
基于主题和特征的文本相似度算法研究
2016-09-03 08:41:30药珍妮
软件 2016年10期
药珍妮
(北京邮电大学 网络技术研究院,北京市 100088)
基于主题和特征的文本相似度算法研究
药珍妮
(北京邮电大学 网络技术研究院,北京市 100088)
本文提出了结合主题和各主题下关键特征的文本相似度算法,目的在于更准确的挖掘被描述对象的近邻对象集。本文首先介绍卡方统检验特征统计法,并利用改进的卡方检验,计算训练集中已知主题的文本的特征;而后介绍了最小编辑距离算法、余弦相似度算法和杰卡德相似系数,在论证了主题对文本相似度的重要性后,又针对难提取主题的文本加以改进,最终提出了基于主题和特征的文本相似度算法;然后对各个算法在测试集上的相似度计算结果进行分析,证明本文提出的算法在速度和精确度上明显优于其他算法;最后将该算法应用于股票的概念股题材标注上,分析结果并提出改进空间和不足之处。
数据挖掘;文本相似度;主题;特征
0 引言
文本相似度的计算已经深入到互联网发展的各个领域;如:在QA系统中,快而准的判断问题之间的相似度,决定了QA系统回答的响应速度和准确度;在各大门户网站中,文本相似度的挖掘,是用户个性化推荐系统和编辑系统的关键工作。
在文本分类的问题上,由于有本数量过多、描述篇幅过大或内容部分缺失等问题,导致想完全依赖标注好的训练集判断新样本的属性越来越难。针对这类问题,本文提出了从文本所描述主题和的各个主题下描述内容的特征入手,对于一个文和其相似度高的几个文本,他们之间不论主题还是对应的主要特征都存在相关性,这样,既不会导致同名但内容不符被判定为一类,也不会导致内容高度相符但被判定成不同类的情况。
在文本分类训练中,之前的实验里,运用了卡方分布和信息熵(Entropy)来计算每个特征词在相应概念下的权重,然后根据这个权重来判断个文本最可能描述的几个概念,然而计算结果并不让人满意,导致结果准确率低的主要原因有两个,其一是因为已标注好概念的股票不到5分之一,另一个是,实际上,对这些股票的原始概念标注并非来源于其对应公司的经营范围概述,而是更多更详细的对其各个从事领域的描述。
1 基于卡方检验的特征统计
1.1 卡方检验算法
假设,两个分类变量X(特征)和T(主题),它们的值域分别为{x1 x2}和{t1, t2},x1表示包含特征x,x2表示不包含特征x,t1表示属于特征T,t2表示不属于特征T,其样本频数列联表为:
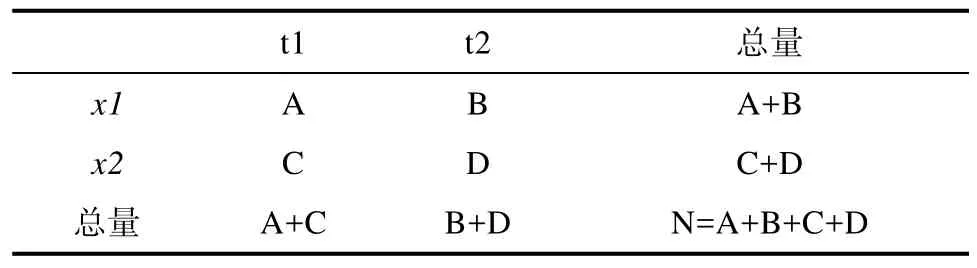
表1 卡方统计特征分布表
设:H1表示X与T相互独立,考虑到当特征与主体完全不相关时相关系数为0,这种情况时有AD-BC<=0,则卡方统计特征与主题的相关系数公式为:
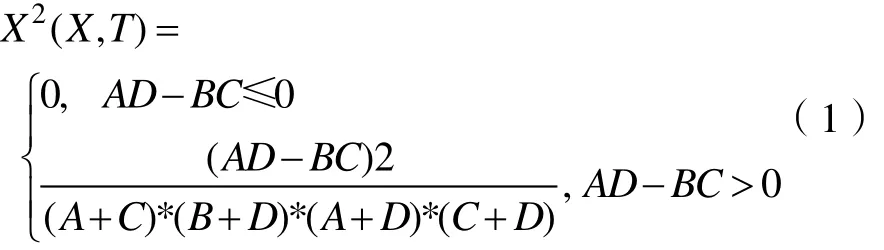
1.2 对基于卡方检验的特征统计的优化
1.2.1 特征的归一化处理
用传统的卡方检验得到的,不同主题下的特征权重是不同的,这样在会导致计算结果倾向于在样本空间中文本数量相对多的主题,为了解决这一问题,可以对数据进行归一化的处理,得:
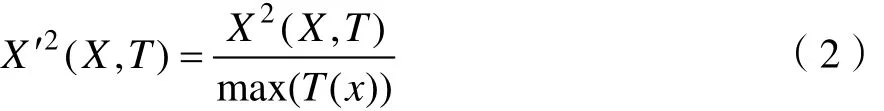
