
基于上市公司财务数据的企业信用风险预测Logistic模型研究
2016-09-01 07:57:21闫炳琪赵月瑶张辉
中国传媒大学学报(自然科学版) 2016年4期
闫炳琪,赵月瑶,张辉
(中国传媒大学 理学院,北京100024)
基于上市公司财务数据的企业信用风险预测Logistic模型研究
闫炳琪,赵月瑶,张辉
(中国传媒大学 理学院,北京100024)
随着国际金融市场的发展,多元化的金融工具和衍生工具在资本市场中得以运用和发展。上市公司作为自主经营、自负盈亏、自我发展的市场主体,面临着日益多变的市场环境,随时都要经受财务危机的考验。信用风险研究有助于对企业信用状况进行预测,动态了解企业发展的现状和未来的趋势,及时发现和解决企业财务管理中存在的问题,降低发生信用危机的概率,给投资者与信贷机构提供保障。本次研究选取我国深沪两市74家上市公司2013-2014年的财务报表数据,通过主成分分析降维,将17个财务指标浓缩为5个主成分因子,将5个主成分因子作为自变量建立回归模型。从上市公司的盈利能力、偿债能力、发展能力和营运能力四个角度,全面反映财务状况在企业信用中所起的作用。在选取变量、建立模型后,得到的整体预测水平较高,模型效果良好,可以将该模型运用于我国上市公司的信用风险预测,为投资者与信贷机构提供信用风险防范方面的帮助。
信用风险预警;财务风险;信用危机;主成分分析;logistic回归模型
1 引言
面对国际竞争的日益加大和经济环境的复杂多变,企业所要面临的风险也随之增大。企业管理制度的缺陷,市场经济体制的不健全等因素都在影响着企业发生财务风险的几率,因高负债,盲目扩张,资金周转问题引发的财务风险也层出不穷。因此在我国上市公司建立信用风险评级系统非常重要。
市场竞争越来越激烈,而我国又有一些上市公司经营效率不高,危机意识不够敏感,导致其中一些企业财务状况没有及时得到改善,负债不断,企业信用持续受损。为此,中国证监会先后出台了多项风险预警机制,来给广大投资者与信贷银行提供信用评测标准。
现代的市场经济,信用是基础中的基础,所以也可是说市场经济也是信用的经济。如今信用风险暴露愈发严重,信用风险已经成为各国金融系统所面临的核心风险。如何准确测度信用风险也成为金融机构、投资者、政府监管部门关注的焦点。
如今我国还处于经济转型时期,市场经济体制并不够完善,与市场经济相关的一些法律和市场规则也有漏洞。这就导致了我国信用体系发育程度低,信用秩序较为混乱。同时企业的信用风险防范意识也比较差,体现在经济行为中就是违约现象不断出现。例如贷款逾期不还,成为呆账死账;企业间资金相互拖欠、三角债盛行等等。我国整个信用体系的不健全以及大量企业存在严重的信用危机将会导致严重的后果:市场秩序遭到破坏,市场交易成本大大提高,市场效率显著降低,市场机制发挥基础性配置资源的作用也受到一定制约;严重阻碍了我国经济持续稳定健康的发展进程。由于信用风险提高,银行等金融机构不敢轻易放贷款,证券市场行情低迷,导致企业难以通过正常信用渠道获取所需资金;信用环境的恶化,将同时恶化我国吸引外资的投资环境,制约我国企业的国际竞争力。因此完善我国信用体系,构建合适的信用风险预警模型对于我国的经济发展,尤其是我国金融市场的稳定发展有着极为重大的现实意义。不论是银行等金融机构、投资者、债权人还是政府监管部门在做出投资或是放贷的决策时最为关心的都是企业的财务风险情况或是信用情况。
2 国内目前信用风险评级模型研究出现的问题
一些企业高层特别是企业的高级财务管理人员无视经济环境变化对企业财务状况和未来发展所造成的重大影响。根本没有建立财务预警系统,或者虽然建立了这一类的财务预警系统,却完全不具备环境变化的适应性,当客观环境发生变化时,企业依旧按照机械或传统的思路来分析判断问题,最终不能适应环境的变化,给企业造成重大损失,而这些企业所谓的财务预警系统也就名存实亡。[1]
企业预警系统必须以大量的信息为基础,而有些企业信息管理系统薄弱,没有专门的组织负责信息的收集和管理,甚至没有专门的人员负责这部分的工作,更没有做到不相容职务分离,信息存在不完整、不及时、甚至错误的问题。
加强信息管理工作,建立信息管理组织机构,配备专门的从业人员,明确信息收集、处理、存放及反馈等各个环节的工作要求,保证权责明确、不相容职务分离,同时提供相关的技术支持。建立完善的内部控制制度,包括法人治理结构完善、组织建设权责分明、交易处理程序适当、信息记录真实、披露及时等内容。[2]
