
大数据分析中基于MapReduce的空间权重创建方法研究
2016-08-06 01:58:31郭平
重庆邮电大学学报(自然科学版) 2016年4期
关键词:可扩展性
郭 平
(广东交通职业技术学院 信息管理中心,广东 广州 510650)
大数据分析中基于MapReduce的空间权重创建方法研究
郭平
(广东交通职业技术学院 信息管理中心,广东 广州 510650)
摘要:大数据空间分析是Cyber-GIS的重要方面。如何利用现有的网络基础设施(比如大规模计算集群)对大数据进行并行分布式空间分析仍然是一大难题。为此,提出一种基于MapReduce的空间权重创建方法。该方法依托Hadoop框架组织计算资源,基于MapReduce模式从大规模空间数据集中高效创建出空间权重:大空间数据被分为多个数据块,将映射器分布给计算集群中的不同节点,以便在数据中寻找出空间对象的相邻对象,由约简器从不同节点处收集相关结果并生成权重文件。利用Amazon公司弹性MapReduce的Hadoop框架,从人工空间数据中创建基于邻近概念的权重矩阵进行仿真。实验结果表明,该方法的性能优于传统方法,解决了大数据的空间权重创建问题。
关键词:大数据空间分析;MapReduce;空间权重;附近邻居;可扩展性
0引言
大空间数据的出现产生了一些新颖而又颇具挑战性的科学问题[1-3],例如,空间数据的多尺度表达、基于服务质量保证的空间数据互操作等。为此,人们提出了CyberGIS[4]框架,通过一种空间中间件,利用当前网络融合基础设施(converged infrastructure,CI)所具有的强大计算资源(比如高性能云计算[4-5])来解决这些问题。该框架将空间数据操作、地理可视化、空间模式检测、空间过程建模和空间分析等分布式地理处理组件,无缝地集成为一种可以高效利用CI计算能力的空间中间件。在这些分布式空间处理组件中,可以解决大空间数据问题的并行空间分析方案是网络地理信息系统(geographic information system,GIS)的重要组件[7]。
空间分析过程包括数据预处理、可视化、勘查、模型规格、估计和验证[8]。然而,传统的空间分析数据结构和算法以桌面计算机架构为基础,且只限于桌面计算机架构。鉴于内存空间和计算能力有限,无法用于大空间数据的空间分析中[9-10]。因此,有必要设计和开发一种可扩展的网络GIS系统平台,为高效的空间分析提供支持。
本文重点研究大数据空间分析时的空间权重生成问题。空间权重代表了空间对象的地理相关性,因此,它是空间分析的重要方面。空间权重矩阵广泛应用于空间自相关和空间回归等多种空间分析算法[11-12]。空间权重生成问题主要是指从空间数据中提取出空间相邻信息(邻近权重)和空间距离(距离权重)等空间结构。然而,传统的空间权重生成算法[13-14]基于本地硬件(比如CPU、内存和硬盘),性能受限,无法用于处理超大规模空间数据集。
因此,本文提出一种基于MapReduce的空间权重创建算法,利用大空间数据创建邻近空间权重。与传统的权重创建算法不同,该方法运行于MapReduce模式下:映射器分布于计算集群中,可并行搜索附近邻居,然后约简器收集结果,进而生成权重矩阵。为了测试该算法的性能,本文设计了相关实验,利用Amazon公司弹性MapReduce的Hadoop框架从人工空间数据中生成Queen邻近矩阵文件,所用的人工空间数据包含多达1.9亿个多边形。实验结果表明,该算法通过利用高性能计算资源,解决了大空间数据基于邻近概念的空间权重生成问题。