其中max(T( x))为主题T下,所有特征中权值的最大值。
1.2.2 对频繁项特征的惩罚
通过卡方检验可以得到,一个主题概念下有若干个特征,但一个特征若属于多个主题,那么该特征并不能代表作为这个主题下独一无二的特征。所以,本文利用TF_IDF的思想,再次对特征的在某主题下的权值作出现频度上的惩罚,最终得到较优化的特征。
2 文本相似度计算算法
2.1 最小编辑距离算法
最小编辑距离的概念由俄罗斯科学家Vladimir Leven Shtein在1965年提出。最小编辑距离(LevenShtein距离)指:由一个字符串转成另一个字符串所需的最少编辑操作次数;编辑操作次数包括:插入或删除一个字符和将一个字符替换成另一个字符,其算法描述为:输入两个任意长度的字符串,str1和str2,其中str1的长度为m,用字母i表示str1中长度为i的子串,str2的长度为n,用字母j表示str2中长度为j的子串,len(i)和len(j)分别表示字串i,j的长度;edit(i,j)表示由str1的子串i到str2的子串j的最小编辑距离。
在对文本相似度的计算中,该算法的局限性体现在,仅可以找出句子结构上最相似的两段描述,并非语义上的相似,其过分强调编辑距离上的改动最小,导致忽略了被文本描述的对象主题。举例如下:
1. 某环保有限公司:从事环保设备领域内的技术开发、技术服务、技术咨询、技术转让。
2. 某医疗集团:从事医疗发展领域内的技术开发、技术服务、技术咨询、技术转让。
因此,最小编译距离并不能有效地表示两个句子之间的语义的相似度。
2.2 余弦相似度和杰卡德系数
2.2.1 余弦相似度计算
余弦相似度是求两个向量之间夹角对应的余弦值,此余弦值可以用来表征这两个向量的相似性。夹角越小,余弦值越接近于1,它们的方向更加吻合,则越相似。
用这一概念来衡量样本向量之间的差异余弦相似度的公式为:

其中,x1、x2为维度相同的两个向量。在机器学习中,文本常由向量表示,训练集中所涉及的词量相对庞大,维度通常会维持在8000到15000,但对于短文本来说,且这个向量是高维且稀疏的。
2.2.2 杰卡德(Jaccard)相似系数计算
杰卡德相似系数是衡量两个集合相似度一种指标。在短文本中,其包含的词可以用一个集合来表示,计算两个文本的相似度时,用杰卡德相似系数表示要比用高维词向量计算余弦相似度快得多。杰卡德相似系数的公式为:
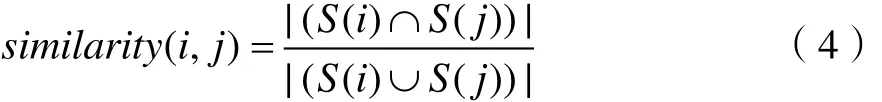
其中,S(i),S(j)分别表示第i和第j个句子中词的集合。
2.3 基于主题和特征的文本相似度计算
在杰卡德相似系数的基础上,加上主题对文本间整体相似度的影响权重,首先分析主题对文本相似度的影响,本文分三种情况去阐述,以两段文本为例:
1. 仅一方可以提取到有效的主题,或两方都提取不到有效主题。
2. 两方提取到的有效主题不一致。3. 两方提取到的主题一致。上述过程用公式表示为:
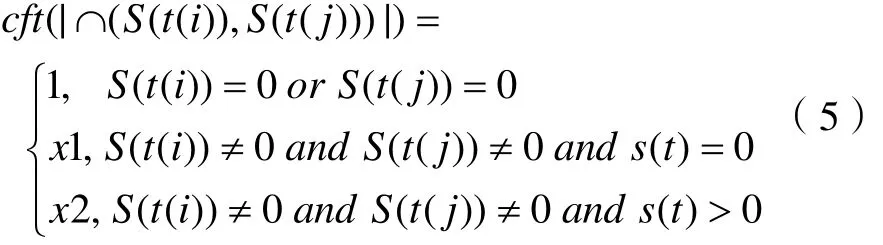
带入式(4),得:
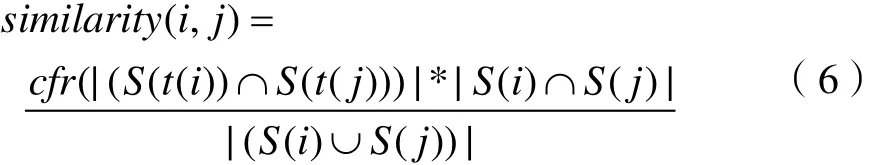
