
基于FCM的网络用户行为识别研究*
2016-09-09 09:21严岳松刘晓然
舰船电子工程 2016年8期
吴 鑫 严岳松 刘晓然
(海军指挥学院信息战研究系 南京 211800)
WU Xin YAN Yuesong LIU Xiaoran
(Information Institute, Naval Command College, Nanjing 211800)
基于FCM的网络用户行为识别研究*
吴鑫严岳松刘晓然
(海军指挥学院信息战研究系南京211800)
网络用户行为识别作为网络监管的一个重要方面,对网络安全具有重要的意义。针对网络用户行为识别问题,提出了一种基于模糊C均值算法的网络用户行为识别模型,并设计了相关实验进行验证。实验结果表明:该模型对网络用户行为具有较好的聚类和识别效果。
网络行为; 模糊C均值; 用户识别
WU XinYAN YuesongLIU Xiaoran
(Information Institute, Naval Command College, Nanjing211800)
Class NumberTP391
1 引言
随着互联网时代的不断发展和壮大,互联网用户的数量不断增多。与此同时,网络犯罪事件随着也不断增多,例如发布反动信息等。如何对网络用户进行有效的监管已经成为社会的热点问题。网络用户行为识别作为网络监管的重要的手段,对于用户行为的追踪、行为负责人的认定有着深远的意义。
网络用户行为识别,就是研究网络用户行为的特点以及在网络活动中所表现出来的规律,并对比行为样本库,对用户行为进行识别的过程。目前网络用户行为识别主要的方法有:刘磊等[1]提出的采用特征加权的朴素贝叶斯分类算法对用户进行行为识别的方法; 叶娜等[2]针对用户行为数据,提出了基于分块和二部图的用户识行为识别算法;徐晏等[3]通过用户上网在浏览器中留下的信息数据,对用户进行行为识别;梁璐在文献[4]中,根据用户行为复杂度关系构建用户行为的层次结构,利用层次隐马尔科夫模型对用户行为进行建模和识别;黄炜[5]提出一种利用分类算法与关联算法相结合的识别方法,通过数据挖掘技术对用户行为进行识别。结果表明上述方法均能对用户行为进行识别,但普遍存在两点不足:一是算法相对复杂,工作量较大;二是识别率相对偏低。针对以上不足,本文以网络用户行为日志集为研究对象,根据模糊C均值聚类算法(Fuzzy C-Means,FCM)设计简单、易于应用计算机实现等优点,提出一种网络用户行为识别模型。
2 网络用户行为识别模型
本文建立了一种基于聚类的网络用户行为识别模型,该模型由数据采集模块、行为样本库、数据选取模块及行为聚类识别模块四部分构成。模型如图1所示。
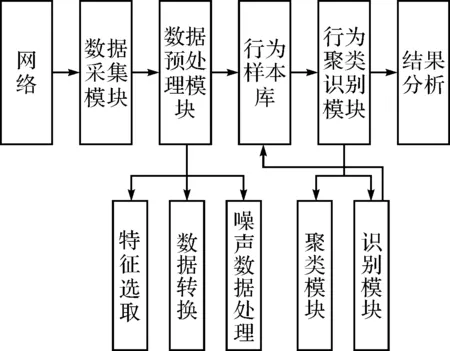
图1 基于聚类的网络用户行为识别模型
数据采集模块:是利用抓取用户上网流量信息的软件或者安装在服务器端口的传感器等手段,获取网络用户上网的行为日志数据。网络用户的行为一般用向量形式表示,即{特征1,特征2,…,特征n},其中n个特征组成了一次行为。
数据预处理模块:主要是对获取的网络用户行为日志进行预处理,使得经预处理的数据便于聚类识别。该模型中对数据的预处理主要包括三点:特征选择、数据转换、噪声数据处理。
