
自动谣言检测分析与实现
2016-09-20 07:22冯程梁刚周鸿宇杨进四川大学计算机学院成都60065乐山师范学院计算机科学学院乐山64000
现代计算机 2016年7期
冯程,梁刚,周鸿宇,杨进(.四川大学计算机学院,成都 60065;.乐山师范学院计算机科学学院,乐山 64000)
FENG Cheng1,LIANG Gang1,ZHOU Hong-yu1,YANG Jin2(1.College of Computer Science,Sichuan University,Chengdu,Chengdu 610065;2.College of Computer Science,Leshan Normal University,Leshan,Leshan 614000)
自动谣言检测分析与实现
冯程1,梁刚1,周鸿宇1,杨进2
(1.四川大学计算机学院,成都610065;2.乐山师范学院计算机科学学院,乐山614000)
0 引言
随着微博的发展,微博从传统的社交工具转变为用户分享信息的重要来源[1]。截至2015年10月,新浪微博月活跃用户数达到2.2亿,每日发布的微博数超过1亿条[2]。在提供信息便利的同时,微博也面临着谣言泛滥的问题。据2015年中国社科院新闻与传播研究所发布的《新媒体蓝皮书》调查显示,近六成的假新闻首发于微博[3]。谣言是指真相或来源不可靠的消息,其传播会引起公众的恐慌,扰乱社会的秩序,降低政府的公信力,甚至危及国家安全。如2011年的日本核电站泄露事故,有谣言称日本核辐射会污染海水导致以后生产的盐都无法食用,而且吃含碘的食用盐可防核辐射,从而导致了盐价上涨,民众大量抢购食盐[4]。
为了抑制微博谣言泛滥的问题,学术界和相关行业提出了基于手工的识别技术和基于机器学习的识别技术。基于手工的识别技术由人为判别,需较长的时间周期并依赖鉴定者的专业能力。基于机器学习的方法是一种自动识别的技术,它将谣言问题看作分类问题,通过提取谣言和其传播的特征用于训练分类模型。该方法受平台限制,并且特征的设计与选择较为困难。本文在前人基础之上,提出了并实现了一种微博谣言的自动识别系统。由于没有任何一种单一的学习算法在所有情况下都具有优势,不同的学习算法可能会得到类似的结果[5],并且最有效的特征通常对机器学习的结果有着巨大的影响[6],因此有效特征的选择对于谣言检测非常重要。前人的研究集中使用微博的固有特征[7-9],而忽略隐含因素的影响,因此本文在前人的研究基础上提出两个微博的隐特征:赞的数目和置疑度。
1 相关工作
为了识别微博中的谣言,微博服务提供商做了大量的努力。新浪微博推出了名为“微博辟谣”的官方账号,由7名经验丰富的编辑组成,对新浪微博24小时不间断监控。微博辟谣定期收集和判断微博中的谣言消息,并将结果以微博的形式发布,凡是关注该账号的用户都可以及时收到辟谣消息。另外,新浪微博还提出了基于众包技术的“不实消息举报”服务。任何用户都可以通过这个平台举报谣言,最终由微博社区服务中心的编辑进行判断并通过微博展示结果。由于消息的正确性完全由人工判断、识别周期长,这些方法不能有效地识别谣言。
为了解决手工识别方式的缺点,提出了基于机器学习的自动识别技术。Mendoza[7]中从Twitter中提取出68个特征并归为4类:基于内容的特征、基于用户的特征、基于传播的特征和基于话题的特征。后续的一些研究在不同的研究对象上分析出更适合的特征,或者从不同角度发现更具有代表性的特征。如Yang[8]等提出了客户端类型和事件地点两个新的特征;Sun[9]等提出了消息使用的实意动词数、消息是否包含强烈消极词汇等,并针对于图文不符类谣言提出了基于多媒体的特征;Cai[10]根据转发和评论文本簇聚消息得到关键词作为特征。这些研究集中使用微博的固有特征,而忽略了微博中各个实体间的联系和其中隐藏的特征,如微博之间的争议、用户态度等。
2 机器学习问题模型
谣言识别可以看作机器学习中的监督学习,监督学习的任务是通过学习使得模型能够对任意给定的输入,对其相应的输出做出一个好的预测。监督学习的模型可以是概率模型或非概率模型,由条件概率分布P (Y|X)或决策函数Y=f(x)表示。其中X称为输入变量,Y称为输出变量。在监督学习中,输入变量的取值记作x,通常由特征向量表示:
