文引用格式:孙庆美,金聪. 基于视觉注意机制和条件随机场的图像标注[J]. 智能系统学报, 2016, 11(4): 442-448.
英文引用格式:SUN Qingmei, JIN Cong. Image annotation method based on visual attention mechanism and conditional random field[J]. CAAI Transactions on Intelligent Systems, 2016, 11(4): 442-448.
随着互联网的不断发展以及移动终端的迅速发展,图像数据不断扩大。图像数据大规模的增长对图像理解技术提出了更高的要求。如何从巨大的图像库中快速有效地找到想要的图像,已经成为了一个亟待解决且具有很大挑战性的任务。而图像标注技术是数字图像语义文本信息的关键技术,在数字图像处理的各个方面有着广泛的应用[1]。
图像标注技术就是为给定的图像分配相对应的语义关键词以反映其内容[2]。早些年的图像标注技术需要专业人员根据每幅图像的语义给出关键词,但那样的方法会消耗大量时间并且带有一定的主观性。因此近几年来,有不少的研究者将注意力转移到图像的自动标注技术上来。就当下的自动标注方法而言大致可以分为两类:1)基于生成式的图像自动标注方法[3-4];2)基于判别式的图像自动标注方法[5-6]。前者主要是先对后验概率建模,然后依据统计的角度表示数据的分布情况,以此来反映同类数据本身的相似度。文献[3]就属于该模型,它将标注问题转化成一个将视觉语言翻译为文本的过程,再收集图像与概念之间的关系以此来计算图像各个区域的翻译概率。文献[4]提出的跨媒体相关模型,将分割得到的团块进行聚类,得到可视化词汇,然后建立图像和语义关键词之间的概率相关模型,估计图像区域集合与关键词集合总体的联合分布。与此类似的方法还包括基于连续图像特征的相关模型,该类方法也存在一定的问题,如当遇到图像过分割和欠分割的时候标注性能大大降低,虽然可以通过改进算法来提高标注结果,但这样增加了计算的复杂性,不具备在真实环境应用的条件。另外,可以构建图像特征与标注词之间的关系模型,然而该模型一般情况下复杂度较高,而且无法确定主题的个数。而后者则是通过寻找不同类别之间的最优分类超平面,从而反映异构数据之间的不同。也就是说,该模型为每个类训练一个分类器,以此来判断测试图像是否属于这个类。文献[2]提出了MRESVM算法,即一个基于映射化简的可扩展的分布式集成支持向量机算法的图像标注。为了克服单一支持向量机的局限性,利用重采样对训练集进行训练,建立了一种支持向量机集成方法。在文献[5-6]中提到的方法也属于判别模型。这两者既有优点又有缺点。相比之下,判别式模型可以实现更好的性能。已有的图像标注方法没有得到较好的标注准确率,主要是由于它们使用的图像内容描述方法和人们对图像的理解方式相距甚远。实际上,当人们看一幅图像的时候,不会把注意力平均分配到图像的各个区域,而是会有选择地把注意力集中到显著区域。由此本文提出了一种基于视觉注意机制和条件随机场的图像自动标注方法。
1 显著区域的标注过程
