
一种改进的密码函数识别方法
2016-09-26 07:20祝跃飞石小龙
计算机应用与软件 2016年3期
林 伟 李 伟 祝跃飞 石小龙
(数学工程与先进计算国家重点实验室 河南 郑州 450002)
一种改进的密码函数识别方法
林伟李伟祝跃飞石小龙
(数学工程与先进计算国家重点实验室河南 郑州 450002)
密码函数识别在恶意代码分析、软件脆弱性分析等领域具有积极的作用。传统的密码函数识别算法由于识别方式单一而存在识别精度不高的问题。针对上述问题,提出一种改进的基于数据流分析的密码函数识别方法,将数据流分析引入密码函数识别中,利用递进式多特征的方法对密码函数进行识别。实验表明,该方法能够准确定位密码函数在应用程序中的位置,相比现有方法提高了密码函数的识别精度。
密码函数识别常数特征匹配数据流分析
0 引 言
目前,为了实现安全通信,软件大都采用加密方式对协议数据进行保护,同时恶意程序也采用加密方法来对抗安全人员的逆向分析。识别应用程序中的密码算法能够在恶意代码分析、网络数据安全传输等领域发挥积极的作用。
现有的密码函数识别可以分为静态和动态识别两种。静态识别方法原理是检测二进制程序中是否存在密码算法的静态特征,使用的特征可能是一个代码片段、特殊的常数(magicnumber)、特殊的结构体如S盒或者加密函数入口处的字符串等等。每当找到了对应的特征,这些工具就输出算法的名字(比如MD5、RSA),也可能输出算法的实现方法(比如OpenSSL)。
文献[1-4]利用加密函数的位运算指令占总指令的比例较大这个特征来对密码函数进行识别。文献[5]通过计算缓冲区的信息熵来判断缓冲区是否被解密,因为解密过程会对降低消息的信息熵。同时文献还利用了另外两个特点,一是密码算法一般都有循环结构,二是密码算法大量使用算术运算指令。上面提到的文献对密码算法的识别仅限于区分密码算法和非密码算法,很多时候安全分析人员需要知道具体采用的是哪种密码算法。文献[6]对大量密码函数样本进行训练,提取各函数的属性信息,定义的属性包括指令条数、逻辑运算类指令频度、移位运算类指令频度等,然后得到各类密码函数的分类模型。文献[7]提出了一种基于循环I/O的密码算法识别方法。其基本思想是首先记录程序的轨迹信息,然后识别轨迹里的循环结构,提取循环结构的输入和输出参数,最后将输入和输出内存数据代入到已知的密码算法实现中进行检验,如果匹配成功则证明是该算法。此方法的局限性在于,部分密码算法为了提高效率,在实现过程中可能会采取一些优化算法,会破坏密码算法原有设计中的一些循环结构,比如AES加解密算法的一种优化算法就是将轮循环全部展开,在汇编代码中将没有循环结构存在,这时就会产生漏报。
综上所述,密码函数识别定位是分析网络软件、恶意程序的关键,现有的静态密码函数识别方法一般都是采用特征匹配的方法,适用性非常有限,而动态识别方法大都是利用密码函数的指令比例特征对密码函数进行分类,但因为密码函数种类众多,利用指令比例特征很难找到一个合适的分类模型使得所有的密码函数仅属于一个类别,因此准确率也有待提高。
1 密码算法识别
1.1总体思路
本文将数据流分析引入密码函数识别中,提出了一种递进式的密码函数识别方法。首先利用密码函数的常数、运算指令比例等简单特征排除掉绝大部分函数的干扰,识别出具有典型常数特征的密码函数,比如MD5、SHA1等,并筛选出疑似密码函数;然后利用数据流分析对可疑函数的数据依赖关系进行分析,判断密码函数的大致种类;最后再利用不同类型指令的比例特征对密码函数的类别进一步区分。密码函数识别的整体思路如图1所示。
