
基于遗忘函数和流行度的旅游产品个性化推荐研究
2016-08-16 07:58彭志强罗定提湖南工业大学管理科学与工程研究所湖南株洲412000
山东财政学院学报 2016年1期
鲁 芳,彭志强,罗定提(湖南工业大学管理科学与工程研究所,湖南 株洲 412000)
基于遗忘函数和流行度的旅游产品个性化推荐研究
鲁 芳,彭志强,罗定提
(湖南工业大学管理科学与工程研究所,湖南 株洲 412000)
非线性遗忘函数能够改进传统协同过滤推荐算法没有考虑游客兴趣稳定性的缺点,从而实现精准旅游个性化服务推荐。但是非线性遗忘函数并没有考虑到旅游产品的流行度,流行度越高的旅游产品,游客之间的兴趣相似度便越不准确,而流行度越低的产品,预测游客之间的兴趣相似度就更加准确。鉴于此,为了更进一步提高推荐精准度,在非线性遗忘函数的基础上构建考虑旅游产品流行度的数学模型,削弱流行度高的旅游产品的权值,调整游客间兴趣相似度。实验表明,引入产品流行度后,得到的平均绝对差值变小,推荐精准度也显著增加。
非线性遗忘函数;产品流行度;协同过滤;个性化推荐
0 引 言
随着互联网的发展,网络能够为旅游业提供非常广泛的各种各样的旅游服务和旅游产品。由于旅游业的信息化程度越来越高和人们在网上的选择与日俱增,所以大部分时间,游客漫游在信息的海洋中从而找不到自己所需要的旅游产品。游客数量的剧增和旅游信息的日益增多导致的旅游网站信息量过载,由于没有为游客量身定做旅游产品和旅游方案以及网页的千篇一律,从而使游客浏览旅游网站的时间机会成本大大增加,也一定程度降低了游客对网站的忠诚度。传统的协同过滤推荐方法能够为游客推荐部分自己想要的产品,但仅仅是根据其他游客的评分和自己本身历史评分数据来预测当前游客的偏好[1],该方法并没有考虑到游客偏好动态转移的特性。消费者心理学研究表明,消费者的偏好并非事先确定的、一成不变的[2],而是受到外部环境如自己本身的购物历史、人口统计和产品本身的流行性程度以及对产品的了解程度等所决定的。那么也就是说游客的兴趣是变化的,只是变化的程度不一样。因此,许多学者提出基于非线性遗忘函数来改善传统的协同过滤算法,虽然推荐效果有所提升,但是产品有冷热门之分,而产品的流行程度对推荐有明显且重要的影响。热门产品所包含的信息没有冷门产品包含的信息多,流行度对推荐的效果影响非常大,例如,假设摩天轮在网上的评分是最高的,游客打开网站第一眼能看到的就是它,游客选择它并不是仅仅是因为喜欢,还包含随大流的思想。因此,推荐效果显然不是很精确。所以在遗忘函数基础上同时提出产品流行度,通过对热门产品降权的方式,融合两种方法,以此来提高对游客推荐的旅游产品的精准度,从而解决旅游信息量过载问题,提高游客对网站的忠诚度,实现旅游资源配置的最优化。
1 相关研究综述
由于网络的发展,互联网+被越来越重视,人们在网上购物已是大势所趋,也越来越多的人会在网上订制旅游门票和旅游产品,许多学者开始在大数据的背景下,通过数据挖掘来掌握游客的偏好。协同过滤算法是旅游电子商务进行个性化推荐最常用、最有效的方法。其中协同过滤算法是根据邻居用户对产品的评分和游客本身对产品的历史评分建立游客兴趣度矩阵,预测游客对该产品未来的兴趣偏好程度,此方法能克服基于内容过滤算法的缺点,也应用最为广泛。但是存在严重的数据稀疏性问题和冷启动问题[3]。此外,该方法预测的只是游客的历史兴趣,不能对游客当前的兴趣进行预测。为了改善协同过滤的推荐效果,Schiaffino等[4]在协同过滤中应用了人口统计学,在这种情况下推荐系统会根据对用户的人口统计和用户本身的行为特性把用户分为不同的类别,以此来改善协同过滤上的不足。Bedi等[5]为在线旅游提出基于声誉协同过滤的多智能推荐系统,用来改善协同过滤的冷启动问题。Burke[6]和 Abbas等[7]采用了将协同过滤和基于内容过滤算法结合的方式,有效地减少了冷启动问题,通过两种方法的结合能够给用户提供一个全新的内容或者自己从未使用过的服务,充分挖掘它们的优点有效减少它们的不足。