本文使用的图像标注算法,主要是将传统依据底层特征的标注方法和人们认识图像的方式结合在一起,然后又利用标签之间的共生关系对标注词进行校正,得到最终标注词。
在使用本文所提算法之前要先对图像进行预处理,然后使用基于视觉注意机制和条件随机场算法对图像进行标注。算法主要流程如下:
输入训练图像和测试图像的混合图像集;
输出所有图像对应的标签集。
1)使用支持向量机对显著区域进行识别并标注;
2)对于非显著区域,结合训练图像库的图像与标签关系进行标注;
3)使用条件随机场模型对每幅图像的标签进行优化。
1.1显著区域的提取
当人们看一幅图像时,注意力更多地放在显著区域而不是非显著区域。图像的显著区域指的是在一幅图像中最能引起人们视觉兴趣的部分,图像的显著区域和图像要表达的含义往往一致。充分利用这一点能提高图像标注的准确率。基于此,本文选择先对显著区域进行标注,然后标注非显著区域。这种方法可以消除非显著区域对显著区域的影响,由此获得更好的标注效果。
在图像处理方面,很多获取图像显著区域的模型已被提出。例如,文献[7]提出了一种显著区域的获取方法,它主要结合像素特征和贝叶斯算法。文献[8]提出了一种视觉显著性检测算法,它将生成性和区分性两种模型结合在一个统一的框架中。这些区域通常具有较大的共同特征,面积相对较大且亮度更高。因此本文提出一个新的方法来提取显著区域,也就是视觉注意机制。定义如下:
在利用N-cut算法对图像分割后,根据视觉注意机制求得图像的每个区域的权重。视觉注意机制模型为
W=ω·Area+(1-ω)·Brightness
(1)
式中:W表示图像中每个区域的显著度;ω表示权重。为获得图像的显著区域,本文通过大量实验来得到ω。计算并比较各个区域的显著度W的大小,W值最大的区域就是该图像的显著区域。模型(1)中各参数的意义如下:
a)面积参数Area。在该模型中,Area是参数之一,一般情况下,面积越大的区域越能引起人们的注意,但是不能过大,过大面积的区域会使得显著度降低。具体计算式为
Area=Si/S
(2)
式中:Si表示每幅图像中第i个区域的像素个数;S表示整幅图像的像素个数。
b)亮度参数Brightness。亮度参数是获得显著区域最重要的参数。HSV颜色模型比较直观,在图像处理方面是一种比较常见的模型。定义一个区域的亮度为该区域和图像其他区域HSV值的方差,用式(3)计算。也就是说,先计算图像中所有区域HSV的平均值,然后计算每个区域HSV的值,最后取得各个区域的亮度值。具体公式为
(3)

1.2显著区域的标注
每一幅图像中都包含不等个数的区域,这些区域或简单或复杂、或大或小,而它们都有不一样的语义。传统的标注方法中,对图像的各个区域同等对待,而事实上人们往往把更多的注意力集中在显著区域。所以可以利用式(1)求出每幅图像的显著区域进行单独标注,对非显著区域的区域在后续的步骤中进行标注。
在对显著区域进行标注时,用一组训练图像训练N个支持向量机分类器C= {c1,c2, …,cn}。具体来说,对一组训练图像利用视觉注意机制提取显著区域,再对每个显著区域提取它们的底层特征构成特征向量,并作为输入训练支持向量机。