x=(x(1),x(2),…,x(i),…,x(n))
x(i)表示的第i个特征,通常使用xi表示多个输入变量中的第i个,即:
xi=(xi(1),xi(2),…,xi(n))
监督学习从训练数据集中学习模型,对测试数据进行预测。训练数据由输入与输出对组成,通常表示为:
T={(x1,y1),(x1,y1),…,(xN,yN)}
xi∈N哿R表示输入,即特征向量;yi表示输出,即预测结果。测试数据也由相应的输入与输出对组成。监督学习分为学习和预测两个过程,在学习过程中,利用给定训练集学习得到模型,表示为概率模型或决策函数。在预测过程中,对于给定测试样本中的输入xN+1,由模型yN+1=argmaxyN+1P(yN+1|xN+1或yN+1=f(xN+1)给出相应的yN+1。
3 特征
特征选择和提取是机器学习的重要步骤,在文献[8]中列举出了68个特征用于谣言检测。本文分析了微博的特性,使用Best-first策略选择了其中的7个特征,如表1所示。

表1 特征描述
在此基础上,本文分析了微博中包含的隐藏信息,提出了两个新的特征:赞的数目和置疑度。新浪微博中提供了 “赞”的操作用于统计用户对该微博的喜好。Mendoza[7]指出微博平台中的谣言消息通常会比正常消息受到更多的置疑。通过观察发现,对于热点话题,正常消息的“赞”的数目和谣言消息的“赞”的数目存在明显的区别。置疑度定义为评论数与转发数之间的关系,定义为:

评论数通常表示用户对该条消息存在者不同的态度或其他的想法,而转发数通常表示了用户对该条微博存在支持的态度,置疑度表示了用户对微博消息存在不同态度的比率。我们将收集到的数据进行处理,提取“赞”的数目及置疑度与消息之间的关系,使用箱线图描述两个新特征区分消息的能力,得到如图1所示的结果。
如图1所示,“赞”的数目和置疑度对谣言和正常消息有着明显的区分能力。通常正常消息的“赞”的数目会更多。与此同时,谣言的置疑程度也明显区别于正常消息。
4 实验
4.1数据集
本文通过模拟登录weibo.cn页面,构造URL抓取微博数据。数据集中包含了1000条正常数据和1000条谣言数据。在实验过程中,本文使用10则交叉验证
进行训练和验证分类器。
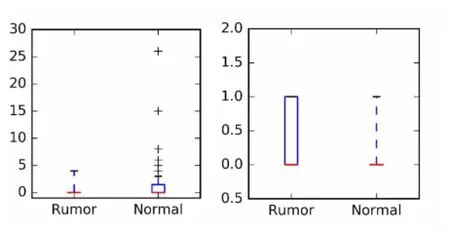
图1 两个新特征对于1(谣言)和2(正常消息)贡献的箱线图
4.2实验结果
本文经过分析,提取出包含了新特征的9个特征用于谣言检测系统,最后使用标准信息检索度量值准确率、召回率和F1来评估方法的性能。精度表示被正确标注的谣言占分类器预测为谣言的比率。召回率表示被正确标注的谣言占真正谣言的比率。F1是精度和召回率的一个综合评价,定义为:

在实验过程中,我们分别使用三种不同的分类算法构造分类器。实验结果如图2所示。
如图2所示,SVM分类器、贝叶斯分类器和决策树分类器的准确率分别是87%、83%和78%,F1分数分别为0.855、0.850和0.765。决策数在三者中精度较低,这是因为特征中有少许的特征分类能力较弱。而从整体结果看出,选择不同的机器学习算法得到的结果是相似的。
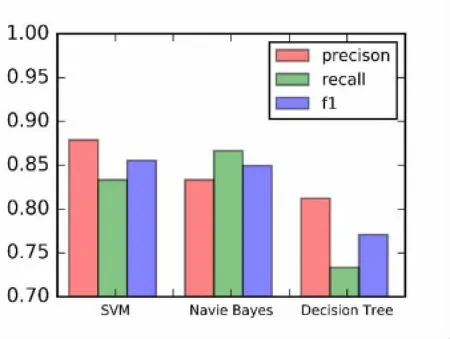
图2 三种不同分类算法结果对比图
5 结语
微博给消息传播提供了一个良好的平台,同时也面临着谣言泛滥的问题,找到一种有效的自动谣言识别方法是非常重要的。本文分析了基于机器学习的分类模型,实现了一个自动谣言检测系统。并挖掘微博中包含的隐藏信息,提出了赞的数目和置疑度两个新的特征。实验结果证明本文提出的方法与特征的可行性和有效性。
[1]M.Mendoza,B.Poblete,C.Castillo,Twitter Under Crisis:Can We Trust What We RT[C].Proceedings of the First Workshop on Social Media Analytics,2010:71-79.