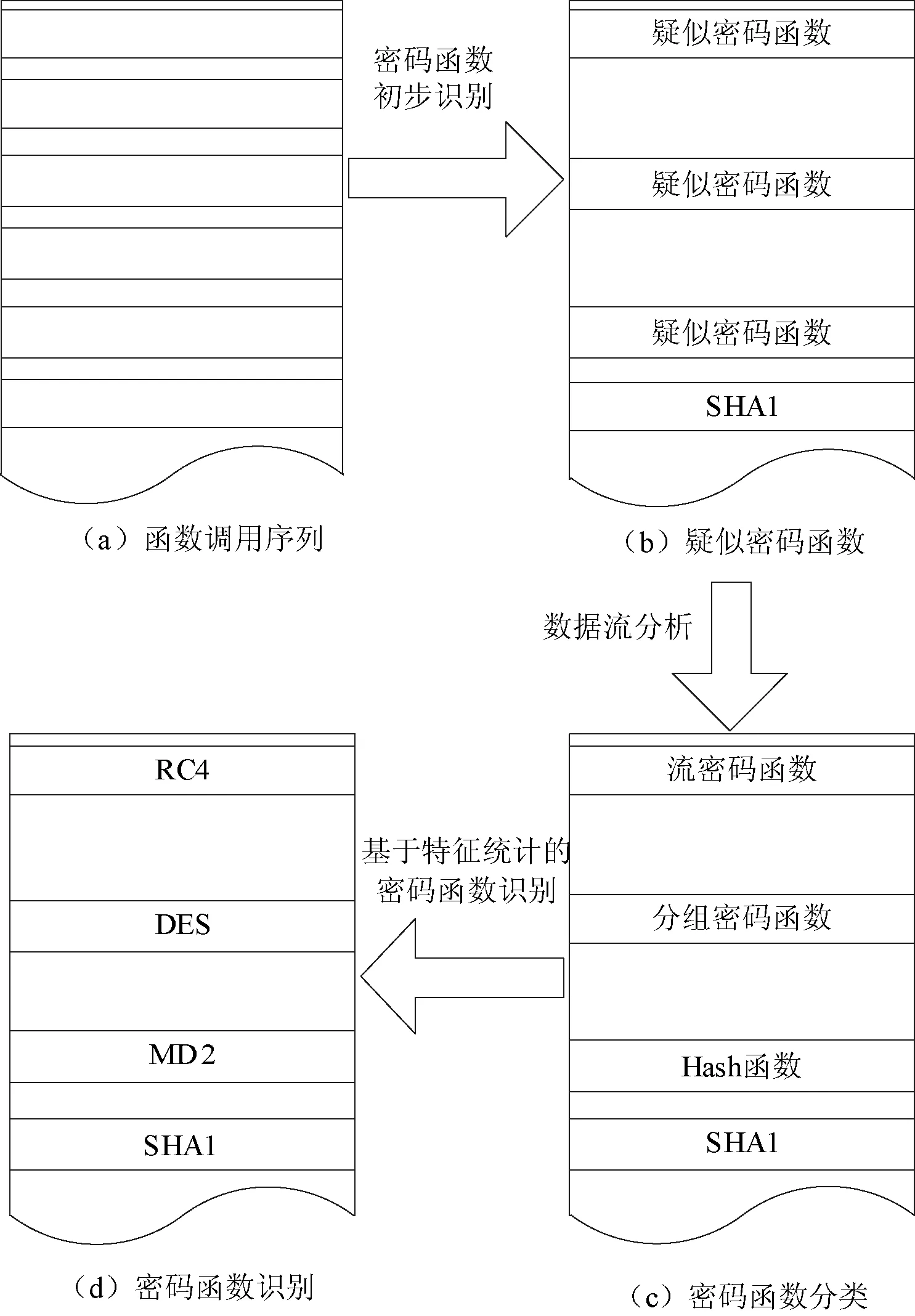
图1 系统架构图
1.2密码函数初步识别
程序执行轨迹包含的函数调用非常多,因此首先根据密码函数的一些简单特征对函数进行初步识别筛选,排除掉绝大部分函数的干扰,然后再对疑似密码函数进行深度识别。经过分析本文选取了以下三种特征:
1) 指令总数:密码函数因为其功能的复杂性,要实现加密或解密功能,所需要的指令不会很少,因此指令总数有一个最小限制。通过对Feiq软件的一次执行轨迹进行分析,本文得到如表1所示的统计结果,可以看出指令数目小于10的函数调用次数占所有函数调用次数的42.8%,而指令数目小于200的函数调用更是占了85.8%,因此仅用指令总数这个特征就可以排除掉大部分非密码函数的干扰。如表1所示。

表1 不同指令数目的函数所占比例
2) 算术运算与逻辑运算指令比例:密码函数的算术运算、逻辑运算指令比较多,控制转移指令比较少,这几类指令在常见的密码算法实现中具有非常明显的统计特性,可以作为区分密码函数和非密码函数的重要指标。
3) 函数使用的常数:密码算法实现中使用的常数分主要分为两类。第一是指令中的立即数,第二是存储在内存中的常数,利用这个特征可以对一些特殊的密码函数进行识别。
提取函数的信息之后,根据上述密码函数特征对函数进行初步识别筛选,为了避免对同一密码函数重复识别,本文只对最内层的密码函数进行识别,如果子函数被识别为密码函数,那么就不对其父函数进行识别,如果子函数不是密码函数,再将子函数的信息并入到父函数再进行识别。对每个函数调用识别的具体步骤如下:
Step1若函数指令总数N在一定的阈值范围内,执行Step2,否则认为该函数不是密码函数,结束所有步骤。
Step2将函数所有指令使用的立即数和访问的内存与密码函数知识库中的特征进行匹配,检测其中是否包含了一些特定密码算法才会使用的常数,如果包含则说明函数是该密码算法的一个实现,识别成功,结束所有步骤。
Step3计算函数算术运算和逻辑运算所占的比例,若大于一定的阈值,则标记该函数为疑似密码函数。
密码函数初步识别筛选将函数调用序列中大部分函数过滤掉,并对一些包含常数特征的密码函数进行识别,比如MD5、SHA1等,再根据指令总数、算术逻辑运算指令比例等特征筛选出疑似密码函数,有待进一步分析。
1.3基于数据流分析的密码函数分类
密码算法为了防止被破解,在设计时会尽量满足雪崩效应。雪崩效应是指当输入发生最微小的改变(比如改变一个二进制位)时,也会导致输出的剧变(比如输出中一半的二进制位发生反转),比如图2所示的SHA-1散列函数,输入只改变了一个二进制位,输出却完全不一样。若某种密码或散列函数的雪崩特性不够好,那么密码分析者就能够仅仅从输出推测输入,这可能导致该算法部分乃至全部被破解。

图2 SHA-1函数雪崩效应示意图
同时由于不同类型密码算法的输入输出依赖关系不一样,如图3所示,分组密码算法每个输入字节会影响输出的每一个字节,而流密码算法每个输入字节仅影响一个输出字节,因此可以利用这个特征对不同类型的密码函数进行识别。

图3 不同类型密码函数输入输出依赖关系