1基于MapReduce的空间权重生成
1.1空间权重
空间权重是空间分析(比如空间自相关测试、空间回归)的重要方面,需要进行空间结构表示。空间特征的空间结构往往描述为一个n行n列空间权重矩阵W(n表示几何特征数量)。如果用featurei和featuej表示为相邻特征,则单元值wij≠0。对于近邻权重矩阵,wij的值要么为1(featurei和featuej相邻),要么为0(featurei和featuej不相邻)。
将一个点定义为2个坐标构成的数组:point=(x,y),将一个多边形定义为M个点构成的集合:Polygon={point1,point2,…,pointM}。对一个包含n个多边形的空间数据集,DS={Polygon1,Polygon2,…,PolygonN},构建一个基于邻近概念的权重矩阵W,就是要对DS中的每个多边形Polygoni,i∈[1,N]寻找出所有的相邻多边形。有3种类型的邻近概念可确定权重矩阵中的数值分布:①rook型邻近(相邻多边形必须共享一条边);②bishop型邻近(相邻多边形需要共享一个角);③queen型邻近(相邻多边形要么共享一条边要么共享一个角)。
传统的邻近权重矩阵生成算法(如GeoDa[13]和PySAL[14])利用几何特征来确定2个多边形有没有共享边或共享顶点。如果通过比较所有多边形对的顶点或边缘来确定邻近关系,则这一过程的计算成本太大,时间复杂度为O(n2)。如果对这些几何形状编制空间索引,则在搜索候选相邻多边形时的时间复杂度下降为O(logN)。然而,此时需要额外比较候选和目标几何形状间的原始点或边,以便确定2个几何形状是否相邻。此外,这些算法需要计算机能够将所有几何形状载入内存。因此,无法从超大规模空间数据集中生成邻近权重。
为此,本文提出一种基于Hadoop的MapReduce算法(见算法1),可从超大规模空间数据集中创建邻近权重。该算法基于如下策略:根据多边形包含的顶点和边来对多边形的情况进行汇总。如果2个多边形中出现同一个点/边,则这2个多边形应该是queen型邻近多边形。为了清晰描述本文算法,我们结合queen邻近权重的创建来描述MapReduce算法。该算法依照相同的汇总思路经过简单更改后即可用于rook或bishop邻近权重的创建。
首先,为了利用多个计算机节点实现map任务的并行化,Hadoop将会把数据平均分为多个数据块,每个数据块由一个计算机节点处理。在每个节点上,映射器为每个顶点创建一个字典,并将相关多边形添加到数据集中。然后,Hadoop系统将会着眼于约简阶段的计算任务,对所有计算机节点创建的字典进行混洗排序。约简器将会根据键(顶点)对这些字典进行融合。所有字典中具有相同键值的邻近多边形组成的集合或数值,经过融合后生成邻近权重文件。
算法1:邻近权重生成。
1:point_polygon_dict {}
/*系统输入: 点:多边形 */
2:forline∈sys.stdindo
3:items←line.split()
4:poly_id←items[0]
5:forpoint∈items[1:] do
6: ifpoint∉point_polygon_dictthen