近年来支持向量机已经被广泛地应用于图像标注中,像文献[2]和[9]。在最简单的情况下,支持向量机是线性可分的支持向量机,这时必须满足数据是线性可分的。但是在实际应用中,线性可分的情况很少,绝大多数问题都是线性不可分的。在遇到线性不可分的问题时,可以通过非线性变换将它映射到高维空间中,从而转化为线性可分问题。SVM的学习策略就是最大间隔法,可以表示为一个求解凸二次规划的问题。设线性可分样本集为(xi,yi),i=1,2,…,n,,i= 1,2,…,n,xi∈Rn,yi∈{+1, -1}是类别标号。通过间隔最大化或等价地求解相应的凸二次规划问题学习得到的分离超平面为wT·x+b=0,线性判别函数为g(x)=wT·x+b。然后将判别函数进行归一化,使两类中的所有样本都必须满足条件|g(x)|≥1,即让距离分类面最近的样本的|g(x)|值等于1,这样分类间隔就等于 2/‖wT‖,因此使间隔最大等价于使‖wT‖最小;分类线若要对所有样本都能正确分类,那么它必须满足以下条件:
(4)

(5)
通过对w和b求解,计算出拉格朗日函数的极小值。再利用KKT条件对分类决策函数求出最优解,最终结果为
(6)
式中:α*为最优解,b*为分类的阈值。
分类时先提取测试图像的显著区域,然后提取图像显著区域的特征值,构成特征向量输入到训练好的支持向量机分类器中,得到每个显著区域的标注词。
2 非显著区域的标注过程
对图像的非显著区域进行标注时,本文将带有标签的图像区域引入对其进行标注。本文将未被标注的非显著区域和带有标注词的图像区域混合在一起,使用k近邻法(k-nearestneighbor, k-NN)聚类算法进行聚类,最终求得非显著区域的标注词。k-NN算法的思路:假设给定一个训练数据集,里面的实例都有确定的类别,对测试实例,根据其k个最近邻的训练实例的类别,通过多数表决方式进行预测。具体的流程如下:
输入待标注的非显著区域和带标签的图像区域;
输出非显著区域的标注词。
1)在带有标签的图像区域中找出与每个待标注的非显著区域相似的K个样本,计算公式为
(7)
2)在每个非显著区域的k个近邻中,分别计算出每个类的权重,计算公式为
(8)
式中:x为待标注区域的特征向量,Sim(x,di)为相似性度量计算公式,与上一步骤的计算公式相同,而y(di,Cj)为类别属性函数,即如果di属于类Cj,那么函数值为 1,否则为0。
3)比较类的权重,将待标注区域划分到权重最大的那个类别中。这样非显著区域就得到了相应的标注词,同时也得到了获得该标注词的概率。
3 标注词校正
设每一幅待标注图像分割为n个子区域Di(i = 1, 2,…, n)。在得到一幅图像的显著区域标签和非显著区域标签集合后,将这些标签整合成图像的标签向量:
式中:p(an)表示该图像的第n个区域获得标注词an的概率。本文使用条件随机场对图像已获取的标注向量进行校正,最终获得图像的标注词。自从条件随机场被提出以来,已有很多研究者把它引入图像标注问题的研究中[10],为了提高图像标注性能,本文根据标注词之间的关系构建合适的条件随机场模型。条件随机场可以用在很多不同的预测问题上。图像标注问题属于线性链条件随机场。本文条件随机场模型是一个无向图模型,图中的每一个点代表一个标注词,而两个点之间的边则代表两个标注词之间的关系。