明密文缓冲区定位是为了在函数所有的输入输出中发现满足密码函数特性的输入和输出缓冲区,如果找不到则说明函数不是密码函数,密码函数常见的种类有Hash函数、分组密码函数、公钥密码函数、流密码函数。可以根据明密文缓冲区的特点将这四类密码函数分为两种:
1) 第一种是前三类密码函数,函数存在一个输入缓冲区和一个输出缓冲区,其中输入缓冲区中的每个字节会影响输出缓冲区的很多字节,反之输出缓冲区的每个字节会依赖输入缓冲区的许多字节;
2) 第二种是流密码函数,函数存在一个输入缓冲区和一个输出缓冲区,缓冲区大小相等,并且每个输入字节只影响对应位置的一个输出字节。
定位明密文缓冲区存在两个干扰,一是普通函数也可能会存在满足上述特性的输入输出缓冲区,二是密码函数中满足上述特性的缓冲区不一定是函数的明密文,也有可能是密码函数的密钥、S盒以及一些临时变量。
本文采取三种方法来排除上述两个干扰:
1) 利用函数的指令数目、指令比例等特征对函数进行初步识别筛选,过滤掉绝大部分的普通函数,根据实际经验,筛选出来的函数一般都是密码函数;
2) 记录函数结束时的栈指针esp的值,因为函数结束时存于栈中的局部变量已经被释放,因此函数内部访问的地址小于esp的内存视为函数的局部变量;
3) 设置加密和解密的缓冲区不小于4个字节,防止一些临时读写的内存或者离散访问的内存被误认为是加解密缓冲区。
秦铁崖来京城之前,翻阅旧案卷宗,去了趟证物库房,翻出这个烟花筒带在身边。秦铁崖道:“你不叫乔十二郎,你是陆枫桥。”
为了识别第一类缓冲区,首先给出内存依赖度的定义:
定义1内存依赖度是指污点分析中,单个内存单元所依赖的污染源字节数,比如若指令movbyteptr[edi],al执行后内存单元的污点状态为{1,2,4},则该内存单元的依赖度为3。
对第一类缓冲区,由于雪崩效应密码函数输出的每个内存单元会依赖于输入的全部字节或者大部分字节,表现出高依赖度的特征,因此可以采用如下方式定位输入输出缓冲区。标记疑似密码函数所有输入内存单元中连续字节数不小于4的地址为初始污点,对疑似密码函数的执行轨迹进行污点分析,然后逐字节检查每个字节污染的输出单元,如果找到一块输入和输出,输入的每个字节都污染了输出的很多字节,并且输出的每个字节也依赖很多输入字节,则说明定位成功。设计定位第一类缓冲区密码算法如下所示,如果定位成功算法返回定位到的输入输出缓冲区,否则返回NULL。如算法1所示。
算法1定位第一类缓冲区算法
Input:函数执行轨迹FuncTrace,及函数读写的所有内存单元In和Out
Output:若定位成功,返回定位到的输入输出缓冲区InBuf和Outbuf,否则返回NULL
1.InitTaintSource(In) //初始化In中连续字节数不小于4的内存单元为初始污点
2.TaintAnalysis(FuncTrace) //对执行轨迹进行局部污点分析
3.foreachbyteiintaintsource
4.calculateT(i) //计算字节i污染的内存单元集合,用T(i)表示
5.endfor
6.InBuf= {污染源第一个字节}
7.OutBuf=T(0)
8.for(污染源中剩下的字节)
9.if(T(i)∩T(i-1)!=NULL)
10.pushitoInBuf;
11.pushT(i)toOutBuf;
12.endif
