
基于特征融合和优化极限学习机算法的虹膜识别系统
2016-08-05 08:05:42路春辉
计算机应用与软件 2016年7期
路 春 辉
(广东工程职业技术学院信息工程学院 广东 广州 510520)
基于特征融合和优化极限学习机算法的虹膜识别系统
路 春 辉
(广东工程职业技术学院信息工程学院广东 广州 510520)
摘要针对虹膜图像采集过程中存在光照、干扰等因素,为进一步提高虹膜图像识别的准确率,提出一种基于组合特征提取的优化极限学习机(ELM)模型来提高虹膜图像识别的精度。模型考虑了特征提取和分类器优化两者均起着重要作用,利用灰度共生矩阵(GLCM)和多通道2D Gabor滤波器特征提取后进行特征融合,得到更丰富的特征信息,并设计改进了蜂群算法(IABC)优化ELM模型作为分类器。同时设计的线性加权多目标函数综合考虑分类精度和网络结构,从而有效提高了虹膜识别的准确率。实验表明提出的模型通过结合两种特征提取方法,能提取出更丰富的可区分特征,并且结合优化分类器得到了很高的分类准确率,是一种有效的虹膜识别模型。
关键词特征提取虹膜识别灰度共生矩阵多通道2D Gabor滤波器极限学习机
0引言
生物特征识别技术是指通过计算机,利用人体所固有的生理特征或行为特征来进行个人身份鉴定。近年来,基于人脸、指纹、虹膜、声音等生物特征的识别技术引起人们关注,其中人眼的虹膜具有丰富的纹理信息和特征,与其他生物特征相比,具有唯一性、稳定性和非侵犯性等优点。因此基于虹膜的身份识别系统研究正成为生物特征识别领域的一个研究热点[1,2]。
虹膜识别系统主要包括三部分:(1) 虹膜图像预处理;(2) 虹膜特征提取;(3) 虹膜分类。虹膜特征提取是虹膜识别系统中最重要的步骤之一。Daugman根据Gabor变换提出了2D Gabor滤波器理论[3]。之后Daugman[4]利用多尺度正交小波法提取虹膜纹理信息并生成2048位虹膜代码。Monro等[5]采用一维离散余弦变换(DCT)作为特征提取方法进行虹膜匹配。Ma等[6]采用纹理分析方法并利用多通道Gabor滤波器捕捉虹膜图像全局和局部细节。He等[7]基于灰度共生矩阵(GLCM)提取特征和图像像素统计强度值属性作为虹膜的特征。
通过分析可以发现,尽管一些研究人员分别利用2D Gabor滤波器和GLCM进行特征提取,然而还未有相关的工作提出结合这两种方法来进行虹膜特征提取。多通道2D Gabor滤波器能够提供信号空间和频率的局部信息,达到局部最优化。而GLCM是一种统计分析方法,能够反映纹理图像中各灰度值在空间上的分布特性,是目前应用最广泛的一种纹理统计分析法。同时,由于眼睑、眼毛等对虹膜的遮挡和干扰,会使得提取的特征在准确性和稳定性方面有所下降,影响识别准确度。为了进一步提高识别精度,本研究尝试结合上述两种方法,通过特征提取进行特征组合以得到新的特征集合,从而更有效地反映虹膜图像的特征和纹理信息。
除了特征提取之外,分类器的选择在虹膜识别系统中也起着重要的影响。在大多数虹膜识别研究中,使用较多的方法包括人工神经网络(ANN)、支持向量机(SVM)以及基于距离的分类模型(DBC)[8]。其中SVM分类方法取得的效果较好。2007年,He等[7]利用传统SVM进行虹膜识别。2008年,Roy等[9]利用遗传算法进行特征选择并结合非对称SVM进行虹膜识别。2009年苑玮琦等[10]提出基于纹理特征点匹配的自适应虹膜识别方法。同年,他又提出利用2D Gabor滤波器提取纹理方向特征的虹膜识别方法[11]。2011年,Roy等[12]利用Daubechies小波变换提取纹理特征,并结合遗传算法和自适应非对称SVM(AASVMs)以提高虹膜识别准确率。