企业是一个有机的整体,企业预警应与其他系统保持良好的合作关系。而有些企业各子系统之间没有建立起密切的联系,信息缺少统一、信息反馈不及时,经常发生几个系统之间,同一经济活动数据不同的现象。[3]同时,企业预警体系必须进行事前、事中、事后的经常性控制。有的企业往往只是在发生财务问题的时候才重视该系统,而系统因为长年不用,形同虚设,根本无法通过预警系统,分析造成危机的问题,无法确定到底是哪个环节发生了问题。
企业预警系统是财务信息为中心的信息系统,它以预警为目的,不同于企业其他系统。但应当考虑不同子系统的数据传递和各子系统对数据的不同要求,实现企业数据共享,建立以财务为中心的信息集中、反馈系统,才能更好的发挥预警系统的作用。[4]同时,企业的每一项重要的经营决策对财务风险都存在影响,要做到预先分析、事中控制、事后反馈。通过日常的实时监控,及时发现财务风险,及时快速做出反应,抓住重点,对症下药,从而达到预警、纠错、改善的目的。[5]
企业的预警区间包括财务指标的安全区间、一般风险区间,以此确定财务预警信号的重大性。有些企业在制定区间指标时,未考虑行业水平、企业规模等因素。所选用的指标也没有实时更新,所选用的区间具有很大的主观性。
一个公司财务状况的好坏往往是管理当局、投资者和债权人等利益相关者关注的焦点。以上四点都是现行我国财务预警方面的现状,公司财务预警是公司管理经营的一个重要方面。在学术研究方面,相比较国外,国内的相关文献较少,且以静态研究为主。静态研究成果涉及到六种财务预警模型:一元判定模型、多元判定模型、Logistic模型、人工神经网络模型、Probit模型和联合预测模型。其中应用较多的是前四种模型,而后面的模型应用相对较少。
3 模型的比较与选取
单变量预警分析方法计算比较简单,便于理解。但是由于企业的财务状况是通过很多财务指标来反映的,单个财务指标是无法把企业完整的、真实的财务风险体现出来。而且单变量比率分析得出的结论可能会受到企业外部经济环境的影响。它仅仅重视的是某个指标的分析能力,使模型过于片面,预测精度也会不稳定。
多元线性回归模型的预测精度虽然较高,但是对样本数据的假设条件过于苛刻,不是所有企业的财务数据都满足相关假设的,所以该模型并不能推广使用,只能对特定的一些企业使用。
对于人工神经网络模型,虽然很多实证研究发现,神经网络模型的拟合或预测准确性要高于多元判别分析和逻辑回归模型,该方法有很强的容错能力、学习能力和纠错能力,但是由于神经网络严重的内在缺陷,运用起来有一定困难,且依据的理论较为抽象,判别结果不具有解释性。因此认为人工神经网络不适合本文样本建模。
而Logistic回归分析是一种非线性的分析方法,它不像多元线性回归有那么多的假设条件作为前提,对数据的要求很低,泛用性很强,用spss又可以非常简便地得出各个参数的计算结果。
综上所述,Logistic模型由于适用性广,操作简便,且解释性也全面,所以我们选择使用Logistic回归方法来构建上市公司的信用风险预测模型。
4 研究思路与方法
目前我国企业的财务危机预警研究仍处于探索阶段,还有许多问题需要进行进一步的探讨。本文比较了当下国内外最流行的几个信用风险评级模型,分析各模型的优缺点,选了一个最适合我国上市公司财务数据特征的模型,运用最新的数据构建并获得最新的、适用的信用风险评级模型。
本文选取了2013-2014年沪深交易所的共74家上市公司作为研究对象,由于*ST类企业过少,这里我们不采取将样本配对的方法进行研究,而将其作为独立样本研究。通过分析最新的财务数据,找出影响企业信用风险预测效果显著的财务指标。然后,利用Logistic回归分析方法构建适合我国上市公司的信用风险评级模型。
5 上市公司信用风险预测模型的构建
5.1研究样本选取
本文是从沪深两市证券交易所挂牌的上市公司选取样本。数据来源为国泰安数据库。
本文通过随机抽样的方式选取了我国沪深两市74个规模相近的企业2014年的财务数据作为研究样本,截止日期为2014年的12月31日。其中*ST类企业有26个,而非*ST类企业有48个。
其中*ST企业指亏损满三年的股票,如果在规定时间之内不能扭转亏损的状态,就会有退市的风险。或是亏损虽不满三年但财务状况较为恶劣的企业。沪深两市的交易所在98年规定对财务状况异常或信用不良的上市公司股票进行特殊处理,即Special treatment,简称即*ST类股票.