13.ifsizeof(InBuf) 14.InBuf= {第i个污染源字节} 15.OutBuf=T(i); 16.endif 17.endfor 18.ifsizeof(InBuf) 19.returnNULL; 20.endif 21.returnInBuf,OutBuf 对于第二类缓冲区,因为密文和明文只有一一对应的依赖关系,可以在输入输出缓冲区中利用滑动窗口的方法识别出满足一一对应的两个内存块,即流密码函数的输入和输出。设计的定位算法如算法2所示。 算法2定位第二类缓冲区 Input:函数执行轨迹FuncTrace,及函数读写的所有内存单元In和Out Output:若定位成功,返回输入输出缓冲区InBuf和Outbuf,否则返回NULL 1.InitTaintSource(In) //初始化Input中连续字节数不小于4的内存单元为初始污点 2.TaintAnalysis(FuncTrace) //对函数的执行轨迹进行局部污点分析 3.OutBuf=GetBytesWithContinuousLabel(Output) //获取Output中污染标签连续的内存单元块 4.ifsizeof(OutBuf) //T为输出缓冲区大小的最小阈值 5.renturnNULL 6.endif 7.InBuf=GetDependencySource(OutBuf); //获取OutBuf依赖的输入缓冲区 8.returnInBuf,OutBuf 不同密码函数的输入输出依赖关系不一样,因此我们可以依此对不同密码函数进行区分。流密码函数的输入输出缓冲区大小相等,并且每个输入字节仅影响一个输出字节;Hash函数与其他密码函数的一个主要区别就是函数输出缓冲区的大小,Hash函数的输出缓冲区一般都比输入要小很多,并且Hash函数的每个输入字节都会影响所有的输出字节;分组密码函数每个输入字节会影响全部输出字节,并且输入和输出缓冲区相等,公钥密码函数的特征与此类似。根据上面的分析,可以用图4所示的决策树对密码函数的类别进行划分。 图4 密码函数分类决策树 利用数据流分析对密码函数进行分类只是将疑似密码函数分为了流密码函数、Hash函数等较大的类别,同时可以根据输出缓冲区的大小对密码函数对密码函数进一步区分,比如对Hash函数,根据输出缓冲区大小可以得到如图5所示的决策树。对一个疑似密码函数,密码函数分类的最终结果是得到其所有可能的类别集合,比如若输出缓冲区大小为16个字节,则疑似密码函数可能的类别为{MD2、MD4、MD5、RIPEMD、…}。 图5 Hash函数根据缓冲区大小的分类 1.4基于特征统计的密码算法识别 不同密码函具有各自独特的指令统计特征,利用该特征可以对密码函数进行识别。本文定义了一个五维特征向量 N:指令总数。 Rarith:算术运算指令比例。算法运算指令反映了函数的算法操作,包括ADC、ADD、DEC等指令。 Rlogic:逻辑运算指令比例。包括AND、SHL、SHR、ROL、SAL等指令。 Rspecial:特殊运算指令比例。公钥密码算法比如RSA包含很多大数的运算,反映到汇编指令则是MUL、IMUL、DIV、IDIV等算术运算指令,因此可以利用这一指标对公钥密码函数进行识别。 Rconj:条件跳转指令比例。通过对密码函数进行分析,发现其中条件跳转指令的比例比一般函数要低很多。因此选取它作为密码函数的特征指标之一。 在获取了待检测函数的五维特征向量后,需要一种数据分类模型,对该函数所属的密码算法类别进行识别。