从这些研究中可以发现,基于人工智能技术的虹膜识别方法已得到了广泛的关注和研究,其中基于SVM的分类模型取得了很好的效果,但仍存在以下两个问题:(1) SVM中的核宽γ和惩罚因子C对分类效果起着重要影响,传统的网格搜索和基于梯度下降[13]的搜索方法都各有不足,难以找到最优的参数,使得模型的表现不稳定;(2) 在设计适应度函数时,通常都是采用分类准确率作为评估标准,很少考虑其他重要因素,容易产生过拟合问题,也会消耗大量训练时间,降低模型的分类效率。
基于上述分析,为了克服上述缺点,得到识别率更高的虹膜识别模型,提出了结合GLCM和多通道2D Gabor滤波器的特征提取方法,并结合优化极限学习机(ELM)分类模型—IABC-ELM模型,用于虹膜识别。该模型提出利用GLCM和多通道2D Gabor滤波器进行特征提取,然后将两种方法得到的特征子集进行特征组合作为分类模型的输入。在分类模型上,提出改进的蜂群算法IABC(Improved Artificial Bee Colony)用于优化ELM分类模型的网络权重,从而得到最优的分类模型。此外,设计了线性加权多目标函数,在最大化分类精度的同时也考虑了网络结构的简化,目标函数由分类准确率和网络隐层节点个数两个子函数通过线性加权计算所得。
1改进的蜂群算法(IABC)
ABC算法由Erciyes大学Karaboga教授于2005年提出,它是最重要的元启发智能算法之一,源于蜜蜂觅食行为的研究,其核心思想是利用蜂群的协作机制结合个体蜜蜂的局部搜索,实现有针对性寻找最优解的过程[14]。由于ABC算法简单易实现、调节参数少、全局寻优能力强,并且在解决实际问题中展示了优越性,近年来被广泛用于解决各种现实复杂优化问题[15]。
ABC算法的具体机制如下:蜂群由三种蜜蜂组成,分别是雇佣蜂、跟随蜂和侦查蜂。蜂群的食物源可看作为问题P的可行解集合,每一个食物源的位置与问题中每一个可行解相对应,目标函数f的计算值决定食物源的优劣,雇佣蜂的数量与食物源的数量相等,那么食物源的位置可用实数向量xi=(xi1,xi2,…,xid)表示。初始种群根据下面公式随机生成SN个解实数向量,每个解xi,i =1,2,…,SN,其中SN是一个d维向量。
(1)
算法将这些食物源随机分配给雇佣蜂,并利用目标函数计算其适应度值,然后开始对食物源进行循环搜索,循环次数为gen,当指定精度达到预定值或者达到最大迭代次数设定值Genmax时,算法停止运行。首先,雇佣蜂对相应的食物源进行搜索,随机选择一个不同于自己的邻域蜂,按照下面的公式在解空间内进行邻域探索,从而产生新的食物源vij:
vij=xij+uij(xij-xkj)
(2)
其中uij是[-1,1]之间均匀分布的随机实数,j和k是随机产生的维度数值,且j必与k相异。
研究发现,ABC算法具有较强的全局搜索能力,但是局部搜索能力较弱[16],在侦查蜂搜索阶段,算法摒弃了当前解,随机生成一个新的可行解。该解可能是个比之前更差的解,降低了算法效率,因此为了进一步提高ABC算法的性能,考虑了当前解的情况,基于当前解所提供的信息产生新的可行解,使得新的解不是完全随机生成,而是得到之前解的指导信息,朝更好的方向搜索。解的更新式为:
(3)

(4)
其中fitnessi是第i个解对应的适应度值,NP为种群数量。
当一个食物源xi在某一位置连续limit代都未得到改善,说明解xi很有可能陷入局部极小值而未找到全局最优解,则相对应的跟随蜂弃掉该食物源,并根据式(3)的搜索方式生成一个新的食物源。算法的具体流程如图1所示。

图1 ABC算法的整体流程图
2极限学习机(ELM)
ELM算法由Huang等提出,它是一种新型单隐层前馈神经网络,研究已经证明了ELM具有与神经网络相同的全局逼近能力[17]。其网络结构分为三层:输入层、单个隐藏层和输出层,其中的网络输入权重和隐偏倚随机生成,且一旦生成不需要调节,输出权重值直接由最小二乘估计方法计算得出。ELM不仅具有良好的泛化能力,而且由于不需要迭代调节网络权重值,避免了梯度下降算法产生的局部极值、学习时间长以及学习率的影响等问题,极大地提高了训练和测试速度,因此ELM的研究和应用受到了广泛的关注。