条件随机场算法对标注词的校正除了涉及到标注词之间的共生关系之外,还将标注词的概率向量作为标注词的先验知识,然后建立标注词关系图并重新计算图像的标注词概率向量。该算法构建所有标注词的关系无向图,在该无向图中除了包含有边势函数(即式(9))之外还包含有点势函数(即式(10)),其中标注词概率向量确定图中点的势函数,而边的势函数则由学习训练集中标注词的关系所得到。例如标注词“马”出现了k1次,标注词“草地”出现了k2次,两者同时出现在同一幅图像的次数为k3次。那么两个标注词的联合概率为式(11)。
(9)
(10)
(11)
式中p(ai)是前面得到的图像被标注为ai的概率。
获得无向图中所有点势和边势之后,求取最优的图结构就能得到最终的图像标注集{afocus,a1,…,an-1}。当图势函数值达到最小时,就得到了最优图结构,即式(12)中M的值最小的图结构:
(12)
式中:λ表示点势函数和边势函数的权重关系,本文通过交叉验证的方法确定λ=0.3。
4 实验结果
4.1图像库
为了验证本文算法的图像标注性能,使用3个图像库。第1个图像库是Corel5K,该库被许多图像处理研究人员使用。它在许多文献中都有提及。Corel5k数据集有5 000幅图像,其中包括4 500个训练样本和500测试样本。每一幅图像平均有3.5个关键词。在训练数据集中有371个标签,在测试数据集中有263个标签。另一个数据集是IAPRTC-12。删除一部分图像后,留有100类的10 000幅图像。在实验过程中,使用80%幅图像用于训练,20%幅图像用于测试。所使用的第3个数据集是ESPGame。总共包含21 844幅图像。其中,19 659张图像用作训练集,2 185张图像用作测试集。
4.2实验设置
为了验证图像标注性能,采取3种评估方法:召回率、查准率和F-measure值。假设一个给定的标签的图像数量是|W1|,|W2|为有正确标注词w的图像数量,|W3|是由图像标注方法得到标签的图像的数量。召回率和查准率可计算如下:
平均查准率(AP)和查全率(AR)可以反映整体标注性能。F-measure可以定义为
在本文实验中选择了3种视底层觉特征进行测试,它们分别为颜色直方图、纹理特征和SIFT。这3种底层特征从不同的角度描述图像的底层信息,同时使用会使标注性能更好。然后在3个数据库Corel5k、IAPRTC-12 和ESPGame上,将VAMCRF算法和其他著名算法进行比较。这些算法已表现出了良好的性能,并且取得了很好的标注结果。因此与它们的比较将能证明VAMCRF算法的性能。表1列出了这些算法和相应的标引。

表 1 实验中用到的算法
4.3 实验结果和比较
4.3.1参数影响
在视觉注意机制中有一个参数ω。该参数对显著区域的提取有着重要的影响,需要通过实验来确定它的值。
首先从图像库中选取100幅有代表性图像,根据经验人眼对亮度的敏感度比面积大一些,所以对ω取这样不同的一组值{0.30, 0.32, 0.34, 0.36, 0.38,0.40, 0.42, 0.44, 0.46, 0.48, 0.50}。通过实验发现当ω = 0.42时,提取图像显著区域效果最好。图1说明了当ω = 0.42时一些类的显著区域提取的实例。从表中可以看到,VAM算法能够预测并很好地提取图像的显著区域。

