
基于Spark的大规模图数据并行计算研究
2016-09-20 07:22:32段剑峰四川大学计算机学院成都610000
现代计算机 2016年7期
段剑峰(四川大学计算机学院,成都 610000)
基于Spark的大规模图数据并行计算研究
段剑峰
(四川大学计算机学院,成都610000)
0 引言
图是一种抽象的数据结构,现实世界中的许多场景都需要用图结构表示,例如在线地图的最短路径、社交网络分析、科技文献的引文网络等。随着Web2.0技术的发展,社交网络用户数量和网页数量猛增,导致图数据规模迅速增长。云计算对于处理大规模图数据[1-2]有诸多优势,然而云计算只提供通用的处理框架,图计算需要复杂的迭代计算和网络通信,采用Hadoop的MapReduce[5]计算框架进行大规模图数据处理,会存在磁盘I/O过多而导致时间代价过高等问题。Spark[3,6-7]利用其内存计算的优势,提供了一套图计算框架Graphx,其中,Pregel类似于MapReduce框架,是一套灵活高效,扩展性强,可供用户自定义的计算框架,适用于图的并行迭代计算。
1 PageRank算法与Pregel计算框架
1.1PageRank 算法
PageRank算法[4]是一种搜索引擎常用的算法,用于计算网页的排名,向用户提供以PageRank值为参考的搜索结果。网页用图顶点表示,网页之间的链接关系用有向边表示。顶点属性表示网页的PageRank值,顶点入度越高,说明指向该网页的链接越多,PageRank值越大。一个顶点的出度为d,则向每个指向的顶点贡献1/d的PageRank值。一个页面有较多的链入页面有较高的PageRank值,如果没有链入页面,则PageRank值为0。为防止页面传出去的值为0,每个页面设定一个最小值。数学公式如(1):
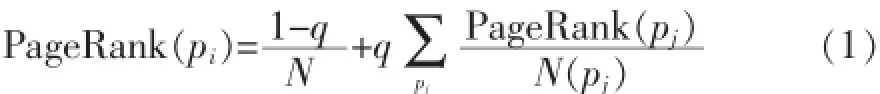
pi∈P,P={p1,p2,…,pN}表示数据集的所有页面,N是页面总数,pj表示链入的页面,N(pj)表示pj链出的页面总数,q是确定页面最小值的可变参数。
算法开始时,为每个页面随机分配一个PageRank值,依据公式(1)进行迭代计算,当|PageRank(pi)t-PageRank(pi)t-1|<着,即本次和上次计算的PageRank值小于某阈值,页面的值趋向稳定,算法迭代结束。
1.2Pregel 计算框架
Pregel计算框架是一个约束到图拓扑的批量同步并行消息抽象的接口。Pregel执行一系列的超步(super steps)运算。每一次超步运算,顶点从之前的超步中接收邻居消息的总和,为顶点计算一个新的属性,向邻居发送更新的属性,判断是否达到收敛条件,如果不收敛,则继续接收邻居消息。类似于Hadoop的MapRe-duce框架,用户需要实现Map和Reduce函数,Pregel框架需要用户实现vprog,sendMsg,mergeMsg三个函数。Pregel定义如下:

VD是图顶点的属性类型,A是消息类型,ED是图的边类型,EdgeTriplet是图的节点对类型。包含两组参数,第一组参数为常量参数,initialMsg是触发图进行迭代计算的初始消息,maxIterations是最大迭代次数,ac-tiveDirection表示有向图的消息传播方向。第二组参数为用户自定义函数,vprog函数功能是根据类型为A的邻居消息总和,将一个节点的属性更新为类型为VD的新属性。sendMsg函数功能是依据节点对中节点和邻居的属性,向邻居发送类型为A的消息。mergeMsg函数功能是将两个邻居的消息合并为一个类型为A的消息。