极限学习机的网络结构如图2所示。
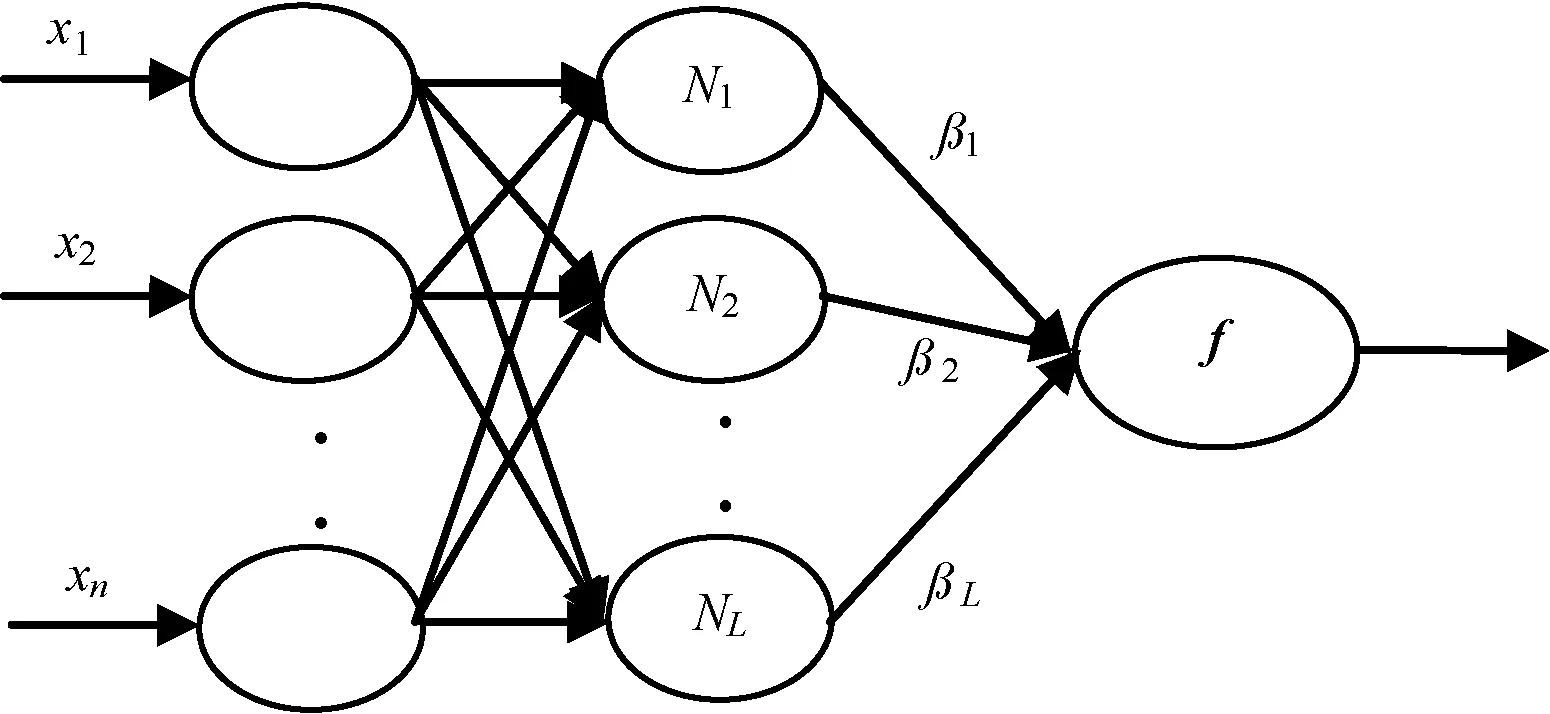
图2 ELM的网络结构
对于N个不同的训练样本集(xi,ti), i =1,2,…,N,其中xi= [xi1,xi2, …,xid]T∈ Rn, ti= [ti1,ti2,…,tim]T∈Rm,具有L个隐层节点和激活函数g(x)的单隐层前馈神经网络,表达式如下:
(5)
其中wj= [wj1,wj2,…,wjn]T( j = 1, 2, …, L)表示连接第j个隐层节点和输入层节点之间的输入权重向量值,bj表示第j个隐层节点的偏倚,wj·xi表示wj和xi的内积,βj= [βj1,βj2,…,βjL]T表示连接第j个隐层节点和输出层节点之间的输出权重向量值。Oi为网络中相应的xi的实际结果。
Huang等在文献[18]中已经证明如果激活函数g(x)无限可微,那么单隐层网络中的输入权重值和隐层偏倚值可以随机生成,且一旦固定不需要迭代调节,使得:
(6)
上述公式实际上就是找到线性系统Hβ = T的最小二乘解β′。其中T = [t1, t2, …, tm]T是目标矩阵(期望得到的输出值)。
H=H (w1,w2,…,wL,b1,b2,…,bL,x1,x2,…,xN)
(7)
其中H = {hij} (i =1,2,…,N;j =1,2,…,L)称为隐层输出矩阵,H的第j个隐层节点的第j列对应输入x1, x2, …, xN,H的第i行对应输入xi的输出向量。
若隐层节点数L等于训练样本个数N时,那么H是个可逆方阵,单隐层前馈神经网络能以零误差逼近训练样本。但在大多数情况下,隐层节点个数会远小于训练样本个数,即L≪N,那么H是一个N×L的矩阵,通常采用最小二乘方法来确定线性系统的输出权重值:
β′=H+T
(8)
其中H+为隐层输出矩阵H的Moore-Penrose广义逆矩阵。
ELM算法的学习过程主要分为三步:
(1) 随机产生输入权重值和隐层偏倚值(wi, bi), i = 1, 2,…,L;
(2) 根据式(4)计算隐层输出矩阵H;
(3) 计算输出权重值β:β′=H+T,完成ELM的学习。
3提出的模型
在这一部分,将详细介绍基于结合GLCM和多通道2D Gabor滤波器特征提取的IABC-ELM虹膜识别系统。如之前所述,本系统的目的是要进一步提高虹膜识别的准确率。为了让系统获得更好的性能,本模型整个运行的过程包括三个阶段:第一阶段,利用GLCM结合多通道2D Gabor滤波器进行特征提取,将这两种方法提取出的特征组成新的虹膜特征集合;第二阶段,利用第一阶段提供的最优特征集合作为分类模型的输入,在不同训练数据集上进行训练,同时利用改进的ABC算法优化ELM模型,得到最优IABC-ELM分类器;第三阶段,利用训练好的分类器在测试数据集上测试其模型的性能,从而达到虹膜识别的目的。
3.1图像预处理
为了准确获取虹膜信息,消除光照不均匀等因素影响,提高虹膜识别准确率,在特征提取前要对虹膜图像进行预处理。我们通过六个步骤实现图像预处理,具体处理过程如图3所示。

图3 图像预处理流程
第一步:评估图像质量,筛掉质量较差的图像;第二步:基于光斑中心,根据经验值确认两个感兴趣区(ROI),包括较小ROI中的瞳孔区和较大ROI中的瞳孔和虹膜区;第三步:利用坎尼算子和霍夫变换对较小ROI区域中的瞳孔进行定位;第四步:通过较大ROI区域中虹膜和白膜间的灰度梯度差异进行边缘定位;第五步:对图像标准化操作,消除虹膜在径向延伸的影响(产生虹膜图像为512×64像素);第六步:用全局直方图强化图像以消除不均匀光照等外界因素的影响。图像预处理过程效果如图4所示。

图4 图像预处理各阶段示意图
3.2多通道2D Gabor滤波特征提取
