
融合用户实时搜索状态的自适应查询推荐模型*
2016-09-20 09:00:45李竞飞商振国宋大为
计算机与生活 2016年9期
李竞飞,商振国,张 鹏,宋大为
天津大学 天津市认知计算与应用重点实验室,天津 300072
融合用户实时搜索状态的自适应查询推荐模型*
李竞飞,商振国,张鹏+,宋大为
天津大学 天津市认知计算与应用重点实验室,天津 300072
传统的查询推荐算法通过挖掘查询日志为用户推荐查询词。通常现存模型只考虑原始查询词与推荐词之间的关系(例如语义相似性或相关性等),没有考虑用户在搜索过程中的满意度情况。针对用户在搜索过程中表现出的不同满意度状态,提出了一个查询推荐基本假设,并通过开展在线用户问卷调查,验证了这一假设。基于相应的假设,提出了一种基于用户搜索满意度状态的自适应查询推荐模型,该模型可以为用户智能推荐不同种类的查询词。当用户对搜索结果满意时,模型将为用户提供更加新颖的推荐词;当用户对搜索结果不满意时,模型将为用户提供一些增强信息表示能力的查询词。大规模日志实验表明,提出的推荐模型显著优于传统的查询流图模型,证明了所提模型的有效性。
查询推荐;查询流图;搜索状态;满意度
1 引言
查询推荐已经成为现代搜索引擎(例如百度、必应和谷歌等)必备的功能之一。虽然现有的查询推荐算法已经能够满足用户的基本需求,但是查询推荐的准确性和智能性还有待进一步提升。为了提高查询推荐质量,研究人员已经提出了大量的查询推荐模型[1-4]。许多经典的查询推荐模型是基于查询日志提出的,例如查询流图模型(query flow graph,QFG)[3]。然而,现有的推荐模型有一个明显的缺陷,即在为用户推荐查询词时,并没有考虑用户当前的搜索状态。本文所指的搜索状态是用户搜索信息过程中,表现出来的对搜索结果是否满意的一种实时状态。为了解决这个问题,本文提出了一种基于查询流图模型的新颖查询推荐模型,可以根据用户当前的搜索状态提供相对原始查询更新颖的或者增强相关性的推荐词。
经典的查询流图模型是一种以查询为节点,以查询之间的转移关系为边的有向图。基于查询流图的推荐模型可以建模全局用户的查询转移关系,反应查询推荐过程中的群体智慧。然而基础的查询流图仅考虑了原始查询与候选推荐词之间的静态转移关系,并没有考虑用户实时的搜索满意度状态。
为了使系统推荐的查询词能自然地适应用户在不同状态下的信息表示需求,本文根据用户的实时搜索状态,对每一个候选推荐词重新赋权重,从而为用户推荐期望的查询词。
为了实现这一目标,本文提出了一个假设,即搜索引擎应该依据用户不同的交互状态提供不同类型的查询推荐词。设想一个真实的搜索场景(如图1所示),一个用户通常输入一个原始查询词作为一次搜索任务的开始,搜索引擎返回一系列结果。随后,用户基于自己的信息需求查看若干可能相关的内容。如果用户对当前的搜索结果已经满意,他可能会中断当前的搜索任务,也可能会提交另一个新的查询;如果用户对当前的结果不满意,他将很有可能修改原始的查询词,重新搜索以期获得更好的搜索结果;另一种极端情况是用户因对当前结果极度失望而放弃搜索或转向其他搜索引擎。通过分析日志发现,这种人机交互行为会频繁出现,本文3.2节的用户实验也进一步证实了这种现象的存在。本文致力于提出一种基于用户搜索满意度的方法建模这种人机交互行为,从而为用户提供高质量的查询推荐词,以引导用户开展高效的探索式查询。
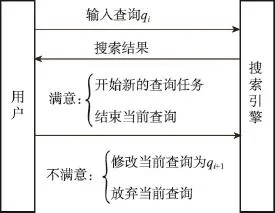
Fig.1 Interactive process of user with a search engine图1 用户与搜索引擎交互过程
