
协同过滤推荐算法比较研究
2016-09-20 07:22周泓宇梁刚杨进四川大学计算机学院成都60065乐山师范学院计算机科学学院乐山64000
现代计算机 2016年7期
周泓宇,梁刚,杨进(.四川大学计算机学院,成都 60065;.乐山师范学院计算机科学学院,乐山 64000)
协同过滤推荐算法比较研究
周泓宇1,梁刚1,杨进2
(1.四川大学计算机学院,成都610065;2.乐山师范学院计算机科学学院,乐山614000)
0 引言
随着信息技术的发展,网络数据规模急剧扩大,大数据满足用户对信息需求的同时,带来了信息过载的问题——用户难以从海量数据中快速找到有用的信息[1]。推荐系统从用户的角度出发,根据用户的需求偏好、行为记录等,挖掘出用户可能感兴趣的信息,并主动推荐给用户。
协同过滤是推荐系统中采用的最为广泛最为重要的技术之一[2],其基本思想是具有相似行为的用户对项目的需求也是相似的[3]。协同过滤算法只关注用户的历史行为,不受项目具体属性的限制;并且能够与社会网络相结合,具有较好的推荐精度。其主要类型分为基于内存的协同过滤、基于模型的协同过滤以及组合协同过滤。本文首先介绍三种类型的协同过滤算法,以其中基于用户(项目)的协同过滤算法、基于矩阵分解的协同过滤算法以及基于线性回归的集成策略为例进行详细阐述,然后给出对比实验结果和分析,最后是全文总结。
1 基于用户(项目)的协同过滤算法
基于内存的协同过滤算法包括基于用户的方法和基于项目的方法,大致分为三个步骤:①基于用户-项目评分矩阵,计算用户(项目)之间的相似性;②通过相似度的逆序,选取最相似的前K个用户(项目)作为邻居;③根据邻居的评分,对目标用户(项目)未评分的项进行预测。下面以基于用户的协同过滤算法为例进行详细说明。
定义一个给定的用户集U和项目集S,用户对项目的评分表示为一个m×n的矩阵R,如表1所示。R(i,j)表示用户i对项目j的评分,代表用户对项目的偏好。如MovieLens数据集中用1~5分表示用户的喜爱程度;若R(i,j)=0则表示用户i未对项目j打分。

表1 用户-项目m×n阶评分矩阵R
首先基于用户-项目评分矩阵计算用户之间的相似度,常用的相似度算法包括余弦相似度算法、修正的余弦相似度算法和Pearson相关相似度算法。本文采用余弦相似度算法,把用户的评分看作一个n维的评分向量,第k维的值表示对项目k的评分,设用户u与用户v的评分向量分别表示为向量u和v,则用户u和用户v之间的相似度为:
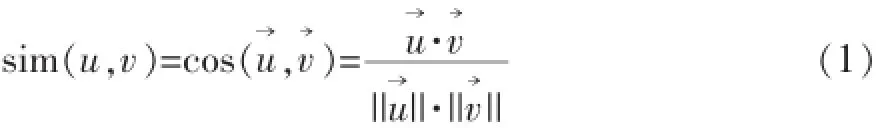
选取与用户u相似度最大的k个用户作为邻居G (u),依据这k个邻居对目标项目j的评分,加权预测用户u对项目j的评分Pu,j,如公式(2)所示。其中,表示用户i评分的均值,Ri,j表示用户i对项目j的评分。
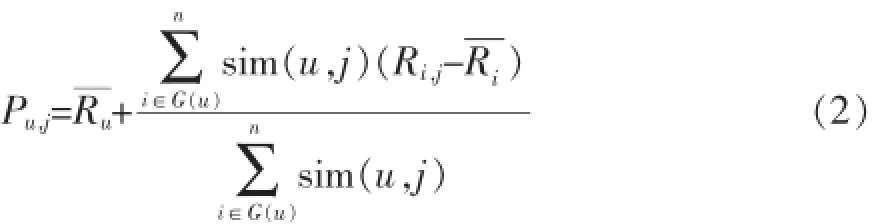
基于项目的方法与基于用户的方法相似,通过计算两两项目的相似性得到目标项目的邻居,并通过项目邻居的评分预测用户对目标项目的评分。两种基于内存的协同过滤算法适用于不同的推荐环境,例如在电子商务中,项目的个数远小于用户的个数,且项目内容相比用户变动更少,因此基于项目的推荐方法有更优的时间复杂度和实时性;而在微博、新闻等方面的推荐则与之相反,使用基于用户的方法更好一些。
2 基于矩阵分解的协同过滤算法
基于模型的协同过滤算法通过对数据集的训练完成对系统复杂模式的识别,并基于学习模型对协同过滤任务做出智能预测,包括基于概率的算法、朴素贝叶斯算法、聚类算法和基于矩阵分解的算法等,其中基于矩阵分解的算法常用于对基于评分的推荐环境[4]。基于矩阵分解的推荐算法是将原本高维度的评分矩阵RM×N分解成两个低维度矩阵PM×D与QD×N的乘积,可将PM×D、QD×N分别看作用户和项目的隐含特征矩阵,其中D表示隐含特征个数[5]。通过多次迭代训练,使得PM×DQD×N不断地逼近评分矩阵RM×N,最后得到最终的P、Q矩阵(P× Q≈R),以此来对未评分的项进行预测。下面以基础的矩阵分解推荐算法为例进行说明。
为使得P×Q≈R,需求P×Q到R的最近距离,即使整个模型的损失最小,如式(3)所示,其中K为所有已评分项。
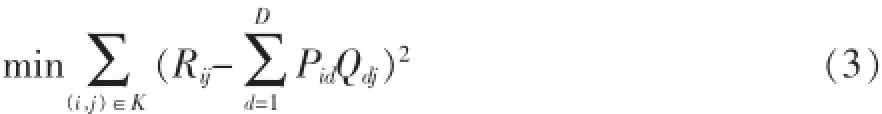