基于Gabor滤波器被广泛用于计算机视觉中,2D Gabor滤波器具有可调方向和径向频率选择、可调中心频率等一系列优点,具体可参考文献[19]。在本文研究中,采用这种方法进行特征提取。直角坐标系下2D Gabor的表达式如下:
(9)
其中f是沿x轴θ方向的正弦平面波频率,σx′和σy′分别是沿x′轴和y′轴的标准差。
为了得到多方向和多尺度的纹理信息,本文采用的多通道2D Gabor滤波器,通过不同方向的滤波器对纹理图像进行滤波,选输出响应最大的滤波器方向作为纹理方向。利用g(x)作为生成函数,可得到一组自相似滤波器,即Gabor滤波,表达式如下:
(10)
其中θ=nπ/k,{k|k>1,k∈Z},k为总方向个数,m和n分别表示尺度和方向的个数,n∈[0,k],a-m是比例系数。通过改变m和n的值可以得到一组方向和尺度各不相同的过滤器。
同时Gabor非正交性意味着在过滤后的图像中存在冗余信息,接下来需要降低这个冗余性。我们设置粗尺度滤波器和最优尺度滤波器的中心频率以确保Gabor滤波器的响应可以相互联系但不会在峰值频率相交。分别设滤波器的最高和最低频率值,差异度的计算式如下:
(11)
对给定图像,Gabor变换函数的表达式如下:
(12)
其中*表示复共轭操作符,(u,v)∈Ω表示滤波窗口的大小。变换系数的均值μmn和方差σmn分别定义为:
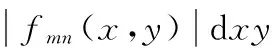
(13)
(14)
最后,通过结合μmn和方差σmn,可得到虹膜的特征向量:
FS={μ00,σ00,μ01,σ01,…,μM-1K-1,σM-1K-1}
其中M和K分别为多通道2D Gabor滤波器的尺度大小和方向。
3.3IABC-ELM模型
IABC-ELM模型是针对ELM模型自身网络权重参数优化问题,利用IABC算法良好的全局寻优能力,对ELM的权重进行自适应迭代优化,以得到更优的分类器。模型的整体流程如图5所示。该模型主要通过下面的步骤进行构建:
第一步选择L×(n+1)维粒子对解进行编码,其中前L×n维表示输入权重值,其余的L维表示隐层偏倚值,它们都是连续实数;
第二步对种群进行初始化,设定种群的大小、最大迭代次数、临界次数等参数;
第三步利用第二步所得到的解在ELM模型上训练;
第四步由于我们在最大化分类精度的同时,也要尽可能地简化ELM网络结构,所以设计的线性加权多目标函数综合考虑了平均分类准确率ACC(Averaged accuracy rate)和网络隐层节点个数,适应度值根据如下等式计算:
(15)
(16)
F=a·f1+(1-a)·f2
(17)
其中f1表示K折交叉验证K-fold CV(K-fold cross validation)得到的ACC均值,f2中的L表示ELM网络隐层节点个数,N为总节点个数。a为常量值,表示ELM分类精度所占的权重值,1-a为隐层节点个数所占的权重值,权重可以调整到一个恰当的值,这主要取决于各个子目标函数对评估结果的贡献大小,在本文中通过多次试验,a取值为0.8,在计算适应度值后,保存全局最优适应度值、全局最优个体;
第五步增加迭代次数;
第六步根据式(3)更新粒子相对应的位置,新粒子的位置不能超出界限,若新的粒子的位置超出了界限[Xmin,Xmax],那么新的位置设为其边界值Xmin或Xmax;
第七步利用第六步得到新的粒子进行解码所得到参数在ELM上训练,并根据式(17)计算该粒子的适应度值;
第八步记录当前种群的最优粒子,若当前的适应度值大于存储的最优适应度值,更新存储适应度值为当前值,否则,保持存储的适应度值不变;
第九步如果达到最大种群数量,算法转到第十步运行,否则,转到第六步运行;
第十步比较当前适应度值和全局最优适应度值,若当前值大于存储的全局最优适应度值,更新为当前值,否则,保持存储的适应度值不变;
第十一步如果达到最大迭代次数,算法转到第十二步运行,否则,转到第五步继续进行迭代优化;
第十二步输出全局最优的粒子,进行解码得到最优参数;