与此同时许多研究学者对旅游需求方面也进行了研究,周霓[8]运用灰色预测动态模型对山东入境旅游游客量进行预测,为山东入境旅游客源市场的规划发展提供了相关的建议。张广海等[9]针对淄博旅游业的发展现状和现存的问题,运用单位根检验、协整分析、VAR模型对城镇化和旅游发展之间的关联机制进行动态计量分析,最后结合协同学理论研究了两者之间的协调性和有序性,为文章研究旅游个性化推荐做好一定程度上的背景和铺垫,最后邓鹏等[10]提出了一种基于用户情境的POI个性化推荐模型,实现实时位置的个性化推荐,推荐结果具有较好的精度,也为个性化推荐做出了更进一步的推进。后期学者考虑到游客偏好随时间的变化发生动态转移,并对此做出了研究。于洪等[11]提出基于遗忘曲线协同过滤算法,借鉴心理学上艾宾浩斯遗忘曲线来跟踪和学习用户的兴趣,来改善传统的协同过滤不能及时反映用户的兴趣变化的不足。郑先荣等[12]提出非线性逐步遗忘协同过滤算法,改善传统协同过滤算法没有考虑用户兴趣变化,导致其推荐质量较差的问题。田宝军等[13]在协同过滤个性化推荐系统中把时间因素的影响考虑进去,改变不同时刻评分的权重,解决了对用户兴趣更新不及时所导致的推荐结果不够全面、准确的问题。曾东红等[14]提出一种基于指数函数的协同过滤算法,通过对评分矩阵的修正,得到一种改进的协同过滤算法,并且推荐的精准度显著提高。朱国玮等[15]提出基于遗忘函数和领域最近邻的混合推荐,通过非线性遗忘函数建立用户兴趣模型,引入领域最近邻处理方法,改善协同过滤面临严峻的数据稀疏性和冷启动问题和基于内容过滤存在新用户问题。
然而上述研究在引入遗忘函数时都是假设产品的流行性程度是平等的,即产品与产品之间的流行与否并没有区别,现实生活中流行度越高的产品在网站的排名就越靠前,从而导致用户获取不同流行度产品的难易程度不同,进而用户对不同流行度产品的选择所包含的用户兴趣程度也不同,从而造成两个用户同时选择一个流行度高的产品兴趣相似度就不一定很高,预测不准确。有许多学者为解决这一问题,在协同过滤的基础上引入产品流行度,削弱热门产品的权值达到提高推荐效果。赵向宇[16]在传统的协同过滤算法上考虑了产品的流行度问题,并做出相应的实验,通过对热门产品进行降权,推荐精度显著提高。Song等[17]针对推荐系统很容易给用户推荐出流行性高的小说,而不能够满足一些用户偏好流行度低的产品进行推荐的问题,提出了个人声望倾向匹配方法,改善小说的流行度和兴趣偏好之间的不平衡问题,并且处罚流行度高的小说,提高了推荐的效果。Lai[18]通过分离高用户追踪和低用户追踪的项目,来预测二进制用户的兴趣偏好,将基于邻居用户模型、潜在因素模型和基于内容的模型进行线性组合,结合项目的流行性程度,最后有针对地推荐。
由以上文献可以看出,个性化推荐获得大批国内外学者的广泛关注,虽然从不同角度完善个性化推荐模型的应用,并有一定的研究成果,但是很少文献能有效地结合非线性遗忘函数和产品流行度给予推荐。单一的对游客兴趣变化分析只是假设了所推荐的产品都是平等的,没有流行与否,这会造成网站在设计个性化推荐时假设游客面对产品的兴趣偏好是平等的,造成预测不准确。而单一的对产品流行度分析试图提高推荐效果都是假设游客兴趣是不变的,得到的只是游客的历史兴趣,也会造成预测不准确。鉴于此,本文在遗忘函数的基础上,在考虑到游客兴趣随时间变化的同时,对热门旅游产品进行惩罚,降低热门旅游产品的权值,然后确定游客之间的兴趣相似度,最后结合传统的推荐算法,以此更进一步提高旅游产品个性化推荐精准度,提高游客对旅游网站的忠诚度,一定程度缓解旅游网站信息量过载问题。
2 相关模型算法
2.1 非线性遗忘函数推荐模型
游客的兴趣偏好预测与游客对旅游产品点击频率和每次评分之间的相隔时间密切相关,也称之为游客隐性偏好,假设游客当前实际评分时间为 tN,游客评分参照时间为 tL,游客对旅游产品的相对评分时间为 t,相对评分时间,也即实际评分时间与所设参照时间的时间间隔。因此,当前游客浏览时间距上次最大时间间隔 tmax=max(TN-tL),最小间隔时间 tmin=min(tN-tL)。根据德国心理学家艾宾浩斯(Ebbinghaus)对人类遗忘现象做出的系统研究,人对于事物的遗忘过程是非线性的[19]。其中h(t)函数表达方式为:
其中:m是遗忘系数,即表示游客对旅游产品的遗忘速度。其值越大,游客对产品遗忘越快,其兴趣变化程度越大,反之亦然。当m=0时,游客未进行非线性遗忘,即表示历史偏好与当前偏好一致;当0<m<1时,游客进行部分非线性遗忘;当 m=1时,游客进行完全非线性遗忘,游客偏好随时间开始呈现非线性变化。m值受系统中游客偏好变化程度的影响,游客偏好变化大,值就会大一些,反之则小一些。为了解决游客兴趣随时间变化的问题,文献[12]在传统的协同过滤基础上引入非线性遗忘函数,对其改进如下:
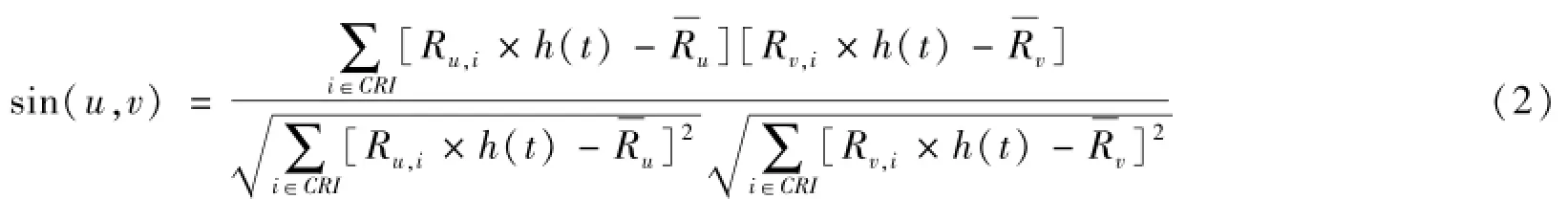
其中:u是当前游客;v是其他游客;sin(u,v)是当前游客和游客的兴趣相似度;CRI是当前游客和其他游客共同评分的产品集合;Ru,i是游客 u对旅游产品的评分;Rv,i是游客 v对项目 i的评分;表示游客 u对所有旅游产品评分的均值;表示游客v对所有旅游产品的评分的均值,该方法是利用Ru,i×h(t)代替Ru,i来确定游客的相似性,h(t)起到调节游客偏好变化程度,缓解游客兴趣随时间变化的程度,增加游客目前评分的重要性同时也降低了游客历史评分的重要性,最后结合协同过滤算法,找出最近邻居,从而产生推荐。
2.2 产品流行度推荐模型
马太效应描述的是流行的物质越来越流行,不流行的物质越不被人知的现象。该现象在生活中比较常见,并且适用推荐系统,以产品为例,越流行的产品就越容易被推荐给用户,相反不流行的产品就相对很难被推荐,甚至需要用户主动检索,由此便会影响用户对产品的选择,最终会影响用户对不同流行程度产品的兴趣。为了降低产品流行度给推荐系统带来的影响,文献[16]在协同过滤的基础上通过引入一般产品流行度函数来削弱热门产品的权值,提高游客之间的兴趣相似度,从而达到推荐效果的提升。其改进如下:

其中:W是对热门产品的惩罚函数。
结合协同过滤算法确定最近邻居,根据最近邻居计算出用户对未知项目的评分大小,从而依据评分的大小予以推荐。
3 非线性遗忘函数与流行度结合算法
上述函数表示对所有产品进行一定程度的惩罚,降低其所占的权值,其表达式为:

其中,W是对热门产品的惩罚值,pi是旅游产品i的流行度,大部分文献对流行度的计算考虑到产品的评分次数,越流行的产品评分次数就越多,故文章用评分次数来反映产品的流行与否。因此公式中的pi也代表产品i被用户评分的次数。即对所有的产品进行降权处理,评分越高的项目,也即越流行的项目,其W值越小,反之亦然。因此,本文改进以上两种推荐算法,改进的兴趣相似度算法如下:

以此来改善上述单一模型的不足,同时考虑游客兴趣随时间的变化和产品流行度在预测中起到的作用,共同调节,重新确定用户的相似度,找到用户的最近邻居,然后结合协同过滤推荐,计算出当前游客对旅游产品未来的评分值,按照评分以高向低排列,为游客推荐旅游产品。

Nu表示用户 u的邻居用户,表示用户u对所有项目的平均评分,表示用户v对所有项目的平均评分,最终形成推荐。
4 实验仿真及分析
4.1 数据集
旅游产品是需要游客亲身体验其中具体的内容方知喜好程度,而电影同样需要用户亲身体验才能反映出用户的喜好程度,同时旅游产品评分和 MoviesLens中包含的电影评分都是五分制,并且用户选择都是根据内容来选择,电影和旅游产品的流行程度都能影响用户对其选择,所以文章引用MoviesLens中电影数据来做实验仿真能够反应模型的准确性。MoviesLens数据集是经常被许多研究学者采集用来研究推荐系统的,其中涉及1 682个电影和943个用户,包含100 000条评论。本文从中提取2 666条记录,包含50个用户和150个电影,并且每部电影至少有11个评论次数。本文将采取80%的数据作为训练集,20%的数据作为测试集。
4.2 评价标准