7:point_polygon_dict[point]←set()
8: end
9:point_polygon_dict[point].add(poly_id)
10: end
11:end
/*为约简器生成输出*/
12:forpoint,neighbors∈point_polygon_dict.items() do
13: ifneighbors.length≡1 then
14: printneighbors
15: else
16:formaster_poly∈neighborsdo
17:forneighbor_poly∈neighborsdo
18: ifmaster_poly≠neighbor_polythen
19: printmaster_poly,neighbor_poly
20:end
21:end
22:end
23: end
24:end
1.2MapReduce过程
1.2.1映射
映射的主要目的是利用顶点创建一个{key-value}字典对象作为键,同时,创建包含该顶点的一组多边形作为值。该算法首先从Hadoop系统的标准输入中读取数据。逐行处理数据。每行表示多边形的几何信息,且以逗号分隔:polyid,point1,point2,…,pointN。这些信息将被解析并存储于poly_polygon_dict字典中。当映射器处理完数据后,将会对poly_polygon_dict字典中的所有值进行迭代,为约简器准备(key value)数据。因为poly_polygon_dict中的值表示共享相同键(顶点)的多边形,所以,认为它们相邻。之后,映射器将键-值对{polygon:neighbor_polygon}写为约简器的相邻信息。
1.2.2约简
Hadoop系统将会监测和采集所有映射器的输出。一旦映射任务的进度达到系统配置或用户指定阈值,则Hadoop系统将会启动约简任务。约简任务分为3步:混洗,排序和约简。在混洗步骤,Hadoop系统对映射输出进行混洗并将映射输出转移到约简器作为输入。在下一个排序步骤中,将会根据{polyid:neighbor_poly_id}字典中多边形主ID(键)对映射输出进行排序。混洗和排序步骤同时进行,以保证每个约简器的输入均被正确排序。在约简步骤中,运行算法2中定义的算法以并行生成每个约简器的权重文件内容。
算法2:邻近权重生成时的约简算法。
1:current_master_poly←None
2:current_neighbor_set←set()
3:temp_master_poly←None
/* 系统输入:{polyid:neighbor_poly_id} */
4:forline∈sys.stdindo
5:neighbors←line.split()
6:temp_master_poly←neighbors[0]
7:temp_neighbor_poly←None
8: ifneighbor.length>0then
9:temp_neighbor_poly=neighbors[0]
10:end
11:ifcurrent_master_poly≡temp_master_polythen
12: iftemp_neighbor_poly≠Nonethen
13:current_neighbor_set