2 文献综述
在查询推荐领域,已经存在大量的相关工作。按照查询推荐候选词的来源,可以将现有工作大致分为基于查询日志的推荐[1,5-6]和基于文本集的推荐[7]。按照模型方法分类,现有工作可以分为基于图的模型[4]和基于排序学习的模型[8]。本文提出的自适应推荐模型是以查询日志为推荐词来源,是基于图的推荐模型。
图模型可以方便地用于挖掘日志中查询之间的关系,包括转移关系、语义相似关系等。进而查询之间的关系可以用于未来的查询推荐。Boldi等人开创性地提出了查询流图模型[3],该模型已经广泛应用于基于日志的推荐方法中,并且取得了很好的效果。后续有一系列基于查询流图的工作[9-11]。例如,Adeyanju等人利用查询流图的思想对静态概念层次模型进行动态更新,并用于局域网查询推荐[1]。此外,点击二分图(click bipartite graph)也是一种广泛应用的查询推荐方法[12-14],它基于不同用户可能利用不同的查询词来搜索同一网页的事实,挖掘查询之间的语义相似性。例如,Baeza-Yates等人提出了基于二分图的迭代聚类方法进行查询推荐[6]。
基于排序学习的推荐模型主要思想是利用从日志中提取大量的特征对查询候选词进行排序。Joachims利用排序支持向量机(ranking support vector machine,RankSVM)对聚类得到的候选推荐词进行排序[15]。Liu等人针对难查询(difficult query)利用排序学习算法(learning to rank)直接对候选查询词的搜索结果进行优化,进而达到对候选词进行排序的目的[8]。
现有推荐模型中存在的一个重要问题是,在为候选词排序时,没有考虑用户当前的满意度状态,忽略了用户可能在一些条件下更喜欢相似的推荐词,而一些情况下更喜欢新颖的推荐词的事实。针对这个问题,本文改进了现有的查询流图,探索性地提出了基于用户满意度状态的推荐模型。
3 基本假设及验证
3.1基本假设
本文提出的自适应查询推荐模型,建立在两个基本假设基础上。
假设1当用户对当前搜索结果满意时,希望获得新颖的推荐词;相反当用户对当前搜索结果不满意时,希望修改当前查询并且增强当前查询的相关性表示能力。
假设2用户当前的搜索满意度可以通过用户行为(例如点击和翻页等)进行估计。
第一个假设是为了表明用户在不同搜索状态下希望获取不同类型的推荐词。第二个假设是希望可以探索性地估计用户搜索满意度的量化指标。为了验证这两个基本假设,本文首先利用第三方问卷调查平台(问卷星)开展充分的用户实验。下面详细介绍用户实验的情况。
3.2用户实验设计及结果分析
为了验证本文提出的假设,首先在互联网的真实环境下进行了问卷调查用户实验。问卷调查的题目为《关于用户使用搜索引擎的行为习惯调查》,其中包含9道单项选择题,1道多项选择题。实验采用第三方问卷调查平台(问卷星是国内知名的网络调查问卷平台),以保证此次用户实验的公平、公正和公开性。在实验过程中,设定了防重复填写机制,通过限制IP设定同一手机、电脑只能参与一次调查。每一次调查完毕后,系统给予用户一定的激励。为了保证问卷调查的质量和结果的可靠性,本文设定用户作答问卷的总用时长最少为30 s。本次用户问卷调查共收到174份调查问卷,过滤保留其中154份有效答卷用于结果分析。
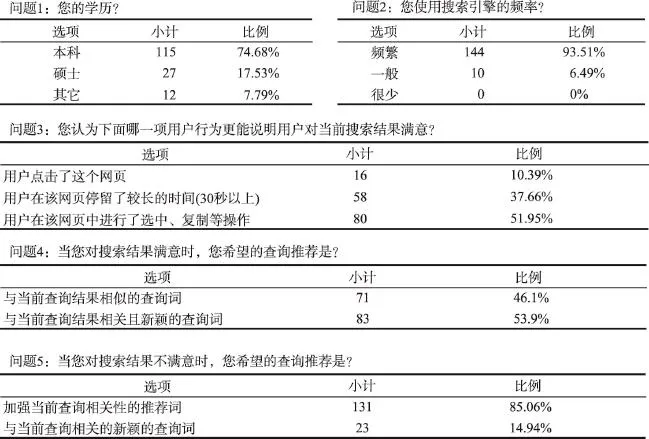
Fig.2 Questionnaires results of user study图2 部分调查问卷结果