目前,推荐算法中最常用的评价标准就是采用平均绝对差法,见(7)式,该方法通过利用定量方法计算游客兴趣偏好与游客真实偏好之间的偏差关系,以确定该推荐算法预测出来的游客兴趣的精确性。并且与推荐精度成负相关关系,也即所得值越小,其预测精确度越高。

其中,Ri表示算法(7)式预测出来对项目 i的评分,ri表示游客对项目 i的真实评分。
4.3 实验结果
m值从0到1变化的三种方法推荐精准度,随机选取k=15个邻居游客,三种方法参数设定下的推荐结果如图1所示。
m是游客兴趣遗忘系数,其值越小表示游客兴趣变化越慢,反之亦然。其中 m过大过小都不适合,过大或过小不仅不会提高推荐效果反而会影响推荐效果。从图 1可知,当设定参数m=0.6时,其推荐效果最好。然后在目标游客中寻找25个邻居用户,分别比较传统协同过滤、非线性遗忘、产品流行度的 MAE值,实验结果如图2所示。
图2可以看出,传统协同过滤值MAE最大,引入产品流行度后 MAE值最小,而非线性遗忘函数的MAE值居于其中,并且总体的MAE值都与邻居数量呈现负相关的关系,也即随着邻居游客数量的增加,三种推荐手段的推荐精度是有所提高的,其中基于产品流行度的推荐方法的 MAE值最小,推荐精度最高。并且推荐效果随着邻居数量的增多,值就越小,看来邻居的数量对推荐效果有着重要的影响,由图2可以看出,非线性遗忘函数对协同过滤的改进在邻居数量k=15的时候,达到最优效果,其提高了26%,基于遗忘函数的流行度函数相对于协同过滤算法,提高了47.8%的推荐效果,相对于非线性遗忘函数提高了29%。其他邻居数量下的推荐提高在10%左右。

图 1 改进算法与传统算法推荐精度随值变化关系

图2 改进算法与传统算法值
5 结 论
旅游产品越来越信息化和人们更愿意在网上购买产品的趋势下,非线性遗忘函数结合协同过滤算法已经不能满足当下旅游网站对游客实现精准推荐的需求,并且一般的非线性遗忘函数也并没有考虑到产品的流行性程度,为了更进一步提高推荐的精准度,融合了旅游产品流行度,以期从不同角度考虑旅游个性化推荐,实现更加精准的推荐。实验表明,在引入流行度后,其值显著下降,推荐精度明显比较传统的协同过滤算法和基于非线性遗忘函数的协同过滤算法要高得多,从而解决游客在大数据面前找到自己所需要产品耗时的难题,进而提高游客对网站的忠诚度,更进一步优化旅游业资源配置。
本文虽然为提高推荐的精准度,提出了产品的流行度,但是旅游个性化推荐模型还有更进一步的发展空间。并不是所有的产品都需要降权处理,所以对产品的划分确定产品的置信区间,是下一步急需解决的问题。
[1]BREESE J S,HECKERMAN D,KADIE C.Empirical Analysis of Predictive Algorithms for Collaborative Filtering[C].Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence.Morgan Kaufmann Publishers Inc.,1998:43-52.
[2]KWON K,CHO J,PARK Y.Influences of Customer Preference Development on the Effectiveness of Recommendation Strategies [J].Electronic Commerce Research and Applications,2009,8(5):263-275.
[3]HUANG Y,BIAN L.A Bayesian Network and Analytic Hierarchy Process Based Personalized Recommendations for Tourist Attractions over the Internet[J].Expert Systems with Applications,2009,36(1):933-943.
