
基于RGB-D传感器的人体姿态估计
2016-08-31 05:26石繁槐
中国科技信息 2016年1期
潘 霁 石繁槐
基于RGB-D传感器的人体姿态估计
潘霁石繁槐
本文提出了一种基于改进的树形图结构模型的人体姿态估计方法,利用RGB-D传感器,将采集到的深度信息加入到人体姿态估计中。通过使用彩色和深度图像特征对人体区域进行检测和预分割,在此基础上提出人体深度观测模型用来改进人体表观模型转换机制。最后根据优化的图结构模型估计人体姿态。由真实图像实验结果表明,本文方法可以在节约时间成本的同时提高人体姿态估计的准确率。
伴随人机交互和视频监控的发展,人体姿态估计逐渐成为计算机视觉领域的一项研究热点。在人体姿态估计领域,现有的研究方法大致可分为基于训练学习和基于部件模型的方法,基于训练学习的方法是以全局人体为导向进行建模或分割,其中,Sapp用一个具有代表性的样例集合来表示姿态空间,进行姿态估计时寻找与图像特征最为匹配的样例去表示姿态估计结果,由于人体姿态变化复杂,该方法在寻找匹配样例的部分算法耗时比较多。基于部件模型的方法则是将人体分为若干相互关联的部件,利用关联部件模型表示整个人体。Gaurav Sharma针对静态图像提EPM模型,Eunji Cho在FMM模型的基础上提出聚合多种姿态理论,两种模型针对静态图像有很好的准确度,但在对于视频场景中的应用却有局限。Ferrari提出了基于图结构模型的人体姿态估计方法,提高了人体姿态估计的准确率,但计算人体表观模型仍然用时较多。此外,还有学者从粒子的角度将姿态估计问题从二维空间聚合到三维空间,进而实现三维人体姿态重建。
本文在Ferrari的基础上做出改进,研究人体上半身姿态估计,提出了一种基于彩色和深度信息的人体姿态估计方法。首先根据彩色和深度图像的相关特征,对人体区域进行检测和预分割;其次,提出人体深度观测模型来改善人体的表观模型;最后,优化图结构模型并估计出人体姿态。真实图像实验结果表明本文所提方法可以实现鲁棒且可靠的人体姿态估计。
基于彩色和深度信息的人体上半身区域分割
为了减少后期人体搜索成本,首先对前景进行预分割。本文通过加入深度图像特征,使得在分割人体区域的同时得到不同部件间的空间结构约束。首先利用AdaBoost算法和HOG特征训练人脸和手部检测器,将检测到的人脸和手部区域用矩形框标记在对应的深度和彩色图像中,构成图像的ROI (Region of Interesting)。此时深度图像记为D , F则表示候选人脸和手部序列对。最后本文提出最优区域搜索算法,通过结合人体分布特征以及深度信息确定人体的最佳区域,并最终提取出人的上半身轮廓。最优区域搜索算法的具体步骤如算法1所示
算法1:最优区域搜索算法

属于同一主体的脸和手在图像的位置分布上具有一定的相关性,利用相关性特征可以排除一些非同一主体的ROI。本文提出相关性函数用来判定人脸和手的相关性,记为,表达式如下:

其中分别表示像素在深度图像中的位置和深度值。根据式(1)选出符合条件的人脸手部序列对,我们定义最优ROI能量函数Score来确定最佳的人脸和手部ROI,其中Score可由下式计算获得:

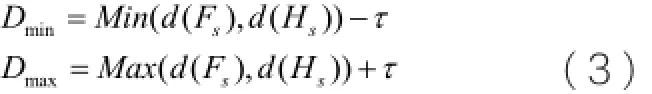
通过计算人体深度距离范围和最优的ROI区域可以分割出上半身人体区域。为了确保搜索的准确性,本文对人体区域做相应比例扩大并归一化到标准尺寸,记为W。最后,本文利用GrabCut分割算法对区域W作前景提取,进一步去除部分背景干扰。图1为一个人体上半身分割的过程示例。