通过对有效问卷结果进行分析发现(如图2所示):(1)问卷用户中,74.68%的用户为本科生,17.53%的用户为硕士生,其他学历的用户占7.79%,基本覆盖了所有学历层次的用户。(2)93.51%的用户频繁使用搜索引擎,说明搜索引擎对用户十分重要。(3)关于用户对查询推荐服务的期待,当用户对当前搜索结果感到满意时,53.9%的用户会选择与当前查询相关且新颖的查询词开始下一次的查询;当用户对搜索结果不满意时,只有14.94%的用户选择新颖的推荐词,而85.06%的用户希望修改当前查询,并且获得增强当前信息表达能力的推荐词。这直接验证了本文的假设1,当用户的当前搜索满意度状态不同时,应推荐不同类型的查询推荐词给用户。(4)针对用户对当前满意度的判别,37.66%的用户认为在点击的网页上停留超过30 s即为满意;51.95%的用户认为在当前网页中进行了选中、复制等操作为满意的标志。
本文的实验数据基于必应搜索日志,只记录了用户在当前网页停留的时长,直观上当用户在网页进行阅读、选中和复制等行为用时一般会超过30 s,因此选择当用户点击并且在当前网页停留超过30 s作为用户对一个结果满意度的标识;把用户的翻页行为作为折算因子,直观认识是当用户有翻页行为时,表明用户对当前查询结果不满意,越往后翻页表示满意度越低,这一直观认识是基于用户通过搜索引擎期望得到查询结果是准确而完整的。若用户期望获得更为详细或全面的答案往往需要点击相关网页,并在相关网页内进行详细浏览。本文提及的用户翻页行为指用户在综合搜索引擎结果页的翻页行为,而非在一些专业搜索引擎中的翻页浏览行为。本文探索性地通过分析用户的点击行为和翻页行为提出了估计用户当前满意度的量化指标,也就验证了假设2。
4 自适应查询推荐模型
以下首先介绍了查询流图的基本概念,随后提出了基于用户满意度状态的自适应的查询推荐模型框架。接下来,形式化了构建推荐词候选集的方法,探索性地给出了一种基于用户满意度状态建模方法,以解决框架中的一个关键问题,即对用户当前搜索满意度估计。最后提出了自适应的推荐词排序模型。
4.1查询流图
查询流图是一种常用的日志挖掘模型[3]。它定义为一个有向图Gqf=(V,E,w),其中节点集合V=Q∪{s,t},表示所有用户在历史上提交的所有查询Q和两个特殊的节点s和t,s和t分别代表一个查询链的开始和结束节点;有向边E∈V×V连接同一个查询会话中两个前后邻接的查询;权重w∈(0,1],连接一对查询(q,q′)的边的权重表示为w(q,q′):
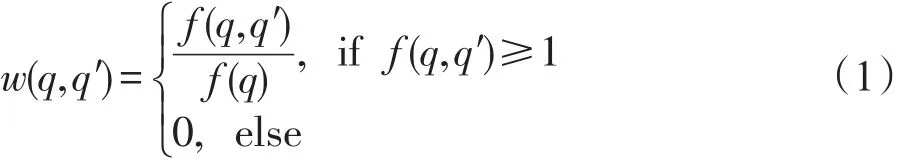
其中,f(q)为查询q在历史日志中出现过的频率;f(q,q′)为查询日志中观测到由查询q转移(改写)为q′的次数。在查询推荐模型中,每一个原始查询将匹配图中的一个查询节点,匹配节点的出边节点,将作为候选推荐词集合。然后按照各自边的权重排序,选取前K个节点对应的查询词推荐给用户。
本文在构建查询流图时,对日志中所有查询词进行词干化(stemming)处理,以保证相同单词的不同形式可以完全匹配。本文构建查询推荐模型以会话为基础,把在30 min之内的所有查询词划分为一次会话。
4.2模型框架
根据第3章中提出的推荐假设以及相应的用户调查结果,理想的推荐模型应该针对用户当前的搜索状态,为用户推荐合理的查询词。为了实现自适应地推荐查询词,本节提出了一个形式化的模型框架。首先通过查询流图模型获取一组候选查询推荐词,同时估计得到用户当前的满意度状态,然后基于用户满意度状态对推荐词候选集进行排序,最后选取前K个候选词推荐给用户。自适应查询推荐模型框架如图3所示。
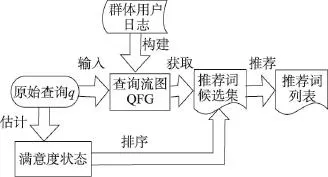