行为样本库:是利用预处理后的数据来建立样本库,以便用作行为识别的模板,并通过不断丰富行为样本库,使得该样本库可以为后续在研究网络用户行为方面提供便利。
行为聚类识别模块:包括聚类模块和识别模块,前者是利用聚类算法对选取的训练数据集进行聚类;后者是利用聚类算法对选取的测试数据集进行聚类,并对比样本库,进行识别。
该模型是将聚类算法应用于网络用户行为识别,识别主要是依据测试数据集与行为样本库中的数据两者之间的相似度或者距离来衡量,若识别成功则可以认定测试的行为数据是某个人的网络行为,并通过查找人员信息表,得出此人的身份信息;若识别失败,证明该用户为新用户或者异常用户,应该予以重点关注。
3 基于FCM的网络用户行为聚类
FCM是一种基于目标函数的无监督聚类分析算法,它是在K-均值聚类算法基础上,将硬分类转换为模糊分类,并引入了一个隶属度的概念,FCM因设计简单、解决问题范围广、易于应用计算机实现等特点受到越来越多人的关注,并应用于各个领域。本文将FCM应用于网络用户行为聚类过程中,其聚类步骤[6]如下所示:
算法:FCM
输入:经预处理的网络用户行为数据
输出:聚类得到的网络用户数目
步骤如下:
Ⅰ begin initialize
(1)
Ⅲdo由式(2)重新计算聚类中心μi
(2)
dij=‖xj-μi‖2
(3)
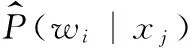
Ⅵreturnμ1,μ2,…,μc
Ⅶend
4 实验及结果分析
4.1数据来源
本实验数据均来自数据堂中的互联网用户行为日志数据集[7]。该数据集提供1000名网络用户日志集,采集了他们在四周中的网络行为日志。根据本文研究目的,选取了部分数据作为训练数据集和测试数据集,其中:
1)训练数据集:在行为样本库中随机选取三个人,记为p1、p2、p3,从这三个人的行为数据中分别抽取150条行为数据当做训练数据集;利用FCM对其进行三次聚类实验,分别为:每个人选取50、100、150条训练数据;最后得出三次实验的最终聚类结果,并统计三次实验中每个人的准确聚类数目、聚类准确率及平均聚类准确率。
2)测试数据集包括两组:第一组:p1的100条测试数据;第二组:分别来自p1、p2、p3的50条测试数据。分别进行聚类识别,分别统计各自的准确识别数目、准确识别率及平均识别率。
4.2数据预处理
对该数据集预处理的主要工作有以下几点:
1) 特征选取:从原始网络用户行为数据中选取的特征包括T、P、I、W、V,即用户的行为可以用向量{T,P,I,W,V}表示。

表1 选取的特征代表的意义
2) 数据转换:将用户的行为数据完全数字化处理,利用5维向量表示用户的行为,为方便数据存储和仿真实验,将窗口进程名全部用数字代替。

表2 窗口进程名转换表
3) 噪声数据处理:将原始数据中其他的特征数据进行保存,将一些有明显错误的数据删除。
4.3结果分析
4.3.1参数及结果统计量
1) FCM的参数设定
FCM重要参数:加权指数b。文献[8]给出的经验值是1.1≤b≤5,J.C.Bezdek在文献[9]中给出了加权值取2最为合理的物理解释;高新波等[10]也解释了b=2的合理性,并通过了实验证明。综上,确定该实验所采用的FCM的加权指数b=2。
2) 结果统计量