图1 用VAM算法提取显著区域的例子Fig.1 Some examples using our proposed VAM
在对图像的非显著区域进行标注时,采用了k-NN聚类算法。k-NN聚类算法是最简单的机器学习算法之一,其中k值的选择对结果至关重要。实验测试了参数k取不同值时对标注结果的影响。图2展示的是用k-NN聚类算法在3个图像库上对非显著区域标注的性能。横坐标表示参数k取值的范围,纵坐标代表对应k值时F1的变化。可以看到,当k=100时F1达到最大值,也就是此时标注效果最好。所以,在下面的实验当中k取100。

图2 在3个图像库上k取不同值的标注结果Fig.2 The results of k-NN with different k in the image datasets 1~3
4.3.2标签数目对标注的影响
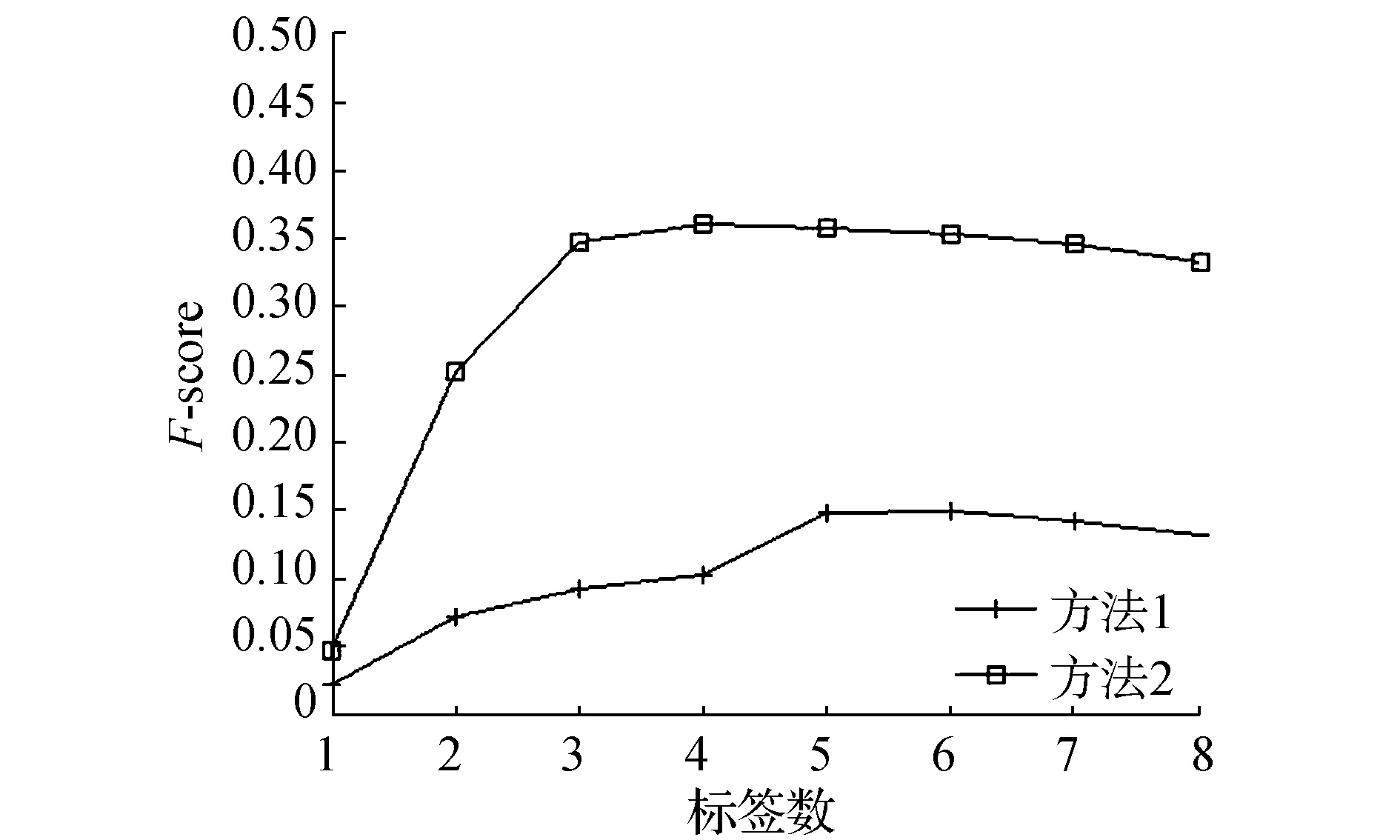
标注性能的好坏有很多影响因素,标签数目就是其中一种因素,为了验证标签数目对标注性能的影响,选取了不同的标签数进行实验。图3分别显示了在3个数据库上不同的标签数目对标注的影响。横坐标表示所取标签的个数从1~8,纵坐标代表对应标签数时F1的变化。这是在两种方法下所做的实验,方法1是使用视觉注意机制和SVM求得显著区域的标注词,然后利用k-NN求得非显著区域的标注词;方法2是在方法1的基础上利用条件随机场对所获得的标注词进行校正。

(a) Corel5k数据库

(b) IAPR TC-12数据库
(c)ESP Games数据库图3 不同标签数对标注的影响Fig.3 The effect of different tag numbers on annotation
从图3可以看出,当只给图像一个标签时,标注结果够不好,随着使用标签数目的增加,标注的准确度都在增加。但是使用的标签数不易过多,如果过多反而会使标注准确度下降。方法2比方法1的效果更好些,说明标注词之间的共生关系对标注效果也是十分重要的。标签相关性的引入使得标注结果更符合实际的标签集,由此证明了本文算法的优势。
4.3.3比较和结果分析
为了验证本文所提出算法的标注性能,在Corel5k、IAPR TC-12和 ESP Game 3个图像库中的测试图像集进行了实验,并对AR、AP和F1的值进行对比。在表2~4给出了比较结果。
表2显示了VAMCRF算法在Corel5k上得到的AR、AP和F1的值。从表中数据可见,VAMCRF算法取得了最高AR值0.48,AP最高值为0.45,F1最大值为0.464。与其他6种算法F1最高值0.439比较,VAMCRF的最大值0.464至少高出了0.014。
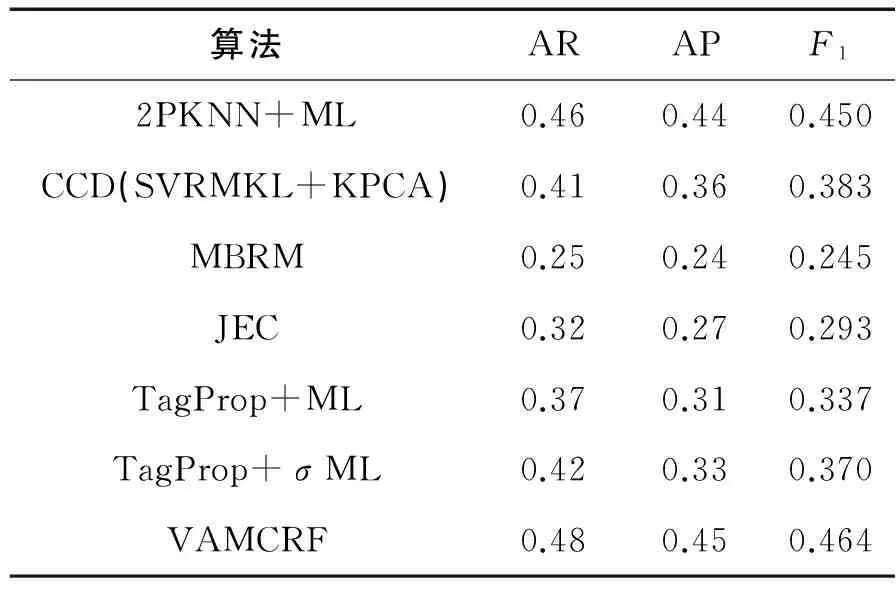
表2 在Corel5k数据库上和其他算法标注性能的比较
表3显示了VAMCRF算法在IAPR TC-12上得到的AR、AP和F1的值。从表中数据可见,2PKNN+ML算法和VAMCRF算法取得了最高AR值0.37,AP最高值0.56,F1最大值0.445。与其他6种算法F1最高值0.450比较,VAMCRF的最大值0.445至少高出了0.006。