[2]Weibo MAUs 198 Mln in Q1 2015,Up 38%YoY.http://www.chinainternetwatch.com/13364/weibo-q1-2015/.
[3]报告称近六成假新闻首发于微博 周二微信谣言最多.http://www.chinanews.com/gn/2015/06-24/7362797.shtml.
[4]人民日报盘点十大网络谣言军车进京、抢盐风波上榜.http://news.xinhuanet.com/politics/2012-04/16/c1117824495.htm.
[5]J.Friedman,T.Hastie,R.Tibshirani.The Elements of Statistical Learning vol.1:Springer Series in Statistics Springer,Berlin,2001. [6]M.A.Hall.Correlation-Based Feature Selection for Machine Learning.The University of Waikato,1999.
[7]C.Carlos,M.Marcelo,P.Barbara,Information Credibility on Twitter[C].Proceedings of the 20th International Conference on World Wide Web,2011:675-684.
[8]Y.Fan,L.Yang,Y.Xiaohui et al.Automatic Detection on Sina Weibo[C].Proceedings of the ACM SIGKDD Workshop on Mining Data Semantics,2012,13.
[9]S.Shengyun,L.Hongyan,H.Jun et al.Detecting Event Rumors on Sina Weibo Automatically[J].Web Technologies and Applications,2013:120-131.
[10]C.Guoyong,W.Hao,L.Rui,Rumor Detection in Chinese Via Crowd Responses[C].2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining,2014.
Rumor;Social Media;Microblog;Machine Learning
Research and Implementation of Automatic Rumor Detection
1007-1423(2016)07-0040-04
10.3969/j.issn.1007-1423.2016.07.009
冯程(1992-),男,贵州桐梓人,硕士研究生,研究方向为网络安全、机器学习
梁刚(1976-),男,四川成都人,博士,讲师,研究方向为网络安全、智能计算、机器学习
周泓宇(1990-),男,重庆人,硕士研究生,研究方向为机器学习
杨进(1980-),男,四川乐山人,博士,教授,研究方向为网络安全、机器学习
2016-01-26
2016-02-26
FENG Cheng1,LIANG Gang1,ZHOU Hong-yu1,YANG Jin2
(1.College of Computer Science,Sichuan University,Chengdu,Chengdu 610065;2.College of Computer Science,Leshan Normal University,Leshan,Leshan 614000)
针对微博中谣言泛滥的问题,提出一种自动识别谣言的方法。该方法基于机器学习的原理,并在前人的基础上,结合赞的数目和置疑度两个新特征。实验结果显示结合新特征实现的系统在识别谣言上准确率达到82%,验证所提出的方法与特征的可行性和有效性。
谣言;社交网络;微博;机器学习
四川省科技厅项目(No.2014JY0036)、四川省教育厅创新团队基金(No.13TD0014)
Aiming at the spread of rumor in microblog system,proposes an automatic rumor detection method.It is based on the principle of ma-chine learning and combined with the number of pros as well as the number of the doubt on the basis of previous studies.The experiment shows that system with new features reaches 82%accuracy rate.Thus,it proves that system that implemented is feasible and two new fea-tures are efficient.
猜你喜欢
电子产品世界(2022年4期)2022-04-21
环球时报(2022-04-13)2022-04-13
小猕猴智力画刊(2021年6期)2021-08-05
计算机系统应用(2021年2期)2021-02-23
小雪花·小学生快乐作文(2020年4期)2020-10-12
电子技术与软件工程(2019年18期)2019-11-18
民生周刊(2017年22期)2017-12-12
电子技术与软件工程(2017年14期)2017-09-08
新高考·高一数学(2016年10期)2017-07-06
作文大王·低年级(2016年3期)2016-03-11