第十三步利用得到的最优参数结合训练集在ELM上训练,构造出最优的分类器;
第十四步利用得到的分类器在测试集上进行测试并输出最终的分类结果。
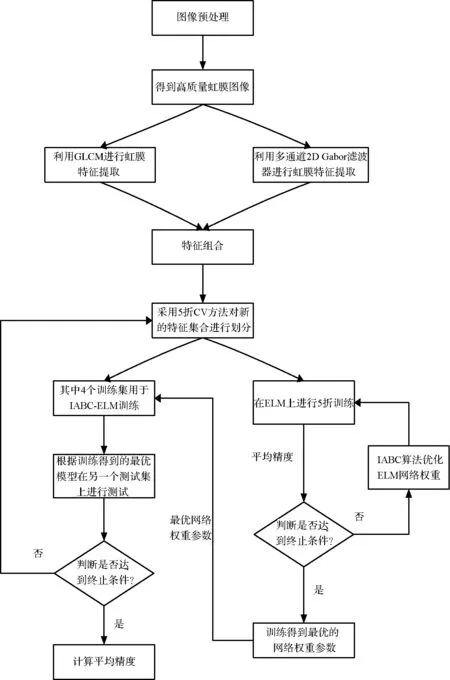
图5 模型的总体流程图
4实验设计
4.1数据描述
本实验所采用的虹膜数据集是利用虹膜图像捕获设备对一些测试人员进行数据采集,自组建的虹膜数据库BR-IRIS。图6给出了BR-IRIS图像数据库中的一些样本,BR-IRIS数据库的基本信息如表1所示。在该数据库中共有180个样本,我们分别捕捉了在不同光照条件下每个人左右虹膜的持续5秒的视频图像。每个视频包含25帧/秒,共采集11 500张图片。图像大小为480×576的8位灰度图像。此外,在实验过程中为了避免过拟合和欠拟合现象的发生,使得结果更具说服力,采用双层交叉验证方法[20]。内层5折交叉验证用来确定最优特征子集和最优参数组合,外层5折交叉验证用于评估ELM的分类性能。由于运行一次交叉验证不能保证结果的公正性,同时数据是随机抽样分割的,每次生产的训练集和测试集不会完全一样,在本实验中将模型运行10次,然后求平均值作为最终结果。
图6 BR-IRIS数据库图像的样本

年龄性别采样时间段采样环境19~45岁,大部分年龄在30岁左右男:女=8:210点,14点和19点三个时段室内正常光线(上午、下午和晚上)
4.2实验设置
本文提出的虹膜识别模型是Matlab 2012a开发环境下设计实现的,ELM 采用的是ELM工具包,采用的机器配置为Intel四核处理器,主频2.0GHZ,4GB内存。
在接下来模型的训练和相关算法比较过程中,模型的详细参数设置如下:对于GLCM,窗口大小为8,灰度值为16,像素对间距为4;对于Gabor滤波器,使用两组方向的滤波器对图像进行滤波,选取输出响应最大的滤波器方向作为该块的方向,其方向分别设置为θ=0°,45°,90°,135°和θ=0°,30°,60°,90°,120°,150°。滤波器的最高和最低频率分别为0.45和0.05;对于ABC算法,粒子初始位置均设为[-1,1]之间的随机数,种群数量为40,最大迭代次数为80,limit值为SN×D[21],其中SN为种群个数,D为解的维度。ELM中隐层激活函数采用Sigmoid函数。基于网格计算的SVM(Grid-SVM)模型中C和γ的搜索范围分别为C∈{2-10,2-9,…,215}和γ∈{2-15,2-14,…,25}。
5实验结果分析
为了验证提出的模型的有效性,首先分别采用基于GLCM和基于多通道2D Gabor过滤器特征提取,其中利用GLCM提取出一个特征子集,利用多通道2D Gabor提取出四个特征子集,然后将这两组特征子集组合得到新的四组特征子集。也就是说,共得到九个虹膜特征子集。为了便于说明,将这九个特征集合标记为fs1到fs9。表2给出了特征集合所相应的特征提取方法和参数。

表2 特征子集所对应的特征提取方法和参数设置情况
实验首先对虹膜特征组合的有效性进行评估。为了验证特征组合的有效性,表3给出了ELM模型通过5折CV在不同特征子集上得到的分类结果(Avg为均值,Dev为均方差)。

表3 九组特征子集在5折CV下分别结合ELM所得到的识别精度
为了使实验结果更明晰,图7给出了所得分类结果的比较。

图7 基于GLCM和多通道2DGabor滤波器特征提取在ELM上的识别精度比较
从图7中可以看出,基于多通道2D Gabor滤波器提取出四组特征子集的识别精度均高于基于GLCM的特征提取方法。这说明在虹膜特征提取方面,多通道2D Gabor滤波器比GLCM更稳定。
图8给出了通过GLCM提取的特征、多通道2D Gabor滤波器提取出的特征以及特征组合这三类特征集合在ELM分类模型上所取得的识别精度比较。从图8中可以看出,组合的特征集合得到了最好的结果,这说明,基于GLCM和多通道2D Gabor滤波器在特征提取上具有互补性,通过特征组合能够进一步提高虹膜识别精度。