表4显示了VAMCRF算法在ESP Game上得到的AR、AP和F1的值。从表中数据可见,VAMCRF算法取得了最高AR值0.28,2PKNN+ML最高AP值0.53,F1最大值0.358。与其他6种算法F1最高值0.357比较,VAMCRF的最大值0.358至少高出了0.001。
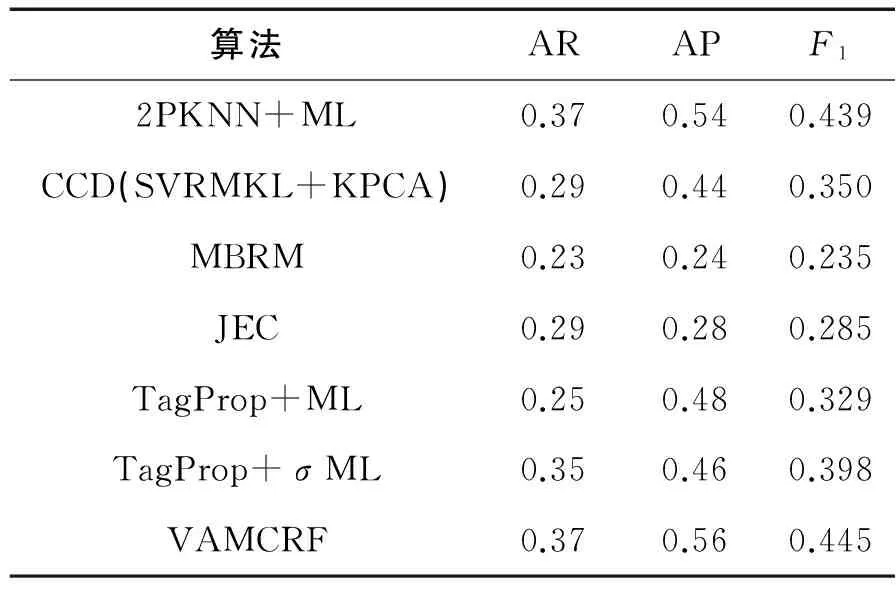
表3 在IAPR TC-12数据库上与其他算法标注性能的比较

表4 在ESP Game数据库上和其他算法标注性能的比较
5 结论
本文提出了一种基于视觉注意机制和条件随机场的算法进行图像的标注,并在Corel5k, IAPR TC-12 和 ESP Game图像库上进行实验。首先,用视觉注意机制提取图像的显著区域,然后利用SVM进行标注,之后使用k-NN聚类算法对图像的非显著区域进行标注,最后利用条件随机场对图像的标注词向量进行校正。实验结果表明,与传统方法相比,本文所提出的算法在标注性能上取得了很好的效果,但是从时间复杂度方面来看还需要很多的改进工作,在未来的研究中可以对算法进行进一步改进以期降低时间复杂度。
[1]WANG Meng, NI Bingbing, HUA Xiansheng, et al. Assistive tagging: a survey of multimedia tagging with human-computer joint exploration[J]. ACM computing surveys, 2012, 44(4): 25.
[2]JIN Cong, JIN Shuwei. Image distance metric learning based on neighborhood sets for automatic image annotation[J]. Journal of visual communication and image representation, 2016, 34: 167-175.
[3]DUYGULU P, BARNARD K, DE FREITAS J F G, et al. Object recognition as machine translation: learning a lexicon for a fixed image vocabulary[C]//Proceedings of the 7th European Conference on Computer Vision. Berlin Heidelberg: Springer-Verlag, 2002: 97-112.
[4]JEON J, LAVRENKO V, MANMATHA R. Automatic image annotation and retrieval using cross-media relevance models[C]//Proceedings of the 26th annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, NY, USA: ACM, 2003: 119-126.
