
基于LDA和SVM的中文文本分类研究
2016-09-24 01:31宋钰婷徐德华同济大学经济与管理学院上海200092
现代计算机 2016年5期
宋钰婷,徐德华(同济大学经济与管理学院,上海 200092)
基于LDA和SVM的中文文本分类研究
宋钰婷,徐德华
(同济大学经济与管理学院,上海200092)
0 引言
在庞大的网络中,大多数信息是以文本形式进行存储的,文本自动分类作为重要的文本挖掘方法,成为目前机器学习研究的一个重点。文本自动分类的研究主要包括三个基本步骤:文本预处理、特征提取和特征权重计算、分类器构造等[1]。
特征空间的高维度是文本分类的一个重要问题,而特征提取是解决特征维度高和稀疏性的关键途径[2]。因此,本文着重改进特征提取算法。特征提取方法主要有以下四种:文档频率(Document Frequency,DF)、互信息(Mutual Information,MI)、信息增益(Information Gain, IG)和卡方统计(CHI)。四种特征提取方法都各有优劣,其中主要在于这几种方法对于低频词过度倚重,忽视了词与文档自身的关系[3]。本文选择卡方统计特征提取方法作为主要研究对象之一。同时,通过LDA(Latent Dirichlet Allocation,LDA)可以解决传统的文本分类的不足,能够从语义出发考虑相似性的度量。并且,支持向量机(Support Vector Machine,SVM)能够处理高维数据,降低稀疏性的影响[4],是较为合适的文本分类器。因此,本文从语义出发,提出LDA和SVM相结合的文本分类算法,将LDA与卡方统计方法相结合,并与其他三种特征提取方法进行对比,以解决低频词问题,最后通过SVM进行分类,实验结果证明该算法能够提高分类精度和分类效果。
1 文本分类相关研究
1.1特征提取
文本分类是指将文档自动分组到预定义的类别中。文本通过文本分类的处理后能够提高的检索和使用效率。传统的文本分类直接通过文本数据空间进行表示,但是被抓取的文本通常依赖于高维度的特征空间,这也是文本分类的一个挑战[6]。特征提取是一种降维的有效方法。特征提取是指从原始数据中提取出有效的特征词,用提取的特征可以表示分类文本。Rogati 和Yang[7]等人对几种常见的特征提取方法进行改进,实验证明改进后的MI、IG和CHI分类效果有一定的提高。以下三种特征提取方法将在本文中进行对比实验。
(1)互信息
互信息是指用来衡量某个特征和特定类别的相关性,计算出特征词t和类别C的相关联的信息量。互信息没有考虑类间分布和类内出现的频数等因素,刘海峰等人[8]在此基础上引入特征项的频数信息,提高了特征提取的准确率。
(2)信息增益
信息增益是指某个特征词在整个文本分类系统中存在与否的信息量的差值,即指该特征文本分类系统带来的信息量。信息增益缺乏对于特征项词频的考虑,刘庆和[9]等人综合考虑频度、分散度和集中度对IG进行了改进,提高了其分类精度。
(3)卡方统计
卡方统计的特征选择方法常常用于检测两个事件的独立性,可以用来度量词项t与类别C之间的相关程度,两者之间关系类似于具有一维自由度的Z分布。卡方统计忽略了单一文档中的出现次数,仅仅从统计特征的角度进行特征提取。针对此问题,裴英博等人[10]通过去除特征项与类别负相关的情况,考虑频度等因素,改进了卡方统计算法,分类效果得到一定程度的提高。
以上三种特征提取方法均仅考虑特征候选词出现的文档数,过度倚重低频词,其改进方法也是通过结合频度等因素。Basu等人[11]通过实验证明了传统的特征提取方法在处理词和文档本身关系上有很大的不足。因此,在此基础上,本文从语义角度,提出结合LDA对传统卡方统计算法进行改进。
1.2LDA主题模型
LDA模型是由Blei等人在2003年首次提出,也被称为三层贝叶斯概率模型,包含词、主题和文档结构[12]。
它将一篇文档看作词向量的集合,其生成过程如下:首先对于一篇文档d,文档与主题满足一个多项式分布,主题与词汇表中的词也满足一个多项式分布,这两个多项式分布分别带有超参数α和B的狄利克雷先验分布。这样,对于一篇文档的构成,可以看成是,首先从文档主题分布θ中抽取一个主题,然后从抽取到的主题所对应的词分布Ø中抽取一个词,重复上述过程N次,即可以构成一篇含有N个词的文章。其概率模型公式如公式(1)所示。
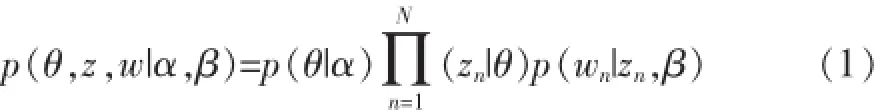
通过LDA,即可以获得词在主题上的概率分布(公式2),以及文章在主题上的概率分布(公式3),其中K表示主题数,Cwk表示词w被赋予主题k的次数,Cdk表示文档d被赋予主题k的次数。