其中,t为迭代次数,α为迭代步长。通过多次迭代得到最终的P、Q矩阵,具体算法如下:

基于矩阵分解的推荐算法关注整个评分矩阵的损失程度,更注重全局性,且空间复杂度较低。
3 基于线性回归的集成策略
基于线性回归的集成策略是将多个弱学习器通过某种线性组合,获得比单个弱学习器效果更好的强学习器的过程,线性系数由回归分析确定。将上述基于用户的方法、基于项目的方法和基于矩阵分解的方法看作三个弱学习器,分别表示为hu(X)、hs(X)和hv(X),强学习器Hw(X)如式(6)所示。
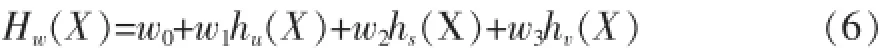
其中,w0,w1,w2,w3为线性系数。便于标记,令h0(X)=1,h(X)=[h0(X),hu(X),hs(X),hv(X)],W=[w0,w1,w2,w3]T,则Hw(X)=h(X)×W。定义实际评分列向量为R(X),整个训练集上的误差平方和如式(7)所示。
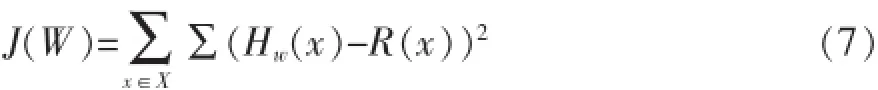
为了使误差平方和J(W)最小,本文采用最小二乘估计法,即:

4 实验结果与分析
4.1实验数据与评价标准
本实验采用MovieLens100K数据集,其中包含了943位用户对1682个项目的100K个评分,并将该数据集的80%作为训练集,剩下20%为测试集。采用平均绝对误差MAE(Mean Absolute Error)作为指标,衡量推荐算法的优劣。设预测的用户评分集合为{p1,p2,…,pC},对应的实际用户评分集合为{r1,r2,…,rC},则平均绝对误差MAE定义如式(9)所示。

4.2实验步骤
为了说明邻居数K对基于用户的协同过滤算法UBCF和基于项目的协同过滤算法IBCF的影响,选取K值从5到35进行测试,如图1所示。从图1中可看出,基于用户的方法和基于项目的方法分别在K取30和K取15时达到最优效果,且前者的误差普遍大于后者。
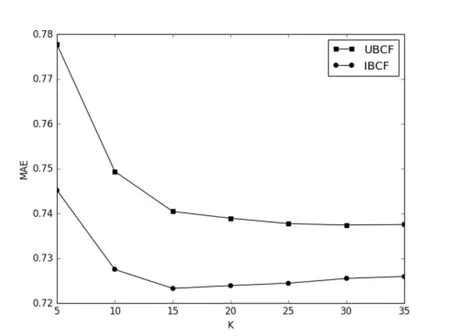
图1 UBCF和IBCF的MAE指标
为了说明隐含特征个数D对基于矩阵分解的协同过滤算法MFCF的影响,分别选取10个,20个,30个,50个进行测试,如图2所示。从图2中可看出,在当前数据集下,MAE值随着D的增加而增加,D取10时,效果最佳。
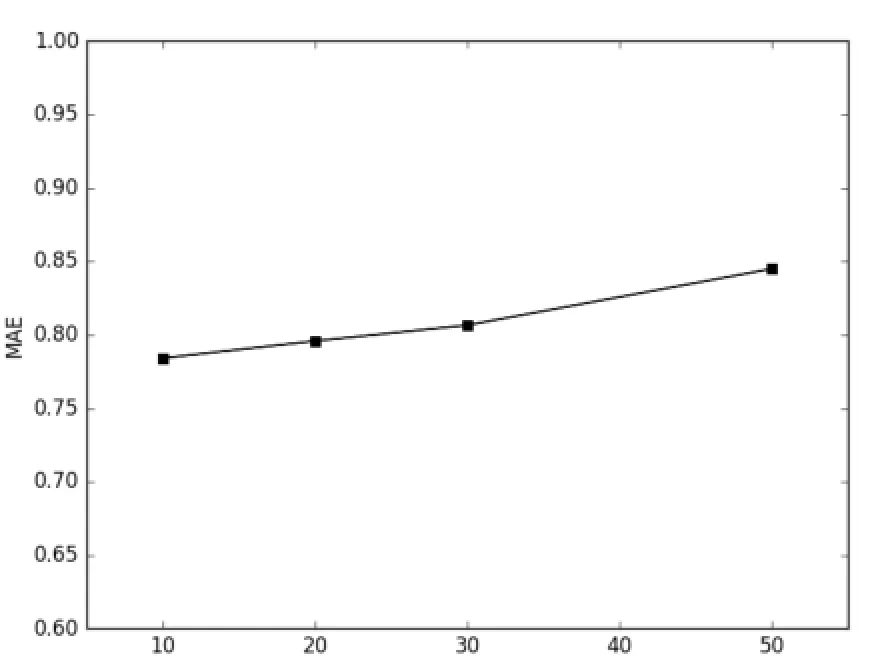
图2 MFCF的MAE指标
为了直观地比较基于线性回归的集成算法LICF与单个学习器算法的优劣,选取每个学习器的最优效果,即分别选择UBCF(K=30)、IBCF(K=15)和MBCF (D=10)作为弱学习器,并与集成后的强学习器作比较,如图3所示。从图中可看出,LICF算法的效果明显优于每个弱学习器。