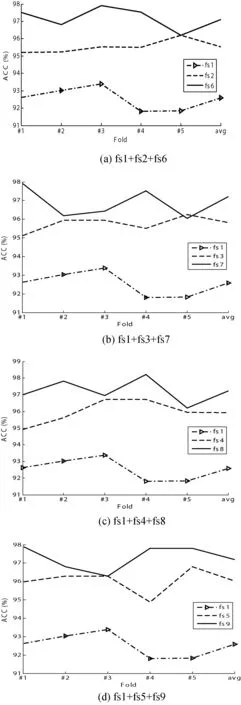
图8 基于GLMC特征子集、2DGabor滤波器特征子集和组合特征子集在ELM分类器上得到的识别精度比较
从图9可以看出,基于IABC-ELM分类模型在5折CV上的识别精度均高于ELM模型,其识别精度平均高了2%。图10给出了ELM和IABC-ELM模型均方差的结果比较,从结果可以看出,基于IABC-ELM的模型的均方差值较小,说明了本方法具有良好的稳定性。
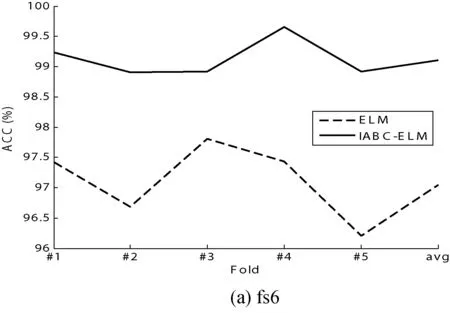
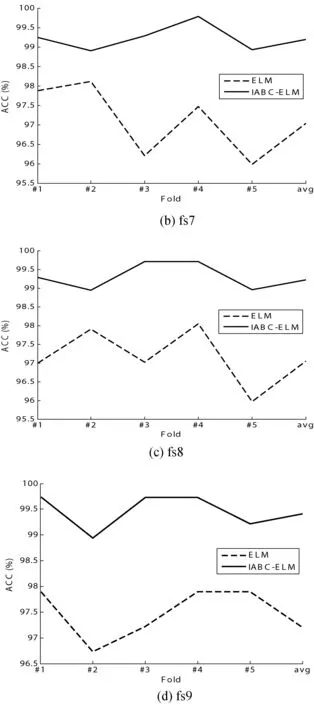
图9 基于IABC-ELM和Grid-ELM模型的识别精度比较结果

图10 不同特征集合在两种方法上得到的均方差值比较
另外为了验证提出的IABC算法的全局搜索能力和收敛速度,实验进一步对IABC算法的演化机制进行了研究,给出了IABC算法在虹膜数据集5折CV过程中某1折数据集上(选出的是第1折)最优适应度值的变化过程,如图11所示。注意到图中显示的是全局最优值的演化过程,将每一次迭代中所有解的最优适应度值记录下来。通过观察可以发现,IABC适应度曲线从第一次迭代一直到第80次迭代逐步演化,曲线在演化的初始阶段增长比较迅速,在第18次迭代时收敛到最高值,之后适应度值趋于平稳。该现象说明了提出的IABC算法具有很好的全局搜索能力和收敛速度,能迅速收敛到全局最优解,因此能够有效地实现了ELM模型参数的优化过程。

图11 IABC算法在第1折上训练数据的适应度值
由于采用ELM作为分类器,实验进一步分析ELM的隐层节点以及权重参数变化对分类性能的影响。图12给出的是随ELM隐层节点变化对虹膜识别精度的影响。由图可见,初始阶段随着隐层节点个数的增加,识别精度曲线呈显著上升趋势,当节点个数为7时,得到最大精度,然而随着节点数的继续增加,识别精度呈下降趋势。这是由于ELM隐层节点个数对分类精度有较大影响,当节点数过多时易造成ELM过拟合,降低了模型分类精度。因此本实验中取模型隐层节点数为7时分类性能最优。另外,从表4结果可见,在相同特征子集和相同隐层节点值条件下,每一折过程中基于ELM分类器所得的识别精度均低于IABC-ELM分类器,这说明ELM的权重参数对虹膜识别精度也具有重要影响。分析其原因是由于ELM会随机产生非最优或不必要的权重值和偏倚值,降低了算法的性能,造成取得的结果不稳定。而通过IABC优化ELM权重参数,能够找出最优的参数从而进一步提高模型的分类精度。

图12 模型分类精度随ELM隐层节点个数变化情况

foldfs6fs7fs8fs9fs6fs7fs8fs9ACC(%)(ELM)ACC(%)(IABC-ELM)#197.41797.78697.04897.78699.26299.26299.26299.631#296.67998.15597.78696.67998.89398.89398.89398.893#397.77896.29697.03796.29698.88999.25999.63099.630#497.40797.40798.14897.77899.63099.63099.63099.630#596.31095.94195.94197.78698.89398.89398.89399.262Avg97.11897.11797.19297.26599.11399.18799.26199.423Dev0.6030.9570.8480.7220.3300.3080.3680.330