(1)准确聚类数目:即某个人的训练数据聚在同一类中最多的数目,定义为mi(i=1,2,3);
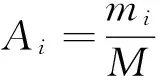
(4)准确行为识别个数:测试数据与对应的训练样数据聚类在同一类的数目,定义准确识别数目为ni(i=1,2,3);
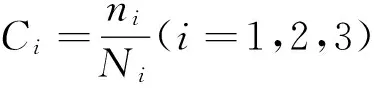
4.3.2实验结果及分析
1) 聚类结果分析,以训练数据集为对象,采用FCM进行聚类。结果如图2所示。
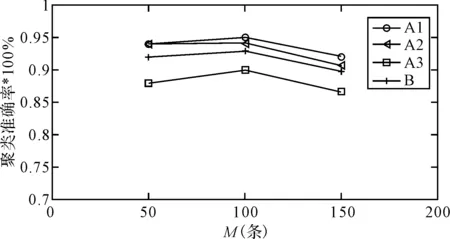
图2 训练数据集聚类结果
训练数据集聚类实验结果分析:由图2可以看出,当训练数据集为在p1、p2、p3中各抽取100条数据时候的聚类最为准确,平均准确率为93%;从总体上来看:第一,当训练数据集从每人50条数据增加到100条数据,聚类效果有所提高,当训练数据集从每人100增加到每人150条时,准确聚类率有所降低;第二,FCM对三组数据的聚类准确率基本都在90%左右。这也证明了该算法对于网络用户的行为数据具有良好的聚类效果。
2) 在聚类的基础上,采用FCM对两组测试数据集分别进行聚类识别,最终用户行为识别结果如图3、图4所示。
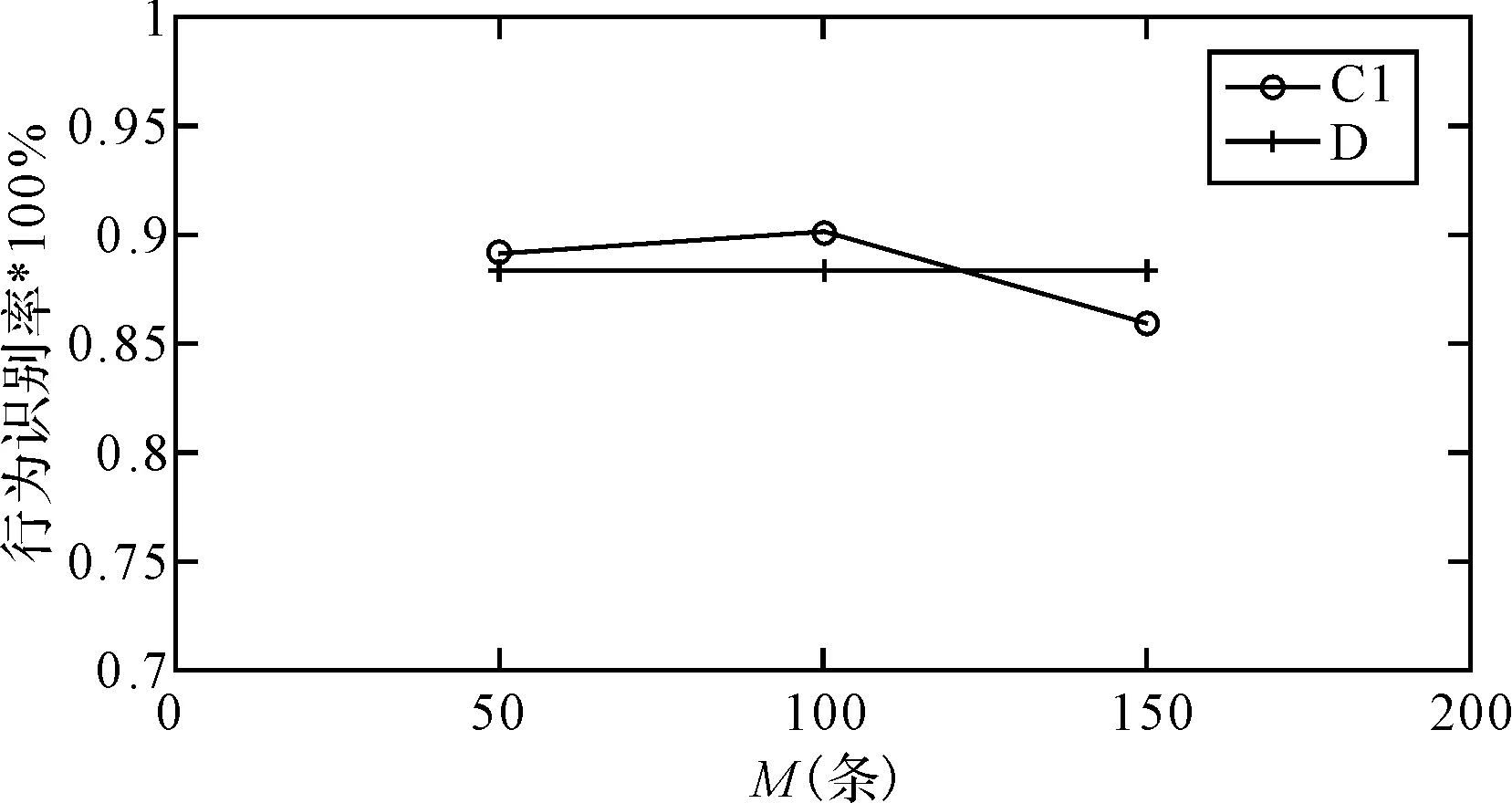
图3 N1=100,识别结果
测试数据集实验结果分析:由图3可知,当每人抽取100条训练数据集时,对于测试数据集的识别率最高,为90%,实验的平均行为识别率为88.3%,即对于p1而言,其行为的平均识别率为88.3%。
由图4可知,以每人取的50、100、150当训练数据集,对于第二组测试数据集的平均行为识别率分别为86.7%、87%、84.7%;相比于图3的结果,第二组测试数据集的平均行为识别率有所下降。首先,因为第一组测试数据来源于p1,第二组测试数据来自p1、p2、p3。用户行为数据变得更复杂,导致聚类和识别的难度加大,这是主要原因;其次,因为图4测试数据集数目相比图3的测试数据集增加了50%,因此数据量增加,对于聚类的结果造成了一定的影响。
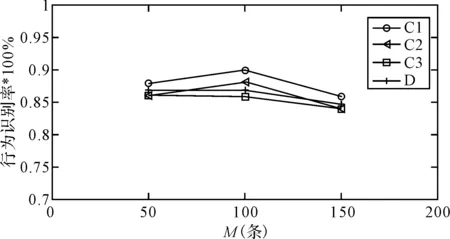
图4 N1=50;N2=50;N3=50识别结果
经过以上实验,将p1、p2、p3的行为数据对比行为样本库,通过查找人员身份信息表,得出产生此网络行为的用户身份信息,从而达到通过对用户行为的识别来识别用户身份的目的。
5 结语
本文以网络用户行为日志集为研究对象,建立了基于FCM的网络用户行为识别模型,通过两组实验分别验证了FCM对于网络用户的行为具有较好的聚类效果和识别效果,这使得公安部门在用户行为追踪、行为负责人认定等方面更加快捷,引导社会更加健康、稳定的发展。
[1] 刘磊,陈兴属,尹学渊,等.基于特征加权朴素贝叶斯分类算法的网络用户识别[J].计算机应用,2011,31(12):3268-3270.
[2] 叶娜,赵银亮,边根庆,等.模式无关的社交网络用户识别算法[J].西安交通大学学报,2013,12(47):19-26.
[3] 徐晏,张代远.基于浏览器用户身份识别系统[J].计算机技术与发展,2013,23(8):79-82.
[4] 梁璐.基于层次隐马尔科夫的行为识别研究[D].上海:华东师范大学,2012.