图3 四种算法MAE指标的比较情况
5 结语
本文就三类协同过滤算法,针对性地对其中基于用户(项目)、基于矩阵分解和基于线性回归集成的方法进行了阐述和比较,然后利用MovieLens的电影评分数据对几种算法的推荐效果进行了验证。实验结果表明,基于线性回归的集成策略比其他单一的协同过滤算法效果好一些。组合推荐的优势明显,然而单个推荐算法的选择和组合策略的方式都是多样化的,如何找到最优的方案还有待进一步解决。
[1]柯良文,王靖.基于用户特征迁移的协同过滤推荐[J].计算机工程,2015,41(1):37-43.
[2]王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66-76.
[3]Candillier L,Meyer F,Boulle M.Comparing State-of-the-Art Collaborative Filtering Systems[J].Machine Learning and Data Mining in Pattern Recognition,2007,11(4):548-562.
[4]Vucetic S,Obradovic Z.Collaborative Filtering Using a Regression-Based Approach[J].Knowledge and Information Systems,2005,7 (1):1-22.
[5]王鹏.基于矩阵分解的推荐系统算法研究[D].北京:北京交通大学.
Recommender System;Collaborative Filtering;Linear Regression;Matrix Factorization
Comparable Research on Collaborative Filtering Recommendation Algorithms
ZHOU Hong-yu1,LIANG Gang1,YANG Jin2
(1.College of Computer Science,,Sichuan University,Chengdu 610065;2.College of Computer Science,,Leshan Normal University,Leshan 614000)
1007-1423(2016)07-0016-04
10.3969/j.issn.1007-1423.2016.07.004
周泓宇(1990-),男,硕士,研究方向为机器学习
梁刚(1976-),男,博士,讲师,研究方向为机器学习、智能计算、网络安全
杨进(1980-),男,博士,教授,研究方向为机器学习
2016-01-15
2016-02-20
推荐系统被广泛用于电子商务、视频网站、新闻小说推荐等各个领域,旨在向用户提供其可能感兴趣的信息。协同过滤是推荐系统的主流技术,分为基于内存的协同过滤、基于模型的协同过滤以及组合协同过滤。以其中基于用户(项目)、基于矩阵分解以及基于线性回归集成策略的协同过滤算法为例进行说明比较,然后通过MovieLens的数据集进行实验对比。
推荐系统;协同过滤;线性回归;矩阵分解
四川省科技厅项目(No.2014JY0036)、四川省教育厅创新团队基金(No.13TD0014)
Recommender system designed to provide users with information that may be of interest is widely used in E-Commerce,video websites, news and novels recommendation,etc.Collaborative filtering is the main technology of recommender system,is divided into three classes: collaborative filtering based on memory,collaborative filtering based on the model and hybrid recommendation.Compares the algorithms of user(item)based,matrix factor based and linear regression in integration strategy as an example and gets the result through experimen-tal comparison with the dataset of MovieLens system.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
新班主任(2022年4期)2022-04-27
中等数学(2021年9期)2021-11-22
中学生数理化·高一版(2021年2期)2021-03-19
密码学报(2019年3期)2019-07-16
汽车观察(2019年2期)2019-03-15
卷宗(2018年14期)2018-06-29
读与写·教育教学版(2017年10期)2017-11-10
民生周刊(2017年19期)2017-10-25
南都周刊(2015年4期)2015-09-10