此外,实验对基于ELM、IABC-ELM和SVM模型的训练时间、测试时间和准确率进行了比较,如表5所示。从表中可知,SVM模型计算效率最低,这是由于采用基于网格的方法需要大量训练时间,极大降低了计算效率。ELM模型所用时间最少,这是由于原始ELM算法随机产生权重参数且无需迭代调节,从而具有极快的训练速度和测试速度。而IABC-ELM的训练时间和测试时间稍多于ELM模型,分析其原因是由于采用IABC算法自适应迭代调节ELM模型权重参数,与ELM模型相比,虽然训练时间和测试时间分别增加了1.132 s和1.016 s,但使得虹膜识别的准确率提高了2.158%,因此在计算效率上是可接受的。
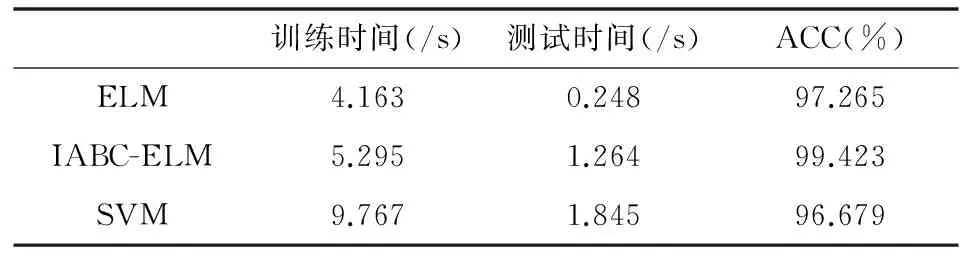
表5 三种模型的训练时间、测试时间及精度比较
6结语
虹膜识别作为身份认证的一种新技术,得到了人们广泛的关注和研究,一个更加精确、稳定的虹膜识别系统可极大地降低错误识别的风险。为此提出了基于特征融合的优化ELM虹膜识别模型。在该模型中,利用GLCM和多通道2D Gabor滤波器分别进行特征提取,之后将两组特征集合进行特征组合,得到了更丰富的虹膜信息,同时提出改进的ABC算法优化ELM分类模型,进一步提高了虹膜识别精度,设计了综合考虑分类精度和ELM网络隐层节点个数的线性加权多目标函数,在最大化精度的同时也精简了网络结构。通过实验,从特征提取和分类模型优化两方面,比较了该模型与ELM的分类准确率和均方差等性能指标。结果表明,与传统特征提取算法相比,本文提出的模型不仅能够得到更优的虹膜特征集合,而且其识别精度也得到极大的提高,获得了99.423%的识别精度,是一个有效的虹膜识别模型。
当然,该模型还存在许多值得进一步研究的地方。首先,采用的是基于ABC算法的优化模型,其他的优化算法在该数据集上是否具有更好的表现;其次,将本文模型用于其他虹膜识别数据库看其识别效果,是下一步的研究工作。
参考文献
[1] Zhenan Sun,Xianchao Qiu,Tieniu Tan.Toward Accurate and Fast Iris Segmentation for Iris Biometrics[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(9):1670-1684.
[2] Tieniu Tan,Zhaofeng He,Zhenan Sun.Efficient and robust segmentation of noisy iris images for non-cooperative iris recognition[J].Image and Vision Computing,2010,28(2):223-230.
[3] John G Daugman.Two-dimensional spectral analysis of cortical receptive field profiles[J].Vision Research,1980,20(10):847-856.
[4] John G Daugman.Statistical richness of visual phase information:Update on recognizing persons by iris patterns[J].International Journal of Computer Vision,2001,45(1):25-38.
[5] Monro D M,Rakshit S,Zhang D.DCT-based iris recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(4):586-595.
[6] Ma L,Tan T N,Wang Y H.Personal identification based on iris texture analysis[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2003,25(12):1519-1533.