在传统的图计算框架下,图节点的迭代运算是顺序执行,即一个顶点运算完成后运算下一个顶点。或利用多线程,达到多个顶点并发运算。由于在传统单机环境下,CPU和内存等计算资源受到限制,多线程方式受到限制。在分布式环境下,Pregel高效并发执行。图的每个顶点运算是独立的,vprog,sendMsg,mergeMsg三个函数针对每个顶点,分别在不同计算节点并行运算。其中,mergeMsg在各计算节点分别进行合并,大大提升了运算效率。
2 PageRank算法并行化
PageRank算法中,各节点运算只依赖于本身和其邻居节点,故适合于使用Pregel计算框架实现。本文给出了PageRank算法在Pregel框架下的一种实现,核心为实现vprog,sendMsg,mergeMsg三个函数。为方便计算,将图的顶点属性初始化为PageRank=0和 差值σ= 0,边属性初始化为顶点的,表示顶点能向其他每个邻居贡献的PageRank值比例。
2.1PageRank 值更新
vprog函数根据节点本身的PageRank值和所有链入的邻居合并后的PageRank值计算新的PageRank值。返回新的节点属性和差值,节点属性用于下次迭代时向链出的邻居发送消息,差值用于在sendMSg函数中判断是否达到收敛。函数实现:

2.2 传播消息
sendMsg函数根据vprog函数的计算后的差值是否大于阈值,向邻居节点发送消息,消息值为节点的PageRank值乘以节点的贡献比值。函数实现:

2.3消息合并
mergeMsg函数将一个节点的任意两个邻居的消息合并为一个类型一致的消息,该操作在从计算节点上执行,提高了运算的并行度,减轻了主计算节点的运算压力,提升了运算速度。函数实现:
3 实验分析
定义顶点数量为10000,20000条连边,顶点属性初始为0的图,分别选取 2000、4000、6000、8000和10000个顶点的子图进行对比实验。实验设备为3台物理机,每台物理机的CPU为2核,内存为4G。实验比较不同计算节点和不同顶点对算法运行时间的影响。
实验表明,并行化的PageRank算法相比传统的单节点实现的算法,运行效率有明显提升。随着图顶点数量的增长,算法的时间消耗成线性增长,说明Pregel计算框架适合于大规模的图数据运算。
另外,实验比较算法迭代次数对算法运行效率的影响。

图1 顶点规模对时间的影响
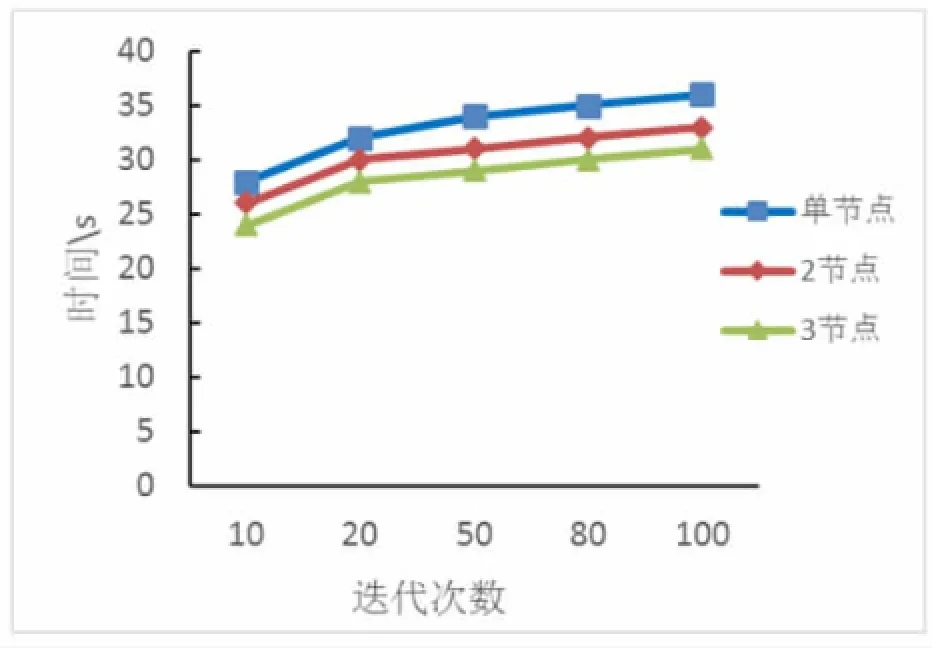
图2 迭代次数对时间的影响
图2可知,随着迭代次数的增加,算法运行时间增长趋于平滑,说明Spark的内存计算模型在迭代计算上体现明显优势,Pregel计算框架适合大规模图数据的迭代算法。
4 结语
本文通过PageRank算法在Spark上的实现,验证了Pregel图计算框架时间效率高,说明Spark处理大规模图数据具有明显的优势。此外,Pregel计算框架供用户自定义接口,具有良好的扩展性,可灵活应用到社交网络分析和社会化推荐等算法中。
[1]Malewicz G,Austern M H,Bik A J C,et al.Pregel:a System for Large-Scale Graph Processing[C].Proceedings of the 2010 ACM SIGMOD International Conference on Management of data.ACM,2010:135-146.