[4]SCHIAFFINO S,AMANDI A.Building an Expert Travel Agent as a Software Agent[J].Expert Systems with Applications,2009,36(2):1291-1299.
[5]BEDI P,VASHISTH P.Empowering Recommender Systems Using Trust and Argumentation[J].Information Sciences,2014,279:569-586.
[6]BURKE R.Hybrid Recommender Systems:Survey and Experiments[J].User Modeling and User-Adapted Interaction,2002,12 (4):331-370.
[7]ABBAS A,ZHANG L,KHAN S U.A Survey on Context-Aware Recommender Systems Based on Computational Intelligence Techniques[J].Computing,2015,97:667-690.
[8]周霓.山东省入境旅游客源市场预测研究——基于灰色GM(1,1)模型[J].山东财政学院学报,2013,25(2):46-51.
[9]张广海,李晶晶.资源型城市城镇化和旅游发展水平的关联机制分析——以淄博市为例[J].山东财经大学学报,2015,27 (4):36-45.
[10]邓鹏,李霖,陈功,等.基于用户情境的 POI个性化推荐模型[J].测绘地理信息,2015,40(3):52-56.
[11]于洪,李转运.基于遗忘曲线的协同过滤推荐算法[J].南京大学学报(自然科学版),2010,46(5):520-527.
[12]郑先荣,汤泽滢,曹先彬.适应用户兴趣变化的非线性逐步遗忘协同过滤算法[J].计算机辅助工程,2007,16(2):69-73.
[13]田保军,张超,苏依拉,等.基于 Hadoop的改进协同过滤算法研究[J].内蒙古农业大学学报:自然科学版,2015,36 (1):132-138.
[14]曾东红,汪涛,严水发,等.一种基于指数遗忘函数的协同过滤算法[J].科技广场,2013(7):10-15.
[15]朱国玮,周利.基于遗忘函数和领域最近邻的混合推荐研究[J].管理科学学报,2012,15(5):55-64.
[16]赵向宇.Top-N协同过滤推荐技术研究[D].北京:北京理工大学,2014.
[17]SONG.M,PARK S,YU H,et al.Novel RecommEndation Based on Personal Popularity Tendency[C].Data Mining(ICDM),2011 IEEE 11th International Conference on.IEEE,2011:507-516.
[18]LAI S,LIU Y,GU H,et al.Hybrid Recommendation Models for Binary User Preference Prediction Problem[J].Journal of Machine Learning Research-Proceedings Track,2012,18:137-151.
[19]GENQING Y.Medical Psychology[M].Nanjing:Southeast University Press,1995:47-53.
(责任编辑 王玉燕)
Tourism Product Personalized Recommendation Based on Forgetting Function and Popularity
LU Fang,PENG Zhiqiang,LUO Dingti
(Institute of Management Science and Engineering,Hunan University of Technology,Zhuzhou 412000,China)
Although nonlinear forgetting functions can be used to overcome the shortcoming of traditional collaborative filtering recommendation algorithms ignoring tourists'interest stability and to realize accurate personalized service recommendations,it fails to take tourism product popularity into consideration.Tourists'interest similarity degree is increasingly inaccurate in highly popular tourism products while it is increasingly accurate in less popular tourism products.In order to improve the recommendation accuracy,a mathematical model involving tourism product popularity is constructed based on nonlinear forgetting functions so as to weaken the weight of highly popular tourism products and adjust tourists'interest similarity degree.The experiment shows that the mean absolute difference value decreases with recommendation accuracy increasing significantly when product popularity is included.
nonlinear forgetting function;product popularity;collaborative filtering;personalized recommendation
F590
A
2095-929X(2016)01-0092-08
2015-12-03
国家自然科学基金“双重委托代理下旅游服务供应链激励机制设计”(71201053);湖南省教育厅优秀青年项目“基于双边非对称信息的合作旅游服务质量生产契约研究”(15B070);湖南工业大学研究生创新基金项目“旅游个性化服务推荐”(cx1507)。
鲁芳,女,湖南浏阳人,湖南工业大学财经学院副教授,研究方向:信息安全、物流与供应链管理;彭志强,男,河南信阳人,湖南工业大学财经学院硕士生,研究方向:物流与供应链管理,Email:946463152@qq.com;罗定提,湖南长沙人,湖南工业大学管理学院教授,研究方向:物流与供应链管理。
猜你喜欢
新班主任(2022年4期)2022-04-27
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
科学大众(2020年23期)2021-01-18
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
文苑(2020年4期)2020-05-30
汽车观察(2019年2期)2019-03-15
新闻传播(2018年12期)2018-09-19
汽车与新动力(2016年6期)2017-01-04