其中x1,x2为相关系数,在实际计算中,可以通过不断尝试,最终确定x1和x2的值,本文初始化时默认x1=0.5,x2=1.5。
在实际操作中,对主题的提取通常来源于标题(或被描述对象的名称),但并不是所有的文章标题、物品名称都可以容易地得到主题,在这种情况下,由3.3.1中提到相似相度的关系系数为1,起不到惩罚或鼓励的做用,基于上述问题,本文通过如下方法进行近一步的改进。
1. 利用改进的卡方检验提取待计算文本的特征。
2. 对相似度的计算公式,增加特征权重这一参数,特征权重用公式如下:

x(i)、x(j)分别表示第i个样本和第j个样本的特征,本文取改进的卡方检验中,计算结果中权重最大的前五个座位特征集,若不满5个则以较小的为基准,保持数量上的一致,x( i)-x( j)表示特征集合i与特征集合j的差集,(3.8)中的公式表示,差集的模越大,权值越小,若完全一致,则权值为1。
下面给出基于主题相关系数和特征权重的文本相似度计算公式:
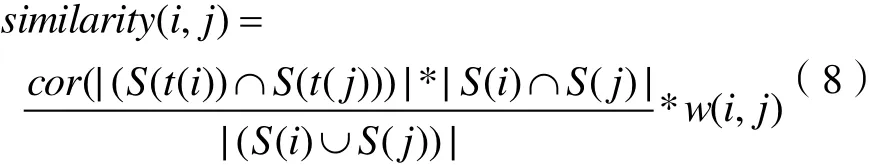
该算法的优势在于,即考虑到主题对文本内容的影响,又可以使文本内容不完全依赖于主题之间的相似,模型相对简单且易于理解。
3 实验结果及对比分析
本文将该算法应用于对股票题材概念的提取,通过上市公司提取股票的经营主题;再从上市公司的经营范围描述中。
3.1 最小编辑距离算法实验结果
如图3.1比对短句:从事环保设备领域内的技术开发、技术服务、技术咨询、技术转让。

图3.1 最小编辑距离下计算结果
3.2 杰卡德文本相似度计算实验结果
如图3.2分析:没有强调行业主题词的作用,误差主要产生于与主题相关性小的特征也都有机会参与计算,直接造成较长的文本占尽优势。
3.3 基于行业主题词的文本相似度计算实验结果
如图3.3分析:结果集的相似度很高,但局限住了很多符合某一行业特征,但文本比较短,且缺失行业主题的描述。

图3.2 基于文本内容的相似度计算结果

图3.3 基于行业主题的相似度计算结果
3.4 基于行业主题词的文本相似度计算实验结果
如图3.4分析:最终结果考虑到了文章内容、主题词权重和文本的特征权重,得到了优于上述三种方法的计算结果。
4 总结
在用改进的卡方分布提取特征词权重比较文本相似的实验中,误差的来源于,抛开主题的影响后,文本的相似性过分依赖于分词系统;在用最小编辑距离计算文本相似度中,误差来源于过分强调文本中字的排列,忽略了主题词本身的意义。
本文提出的方法很好的适用于段文本中,关键词比较集中的(大多数相同行业的描述比较相似)本文相似度分析中,然而在此之后的的工作中,在面对100G这样的大文本时,计算速度将成文一个必须解决的问题,所以还可以使用局部敏感哈希来对海量数据进行处理。
最后,本算法还存在的在于泛化能力不强,很难将潜在的概念全部挖掘出来。在实验中,取最相似的10个文本对其概念进行标注,若取其中概念交集的前三个,准确率仅有74.43%,但其中概念交集的第一个,准确高达有98.87%。

图3.4 加入行业权重主题词的实验结果
[1] 李凡, 鲁明羽, 陆玉昌. 关于文本特征抽取新方法的研究[J]. 清华大学学报(自然科学版), 2001, 41(7): 98-101.