*ST类企业由于财务问题严重,因此国内外研究者通常把*ST类公司也视为财务困境公司,随时存在退市的风险。因此,从理论上来说,由于*ST类公司的经营状况通常出现了较为严重的问题,资金链随时会出现断层的情况,出现债务问题时将无法如期偿债,综上所说,如果投资者对*ST类公司进行投资,将承担更大的信用风险,*ST类公司的信用程度大大的低于非*ST类公司。因此,本文将*ST类公司与非*ST类公司界定为分别是高信用与低信用的两类企业,作为因变量Y的值分别是*ST类公司为“0”,非*ST类公司为“1”。
选取样本见下表。

表 1 研究样本
5.2财务指标的选取与说明
为了全面的解释各个企业的信用情况,我们分别从四个方面寻找指标来建立评估模型,四个方面分别是偿债能力,经营能力,盈利能力,发展能力。
偿债能力就是指企业用其资产偿还长期与短期债务的能力。一个企业若无法支付足够的现金和偿还所负的债务,企业就难以健康地生存和发展下去。企业的偿债能力是反映企业财务状况的重要指标。静态上讲,偿债能力就是用企业资产清偿企业债务的能力;动态上讲,就是用企业资产和经营过程创造的收益偿还债务的能力。偿债能力越强,企业的财务状况就越乐观,信用状况也就越健康。其中反映企业短期偿债能力的指标有流动比率、速动比率、现金比率。[6]流动比率就是指企业流动资产与流动负债的比率,反应企业短期将流动资产转变为现金以用来清偿债务的能力计算公式为流动资产/流动负债;速动比率又称酸性试验比率,指速动资产与流动负债的比率。其中速动资产就是指流动资产除去其中变现能力弱和不稳定的存货、待摊费用、待处理流动资产损失等所剩的余额。速动比率对短期负债的解释能力比流动比率更加精确可靠,计算公式为:速动资产/流动负债;现金比率是指企业现金与流动负债的比率,反映企业的即时变现能力。计算公式为:现金/流动负债。反映企业长期负债能力的指标有资产负债率和产权比率两项。资产负债率指的是总负债与总资产之比,反映的是企业利用债权人的存贷资金进行经营活动的能力。计算公式为:总负债/总资产*100%;产权比率指企业总负债与所有者权益的比率,计算公式为:负债总额/所有者权益总额。这一比值越低,企业的长期偿债能力则越强,债权人权益的保障就越高,所要承担风险越小。

表 2 模型指标体系
经营能力又称资产管理能力,指的是企业在日常生产经营过程中,资产的周转速度所反应出的企业在资产运作方面的效率,它不仅反映着企业的对资产的管理能力和调配能力,而且也影响着企业的偿债能力和盈利能力。企业的资产调配越先进越合理,资产周转效率就越快,资产管理能力也就越高,盈利就越多,企业就有足够的资金去清偿所欠的债务,发生信用危机的风险则越低。我们选取了应收账款周转率、存货周转率、流动资产周转率、总资产周转率作为解释企业经营能力的指标。应收账款周转率反映的是应收账款周转的速度,它是一定时期内赊销收入净额与应收账款平均余额的比率,计算公式:销售收入/平均应收账款;存货周转率是指企业一定时期内一定数量的存货所占资金循环周转次数或循环一次所需要的天数。存货周转率反映的是存货资金与它周转所完成的销货成本之间的比率,计算公式:销货成本/存货平均余额。这是一组衡量企业销售能力强弱和存货是否过量的重要指标,是分析企业流动资产效率的又一依据;流动资产周转率指一定财务期间内一定数量的流动资产价值(即流动资金)周转次数或完成一次周转所需要的天数,这反映的是企业全部流动资产价值(即全部流动资金)的周转速度,计算公式:销售收入/平均流动资产;总资产周转率是指一定财务期间内,企业全部资产所占资金循环一次所需要的天数,它反映企业全部资产与它周转所完成的销售收入的比例关系。
盈利能力指的是企业获取利润的能力。盈利所得的资金是企业用来偿还所负债务以及为企业提供经营资本的重要来源,也是企业从投资者和债权人处获得更多资金的信用保证。盈利能力越强,企业偿还到期债务越有保证,发生信用危机的可能性也就越小。为了反映企业的盈利能力,我们选取了资产报酬率、净资产收益率、营业利润率、成本费用利润率四项指标。资产报酬率是企业在一定时期内的净利润和资产平均总额的比率,反映了企业总资产的利用效率,计算公式为:资产报酬率=净利润/资产平均总额×100%;净资产收益率,是企业一定时期净利润与平均净资产的比率,反映了企业所拥有资金投资过程中的收益能力。其计算公式为:净资产收益率=净利润/平均净资产×100%;营业利润率是指企业的营业利润与营业收入的比率,计算公式:营业利润率=营业利润/全部业务收入×100%,该比率反映了在考虑营业成本的情况下,企业通过营运操作获取利润多少的能力;成本费用利润率是企业一定时期内的总利润与成本总费用的比率。其计算公式为:总利润/成本总费用×100%,成本费用利润率越高,表明企业为取得利润而付出的成本越小,盈利能力就越强。