[5]LOOG M. Semi-supervised linear discriminant analysis through moment-constraint parameter estimation[J]. Pattern recognition letters, 2014, 37: 24-31.
[6]FU Hong, CHI Zheru, FENG Dagan. Recognition of attentive objects with a concept association network for image annotation[J]. Pattern recognition, 2010, 43(10): 3539-3547.
[7]FAREED M M S, AHMED G, CHUN Qi. Salient region detection through sparse reconstruction and graph-based ranking[J]. Journal of visual communication and image representation, 2015, 32: 144-155.
[8]JIA Cong, QI Jinqing, LI Xiaohui, et al. Saliency detection via a unified generative and discriminative model[J]. Neurocomputing, 2016, 173: 406-417.
[9]KHANDOKER A H, PALANISWAMI M, KARMAKAR C K. Support vector machines for automated recognition of obstructive sleep apnea syndrome from ECG recordings[J]. IEEE transactions on information technology in biomedicine, 2009, 13(1): 37-48.
[10]PRUTEANU-MALINICI I, MAJOROS W H, OHLER U. Automated annotation of gene expression image sequences via non-parametric factor analysis and conditional random fields[J]. Bioinformatics, 2013, 29(13): i27-i35.
[11]VERMA Y, JAWAHAR C V. Image annotation using metric learning in semantic neighbourhoods[C]//Proceedings of the 12th European Conference on Computer Vision. Berlin Heidelberg: Springer, 2012: 836-849.
[12]NAKAYAMA H. Linear distance metric learning for large-scale generic image recognition[D]. Tokyo, Japan: The University of Tokyo, 2011.
[13]FENG S L, MANMATHA R, LAVRENKO V. Multiple Bernoulli relevance models for image and video annotation[C]//Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC, USA: IEEE, 2004, 2: II-1002-II-1009.
[14]MAKADIA A, PAVLOVIC V, KUMAR S. A new baseline for image annotation[C]//Proceedings of the European Conference on Computer Vision. Berlin Heidelberg: Springer-Verlag, 2008: 316-329.
[15]GUILLAUMIN M, MENSINK T, VERBEEK J, et al. TagProp: discriminative metric learning in nearest neighbor models for image auto-annotation[C]//Proceedings of the 2009 IEEE 12th International Conference on Computer Vision. Kyoto: IEEE, 2009: 309-316.

孙庆美 ,女,1989年生,硕士研究生,主要研究方向为数字图像处理

金聪,女,1960年生,教授,博士。主要研究方向为数字图像处理
Image annotation method based on visual attention mechanism and conditional random field
SUN Qingmei, JIN Cong
(School of Computer, Central China Normal University, Wuhan 430079, China)
Traditional image annotation methods interpret all image regions equally, neglecting any understanding of the image. Therefore, an image annotation method based on the visual attention mechanism and conditional random field, called VAMCRF, is proposed. Firstly, people pay more attention to image salient regions during the process of image recognition; this can be achieved through the visual attention mechanism and the support vector machine is then used to assign semantic labels. It then labels the non-salient regions using a k-NN clustering algorithm. Finally, as the annotations of salient and non-salient regions are logically related, the ultimate label vector of the image can be corrected and determined by a conditional random field (CRF) model and inter-word correlation. From the values of average precision, average recall, and F1, the experimental results on Corel5k, IAPR TC-12, and ESP Game confirm that the proposed method is efficient compared with traditional annotation methods.
automatic image annotation; visual attention mechanism; inter-word correlation; conditional random fields
10.11992/tis.201606004
网络出版地址:http://www.cnki.net/kcms/detail/23.1538.TP.20160808.0831.024.html
2016-06-02. 网络出版日期:2016-08-08.
国家社会科学基金项目(13BTQ050).
金聪. E-mail: jinc26@aliyun.com.
TP391
A
1673-4785(2016)04-0442-07
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
铁道通信信号(2020年3期)2020-09-21
车迷(2018年11期)2018-08-30
无人机(2018年1期)2018-07-05
百科探秘·航空航天(2018年4期)2018-05-14
海峡姐妹(2018年3期)2018-05-09
商周刊(2017年23期)2017-11-24
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