图1 人体上半身区域分割过程示例
人体姿态估计
基于图结构模型的人体姿态估计
本文将人体上半身划分为6个部件:头,躯干,左上臂、右上臂、左下臂、右下臂。使用无向图来表示上半身结构,不同的节点即代表不同的身体部件。每个节点用矩形框表示,记为其中表示部件的位置,d表示部件的深度值,θ表示矩形方向。对于某一幅图像I,人体的姿态可以定义为。经过上一步的预处理,我们分割了人体区域,同时也获得头部和下臂的空间分布约束关系。本文将头与下臂的约束加入到图结构模型中,重新定义文献中的人体姿态后验概率项:
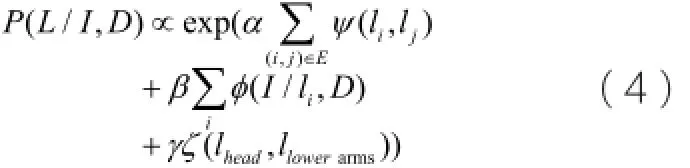
人体表观模型
与相同,人体表观模型是根据初始表观模型和表观模型转换机制估计得到。初始表观模型则是经先验分割计算获取,之后再由表观模型转换机制来修正初始表观模型,最后获得不同部件i的表观模型和背景模型,分别记为。根据贝叶斯公式 (5)计算出不同像素点属于部件i的概率,用来计算式(4)中的:
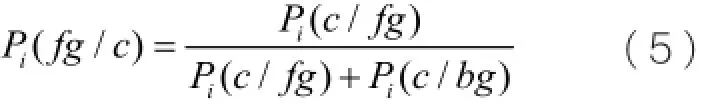
改进的人体表观模型转换机制
为了得到更加精确的人体表观模型,本文在文献的基础上加入人体深度观测模型。人体深度观测模型是根据检测到主体区域以及其所在的深度范围所确定的,用DM表示。使用深度直方图模型,将深度范围分为256份,定义每份深度为d。在计算观测模型之前,需要将主体区域的深度值根据深度范围进行归一化处理。改进后的人体各部件的表观模型可以表达为:

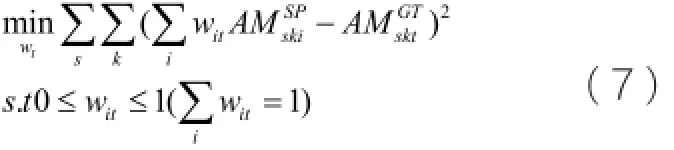
实验
实验数据
实验使用两个不同的数据集来评估本文的算法:DGait database和本文作者实验室数据集,下文记为A和B数据集,其中分别在DGait database取20组人物(1000张)图像对,实验室数据集取9组人物(450张)图像对(图像对是指对应的彩色和深度图),两个数据集都是通过kinect设备采集。本文采用PCP (Percentage of Correctly estimated body Parts)评估准则,分别测算不同部件被正确估计的百分比。根据PCP准则定义,如果部件估计所得位置与其真实标记区域重合度高于50%,即认为该部件被正确估计。本文硬件环境为Intel Core i5 CPU, 4GB内存。
实验结果与分析
本文根据不同的数据集和不同方法做了对比实验,如图2所示, (a)是应用Ferrari方法的结果示例,(b)是应用Wang方法的结果示例, (c)是应用本文方法的结果示例。通过观察发现,因为光线或者手臂活动等原因,前景很容易受到背景干扰,本文在增加了深度信息后,弥补了Ferrari 和Wang 方法的不足,得到了更加准确的人体姿态估计结果。表1列出了不同方法在六个部件上的定量PCP值和算法耗时,可以看出,本文的方法在六个部位上都取得了最高的PCP值,平均耗时也是最少的。说明通过加入深度信息,可以有效提高人体姿态估计的准确率,并且减少后期人体搜索的成本。此外,本文在生成人体表观模型时,直接使用深度观测模型生成最终的表观模型,得到如图3的实验结果,从实验结果可以看出,仅仅利用深度特征是不能提供足够的区别性的信息,证明了彩色图像特征在人体姿态估计中的重要性。

图2 不同数据集中部分样本的人体姿态估计结果

表1 人体姿态估计在不同数据集的PCP Value
结束语
基于RGB-D传感器,本文提出了一种基于改进的图结构模型的人体姿态估计方法,通过对人体上半身的预分割以及加入深度观测模型,得到更加鲁棒的人体姿态估计结果。实验结果表明,与Ferrari等人提出的算法相比,本文的方法可以得到较高的姿态估计准确率,并且减少了时间成本。因为本文的方法很大程度的依赖人脸和手部的正确检测,所以在未来的研究中,我们将优化算法,加入更多的人体信息特征。

潘 霁 石繁槐
同济大学电子与信息工程学院
潘霁(1993-)女,硕士研究生,主要研究领域为计算机视觉与模式识别;石繁槐(1974-)男,博士,副教授,主要研究领域为计算机视觉与模式识别。
10.3969/j.issn.1001-8972.2016.01.015
猜你喜欢
ELLE世界时装之苑(2022年2期)2022-02-14
河北果树(2021年4期)2021-12-02
装备制造技术(2020年4期)2020-12-25
汽车维修与保养(2020年11期)2020-06-09
福建基础教育研究(2019年10期)2019-05-28
制造技术与机床(2018年9期)2018-09-19
环球时报(2017-12-06)2017-12-06
中国新闻周刊(2016年33期)2016-10-27
视野(2014年23期)2014-11-24
中医研究(2014年11期)2014-03-11