发展能力指标是对企业的各项财务指标与上年相比的纵向分析。通过发展能力指标的分析,我们能够推算出企业大致的变化趋势,从而可以大致预测出企业未来的发展情况,发展能力乐观的话,表明企业的发展前景比较好,存在着一定的潜力,人们往往更愿意相信一个未来前景更好的企业。我们选取了四个指标来解释企业的发展能力水平,分别是资本保值增值率、总资产增长率、营业利润增长率和可持续增长率。资本保值增值率是企业扣除客观因素后的本年末所有者权益总额与年初所有者权益总额的比率,反映企业当年资本在企业自身努力下实际增减变动的情况,其计算公式为:资本保值增值率=扣除客观因素后的本年末所有者权益总额/年初所有者权益总额×100%,一般认为,资本保值增值率越高,表明企业的资本保全状况越好,所有者权益增长越快,债权人的债务越有保障;总资产增长率指企业当年总资产增长额同年初资产总额的比率,反映企业本期资产规模的增长情况。其计算公式为:总资产增长率=当年总资产增长额/年初资产总额×100%;营业利润增长率就是企业当年营业利润增长额与上年营业利润总额的比率,该比率反映企业营业利润的增减变动情况。其计算公式为:营业利润增长率=当年营业利润增长额/上年营业利润总额×100%;可持续增长率是指不增发新股并保持目前经营效率和财务政策条件下公司销售可以实现的最高增长率。此处的经营效率指的是销售净利率和资产周转率。财务政策指的是股利支付率和资本结构。可持续增长率的计算公式:可持续增长率=销售净利率×总资产周转率×利润留存率×权益乘数。
5.3指标筛选处理
5.3.1正态性检验
为了对各个指标进行显著性的检验以筛选解释能力较强的指标纳入模型,我们首先需要检验各个指标变量的分布,因此这里将通过正态性检验来将指标分为两类讨论,分别是服从正态分布的一类和不服从正态分布的一类。
这里我们采用单样本K-S检验来进行正态性检验。通过进行单样本的K-S检验,设原假设H0:指标xi是服从正态分布,观察对应P值是否大于0.05,若大于则接受原假设,即对应指标服从正态分布,反之若小于0.05则拒绝原假设,对应指标不服从正态分布。
表3为单变量K-S检验结果汇总表格,由表可见其中x4(资产负债率)、x8(流动资产周转率)、x9(总资产周转率)、x15(总资产增长率)的K-S检验的双侧显著性大于0.05,则可知以上四个变量是服从正态分布的,而其余的13个指标则不符合正态分布。
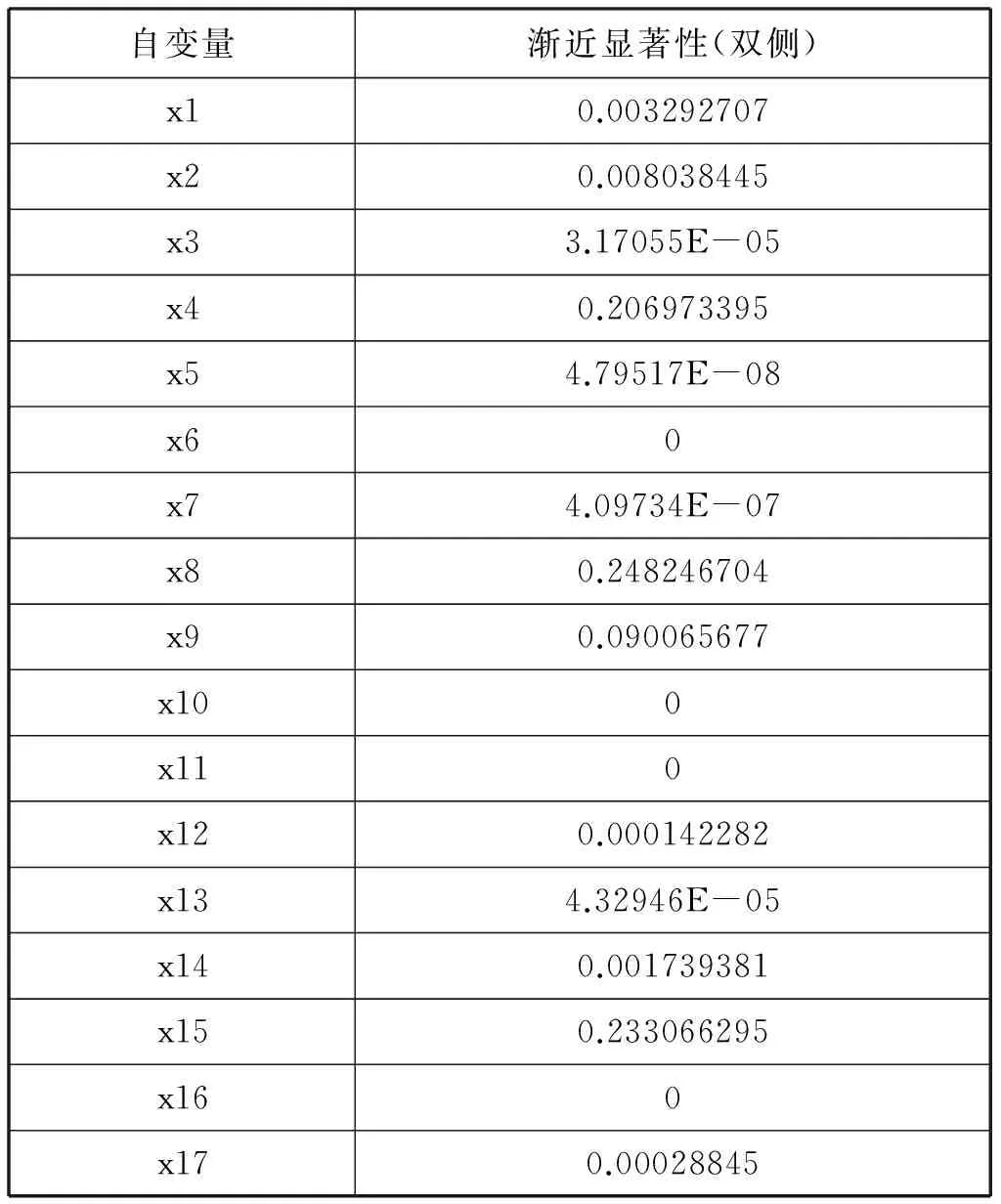
表 3 K-S正态性检验
5.3.2显著性检验
(1)独立样本t检验
独立样本的T检验过程用于检验两个来自正态分布的独立样本是否来自具有相同均值的总体,即检验各个指标在不同的因变量水平下的均值是否存在显著差异,若差异显著,则表明该指标对企业的*ST性与非*ST性的影响是明显的,反之,则对应的指标对企业的信用好坏影响不大,予以剔除。在这里我们规定显著水平95%,若检验的指标对应p值小于0.05,则表明对应的指标显著,反之,则说明指标的影响不够显著,应予以剔除。
表4中的F检验是检验的指标方差是否相等,若p值大于0.05,则接受第一个原假设方差相等,之后的t检验以第一行为基准,反之则接受第二个原假设,认为方差不相等,t检验以第二行为基准。
根据以上准则,我们可以看出四个指标中x4(资产负债率)、x9(总资产周转率)、x15(总资产增长率)的p值小于0.05,通过了t检验,表明它们的变化对企业是否成为*ST类企业有着显著的影响,而x8(流动资产周转率)的p值大于0.05,未通过t检验,说明该指标对企业信用程度的影响并不显著,所以将该变量剔除。

表4 独立样本t检验结果
(2)非参数检验
通过K-S检验的检验结果得知除了上一节所研究的四个指标外的十四个指标都不服从正态分布,由于这13个指标的分布未知,所以无法用参数检验来检验它们的显著性。非参数检验正是一类基于这种考虑,在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态等进行推断的方法。由于非参数检验方法在推断过程中不涉及有关总体分布的参数,因而得名为“非参数”检验。前面用到的K-S检验也是非参数检验的一种。