[2]Kang U,Tong H,Sun J,et al.Gbase:a Scalable and General Graph Management System[C].Proceedings of the 17th ACM SIGKDD
International Conference on Knowledge Discovery and Data Mining.ACM,2011:1091-1099.
[3]Zaharia M,Chowdhury M,Das T,et al.Resilient Distributed Datasets:A Fault-Tolerant Abstraction for In-Memory Cluster Computing[C].Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation.USENIX Association,2012:2-2. [4]Brin S,Page L.Reprint of:The Anatomy of a Large-Scale Hypertextual Web Search Engine[J].Computer Networks,2012,56(18):3825-3833.
[5]Hadoop MapReduce Tutorial[EB/OL].http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html.
[6]Spark Programming Guides[EB/OL].http://spark.apache.org/docs/1.1.0/quick-start.html.
[7]Scala[EB/OL].https://www.scala-lang.org.
Research on Large-Scale Graph Parallel Computing Based on Spark
DUAN Jian-feng
(College of Computer Science,Sichuan University,Chengdu 610000)
1007-1423(2016)07-0044-04
10.3969/j.issn.1007-1423.2016.07.010
段剑峰(1989-),男,云南大理人,在读研究生,研究方向为移动与分布式计算
2016-01-26
2016-02-25
1007-1423(2016)07-0065-0410.3969/j.issn.1007-1423.2016.07.015
随着社交网络的兴起,大规模图数据处理技术成为研究的热点,从海量的社交数据中分析数据的关系具有巨大的商业价值。Spark利用其内存计算模型和适合迭代运算的优势,为大规模图数据并行运算提供Graphx框架。以经典的PageRank算法为例,分析Graphx框架下的Pregel迭代计算模型,总结Pregel计算模型的优势和应用场景。
大规模图数据;并行计算;Spark;Pregel
With the development of social network,large-scale graph processing technology become a hot spot of research.Analyzing relationship from massive social data has great commercial value.Taking the advantages of memory-computing model and iterative computation,Spark provides Graphx for large-scale graph parallel computing framework.Analyzes the Pregel iterative computing model under Graphx in the example of classical PageRank algorithm,summarizes the advantages and application of Pregel computing model.
Large-Scale Graph;Parallel Computing;Spark;Pregel
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14
中等数学(2021年9期)2021-11-22 08:06:58
通信产业报(2020年43期)2020-01-15 06:38:43
山东科学(2018年6期)2018-12-20 11:08:58
中国卫生(2014年12期)2014-11-12 13:12:26
中国卫生(2014年8期)2014-11-12 13:00:50
中国卫生(2014年7期)2014-11-10 02:32:52
电脑爱好者(2011年11期)2011-06-22 08:20:18
河北软件职业技术学院学报(2010年3期)2010-06-06 07:18:42
中学生数理化·高一版(2009年6期)2009-08-31 02:58:28