常见的数据分类算法有决策树方法、人工神经网络方法、贝叶斯方法和支持向量机方法等,不同的分类方法有不同的特点,分别适用不同类型的数据,评价一个分类算法的标准包括准确率、执行效率、强壮性、伸缩性和可解释性等,上述四种方法的性能评估如表2所示,综合考虑算法的性能以及实现难度,本文选择贝叶斯方法来实现这一目标。如表2所示。 表2 各分类算法性能比较 贝叶斯分类的基本流程如下: 1) 设x={a1,a2,…,am},其中ai为x的一个特征属性; 2) 获取类别集合C={y1,y2,…,yn}; 3) 计算条件概率P(y1|x),P(y2|x),…,P(yn|x); 4) 如果P(yk|x)=max{P(y1|x),P(y2|x),…,P(yn|x)},则x∈yk。 问题的关键在于如何计算第3步中的各个条件概率,可以采用如下方法: 1) 找到一个已经分好类的训练样本集。 2) 统计得到各类别下各个属性的条件概率分布: P(a1|y1),P(a2|y1),…,P(am|y1),…,P(am|yn) 3) 根据贝叶斯定理有如下推导: 因为分母对所有类别为常数,只需要将分子最大化即可,若各特征属性是条件独立的,则有: P(x|yi)P(yi)=P(a1|yi)…P(am|yi)P(yi) 根据上述分析,利用贝叶斯分类对密码函数进行识别的基本步骤如下: Step1通过加密算法库、网页论坛等方式收集密码算法样本,通过手工定位的方法确定各个程序中密码算法的所在位置,运行程序收集密码函数的特征。 Step2分类器训练,这一步的主要任务就是生成分类器,计算每个类别的出现频率和每个特征属性对每个类别的条件概率估计。 Step3使用分类器对目标函数进行分类。输入是分类器和待分类函数,输出是待分类函数所属的算法类别。 2.1测试环境 本文测试环境如表3所示。 表3 测试环境 2.2功能测试 (1) 测试对象EncryptDemo EncryptDemo是本文为了测试系统的功能自己编写的一款加密通讯程序。软件分为客户端和服务端,客户端每发送一个明文命令,服务端就回应一个加密的数据包,客户端再回应一个确认包。数据包的加密方法如所图6所示,客户端收到数据包后,将数据包解密还原成明文,并计算SHA-1摘要,与数据包中的摘要作比对。客户端和服务端的加解密函数基于开源加密算法库xyssl-0.8实现。 图6 EncryptDemo协议格式设计 (2) 密码函数识别 首先根据函数使用的常数、指令比例等特征对密码函数进行初步识别,识别结果如图7所示。识别出了SHA1_init、SHA1_update和AES_DE函数,除此之外还识别出了一个疑似密码函数sub_44110d。 图7 EncryptDemo密码函数初步识别结果 然后利用污点分析定位疑似密码函数中的加解密缓冲区,对函数sub_44110d的第一次调用实例的输入和输出定位结果如图8所示。 图8 EncryptDemo密码函数进一步识别结果 图8中省略了一些输入和输出内存单元,输入输出缓冲区都是0x43字节,并且输出的每个字节依赖于输入的每一个字节,因此我们判定它为流密码函数,根据贝叶斯识别算法,算法是RC4的概率为87%,是SEAL的概率为13%,因此判断sub_44110d为RC4函数。 另外本文对公开软件中的8种密码算法进行了识别,并与3种密码识别软件进行了对比,结果如表4所示。 表4 识别结果 3种工具都声称能够检测本文测试的8种密码算法,本文的测试结果见表4所示,其中Π表示成功识别了程序中的加密算法,Ο表示未能识别指定的密码算法,可以看出没有任何一个工具能够识别所有的加密算法。