非参数检验中较为常用的有曼惠特尼U检验、Kruskal-Wallis检验、Wilcoxon检验等,本文采用的是独立样本而非配对样本,因此前两者更适合本文的数据,我们这里选择曼惠特尼U检验。
曼惠特尼U检验是用于两独立样本的非参数检验,是对两总体分布的比例判断。其原假设:两组独立样本来自的两总体分布无显著差异。曼-惠特尼U检验通过对两组样本平均秩的研究来实现判断。秩简单说就是变量值排序的名次,可以将数据按升序排列,每个变量值都会有一个在整个变量值序列中的位置或名次,这个位置或名次就是变量值的秩。
简单来说,我们可以通过将检验得出的p值与给定显著性水平进行比较,p若小于0.05,则拒绝原假设,表明所研究变量在不同因变量水平下的差异是显著的,是适合保留的指标,反之,则说明所研究变量对因变量的变化无显著影响,应予以剔除。

表5 曼惠特尼U检验结果
通过两独立样本曼惠特尼U检验,我们看到通过检验的指标有 x1(流动比率)、x2(速动比率)、x3(现金比率)、x5(产权比率)、x10(资产报酬率)、x11(净资产收益率)、x12(营业利润率)、x13(成本费用利润率)、x14(资本保值率)、x17(可持续增长率),而另外的x6(应收账款周转率)、x7(存货周转率)、x16(营业利润增长率)三项指标对应的曼惠特尼U检验p值大于0.05,未通过检验,说明该三项指标不够显著,因此将它们剔除。
5.4主成分分析
5.4.1KMO和巴特莱特球度检验
主成分分析也称为主分量分析,是利用对研究对象进行降维的思想,在保留原始变量尽可能多信息的前提下把多个指标华为几个综合指标的多元统计方法。通常把转化生成综合指标 称为主成分,每个主成分都是原始变量的线性组合,并且各个主成分没有相关性,因此主成分相比原始变量更能反映问题的实质,在研究复杂问题时便于我们抓住主要矛盾。
在进行主成分分析前,需要首先进行KMO和巴特莱特球度检验。KMO测定用来比较观测变量之间的简单相关系数和偏相关系数的相对大小,其值得变化范围从0到1,通常以0.5为界。KMO值大于0.5,则说明变量适合做因子分析,若小于0.5,则说明变量不适合做因子分析,当对样本或变量进行进一步处理。

表 6 KMO检验结果
上表为KMO和巴特莱特球度检验的结果,可看出KMO值约等于0.7,说明变量非常适合做因子分析,并且巴特莱特检验的卡方统计的显著性p值远小于0.05,说明变量间独立,综上两个结果,我们可以对数据进行下一步的因子分析与主成分分析。
5.4.2提取主成分
首先说明一下主城分析的原理以及步骤。第一步,是对所有选定自变量进行标准化处理。因为原始数据在数量级上可能相差很大,甚至是不同的量纲,统一为标准分值后就消除了这些影响。主成分分析要求各指标符合同趋势性的要求,在本文中由于财务指标的方向各不相同,所以首先要对指标进行同向性处理。第二步,通过标准化处理后的数据,求出相关系数矩阵。第三步,求出相关系数矩阵的 特征值和特征向量,最后从中选择主成分
通过以上步骤得到的结果如下表。

表7 提取主成分结果

续表
我们选取特征值大于0.9部分的为主成分,虽然通常默认采用特征值大于1的部分,但是由于采取这一方法得出的主成分贡献率不足百分之八十,代表性还不够强,所以为了更高的代表性,我们提取出了一共五个主成分。我们可以看到这五个主成分的累计贡献率达到81.992%。我们可以认为这五个主成分对原本17个指标所包含信息具有很大的代表性。
对主成分因子进行因子载荷,可以得到原始指标与主成分因子的相关系数。研究中发现,很多个变量和多数因子均有相关关系,使得初始因子 解释起来比较困难。为了解决这个问题,本文使用了正交旋转法中方差最大法进行转换。经过因子旋转后,得到的因子载荷矩阵如下表所示。

表8 因子载荷矩阵
通过因子载荷矩阵可知,主成分1中代表企业发展能力的资本保值增值率,总资产增长率和可持续增长率的财务指标起主导作用。说明主成分1主要是代表企业的未来发展趋势,其中具有代表性的指标是x14(资本保值增长率)。
主成分2中,三个代表企业短期偿债能力的指标即流动比率、速动比率和现金比率的因子载荷量较其他比率有显著差异。因此,主成分2主要解释的是企业的短期偿债能力指标,其中代表性指标为x2(速动比率)。
