
基于关联规则的隐私泄露风险评估模型
2016-09-24 06:42:38邝青青彭长根
贵州大学学报(自然科学版) 2016年2期
邝青青,彭长根*,丁 洪
(1.贵州大学 理学院,贵州 贵阳 550025;2.贵州大学 密码学与数据安全研究所,贵州 贵阳 550025)
基于关联规则的隐私泄露风险评估模型
邝青青1,彭长根1*,丁洪2
(1.贵州大学 理学院,贵州 贵阳 550025;2.贵州大学 密码学与数据安全研究所,贵州 贵阳 550025)
传统的信息安全风险评估较少涉及对背景知识关联分析所导致的隐私泄露风险。针对基于关联分析的大数据隐私泄露风险问题,以隐私资产、隐私威胁因子和隐私存储有效时间为要素建立隐私泄露风险指标体系、定义风险计算函数;通过对隐私库的关联规则及频繁项的分析,得出满足最小支持度阈值的关联概率,实现风险函数计算;最后,针对搜索数据进行实例验证,验证表明该模型可以有效评估风险,真实刻画隐私泄露风险大小。
隐私数据;隐私泄露;FP-Growth;关联分析;风险评估;大数据
大数据给社会带来了便利,同时也造成了巨大的隐私泄露问题[1],尤其是对背景知识的关联分析导致的个人隐私泄露问题。
目前,针对安全的评估风险评估主要集中在信息安全领域,早期方法多为定性的评估方法。对于量化风险评估,初期研究多集中在基于简单概率模型的风险分析方面[2-4]。后来,Bilge等[5]在2005年提出了一种新的量化方法,该方法考虑到当前需求对将来的影响;Kondakci等[6]于2010年引入Bayesian网络模型给出了一种量化风险分析方法。文献[7]中Liu等人采用模糊层次分析(AHP)理论,通过引进相关系数,针对云计算环境下的信息安全进行风险评估,综合系统面临的威胁因子得出结论。但是,由于使用AHP理论时需要计算最大特征值标量,而计算过程中需要不断的校正模糊权重,所以评估结果会因为赋予模糊权重时的任意性而不准确。文献[8]提出了一种基于信息测量和模糊聚类的风险评估,该方法对所有威胁因子进行量化并保证在具体运算过程中的信息独立性,然后使用K-means聚类算法来区分数据。但是,该方法主观性太强,而且在大数据环境下,由于数据量大,数据结构多元化,使用K-means聚类算法不能达到预期效果。Bernardo等[9]于2012年提出了一种基于距离的定性和排序,并提供用户偏好参数的方法进行安全风险评估。2015年Kresimir等[10]改进了证据理论方法,并将该方法应用于信息安全风险量化评估。
众所周知,大数据应用势必带来诸多的信息安全问题,尤其是隐私泄露问题。关于隐私泄露的风险评估研究迫在眉睫,然而,信息安全风险评估对因关联隐私或威胁产生风险的理论研究还没有被检索到。因此,本文利用FP-Growth方法,设计大数据环境下的隐私泄露风险评估模型,综合隐私资产、隐私威胁因子以及隐私存储有效时间三要素建立隐私泄露风险指标体系,通过对隐私库的关联规则及频繁项的分析,对脆弱隐私项之间的强关联规则进行计算,得出各关联规则的概率,把隐私泄露的风险度间接转化为求关联规则的概率。
1 基础知识
1.1基本概念
隐私资产:这里的隐私资产主要指用户不愿意让别人看见或非法使用的各种互联网隐私数据信息,如身份隐私、位置隐私、浏览轨迹、网购习性以及社交关系网等等。
脆弱性:脆弱性指隐私数据持有者由于自身的设备安全,人为安全或者管理安全等不足而客观存在的,攻击者可以不经过持有者的同意而非法访问或盗用用户隐私数据信息的弱点。可分为技术脆弱性和管理脆弱性两类。
风险评估:本文的风险评估,指的是对隐私数据信息持有者或管理方的脆弱性、可能存在的威胁等各方面进行分析,构造由脆弱隐私数据项之间关联而产生的对个人隐私造成泄露的概率和发生泄露造成的影响所决定的函数。