1.3文本表示方法
在提取特征词后,需要将文档用所提取的特征词来表示。向量空间模型(VSM)是使用较多且效果较好的表示方法之一。在该模型中,文档空间被看作是由一组正交向量组成的向量空间。若该空间的维数为n,则每个文档d可被表示为一个实例特征向量d⇀={w1,w2,…,wn}。wn指第n个词在文档d中的权重。
本文利用TF-IDF公式来计算词的权重。见公式(4)。

其中tfji指的是第i个词在文档j中出现的频数,dfi指的是包含第i个词的文档数,N指所有文档总数。
1.4文本分类器
随着文本检索和分类的需求迅速增长,文本自动化分类的研究成果发展迅速。如今,已经有相当多的数据分类方法和机器学习技术被应用到文本分类当中,其中包括支持向量机 (SVM)、贝叶斯算法、K最近邻(KNN)、决策树等分类算法[13]。
支持向量机[14]是由Joachims首先运用到文本分类中,和其他分类算法相比,SVM具有较好的稳定性和分类效果[15]。本文采用SVM构建分类器。
2 基于LDA和SVM的文本分类
结合LDA和SVM的中文文本分类流程如下,如图1所示:

图1 文本分类流程图
2.1文本预处理
本分词作为中文文本分类的文本预处理重要的步骤,相比英文文本,中文文本分类需要对没有空格进行区分的中文文本进行分词处理。本文选择的是由张华平博士带领团队研制的ICTCLAS汉语分词系统。
首先将文本分为训练集和测试集。然后对文本进行分词、去停止词等操作,并将处理好的数据按照一定格式进行存储。
2.2结合LDA主题模型的特征提取
卡方统计、信息增益和互信息都没有从语义的角度考虑,仅仅从统计的角度来提取特征词,本文将以卡方统计为例,详细描述如何通过结合主题模型,从语义的角度提取特征词。
然后选择形容词和名词作为特征词的候选词语,利用卡方公式,对某一类别下,例如财经类,计算出该类别下所有候选特征词的卡方值,例如“股票”在财经类别下的卡方值。其计算公式见公式(5):

式中,A表示包含词项t又属于分类C的文档数目,B表示包含词项t不属于分类C的文档数目,C表示不包含词项t但属于分类C的文档数目,D表示既不包含词项t又不属于分类C的文档数目。N代表所有文档总数。
接着,选择该类下包含该词次数最多的文档,例如在财经类下,包含“股票”一词最多的文档为Di,采用公式(6)计算“股票”与该文档Di在主题分布下的关联度。某一词语和某文本的主题关联度,即该词能在主题上代表该文本的程度。如果出现多个包含该词最大数目相同的文本,则选择该词与文本关联度最大的值,作为该词与该文本的关联度。
接着,把所有包含词Ti的文档聚为该类下的一个子类,称为词子类C⇀,其他不包含该词的文档称为非Ti词子类。对于词的关系,可以用刚刚算出的词与包含该词次数最多文档的关联度近似表示。