主成分3中,代表企业盈利能力的财务指标资产报酬率和成本费用利润率的因子载荷量都很大,说明主成分3主要代表企业盈利能力指标,把因子载荷量最大的x10(资产报酬率)作为该主成分的代表性指标。
主成分4代表着企业的资金利用合理性的能力,从资产周转率和营业利润率的因子载荷量较大可总结出,而其中占比更大的x9(资产周转率)将作为该主成分的代表性指标。
主成分5中带表着企业长期偿债能力的产权比率占主导地位,另外产权比率还反映着企业的资本结构。说明主成分1主要是站在企业管理的角度评价企业的长期偿债能力,该主成分的代表性指标就是x5(产权比率)。
5.5模型建立
根据之前介绍比对的多元逻辑回归分析理论与方法,且我们已经筛选与确定出了模型构建所需要的样本数据和解释性与代表性较强的自变量指标。我们对符合与不符合正态分布的两组指标分别进行的t检验与曼惠特尼U检验得出通过检验的13个指标是具有显著性差异的。这里采用Logistic回归建立信用风险预测模型。根据上章的指标筛选结果,我们重新定义自变量。

表9 最终确定指标方案
这里设信用不良的概率为P,将其看做新的自变量Zi的函数,当P大于0.5时,Y值为1,P小于0.5时,Y值为0。我们将之前经过筛选与整合的全新的五个指标Z1、Z2、Z3、Z4、Z5作为研究变量。用spss对这五个新的自变量进行Logistic回归,采用向前逐步回归法,经过五次迭代,剔除掉了对模型不显著的两个变量Z3,(资产报酬率)、Z5(产权比率)得到最终的模型统计量:

表10 模型统计量
根据以上结果我们可以得到根据2014年的财务数据建立的Logistic信用风险预测模型:

5.6模型结果分析
根据上表我们可以看到三个综合指标Z1(资本保值增长率)、Z2(速动比率)、Z4(资产周转率)都对企业的信用优劣的影响显著,并且与企业的信用状况正相关,这也非常符合实际情况,因为三者都分别与企业的发展能力、偿债能力、营运能力正相关,即三项指标的值越高,都能提高企业的信用水平。
在实证研究中,如果研究的样本数量不是太大,就可以考虑将所有的样本均用于模型的参数估计,再将样本的指标值回代得出所有样本的预测值,然后根据模型的准确率或误判率检验模型的预测效果。这里用spss对模型预测效果进行检验,检验结果如图:
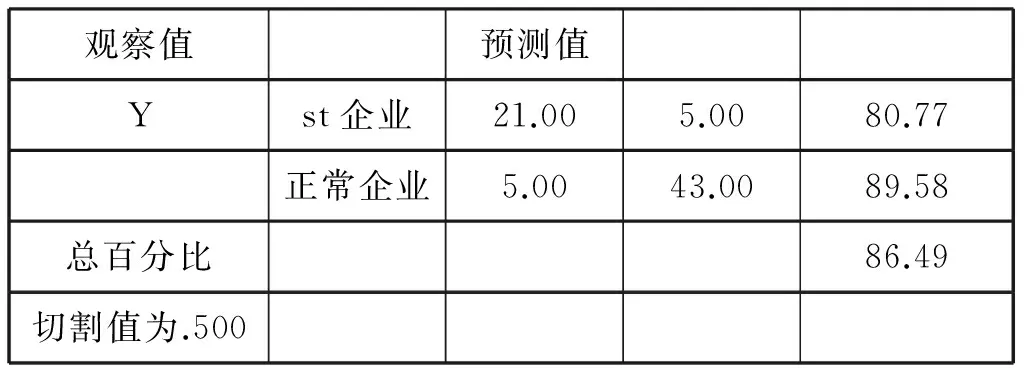
表11 模型预测效果检验
从表中,我们看到原本信用状况健康的企业在该模型中预测效果更好,48家正常企业中仅有5家被误判为*ST类企业,预测准确率高达接近90%,而对信用状况不佳的企业的预测准确率也有80%以上,而模型的整体的准确率高达86.49%,说明模型用原始数据的预测效果非常好。
用同样的方法以2013年的数据为样本建立模型得到的精度表:

表12 基于2013年数据建模预测准确度检验
从表中可以看到以2013年数据为样本建立的模型对信用状况不佳的企业的预测效果并不理想,仅有61.54%,但对信用正常的企业预测准确率同样高达近90%,整体的模型预测准确率79.17,较之使用最新数据2014年数据为样本建立的模型的精度要差上一些,尤其是对信用危机企业的预测效果太差。所以我们认为使用越新的数据建立的模型越适用。
5.7往年数据预测分析
接下来我们将2013年的财务数据利用2014年财务数据分析并建立的Logistic回归模型来进行模型的精度检验,得到的预测结果如表13。
可以看到用2014年数据所建立的Logistic回归模型对2013年财务数据进行预测检验后,得到的结果显示*ST类企业的预测准确率仅有42.31%,比2014年的预测准确率要低上很多,而信用健康的企业的预测准确率高达93.48%,相比于2014年的预测准确率却要稍稍高上一些。整体的准确率来说,利用2013年来进行信用风险评级的准确度仅有75%,准确率并不是很高,实际应用中很容易发生判断失误,导致不必要的损失。

表13 模型的精度检验
6 结论
以2014年容量为74的研究样本详细阐述了Logistic预测模型的建立和检验。主要思路:先通过显著性检验剔除显著性差的变量,保留对因变量影响显著的指标自变量。然后,为检验这些指标是否存在共同因素,是否适合进行主成因分析,首先进行KMO统计量检验和Bartlett检验。在确定可以进行因子分析后,将原始数据进行标准化处理,计算各主成分的特征值和方差贡献率、降序排列,提取代表性指标。然后将5个代表性指标作为综合性指标代入Logistic回归,通过Logistic向前逐步回归法保留对模型显著的变量,最终保留下Z1(资本保值增长率)、Z2(速动比率)、Z4(资产周转率)作为建模变量的预测模型,模型的准确率为86.49%。