Fig.3 Auto-adaptive query recommendation framework图3 自适应查询推荐模型框架
为了实现模型的自适应推荐目标,需要解决以下3个问题:第一,如何获取足够多的相关候选推荐词;第二,如何估计用户当前的满意度状态;第三,如何根据用户满意度对候选推荐词进行排序,为用户推荐高质量的查询词。下面将分别详细介绍3个问题的解决算法。
4.3候选推荐词集合构建
本文采用的候选推荐词集合由两类节点组成。第一类节点是与原始查询qo模糊匹配得到的节点(No),通过查卡德系数(Jaccard index)[16]为每一个节点赋予初始得分Score(No),具体定义如下:
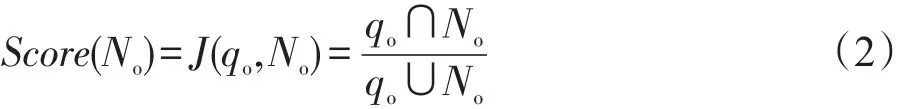
其中,J(∙)是计算两个集合之间查卡德系数的函数,查卡德系数可以衡量两个集合之间的相似度;qo表示一个查询(或节点)的单词集合;No表示图中匹配节点的单词集合。第二类节点是由第一类节点在图中的出边决定的全部节点(Noe),每个节点的初始得分由父节点的初始得分和相应边的权重相乘得到。这样,远离原始查询的推荐节点得分将得到相应的惩罚,具体形式为:
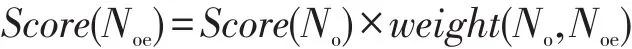
其中,weight(No,Noe)为两个节点之间边的权重。两类节点融合之后作为候选推荐词集合,其中移除重复的节点。
4.4用户搜索状态建模
本文通过用户的点击行为和翻页行为来估计用户对当前查询结果的满意度状态。为了更准确地建模用户的点击行为,本文采用广泛接受的停留时间点击模型来预测用户对一个查询结果(网页)的满意度[17]。点击模型规定,当用户点击一个网页并在这个网页上停留时间超过30 s作为满意点击。本文第3章中所做的用户调查,也可说明30 s的停留时间可以作为用户满意度的一个标识。
为了衡量用户对整个查询列表的满意度,本文基于平均准确率(average precision,AP)[18]的计算方法定义了用户对当前结果的满意度得分SAT(qo)。在计算时,满意点击的网页被看作是相关文档。具体计算如下:

其中,AP(qo)是当前查询的平均准确率;n是用户当前所在的搜索结果页码(考虑用户的翻页行为,并且在用户每次翻页时都会触发查询推荐事件);lb(n+1)是折扣因子。本文假设用户翻页越多对当前查询结果的满意度就越低。AP(qo)的具体计算方法如下:

为了估计式(4)中的参数,在实验数据集的规模上计算了两个邻接查询词AP值的浮动分布概率和平均准确率的变动幅度,如表1所示。
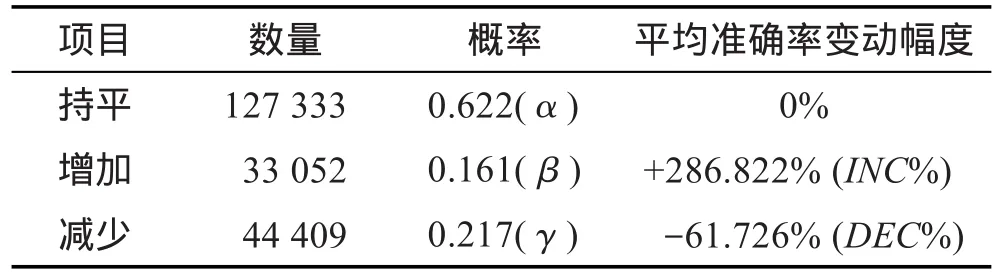
Table 1 Difference ofAP between adjacent queries表1 相邻查询的不同AP值
将表1中统计得到的数据带入式(4)可以化简得到当前查询与邻接前一个查询词的AP值关系为AP(qo)=1.112 2×AP(qpre)。在实际计算中,当前一个查询词的AP值也无法估计时,本文用历史搜索日志的平均AP值(AP=0.324 2)来估计当前查询的AP值。
4.5自适应排序算法
本节介绍自适应推荐排序算法。当用户提交一个原始查询qo时,依据用户对当前搜索结果的满意度状态给出推荐词,即通过自适应排序算法给出最后每个候选词的分数并排序。对于每一个在候选集合中的推荐词s,定义其自适应排序算法的得分Scoreadaptive(s)如下:

其中,novelty(s)和similarity(s)分别表示每一个候选词的新颖性和相似性;Score(s)表示候选词s与原始查询qo的初始匹配得分。