[7] He X F,An S J,Shi P F.Statistical texture analysis-based approach for fake iris detection using support vector machines[J].Advances in biometrics,Lecture Notes in Computer Science,2007,46(2):540-546.
[8] John G Daugman.New methods in iris recognition[J].IEEE Transactions on System,Man,and Cybernetic,Part B:Cybernetics,2007,37(5):1167-1175.
[9] Roy K,Bhattacharya P.An iris recognition method based on zigzag collarette area and asymmetrical support vector machines[C]//IEEE International Conference on System,Man and Cybernetics,2006(1):861-865.
[10] 苑玮琦,林忠华,徐露.一种基于纹理特征点匹配的自适应虹膜识别方法[J].仪器仪表学报,2009,30(2):232-236.
[11] 苑玮琦,冯琪,柯丽.利用2D-Gabor滤波器提取纹理方向特征的虹膜识别方法[J].计算机应用研究,2009,26(8):3166-3168.
[12] Roy K,Bhattcharya P,Suen C Y.Towards nonideal iris recognition based on level set method,genetic algorithms and adaptive asymmetrical SVMs[J].Engineering Applications of Artificial Intelligence,2011,24(3):458-475.[13] Chapelle O,Vapnik V,Bousquet O.Choosing multiple parameters for support vector machines[J].Machine Learning,2002,46(1-3):131-159.
[14] Karaboga D,Basturk B.A powerful and efficient algorithm for numerical function optimization:artificial bee colony (ABC) algorithm[J].Journal of Global Optimization,2007,39(3):459-471.
[15] TsungJung H,WeiChang Y.Knowledge discovery employing grid scheme least squares support vector machines based on orthogonal design bee colony algorithm[J].IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2011,41(5):1198-1212.
[16] Gao W F,Liu S Y.A modified artificial bee colony algorithm[J].Computers & Operations Research,2012,39(3):687-697.
[17] Huang G B.Extreme Learning Machine for Regression and Multiclass Classification[J].IEEE Transactions on Systems,Man,and Cybernetics,Part B,2012,42(2):513-529.
[18] Huang G B,Ding X,Zhou H.Optimization method based extreme learning machine for classification[J].Neurocomputing,2010,74(3):155-163.
[19] Bovik A C,Clark M,Geisler W S.Multichannel texture analysis using localized spatial filters[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1990,12(1):55-73.
[20] Chen H L.A novel bankruptcy prediction model based on an adaptive fuzzy k-nearest neighbor method[J].Knowledge Based Systems,2011,24(8):1348-1359.
[21] Karaboga D,Görkemli B,Ozturk C.A comprehensive survey: artificial bee colony (ABC) algorithm and applications[J].Artificial Intelligence Review,2014,42(1):21-57.
收稿日期:2015-04-13。广东省科技厅项目(粤科规财字[2015]72号)。路春辉,讲师,主研领域:数据挖掘,计算机图像处理,模式识别。
中图分类号TP3
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.07.073
AN IRIS RECOGNITION SYSTEM BASED ON FEATURE FUSION AND OPTIMIZED EXTREME LEARNING MACHINE ALGORITHM
Lu Chunhui
(CollegeofInformationEngineering,GuangdongEngineeringPolytechnic,Guangzhou510520,Guangdong,China)
AbstractThe acquisition of iris image is easily affected by the uneven light and noise interference, thus, an optimized extreme learning machine (ELM) based on feature extraction is proposed to improve the accuracy of iris recognition. In the proposed model, considering both feature extraction and classifier selection play an important role, the gray level co-occurrence matrix (GLCM) and multi-channel 2D Gabor filters are used for separate feature extraction, and then two groups of feature sets are combined for achieving more information characteristics. Moreover, an improved artificial bee colony (IABC) is designed to conduct parameter optimization for ELM. Besides, a linear-weighted multi-objective function is designed to take into account the average accuracy rate and the number of ELM network hidden-layer nodes, which helps to improve the accuracy of model. Experimental results show that the proposed algorithm not only extracts more distinguished information by the combination of two feature extraction methods, but also obtains the highest accuracy, which proves the validity of the proposed model.
KeywordsFeature extractionIris recognitionGray level co-occurrence matrixMulti-channel 2D Gabor filtersExtreme learning machine
猜你喜欢
中国典型病例大全(2022年11期)2022-05-13 17:54:50
人民珠江(2019年4期)2019-04-20 02:32:00
电子制作(2018年19期)2018-11-14 02:37:08
文萃报·周二版(2018年51期)2018-08-04 06:05:18
自动化学报(2017年11期)2017-04-04 02:52:58
警察技术(2015年3期)2015-02-27 15:37:15
噪声与振动控制(2015年4期)2015-01-01 07:08:21
计算机工程(2014年9期)2014-06-06 10:46:47
机械工程与自动化(2014年3期)2014-05-07 12:49:22
电视技术(2014年19期)2014-03-11 15:38:23