通过以上的分析,我们可以发现Logistic具有较好的财务风险预测能力。通过主成因法降维,第一、可以避免因财务指标间信息的相关性和重复,将几个财务指标浓缩为一个主成分,用少量因子代替所有变量。第二、只要该财务比率能够在一定程度上区分ST和非ST企业,就可以作为建模时采用的原始财务比率,不受财务比率个数的限制。
本文使用前进逐步回归法得到的Logistic回归模型对上市公司信用风险进行了实证分析,得到以下结论:(1)本文建立的Logistic回归模型针对最新数据样本时取得了86.49%的预测准确率,使用往年数据样本预测时也得到了75%的预测准确度。在使用往年样本预测时,对正常企业错误预测率明显偏高,我们认为这一结果表明我国上市公司整体信用状况较差,一些公司虽然没有由于信用记录不良而被标记*ST,但是这些公司的财务状况实际已经开始恶化。(2)本文分别对2014与2013年的数据进行分析并建模,经过比较我们得出结论用最新的数据建立的Logistic模型的精度更高,更加可靠。(3)我们发现通过显著性检验与提取主成分后留下的5个财务指标中,有2个是偿债能力指标,1个盈利能力指标,1个成长能力指标和1个营运能力指标。可见在我国的证券市场上,对上市公司的信用水平影响比重比较大的还是企业的偿债能力,也可以说偿债能力直接反映着企业的信用风险水平,毕竟一个企业的信用好坏最简单来判断的话还是要看它还不还得起债。而成长能力,营运能力和盈利能力反映的是一个企业是否运转良好和未来的发展是否稳定,这几类指标被纳入模型就表明一个陷入信用危机的公司,不仅仅是短期内出现资金短缺或者暂时亏损的问题,公司陷入信用危机有它更深层的经营管理的问题,如果不能很好的解决这些问题,企业的财务状况将越走越劣,最终走向退市的结局。(3)本文共选取了74家上市公司作为研究样本,样本量还并不足够,且选取数据时间段为2013-2014年,跨度还不够大,导致模型的长期稳定性不能保证,这就需要我们根据每年财务数据的更新,搜集更多更新的数据,对模型进行修正优化,以达到更好的预测效果。
[1]Coats P,Fant L.Recognizing Financial Distress Patterns Using Neural Network Tool[M].Financial Management,1993,145-155.
[2]谢春岩.上市公司信用风险实证研究——基于Logistic模型的比较分析[D].吉林大学,2004.
[3]李小燕,钱建豪.我国企业信用风险评价指标的有效性研究[J].2005,(9).
[4]刘红霞,张红林.以主成分分析法构建企业财务危机预警模型[J].中央财经大学学报,2004,70-75.
[5]江红.试论企业财务风险的分析与防范[J].经济研究参考,2008,21-24.
[6]闫哲.基于Logistic模型的上市公司财务危机预测的实证研究[J].东北财经大学,2007.
(责任编辑:马玉凤)
Research on Enterprise Credit Risk Forecast Based on Financial Data of Listed Company
YAN Bing-qi,ZHAO Yue-yao,ZHANG Hui
(School of Science,Communication University of China,Beijing 100024)