通过式(5),可以很直观地看到,当用户满足于原始查询时,搜索引擎会给出一些新颖性更强的候选词作为推荐查询词。反之,当用户对原始查询结果不满意时,搜索引擎会推荐那些与原始查询更相关的候选词。具体的新颖性函数和相似性函数,形式如下:

其中,D是当前查询的前3个网页结果的摘要和所有满意点击网页的摘要组成的文本,可以认为是对原始查询的扩展表示。本文认为,D中包含了用户已经阅读信息。如果当前候选词与文本D重合较多,说明这个候选词不够新颖。如何更有效地建模新颖性和相似性,将作为未来工作进一步探索。
5 实验
5.1实验数据
实验数据是从必应搜索引擎日志中随机采样得到的查询数据(英文),其中包括1 166个用户从2012 年7月1日到31日提交的522 900个查询。在构建基本的查询流图时,本文采用信息检索领域广泛接受划分会话(session)的方法,将相邻时间间隔在30 min之内的查询词划分为一个查询会话[1-2],则共划分得到134 284个查询会话。图4描述了在实验数据集的日志中每一天的查询数和会话数。
Fig.4 Distribution of session number and query number on 31 days图4 查询会话数和查询数在31天的分布
5.2评价指标
本文实验采用信息检索中常用的NDCG(normalized discounted cumulative gain)[19]作为实验效果的评价指标。
DCG(discounted cumulative gain)是用来衡量排序结果质量的重要指标,表示如下:

其中,n表示返回的推荐词在结果列表中的排序值;rel(j)表示第j个推荐词的相关度;lb(1+j)是折扣因子。归一化的DCG值为nDCG@n=DCG@n/idealDCG@n,其中idealDCG@n是最优排序情况下的DCG评价值。

相关性评价指标需要反映用户在实时搜索状态下的推荐质量。本文将用户在搜索过程中的实际查询修改行为引入到性能评价中,并改进了NDCG中的相关性函数rel(j):其中,qr是原始查询qo在查询日志中的实际查询修改词,作为查询推荐的“标准答案”是n个查询推荐词;qsj表示第 j个推荐词。这样本文的NDCG评价能够真实地反映用户在搜索过程中的实际行为,从而如实地反映模型推荐词的质量。
5.3结果与讨论
在本文实验中,利用第一天到第i天的数据进行训练,第i+1天的数据用于测试。与传统查询流图模型比较的实验结果如图5所示。
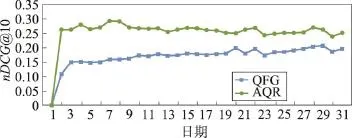
Fig.5 Experiment results of nDCG@10图5nDCG@10的实验结果
图5中横坐标表示天数,纵坐标表示nDCG@10值,结果表明基于实时用户搜索状态改进后的推荐模型显著优于传统的查询流图模型。分析模型表现优异的原因是:(1)通过模糊匹配,得到了更多的查询候选词;(2)本文提出的基于用户当前搜索满意度的模型能够有效调整候选词集合中推荐词顺序,在真实的环境中,更能匹配用户的搜索习惯。
6 结论及展望
本文提出了一种基于用户搜索状态的查询推荐模型。通过用户实验验证了本文提出的假设,即在用户不同搜索状态下,用户喜欢不同类型的推荐词。本文利用跳转页面和点击相关文档的行为来估算用户对当前搜索结果的满意度,并且基于当前满意度,自适应地调整推荐词顺序。