.add(temp_neighbor_poly)
14:end
15:else
16:ifcurrent_master_poly≡Nonethen
17: ifneighbor_poly≠Nonethen
18:Current_neighbor_set←set()
19: else
20:current_neighbor_set←set([neighbor_poly])
21: end
22:else
23: WriteWeightsFilecurrent_master_poly,current_neighbor_set
24: end
25:end
26:end /* 在需要情况下处理最后一行 */
27:ifcurrent_master_poly≡temp_master_polythen/* 将GAL结果写入输出权重文件中 */
28:num_neighbors←current_neighbor_set.length()
29: printcurrent_master_poly,num_neighbors
30: printcurrent_neighbor_set.items()
31:end
1.2.3生成邻近权重文件
因为每个约简器只将其输入写入本地磁盘,所以,需要一个专门的融合步骤将所有单个结果进行融合,以生成一个有效的权重文件。本文采用Hadoop平台提供的分布式拷贝工具(DistCp)来完成MapReduce模式下的融合任务。为了加快融合任务的速度,对约简器做适当配置,将其输出压缩为GNU zip格式,于是,数据服务器和计算节点间的数据传输速度加快,且压缩后的文件可直接串联。
2仿真实验
2.1样本数据集
本文实验使用的底图为美国芝加哥市的地块数据。该地块数据包含592 521个多边形。为了模拟大规模数据集,利用该底图创建人工大数据:人工多次复制该底图,然后并排放到一起,生成一个大型人工底图。例如,图1即为4倍于原始数据且含有2 370 084个多边形的数据图。在实验中创建的最大规模数据为32倍于原始数据、含有18 960 672个多边形的数据。整个数据集包括原始数据的1倍、2倍、4倍、8倍、16倍和32倍数据。

图1 底图连续复制4次生成的人工数据Fig.1 After continuous replication 4 times to generate artificial data
2.2测试系统
本文选择Amazon的弹性MapReduce(elastic mapreduce,EMR)服务(http://aws.amazon.com/)来创建一个Hadoop测试系统。Amazon EMR服务提供了一种易于使用的可定制Hadoop系统。采用Amazon提供的Hadoop缺省配置。我们选择运行于Amazon EMR上、节点数量为1至18个节点的“C3 Extra Large(C3.xlarge)”类型计算机实例集群。除了计算机集群外,Hadoop系统运行时还通过一个主节点来监测所有计算机实例并与所有计算机实例进行通信。C3.xlarge节点的配置包括7.5 GB内存,14核(4核×3.5个单元)CPU,80 GB (2×40 GB SSD),64位操作系统和500 Mbit/s中等网速。除了Hadoop测试系统外,我们还在一台单机上测试了相同的MapReduce算法,单机配置为2.93 GHz 8核CPU,16 GByte内存,100 GByte硬盘,64位操作系统。