Along with the development of the international financial market,diversification of financial instruments and derivatives to apply and develop in the capital market.The listed company as an independent market main body,self-financing,self-development,facing the increasingly volatile market environment,all the time to stand the test of the financial crisis.Credit risk research helps to forecast the enterprise credit conditions,dynamic understanding of enterprise development present situation and the trend of the future,timely discover and solve the problems existing in the enterprise financial management,reduce the probability of the credit crisis,to investors and credit institutions to provide security.This study selected deep Shanghai two cities 74 listed companies in China in 2013-2014 financial statements data,through the principal component analysis dimension reduction,condensed the 17 financial indicators for the five principal component factors,the four principal component factors as the independent variable regression model is established.From the listed company profit ability,debt paying ability,development ability and operation ability of four point of view,reveal the financial indicators signal role in enterprise development.In the selection of variables,to set up the model,the prediction level is higher,the model effect is good,the model can be applied in our country the credit risk of listed companies to predict,for investors and credit institutions to provide help for the credit risk prevention.
early warning of credit risk;financial risk;the credit crisis;principal component analysis;logistic regression model
2016-05-16
闫炳琪(1992-),男(汉族),山东莱芜人,中国传媒大学硕士.E-mail:cmzsqisi@163.com
O213.9
A
1673-4793(2016)04-0036-12
猜你喜欢
数学物理学报(2022年1期)2022-03-16 06:15:20
公民与法治(2020年20期)2020-11-27 01:44:42
中国外汇(2019年9期)2019-07-13 05:46:30
辽宁经济(2017年6期)2017-07-12 09:27:35
中国设备工程(2017年7期)2017-04-10 08:09:12
瞭望东方周刊(2016年45期)2016-12-07 16:03:39
当代经济(2016年26期)2016-06-15 20:27:18
中国惯性技术学报(2015年1期)2015-12-19 13:12:07
新疆财经大学学报(2015年3期)2015-12-10 03:49:13
特区实践与理论(2014年5期)2014-07-24 14:02:08