在下一步的工作中,首先将着力优化改进相关算法,重点是对用户当前满意度的估计方法,如Albakour等人提出的自适应的MRR[20]评价指标,并且尝试用多种相关性指标进行衡量,尤其是当用户期望获得全面信息时的用户翻页行为的建模还需要进一步改进。其次对候选词的新颖性和相关性评价工作进行完善,更好地建模推荐词的新颖性和相关性。最后考虑将更多的扩展文档资源融合进本文的模型,扩充原始查询候选词集合。
References:
[1]Adeyanju I A,Song Dawei,Albakour M,et al.Adaptation of the concept hierarchy model with search logs for query recommendation on intranets[C]//Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval,Oregon,USA,Aug 12-16,2012.New York:ACM,2012:5-14.
[2]Adeyanju I A,Song Dawei,Albakour M,et al.Learning from users Ƴ querying experience on intranets[C]//Proceedings of the 21st International Conference on World Wide Web,Lyon,France,Apr 16-20,2012.New York:ACM,2012: 755-764.
[3]Boldi P,Bonchi F,Castillo C,et al.The query-flow graph: model and applications[C]//Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley,USA,Oct 26-30,2008.New York:ACM,2008: 609-618.
[4]Bai Lu,Guo Jiafeng,Cheng Xueqi.Query recommendation by modelling the query-flow graph[C]//LNCS 7097:Proceedings of the 7th Asia Information Retrieval Societies Conference,Dubai,United Arab Emirates,Dec 18-20,2011. Berlin,Heidelberg:Springer,2011:137-146.
[5]Bhatia S,Majumdar D,Mitra P.Query suggestions in the absence of query logs[C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval,Beijing,China,Jul 24-28, 2011.New York:ACM,2011:795-804.
[6]Baeza-Yates R,Hurtado C,Mendoza M.Query recommendation using query logs in search engines[C]//LNCS 3268: Proceedings of the 2004 International Conference on Current Trends in Database Technology,Heraklion,Greece,Mar 14-18,2004.Berlin,Heidelberg:Springer,2005:588-596.