2.3结果
为了测试本文MapReduce性能,利用python语言来实现一个桌面版本及通过Hadoop的流式管道功能运行另外一种Hadoop版本。第1个实验是在一台测试单机上运行MapReduce算法。该算法从不同数据规模中生成邻近权重的运行时间如图2所示。从图2可以看到,随着数据规模的增长,本文算法的运行时间也在增加。该算法的复杂度为O(N),在处理16倍的数据集(9 480 338个多边形)时达到最大计算能力。
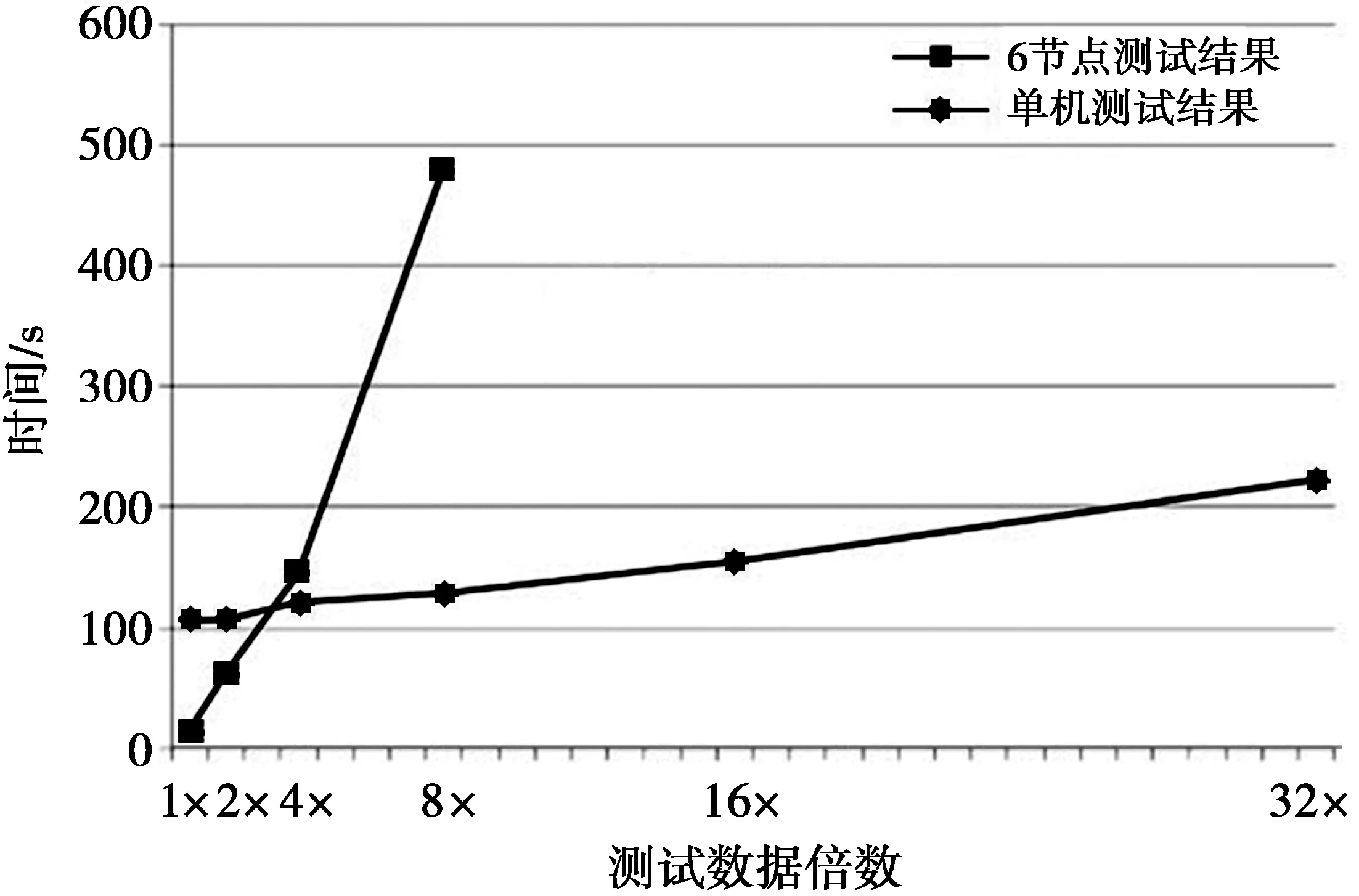
图2 利用6个计算机节点从不同数据规模中生成邻近权重Fig.2 Using 6 computer nodes to generate neighboring weights from different data scale
第2个实验是在Amazon EMR Hadoop系统上运行MapReduce算法。首先,对包含一个主节点和6个C3.xlarge节点的Hadoop系统进行配置,分别测试1倍、2倍、4倍、8倍、16倍和32倍数据时的算法性能。该算法从不同数据规模中生成邻近权重的运行时间见图2(方点线)。因为Hadoop需要花费额外时间传递程序及与运行节点通信,所以,如果数据集为原始数据的4倍以下(大约2百万个多边形),则运行时间慢于桌面计算机上运行相同程序所需时间。然而,数据集越大,该算法在Hadoop系统上的性能越高。例如,对于8倍数据,算法在Hadoop上的完成时间为167 s,其运行时间远快于桌面计算机(482.67 s)。此外,运行时间呈线性增长,表明本文算法随着数据规模的增长具有良好的可扩展性。
然后,在后续测试中,本文创建带有6, 12, 14, 18个计算机节点的不同Hadoop系统,以便利用32倍数据创建邻近权重。运行时间如图3所示。利用Hadoop中的18个计算机节点,可在163 s内生成32倍数据的邻近权重,这是我们在所有测试中获得的最优性能。在图3中,当计算机节点数量增多时,运行时间没有线性下降。这一现象是合理的,因为当计算节点数量增多时,需要额外时间在Hadoop系统内进行通信。
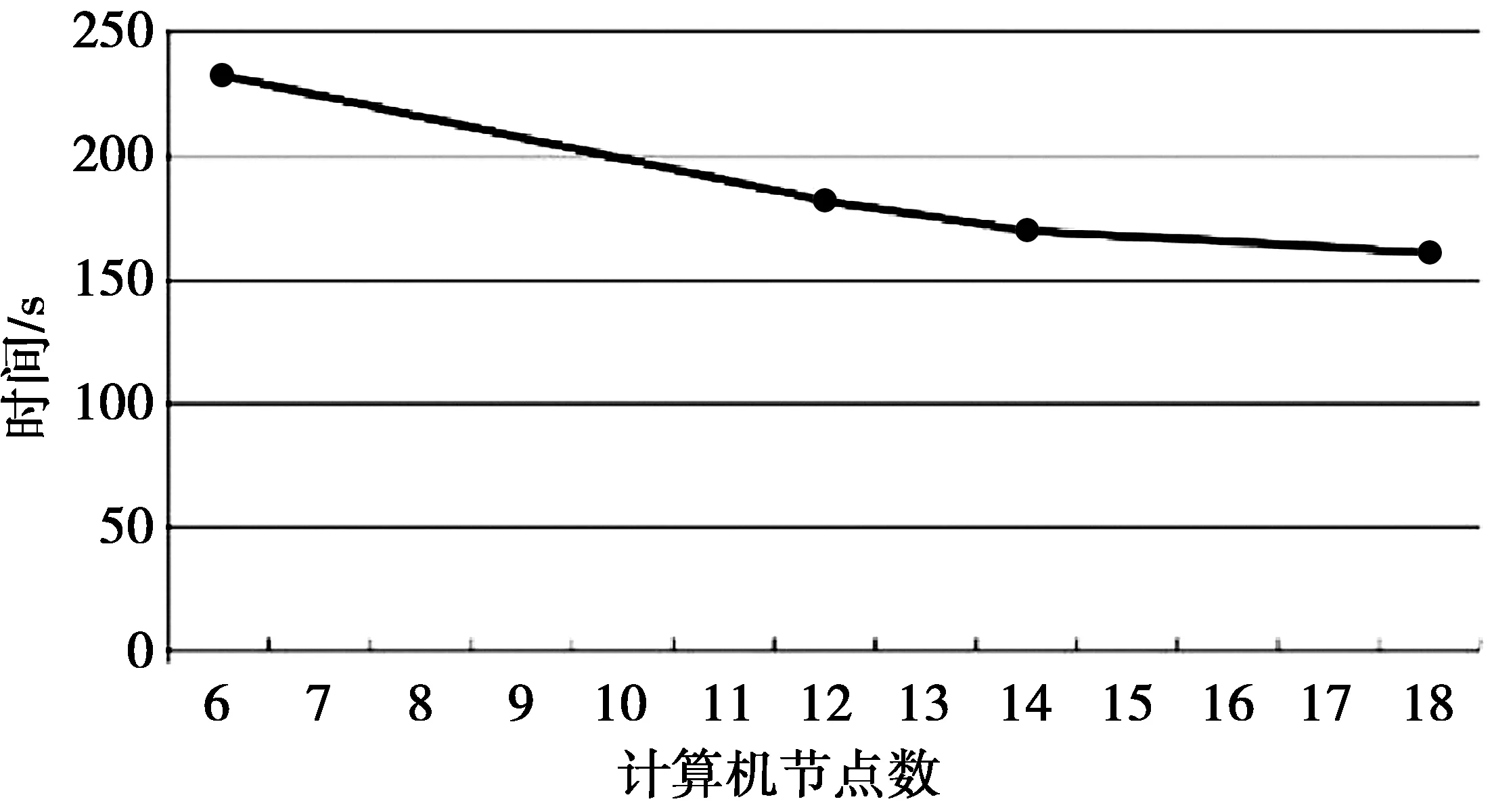
图3 利用不同计算机节点从32倍数据中生成邻近权重Fig.3 Using different computer nodes to generate neighboring weights from 32 times data
最后,为了进一步体现本文方法的优越性,比较本文方法与传统的邻近权重矩阵生成算法GeoDa[13]和PySAL[14]从不同数据规模中生成邻近权重的运行时间,实验结果如图4所示。从图4可以看到,随着数据规模的增加,不同方法的运行时间都在显著增加。但总的来说,本文方法的性能更优,从1倍数据到32倍数据,本文方法的运行时间相比GeoD和PySAL平均降低了约14.15%和17.64%。仔细分析其原因可知,这主要是因为GeoD和PySAL需要计算几何特征间的距离,这种基于距离的计算方法容易受到数据规模和数据分布的影响,另外GeoD和PySAL主要基于本地硬件,随着数据规模的增加,它们的性能严重受限,因此,运行时间较长。而本文方法基于邻近概念来创建空间权重,充分利用了空间对象的地理相关性,通过MapReduce模式避免了不必要的搜索操作,节省了时间。