[2] 刘涛. 用于文本分类和文本聚类的特征选择和特征抽取方法的研究[D]. 南开大学, 2004.
[3] 周水庚, 关佶红, 胡运发. 隐含语义索引及其在中文文本处理中的应用研究[J]. 小型微型计算机系统, 2001, 22(2): 239-243.
[4] 孙爽, 章勇. 一种基于语义相似度的文本聚类算法[J]. 南京航空航天大学学报, 2006, 38(6): 712-716.
[5] 刘群, 李素建. 基于知网的词汇语义相似度的计算[C]. 第三届汉语词汇语义学研讨会, 台北, 2002: 59-76.
[6] 陈龙, 范瑞霞, 高琪. 基于概念的文本表示模型[J]. 计算机工程与应用, 2008, 44(20): 162-164.
[7] 单丽莉, 刘秉权, 孙承杰. 文本分类中特征选择方法的比较与改进[J]. 哈尔滨工业大学学报, 2011(s1): 319-324.
[8] 柴加加, 张德贤, 耿瑞焕. 基于TF-CA-CI算法的互信息特征选择改进研究[J]. 计算机应用与软件, 2013, 30(3): 255-257.
[9] Fragoudis D, Meretakis D, Likothanassis S. Best terms: an efficient feature-selection algorithm for text categorization[J]. Knowledge & Information Systems, 2005, 8(1): 16-33.
[10] Zheng D F, Shi B. Inductive learning algorithms and representations.
[11] 郑世卓, 崔晓燕. 基于半监督LDA的文本分类应用研究[J].软件, 2014, 35(1): 46-48.
[12] 郑晓健. 面向领域主题的智能搜索引擎设计[J]. 软件, 2014, 35(3): 4-5.
[13] 赵旭剑, 邓思远, 李波, 等. 互联网新闻话题特征选择与构建[J]. 软件, 2015, 36(7): 17-20.
The Research of Texts’ Similarity Algorithm Based on Topic and Features
YAO Zhen-ni
(Dept. Network Technology Research Institute, Beijing University of Posts and Telecommunications, Beijing, 100088, China)
In this paper, we proposes a texts’ similarity algorithm based on the topic and features of each text, the purpose is to accurately mine the nearest neighbor texts of a given text. Firstly, we introduces the characteristics of CHI Square Statistics and gives improvement to features selection of training text which have known topic; and then compare the minimum edit distance algorithm (LevenShtein Distance), Cosine Similarity Algorithm and Jaccard Similarity Coefficient, analyze principal defect of each algorithm and propose a new text similarity algorithm based on features and topic; after that we use the new algorithm on real data set and prove no matter in speed or accuracy the new one is better than others; In the end, the new algorithm is applied to stocks’ subject tagging, from the analysis of results, we expound recent shortage and put forward the improvement.
Data mining; The similarity between texts; Topic; Feature
TP391.1
A
10.3969/j.issn.1003-6970.2016.10.028
本文著录格式:药珍妮. 基于主题和特征的文本相似度算法研究[J]. 软件,2016,37(10):123-126
猜你喜欢
临床肝胆病杂志(2022年6期)2022-11-25 05:08:24
汽车实用技术(2022年16期)2022-08-31 07:15:40
现代电生理学杂志(2021年3期)2021-12-05 19:22:54
中学数学杂志(高中版)(2016年6期)2017-03-01 18:53:58
爱你·心灵读本(2016年7期)2016-07-06 19:06:10
故事会(2016年6期)2016-03-23 21:59:01
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:40
职业技术(2015年8期)2016-01-05 12:16:46
中外文摘(2015年3期)2015-11-22 23:36:25
声学技术(2014年1期)2014-06-21 06:56:26