[7]Xu Jinxi,Croft W B.Query expansion using local and global document analysis[C]//Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Zurich,Switerland, Aug 18-22,1996.New York:ACM,1996:4-11.
[8]Liu Yang,Song Ruihua,Chen Yu,et al.Adaptive query suggestion for difficult queries[C]//Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval,Oregon,USA,Aug 12-16, 2012.New York:ACM,2012:15-24.
[9]Bordino I,De Francisci Morales G,Weber I,et al.From Machu_Picchu to rafting the urubambariver:anticipating information needs via the entity-query graph[C]//Proceedings of the 6th ACM International Conference on Web Search and Data Mining,Rome,Italy,Feb 4-8,2013.New York: ACM,2013:275-284.
[10]Bai Lu,Guo Jiafeng,Cheng Xueqi,et al.Exploring the queryflow graph with a mixture model for query recommendation [C]//Proceedings of the 2011 SIGIR Workshop on Query Representation and Understanding,Beijing,China,Jul 24-28,2011.New York:ACM,2011.
[11]Song Yang,Zhou Dengyong,He Liwei.Query suggestion by constructing term-transition graphs[C]//Proceedings of the 5th ACM International Conference on Web Search and Data Mining,Seattle,USA,Feb 8-12,2013.New York: ACM,2012:353-362.
[12]Wu Wei,Li Hang,Xu Jun.Learning query and document similarities from click-through bipartite graph with metadata [C]//Proceedings of the 6th ACM International Conference on Web Search and Data Mining,Rome,Italy,Feb 4-8, 2013.New York:ACM,2013:687-696.
[13]Chen Jimeng,Wang Yuan,Liu Jie,et al.Modeling semantic and behavioral relations for query suggestion[C]//LNCS 7923:Proceedings of the 14th International Conference on Web-Age Information Management,Beidaihe,China,Jun 14-16,2013.Berlin,Heidelberg:Springer,2013:666-678.
[14]Wei Chao,Liu Yiqun,Zhang Min,et al.Fighting against Web spam:a novel propagation method based on clickthrough data[C]//Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval,Oregon,USA,Aug 12-16,2012.New York:ACM,2012:395-404.
[15]Joachims T.Optimizing search engines using clickthrough data[C]//Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Edmonton,Canada,Jul 23-26,2002.New York:ACM,2002: 133-142.
[16]Jaccard P.The distribution of the flora in the alpine zone 1 [J].New Phytologist,1912,11(2):37-50.
[17]Teevan J,Dumais S T,Horvitz E.Potential for personalization[J].ACM Transactions on Computer-Human Interaction, 2010,17(1):4.
[18]Turpin A,Scholer F.User performance versus precision measures for simple search tasks[C]//Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Seattle, USA,Aug 6-11,2006.New York:ACM,2006:11-18.
[19]JärvelinK,Kekäläinen J.Cumulated gain-based evaluation of IR techniques[J].ACM Transactions on Information Systems,2002,20(4):422-446.
[20]Albakour M D,Kruschwitz U,Nanas N,et al.AutoEval:an evaluation methodology for evaluating query suggestions using query logs[C]//LNCS 6611:Proceedings of the 33rd European Conference on Advances in Information Retrieval, Dublin,Ireland,Apr 18-21,2011.Berlin,Heidelberg:Springer, 2011:605-610.

LI Jingfei was born in 1987.He is a Ph.D.candidate at Tianjin University,and the student member of CCF.His research interests include query recommendation,quantum information retrieval and search personalization,etc.He has published 5 papers on international conferences.
李竞飞(1987—),男,河北石家庄人,天津大学博士研究生,CCF,主要研究领域为查询推荐,量子信息检索,个性化信息检索等。

SHANG Zhenguo was born in 1990.He is an M.S.candidate at Tianjin University.His research interests include query recommendation and search personalization,etc.