这是因为对于恶意软件来说,使用静态的方法很难识别其中的密码算法,因为攻击者可以很容易地混淆恶意程序把算法的静态特征给隐藏起来。 (3) 性能分析 本文的方法的时间开销包含三个部分:指令特征的统计、基于数据流分析的密码函数分类和特征统计的样本训练。其中特征统计的样本训练的时间开销取决于样本复杂度和训练次数,差异性较大,因此本文只给出了前两个部分的时间开销。本文采取PIN平台进行的指令特征的统计和数据流分析,其中时间开销为软件从启动到启动完毕的时间开销,如表5所示。 表5 时间开销 传统的密码函数识别算法中的静态密码函数识别方法一般都是采用特征匹配的方法,而动态识别方法是利用密码函数的指令比例特征对密码函数进行分类,两者的准确精度不高。针对上述问题,本文提出了一种改进的基于数据流分析的密码函数识别方法,将数据流分析引入密码函数识别中,利用递进式多特征的方法对密码函数进行识别。实验表明,该方法能够准确定位密码函数在应用程序中的位置,相比现有方法提高了密码函数的识别精度。 [1]CaballeroJ,YinH,LiangZ,etal.Polyglot:Automaticextractionofprotocolmessageformatusingdynamicbinaryanalysis[C]//Proceedingsofthe14thACMconferenceonComputerandcommunicationssecurity.ACM,2007:317-329. [2]LinZ,JiangX,XuD,etal.AutomaticProtocolFormatReverseEngineeringthroughContext-AwareMonitoredExecution[C]//NDSS,2008,8:1-15. [3]WangZ,JiangX,CuiW,etal.ReFormat:Automaticreverseengineeringofencryptedmessages[M]//ComputerSecurity-ESORICS2009.SpringerBerlinHeidelberg,2009:200-215. [4]WondracekG,ComparettiPM,KruegelC,etal.AutomaticNetworkProtocolAnalysis[C]//NDSS,2008,8:1-14. [5]LutzN.Towardsrevealingattackersintentbyautomaticallydecryptingnetworktraffic[J].Master’sThesis,ETH,Zürich,Switzerland,2008. [6] 李洋,康绯,舒辉.基于动态二进制分析的密码算法识别[J].计算机工程,2012,38(17):106-109,115. [7]CalvetJ,FernandezJM,MarionJY.Aligot:Cryptographicfunctionidentificationinobfuscatedbinaryprograms[C]//Proceedingsofthe2012ACMconferenceonComputerandcommunicationssecurity.ACM,2012:169-182. [8] 李继中.