3结束语
本文对大数据空间分析时的空间权重生成问题进行研究,提出一种MapReduce算法。该算法利用Amazon EC2云计算平台等高性能计算资源,可为大空间数据(约1.9亿个多边形)生成权重文件,解决了大空间数据的邻近权重生成问题。仿真实验结果表明,本文算法的性能优于传统的以桌面计算机架构为基础的方法。
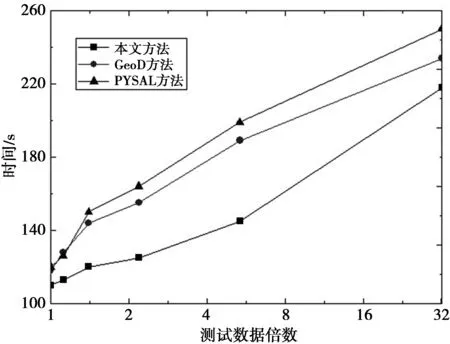
图4 不同方法的运行时间比较Fig.4 Running time comparison of different methods
参考文献:
[1]李德毅.大数据认知—“2015 大数据价值实现之路高峰论坛”主题报告[J].重庆理工大学学报:自然科学,2015(9):1-6.
LI Deyi.Big Data Cognition: Keynote Lecture of“2015 Forum of Big Data Value Realization Road”[J].Journal of Chongqing University of Technology:Natural Science,2015(9):1-6.
[2]吴烨, 陈荦, 熊伟, 等. 面向高效检索的多源地理空间数据关联模型[J]. 计算机学报, 2014, 37(9): 1999-2010
WU Ye, CHEN Luo,XIONG Wei,et al. Multi-Source Geospatial Data Correlation Model for Efficient Retrieval [J].Chinese Journal of Computers, 2014, 37(9): 1999-2010
[3]GOODCHILD M F. Whose hand on the tiller? Revisiting Spatial Statistical Analysis and GIS[M]. Berlin Heidelberg:Springer, 2010: 49-59.
[4]WANG S. A CyberGIS framework for the synthesis of cyber infrastructure, GIS, and spatial analysis [J]. Annals of the Association of American Geographers, 2010, 100(3): 535-557.
[5]刘荣华, 魏加华, 翁燕章, 等. HydroMP: 基于云计算的水动力学建模及计算服务平台[J]. 清华大学学报: 自然科学版, 2014 (5): 575-583.
LIU Ronghua,WEI Jiahua,WENG Yanzhang,et al. HydroMP: A cloud computing based platform for hydraulic modeling and simulation service[J].Journal of Tsinghua University: Science and Technology 2014(5): 575-583.