ZHANG Peng was born in 1983.He received the Ph.D.degree from Robert Gordon University in 2013.Now he is a lecturer and M.S.supervisor at Tianjin University,and the member of CCF.His research interests include information retrieval,quantum cognitive computing and machine learning,etc.He has published more than 20 papers in journals and conferences.
张鹏(1983—),男,山西高平人,2013年于英国罗伯特戈登大学获得博士学位,现为天津大学计算机学院讲师、硕士生导师,CCF会员,主要研究领域为信息检索,量子认知计算,机器学习等。发表20余篇期刊及会议论文,主持1项国家自然科学基金和1项教育部博士点新教师类基金。

SONG Dawei was born in 1972.He received the Ph.D.degree from Chinese University of Hong Kong in 2000. Now he is a professor and Ph.D.supervisor at Tianjin University,and the member of CCF.His research interests include theory and formal models for context-sensitive information retrieval,multimedia and social media information retrieval,domain-specific information retrieval,user behavior,interaction and cognition in information seeking, text mining and knowledge discovery,etc.He has published more than 100 papers in many top tier international journal and conference.
宋大为(1972—),男,河北沧州人,2000年于香港中文大学获得博士学位,现为天津大学计算机学院教授、博士生导师,CCF会员,主要研究领域为信息检索理论与模型,多媒体与社会媒体信息检索,特定领域信息检索,信息检索用户交互与认知,文本挖掘与知识发现等。发表学术论文百余篇,主持英国国家工程和物理科学研究基金委员会基金项目4项,参与国家重点基础研究发展计划(973)2项,主持国家自然科学基金项目1项。
Auto-adaptive Query Recommendation Model Considering UsersƳ Real-Time Search Stateƽ
LI Jingfei,SHANG Zhenguo,ZHANG Peng+,SONG Dawei
Tianjin Key Laboratory of Cognitive Computing andApplication,Tianjin University,Tianjin 300072,China
+Corresponding author:E-mail:pzhang@tju.edu.cn
LI Jingfei,SHANG Zhenguo,ZHANG Peng,et al.Auto-adaptive query recommendation model considering usersƳ real-time search state.Journal of Frontiers of Computer Science and Technology,2016,10(9):1290-1298.
The traditional query recommendation algorithms generate query suggestions by mining query logs of search engines.However,existing models focus more on the relationships(e.g.,semantic similarity or relevance etc.)between original query and candidate suggestions without considering users’search state during the search process.To address this challenge,this paper proposes a basic assumption for query suggestion inspired by the fact that users have different satisfaction states when searching for information,then verifies the assumption by conducting a large scale online user questionnaire.According to the verified assumption,this paper presents an auto-adaptive query recommendation model which is able to provide different categories of queries to users intelligently.In the proposed model,the system will provide new query suggestions to users when they are satisfied with current search results; on the contrary,the system will tend to recommend those query suggestions which are relevant and have more powerful representing ability.Large scale experiments on query logs show that the proposed model outperforms the traditional query flow graph model significantly and demonstrate the effectiveness of the proposed model.
2015-08,Accepted 2015-10.
query recommendation;query flow graph;search state;satisfaction
*The National Natural Science Foundation of China under Grant Nos.61402324,61272265(国家自然科学基金);the National Basic Research Program of China under Grant Nos.2013CB329304,2014CB744604(国家重点基础研究发展计划(973计划));the Specialized Research Fund for the Doctoral Program of Higher Education of China under Grant No.20130032120044(高等学校博士学科点专项科研基金).
CNKI网络优先出版:2015-10-20,http://www.cnki.net/kcms/detail/11.5602.TP.20151020.1041.006.html
A
TP391.3
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
动漫界·幼教365(小班)(2020年6期)2020-05-22 03:46:52
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
中华家教(2018年7期)2018-08-01 06:32:32
儿童绘本(2018年5期)2018-04-12 16:45:32
发明与创新(2018年19期)2018-04-01 03:44:50
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