隐私关联:一个单一的隐私信息发生泄露通常不会带来风险,但是如果同一用户的多个单一隐私被关联,即隐私节点A将自身风险转移给数据库中不存在风险的另一隐私节点B,产生关联。
1.2关联规则
I={i1,i2,…,im}包含m个不同项目的集合,简称项集。D为关于I的事务集合,每个事务T为包含有若干项集的集合,即I⊆T。每一个事务都具有一个标示符TID。一个关联规则可以表示为A⟹B,其中,A⊂I,B⊂I,且A∩B=φ。
定义1设A⊂I,B⊂I,对于关联规则A⟹B,称在事务集D中同时出现A和B的概率叫支持度,记作Support,且
Support(A⟹B)=P(A∪B)
定义2设A⊂I,B⊂I,对于关联规则A⟹B,在事务集D中,若在A出现的条件下,B也出现的概率叫置信度,记作Confidence,表示为
Confidence(A⟹B)=P(B|A)
定义3设存在关联规则A⟹B,若A⟹B同时满足给定的最小支持度(minsupport)和最小置信度(minconfidence),则称这样的关联规则为强关联规则。
1.3关联规则算法
常见的经典关联规则算法主要有Apriori、K-means及FP-Growth等算法。1993年,Agrawal等[11]人首次提出Apriori算法,该算法使用一种逐层迭代的方法搜索频繁项集,频繁k-项集作为探索频繁k+1-项集的基础。由于在产生频繁项集时每次都要对数据库进行扫描,所以当项目集增大时,在产生候选集C2时,Apriori算法的时间复杂度和空间复杂度都比较大。
针对Apriori算法效率和性能低下的问题,2000年,HAN等[12]提出了FP-Growth算法,将提供频繁项集的数据库压缩到一颗频繁模式树(或FP树),整个过程不适用候选集,但保留项集关联信息;然后,将压缩后的数据库分成一组条件数据库(一种特殊类型的投影数据库),每个关联一个频繁项集,所以具有很强的适用性和高效性。算法核心思想:
(1)FP-Growth算法只需要扫描事务数据库D两次。第一次扫描数据库,收集频繁项的集合F和它们的支持度。对F按支持度降序排序,结果为频繁项表L;
(2)创建FP-tree的根结点,以“null”标记它。再次扫描数据库,对于D中每个事务T,选择T中的频繁项,并按L中的次序排序。设排序后的频繁项表为[p|P],其中,p是第一个元素,而P是剩余元素的表。调用insert_tree([p|P],T)。该过程执行情况如下,如果T有子节点N使得N.item-name = p.item-name,则N的计数增加1;否则创建一个新结点N,将其计数设置为1,链接到它的父结点T,并且通过结点链结构将其链接到具有相同item-name 的结点。如果P非空,递归地调用insert_tree(P,N)。FP-Tree的挖掘通过调用FP_growth(FP_tree,null)实现。该过程实现如下:

procedureFP_growth(Tree,α) ifTree含单个路径Pthen for路径P中结点的每个组合(记作β) 产生模式β∪α,其支持度support=β中结点的最小支持度; elseforeachai在Tree的头部 { 产生一个模式β=ai+α,其支持度support=ai.support; 构造β的条件模式基,然后构造β的条件FP-树Treeβ; ifTreeβ≠⌀then调用FP_growth(Treeβ,β); }
2 建立评估指标体系
风险评估是建立在评估指标体系的基础上进行操作的,根据隐私数据管理方的具体情况,分析隐私资产、威胁因子和隐私存储有效时间,并建立与FP-Growth算法相匹配的风险评估指标体系。风险评估指标体系的建立基本分为以下几个部分:
2.1隐私资产定义
风险评估中资产的价值主要通过保密性(C)、完整性(I)、可用性(A)三个属性来刻画,而不同的资产三个属性(CIA)的重要性不一样。用户隐私数据资产,保密性是更加关注的属性。根据大数据环境下隐私数据内容及形式所具有的特点,主要将隐私数据分为身份隐私、位置隐私、浏览轨迹、网购习惯、社交网络等。
身份隐私:主要指与用户个人直接关联的信息,如个人姓名、肖像、身份证号码、家庭住址等;
位置隐私:本文主要指的是用户过去、现在或者是将来的原始位置数据,它记录了用户的具体位置以及行动轨迹;
浏览轨迹:本文主要指用户通过使用移动设备等对网页的浏览习惯及规律和浏览日志记录等;
购买习性:购买习性这里是指用户在长期使用网络运营商(如淘宝、京东等)过程中逐渐形成的浏览并购买商品的网络行为;
社交关系网:用户自己的一个朋友圈、关系圈。一般来说,可以通过用户个人的社交关系网间接性关联,分析出用户本人的完整信息。
这里的资产主要指以上的隐私数据信息,风险影响程度由隐私资产的重要性决定,隐私资产重要度定义为:
I=ln[(eCon+eInt+eAvail)/3]
其中Con,Int,Avail分别表示保密性、完整性、可用性赋值,且Con+Int+Avail=3。
2.2威胁因子
由于每个行业的关注点不一样,管理方案和技术手段也会有差异,本文考虑一般的情况,把隐私资产可能面临的隐私泄露风险划分为隐私数据使用风险以及人为风险。如表1:

表1 隐私泄露威胁因子
2.3隐私存储有效时间
各类隐私数据由于其本身价值或效用的大小,在存储有效时间上有所差异,如对于网购商品的用户来讲,一次性购买的用户所产生的隐私信息选择短期存储,之后根据其具体的购买情况再更改存储时间,不仅可以节省内存,还能有选择性的提供服务。本文定义存储有效时间为:
T=ωCS+ωIM+ωAL
式中:ωC、ωI、ωA分别为隐私资产保密性、完整性和可用性在存储有效时间内的权重,S、M、L分别表示隐私信息短期、中期和长期存储有效时间上按权重分配的值,且S+M+L=5。
3 基于关联规则的隐私泄露风险评估
基于关联规则的隐私泄露风险评估模型如图1所示,主要步骤分为以下4步:
(1)收集并建立一个脆弱隐私数据库。在进行风险指标体系构建过程中,首先需要收集隐私数据,分析隐私数据脆弱性,从而能从大量脆弱隐私数据集中选择适合本文所采用的FP-Growth算法的数据。
(2)设计多维关联规则隐私数据库表。分析脆弱隐私数据库的性质特点,找出各项指标间的关系,构造多维隐私数据库表,设计基于关联规则的隐私数据挖掘算法,挖掘频繁项集,推导出强关联规则。
(3)引入关联规则算法。本文引入FP-Growth算法,通过建立风险隐私数据网络,利用该算法挖掘出频繁项集,计算关联规则强度。
(4)风险值定义。本文通过对隐私资产、威胁因子、以及隐私数据资产存储的时间进行风险指标体系建模,构造风险计算函数R=P·I·T。这里,P表示关联风险发生的可能性,I表示风险影响程度,T表示隐私存储有效时间。
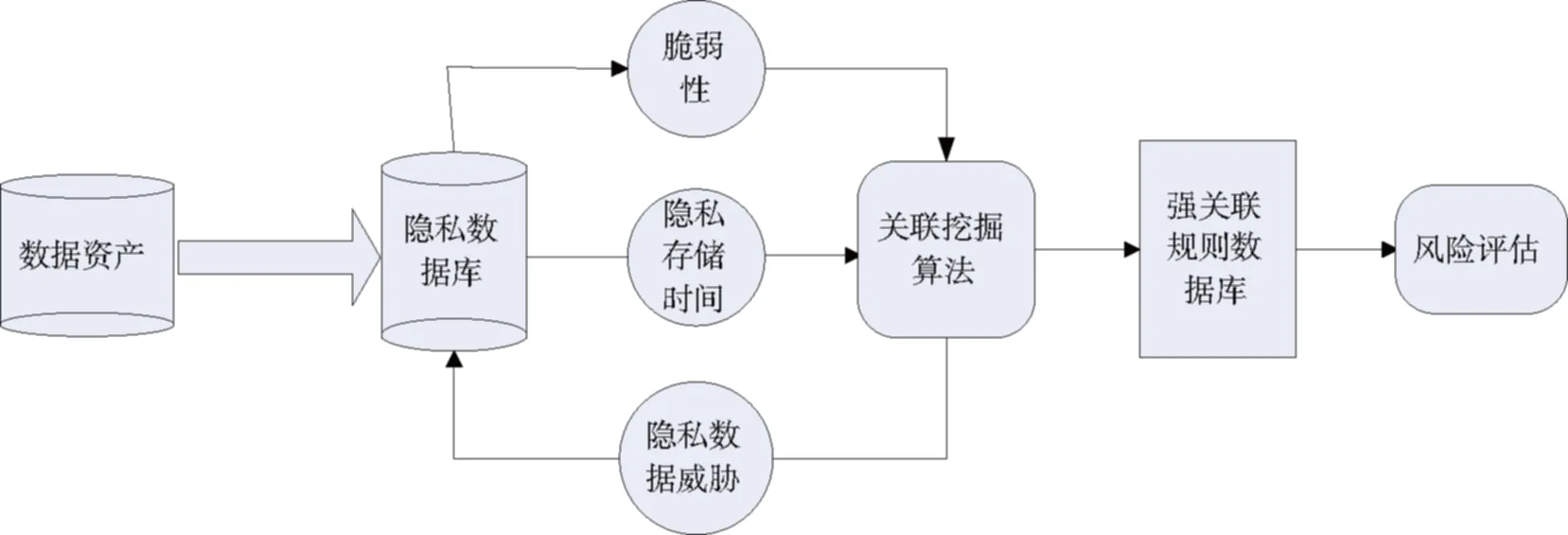
图1 隐私泄露风险评估
隐私管理方在不断获得用户隐私数据信息的时候,会结合自身软硬件设施的强弱而考虑存储隐私数据的模式。但是,为了便于归类和存储,在数据库结构上通常以大类型保存,脆弱隐私数据库的逻辑结构是一维的形式,在输入存储数据时,一般呈现为表2风格:

表2 数据存储结构
对于脆弱隐私数据库而言,隐私数据呈现多维结构,如威胁因子为两层。所以,在隐私泄露的风险评估应用中,为了使FP-Growth算法能够很好的应用于隐私泄露风险指标体系,设计二维数据库表如表3:

表3 二维数据库表
表中,把项目分割成根项目和子项目,通过这样的设置,隐私信息映射为二维结构表。
4 实例应用
以互联网的用户搜索数据为例[13],抽取其中15条搜索记录,数据预先进行处理,格式为:用户ID、查询词、该URL在返回结果中的排名、点击顺序及点击URL,当用户访问搜索引擎时ID被自动赋值,见表4。在访问互联网数据时,一般规定,当访问内容属于同一个网站时,尽管归属这个网站的子网站不同,将其归为同一网站。

表4 搜索记录表
选取表4中的1、2、5列,依据二维数据库表,将用户个人信息作为根项目,查询值和URL作为子项目,根项目用Ii表示,子项目用Iij表示,则二维交易数据库表见表5。

表5 交易数据库
(1)首先,不妨设最小支持度计数为2,此时有
Support(A⟹B)=P(A∪B)=2/15=13%
(2)对这些隐私泄露信息进行第一次扫描,记录每一项出现的次数。每个记录按次数大小排序,去掉支持度计数小于2的项,得到满足最小支持度的频繁一项集,见表6。

表6 频繁一项集
(3)构造频繁模式树。创建FP-树的根结点,以“null”标记,第二次扫描该隐私泄露数据信息,项目集一次链接到树上,直到最后一项链接完成。通过挖掘条件模式树,最终得到频繁项集,见表7。

表7 强关联规则项
以频繁项集I={I5,I53,I55}为例,我们来分析发生隐私泄露事件以后,各项事件之间相互影响的概率(即风险概率)的大小。
频繁项集I={I5,I53,I55}拥有{I5},{I53},{I55},{I5,I53},{I5,I55}以及{I53,I55}6个非空子项集,各个项集之间的关联规则结果如下:
(1)I5⟹I53,I55,置信度:40%
(2)I53⟹I5,I55,置信度:50%
(3)I55⟹I5,I53,置信度:100%
(4)I5,I53⟹I55,置信度:50%
(5)I5,I55⟹I53,置信度:100%
(6)I53,I55⟹I5,置信度:100%
如果由隐私数据持有方预先给定最小置信度阈值为70%,则可以得到超过最小置信度阈值的强关联规则有3、5和6三个。即由被点击的URL推出查询结果和用户ID概率为100%;由用户ID和被点击的URL推出查询结果概率为100%,由被点击的URL和查询结果推出用户ID的概率为100%。由此有
R1=P1·I1·T1
=1×ln[(e1.6+e0.9+e0.5)/3]×1.8=1.99
R2=P2·I1·T2
=1×ln[(e1.6+e0.9+e0.5)/3]×1.5=1.66
R3=P3·I1·T3
=1×ln[(e1.6+e0.9+e0.5)/3]×1.9=2.10
则对于整个隐私库,隐私泄露风险向量为R=(R1,R2,R3)=(1.99,1.66,2.10)。
5 总结
本文通过对隐私数据资产的定义以及威胁等的分析,综合隐私资产、隐私威胁因子以及隐私存储有效时间建立风险评估指标体系,引进关联规则算法,建立与隐私泄露风险评估指标体系匹配的二维数据表,利用FP-Growth算法找出频繁项集和强关联规则,通过计算得到风险向量。但是,由于该模型尚处于探索阶段,在大数据环境下,由于数据量大,隐私泄露风险评估估计会有一些困难。在未来的工作中,我们需要对FP-Growth算法进行一定的改进,使之能够在Spark下运行,达到省时高效的目的;与此同时,寻求其他不同的方法,解决大数据环境下的隐私泄露风险评估问题。
[1] 孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-169.