那么,词Ti与类C的主题关联性即可表示为公式(7)。
最后,将语义特征与统计特征(如互信息、信息增益、卡方统计等)相结合,例如结合X2值以及基于潜在语义主题的sim值,得出最终X2,如公式(8)所示。
最后根据这个结果,找出排名在前即特征值较高的词,作为某一分类下的特征词。
2.3特征权重计算及分类模型
对于特征权重计算,本文仍然是采用传统的TFIDF值来表示特征词的权重,从而将文档表示为一组特征向量。
在选出特征词,并计算出权重之后,本文采用LIBSVM算法进行文本分类。本文采用的是SVM分类器模型,并将文档的输入形式表示为:类别C特征词1编号:特征词1权重特征词2编号:特征词2权重…其核函数选取的是径向基内核(RBF)。其中特征词序号来自于选出的所有特征词的集合,特征值为TF-IDF计算得到的值。LIBSVM读取训练数据得到训练模型,并对测试集进行分类预测,最终得到分类准确率。
3 实验结果及分析
为了进一步考察改进后方法的效果及效率,本文进行了如下实验。
3.1实验收据
本实验使用的是搜狗实验室中文新闻语料库,总共有8个分类,每个分类下有1990篇文档,其中1590篇用作训练集,400篇用作测试集。如表1所示。

表1 实验数据训练集测试集及类别分布情况
3.2评价指标
文本分类中普遍使用的性能评估指标有:查全率R(Recall)和查准率P(Precision),其中查全率为类别C下正确分类文档数与C类测试文档总数之比,查准率为正确分类文档数与被分类器识别为C类的文档数之比。
F-measure,用来衡量的是查全率和查准率的综合,以及对它们的偏向程度。
3.3实验结果分析
本实验将LDA分别与卡方统计、互信息和信息增益进行结合,利用改进后的特征提取方法提取特征词并将卡方统计与其他两种特征提取方法的分类效果进行比较。
(1)LDA主题数K的比较
在训练LDA主题模型时,由于需要先给出主题K的值,因此实验分别选择了主题数为20,30,40,60,80,100,120等进行比较,计算出不同方法与LDA结合时的分类性能,图中横坐标为不同的主题数目,纵坐标为F值,选取的特征词个数为8000,如图2所示。

图2 特征词个数为8000,不同主题数的分类结果

图3 主题数为60,不同特征值维数的分类结果
从图2中可以看出随着主题数目的增长,分类性能虽然越来越好,但效果变化并不大。而随着主题数目的增长,训练LDA模型所需要的时间却越来越长,即消耗很大的代价,却只得到了一点提高。因此综合考虑,本文选取60作为主题数目。
(2)特征词数目的比较
为了考察选取的特征词数目对文本分类效果的影响,本文选取了 400,1600,3200,4000,6400,8000,9600,11200,128000,16000个特征词进行比较,分别采用chi、chi+lda、ig、ig+lda、mi、mi+lda得出文本分类的性能,见图4.图中横坐标为特征词个数,纵坐标为F值,选取的LDA主题数为60。
从上图3可以看出,本文提出的结合LDA的特征提取算法均比原来的方法分类效果好;另外随着特征词个数的增多,每一种方法的分类性能也有提高,但是当特征词个数过多时,除了会导致维度灾难,也可能会因为过多无用的词或分类特征不明显的词被当作特征词,从而导致分类性能下降。所以在分析比较三种方法分别与LDA结合后的性能时,选取8000作为特征词的数目。
(3)三种方法与LDA结合的比较
本实验选择主题数K为60,特征词数为8000,分别计算出chi、chi+lda、ig、ig+lda、mi、mi+lda在不同分类下的查准率、查全率以及F值,实验结果如下表2、3、4所示。