[5] 黄炜.基于数据挖掘的学习者身份识别[D].杭州:杭州电子科技大学,2011.
[6] 李粥程,邵美珍,黄洁.模式识别原理与应用[M].西安:西安电子科技大学出版社,2008.
[7] 数据堂(http://www.datatang.com)[EB/OL].互联网用户行为日志数据集.
[8] N.R.Pal and J.C.Bezdek.On cluster validity for the fuzzy c-means model[J]. IEEE Trans.Fuzzy Systems,1995,3(3):370-379.
[9] J.C.Bezdek. IEEE Trans.Syst .Man Cybern[J].1976(6):387-390.
[10] 高新波,裴继红,谢维信.模糊C均值聚类算法中加权指数的研究[J].电子学报,2000,17(4):21-24.
Identification of Network User Behavior Based on FCM*
Network user behavior recognition is an important aspect of network supervision, which has important significance to network security. Aiming to identify network user behavior problem,this paper proposes a network user identification model based on FCM,and designs the related experiments to verify the model.The results show that the model has good clustering and recognition effect on the behavior of the network user.
network behavior, fuzzy C-Means, user identification
2016年2月11日,
2016年3月27日
信息保障技术重点实验室开放基金项目(编号:KJ-13-103)资助。
吴鑫,男,硕士研究生,研究方向:信息安全理论与技术。严岳松,男,硕士,讲师,研究方向:信息安全。
TP391
10.3969/j.issn.1672-9730.2016.08.029
刘晓然,男,博士,教授,研究方向:信息作战。
猜你喜欢
中国听力语言康复科学杂志(2019年3期)2019-06-24
科学与财富(2018年30期)2018-12-28
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
中国高新技术企业(2017年5期)2017-05-05
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
计算机应用(2016年9期)2016-11-01
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