基于相似性判定的密码算法识别技术研究[D].解放军信息工程大学,2009. ANIMPROVEDMETHODOFCRYPTOGRAPHICFUNCTIONRECOGNITION LinWeiLiWeiZhuYuefeiShiXiaolong (State Key Laboratory of Mathematical Engineering and Advanced Computing,Zhengzhou 450002,Henan,China) Cryptographicfunctionrecognitionhasapositiveeffectinmaliciouscodeanalysis,softwarevulnerabilityanalysisandotherfields.Traditionalcryptographicfunctionrecognitionalgorithmhastheproblemoflowidentificationaccuracyduetoitssinglemode.Inlightoftheaboveproblem,weproposedanimprovedmethodofcryptographicfunctionrecognitionwhichisbasedondataflowanalysis.Itintroducesdataflowanalysistocryptographicfunctionrecognition,andusesprogressivemulti-featureapproachtorecognisethecryptographicfunctions.Experimentsshowedthatthemethodcouldaccuratelylocatethepositionofcryptographicfunctionsintheapplication,comparedtoexistingmethods,theaccuracyofcryptographicfunctionrecognitionwasimproved. CryptographicfunctionrecognitionConstantfeaturematchingDataflowanalysis 2014-06-13。国家自然科学基金项目(61309007);国家科技支撑计划项目(2012BAH47B01)。林伟,博士生,主研领域:信息安全。李伟,讲师。祝跃飞,教授。石小龙,硕士生。 TP393.08 ADOI:10.3969/j.issn.1000-386x.2016.03.071


2 实现与测试

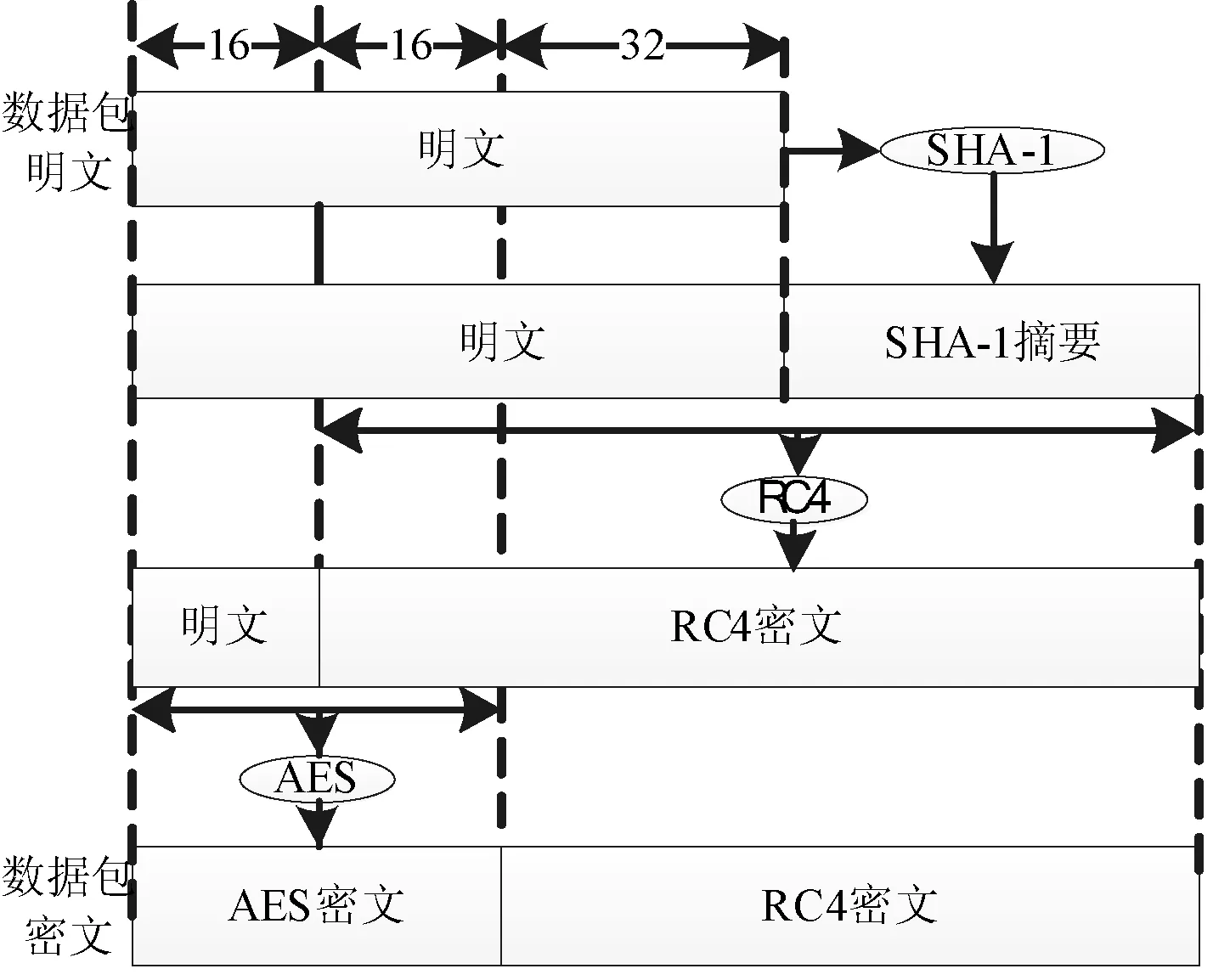




3 结 语
猜你喜欢
销售与市场(营销版)(2021年10期)2021-11-21当代陕西(2019年13期)2019-08-20销售与市场(营销版)(2019年6期)2019-06-21沈阳工业大学学报(2018年1期)2018-01-08网络安全技术与应用(2017年9期)2017-09-20电脑爱好者(2015年21期)2015-09-10项目管理技术(2015年3期)2015-04-23时代人物(2014年10期)2015-01-28测绘科学与工程(2014年5期)2014-02-27电视技术(2012年1期)2012-06-06