[6]WANG S, ANSELIN L, BHADURI B, et al. CyberGIS software: a synthetic review and integration roadmap[J]. International Journal of Geographical Information Science, 2013, 27(11): 2122-2145.
[7]ANSELIN L, REY S J. Spatial econometrics in an age of CyberGIScience[J]. International Journal of Geographical Information Science, 2012, 26(12): 2211-2226.
[8]ANSELIN L, REY S J. Spatial econometrics in an age of CyberGIScience[J]. International Journal of Geographical Information Science, 2012, 26(12): 2211-2226.
[9]关丽, 吕雪锋. 面向空间数据组织的地理空间剖分框架性质分析[J]. 北京大学学报: 自然科学版, 2012, 48(1): 123-132.
GUAN Li,LV Xuefeng. Properties Analysis of Geospatial Subdivision Grid Framework for Spatial Data Organization[J].Journal of Peking University: Natural Science Edition, 2012, 48(1): 123-132.
[10] CRAMPTON J W, GRAHAM M, POORTHUIS A, et al. Beyond the geotag: situating ‘big data’and leveraging the potential of the geoweb [J]. Cartography and Geographic Information Science, 2013, 40(2): 130-139.
[11] WAGNER H H, FORTIN M J. A conceptual framework for the spatial analysis of landscape genetic data [J]. Conservation Genetics, 2013, 14(2): 253-261.
[12] 陈江平, 黄炳坚. 数据空间自相关性对关联规则的挖掘与实验分析[J]. 地球信息科学学报, 2011, 13(1): 109-117.
CHEN Jiangping, HUANG Bingjian. Application and Effects of Data Spatial Autocorrelation on Associstion Rule Mining [J].Journal of Geo-Information Science,2011, 13(1): 109-117
[13] ANSELIN L, SYABRI I, KHO Y. GeoDa: an introduction to spatial data analysis[M]. Berlin Heidelberg: Springer, 2010:73-89.
[14] REY S J, ANSELIN L. PySAL: A Python library of spatial analytical methods[M]. Berlin Heidelberg: Springer, 2010: 175-193.
DOI:10.3979/j.issn.1673-825X.2016.04.014
收稿日期:2015-01-28
修订日期:2016-04-29通讯作者:郭平hdgp@163.com
基金项目:广东省交通运输厅科技项目( 2013-02-093)
Foundation Item:The Guangdong Provincial Communications Department Project (2013-02-093)
中图分类号:TP391
文献标志码:A
文章编号:1673-825X(2016)04-0533-06
作者简介:

郭平(1970-),男,湖南澧县人,副教授,硕士,主要研究方向为物联网、云计算、大数据。E-mail: hdgp@163.com。
(编辑:刘勇)
Research on construction method of spatial weights based on mapreduce in analysis of big data
GUO Ping
(Information Management Center, GuangDong Communications Polytechnic, Guangzhou 510650, P.R. China)
Abstract:Spatial analysis of big data is a key component of Cyber-GIS. However, how to exploit existing cyber infrastructure (e.g. large computing clusters) in performing parallel and distributed spatial analysis on Big data remains a huge challenge. To solve this problem, a construction method of spatial weights based on MapReduce is proposed in this paper, which creates spatial weights from very large spatial datasets efficiently by using computing resources that are organized in the Hadoop framework: the big spatial data is firstly chunked into pieces, then the mappers are distributed to different nodes in the computing cluster to find neighbors of spatial objects in the data, and finally the reducers collect the results from different nodes to generate the weights file. To test the performance of this algorithm, we design experiment to create contiguity-based weights matrix from artificial spatial data using Amazon’s Hadoop framework called Elastic MapReduce. The experimental results show that the performance of the proposed method is better than the traditional method, and solve the construct problem of spatial weight in big data.
Keywords:spatial analysis of big data; MapReduce; spatial weights; contiguous neighbors; scalability
猜你喜欢
汽车零部件(2017年3期)2017-07-12 17:03:58
自动化博览(2017年2期)2017-06-05 11:40:39
电脑知识与技术(2016年14期)2016-06-30 20:29:18
现代工业经济和信息化(2016年12期)2016-05-17 05:38:00
软件导刊(2015年4期)2015-04-30 13:25:21
航空兵器(2014年5期)2015-02-10 02:45:44