表2 CHI和LDA结合分类结果

表3 IG和LDA结合分类结果

表4 MI和LDA结合分类结果
从上面三个表中可以看出,三种特征提取方法在与LDA主题模型结合后的分类效果都有一定程度的提高,在不同分类下均能有3%到6%的提高。特别是与CHI结合时分类效果较明显。因为CHI在选取特征词时倾向于选取那些词频相对较低的词语,而这些词在某些分类中并不能很好的代表该类下的特征词,在与LDA结合后,由于LDA从语义的角度计算词的权重,一定程度上能够很好地改善CHI低频词的选取,从而提高分类的性能。
4 结语
文本分类涉及到文本表示、相似度计算和算法决策等多种复杂的技术,特征选择在文本分类中具有重要作用。本文研究并改进了传统的特征选择方法,结合LDA主题模型计算出词和文档的语义关系,避免了低频词的夸大处理,实验结果表明提出的方法对分类效果提高是有效的,卡方统计、信息增益、互信息等结合LDA后分类效果都有明显提高。其中卡方统计的分类准确率提高较为明显。下一步的研究方向是针对不同的特征提取方法分别设计出不同的与LDA结合的算法,以更好地利用LDA进行文本分类;同时在进行特征值计算时,也可以结合LDA主题信息计算。
[1]Dash M,Liu H.Feature Selection for Classification[J].Intelligent Data Analysis,1997,1(1):131-156.
[2]Yang Y,Pedersen J O.A Comparative Study on Feature Selection in Text Categorization[C].ICML.1997,97:412-420.
[3]代六玲,黄河燕,陈肇雄.中文文本分类中特征抽取方法的比较研究[J].中文信息学报,2004,18(1):26-32.
[4]李志清.基于LDA主题特征的微博转发预测[J].情报杂志,2015,34(9):158-162.
[5]李锋刚,梁钰.基于LDA-WSVM模型的文本分类研究[J].计算机应用研究,2015,32(1):21-25.
[6]Wang Z,Qian X.Text Categorization Based on LDA and SVM[C].Computer Science and Software Engineering,2008 International Conference on.IEEE,2008,1:674-677.
[7]Rogati M,Yang Y.High-Performing Feature Selection for Text Classification[C].Proceedings of the Eleventh International Conference on Information and Knowledge Management.ACM,2002:659-661.
[8]刘海峰,姚泽清,苏展.基于词频的优化互信息文本特征选择方法[J].计算机工程,2014,40(7):179-182.
[9]刘庆河,梁正友.一种基于信息增益的特征优化选择方法[J].计算机工程与应用,2011,47(12):130-134.
[10]裴英博,刘晓霞.文本分类中改进型 CHI特征选择方法的研究[J].计算机工程与应用,2011,47(4).
[11]Basu T,Murthy C A.Effective Text Classification by a Supervised Feature Selection Approach[C].Data Mining Workshops(ICDMW),2012 IEEE 12th International Conference on.IEEE,2012:918-925.
[12]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet Allocation[J].the Journal of Machine Learning Research,2003,3:993-1022.
[13]Sebastiani F.Machine learning in Automated Text Categorization[J].ACM Computing Surveys(CSUR),2002,34(1):1-47.
[14]Chang C C,Lin C J.LIBSVM:A Library for Support Vector Machines[J].ACM Transactions on Intelligent Systems and Technology(TIST),2011,2(3):27.
[15]Joachims T.A Support Vector Method for Multivariate Performance Measures[C].Proceedings of the 22nd International Conference onMachine learning.ACM,2005:377-384.
LDA;CHI;Text Classification;SVM
Research on Chinese Text Classification Based on LDA and SVM
SONG Yu-ting,XU De-hua
(School of Economics and Management,Tongji University,Shanghai 200092)
1007-1423(2016)05-0018-06
10.3969/j.issn.1007-1423.2016.05.004
宋钰婷(1991-),女,江苏泰州人,硕士研究生,研究方向为信息管理与信息系统
2016-01-07
2016-02-18
针对中文文本分类中特征提取的语义缺失和低频词问题,提出一种基于LDA和SVM的中文文本分类算法,首先将LDA与卡方统计特征提取算法结合,根据计算结果得到Top k个指定数目的词项作为特征词,使用SVM进行分类,并与互信息、信息增益进行对比,结果分析显示与主题模型相结合的卡方统计特征提取方法有更高的分类精度。
LDA;卡方统计;文本分类;SVM
徐德华,男,副教授,硕士生导师,研究方位为管理信息系统、电子商务
Against the Chinese text classification feature extraction of semantic loss and low frequency words,proposes a text classification algorithm based on LDA and SVM,which describes CHI feature extraction method combining LDA,according to the results obtained Top k items of specified number of lexical items as feature words,uses SVM classification to realize text classification,compares respectively with mutual information and information gain.The results of the analysis proves that combining CHI feature extraction methods with the topic model have higher classification accuracy.
猜你喜欢
临床肝胆病杂志(2022年6期)2022-11-25
汽车实用技术(2022年16期)2022-08-31
计算机技术与发展(2022年8期)2022-08-23
现代电生理学杂志(2021年3期)2021-12-05
计算机系统应用(2021年9期)2021-10-11
现代信息科技(2020年18期)2020-02-22
数学学习与研究(2019年12期)2019-08-07
计算机应用与软件(2018年1期)2018-02-27
计算机应用(2016年10期)2017-05-12
电脑知识与技术(2016年1期)2016-03-22