[2] National Bureau of Standards. Guideline for Automatic Data Processing Risk Analysis[S]. USA:Federal Information Processing Standards Publication FIPS 65, 1979.
[3] James W Meritt. A Method for Quantitative Risk Analysis[EB/OL].[2015-11-04].http://csrc.nist.gov/nissc/1999/proceeding/papers/p28.pdf ,2000: 7-10.
[4] Bedford T M, Cooke R M. Probabilistic Risk Analysis: Foundationa and Methods[J]. Probabilistic Risk Analysis Foundations & Methods, 2001, 13(5):61.
[5] Bilge Karabacak,Ibrahim Sogukpinar.ISRAM:information security risk analysis method[J].Computers & Security,2005,24:147-159.
[6] Kondakci S. Network Security Risk Assessment Using Bayesian Belief Networks[C]// Proceedings of the 2010 IEEE Second International Conference on Social Computing.USA:IEEE Computer Society, 2010:952-960.
[7] Liu Peiyu.The New Risk Assessment Model for Information System in Cloud Computing Environment[J].Procedia Engineering,2011(15):3200-3204.
[8] Guo-hong Gao.Information Security Risk Assessment Based on Information Measure and Fuzzy Clustering[J].Journal of software,2011,11(6):2159-2166.
[9] Bernardo,Danilo Valeros.Security risk assessment:Toward a comprehensive practical risk management[J].International Journal of Information and Computer Security (IJICS),2012,5(2):77-104
[10] Kresimir Solic,Hrvoje Ocevcic.The information systems’security level assessment model based on an ontology and evidential reasoning approach[J].Computers & Security,2015,55:100-112.
[11] Agrawal R, Imielinski T, Swami A. Mining association rules between sets of items in large databases[J]. Acm Sigmod Record, 1993, 22(2):207-216.
[12] HAN J, PEI J, YIN Y. Mining frequent patterns without candidate generation[J]. Acm Sigmod Record, 2000, 29(2):1-12.
[13] LIU Y, MIAO J, ZHANG M, et al. How do users describe their information need: Query recommendation based on snippet click model[J]. Expert Systems with Applications, 2011, 38(11):13847-13856.
(责任编辑:周晓南)
Privacy Disclosure Risk Assessment Model Based on Association Rules
KUANG Qingqing1,PENG Changgen1*,DING Hong2
(1.College of Science, Guizhou University, Guiyang 550025, China; 2. Institute of Cryptography & Data Security, Guizhou University, Guiyang 550025, China)
The traditional information security risk assessment is less involved in the privacy disclosure risk caused by association analysis of the background knowledge. For the problem of big data’s privacy disclosure based on association analysis, privacy asset, privacy threat factors and effective time for privacy storage were combined to establish risk index system of privacy disclosure. Besides, risk function was defined; with analysis association rules of privacy and frequent items , association probability of satisfying a minimum support threshold was generated; In addition, an example verification shows that the model can effectively evaluate privacy disclosure risk.
privacy data; privacy disclosure; FP-Growth; association rule; risk assessment; big data
1000-5269(2016)02-0088-05
10.15958/j.cnki.gdxbzrb.2016.02.20
2015-11-04
国家自然科学基金项目资助(61262073);全国统计科学研究计划基金项目资助(2013LZ46);贵州省统计科学研究课题项目资助(201511)
邝青青(1988-),男,在读硕士,研究方向:密码学理论与工程,Email:631463293@qq.com.
彭长根,Email:peng_stud@163.com;
TP309
A
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
当代陕西(2019年15期)2019-09-02 01:52:00
计算机应用(2018年5期)2018-07-25 07:41:26
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
轴承(2015年2期)2015-07-25 03:51:04
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
电讯技术(2011年11期)2011-04-02 14:00:37
当代修辞学(2011年2期)2011-01-23 06:39:12
