
基于Skip-gram模型的微博情感倾向性分析
2016-08-05 08:05:56李天彩毛二松席耀一
计算机应用与软件 2016年7期
李天彩 王 波 毛二松 席耀一
(解放军信息工程大学 河南 郑州 450002)
基于Skip-gram模型的微博情感倾向性分析
李天彩王波毛二松席耀一
(解放军信息工程大学河南 郑州 450002)
摘要为了更好地对微博进行表示,提高微博情感倾向性识别的准确度,提出一种基于Skip-gram模型的微博情感倾向性分析方法。首先,使用Skip-gram模型在中文数据上进行训练得到词向量;然后,利用词向量在词语表示上的优势,以及一定程度上满足加法组合运算的特性,通过向量相加获得微博的向量表示以及正负情感向量;最后,通过计算微博向量和正负情感向量的相似度判断微博的情感倾向。在NLP&CC2012数据上进行实验,结果表明,该方法能够有效识别微博的情感倾向,较传统的JST(Joint Sentiment/Topic model)和ASUM(Aspect and Sentiment Unication Model)平均F1值分别提高了23%和26%。
关键词微博情感分析Skip-gram模型词向量微博向量
0引言
微博的情感倾向性分析是指对微博消息所表示的情感进行识别,判断它的倾向性是正面还是负面。根据中国互联网信息中心CNNIC(China Internet Network Information Center)2014年7月发布的全国互联网发展统计报告[1]指出,我国网民规模达6.32亿,其中微博用户2.75亿,占整体网民的43.6%。虽然较2013年的微博用户的数量略有下降,但是微博的平台效应更加明显,内容更加丰富,网民参与微博上的讨论,发表意见和看法的活动也越来越频繁。因此,对微博中包含的情感进行分析,获得网民对热点事件的情感倾向对舆情监测、辅助决策等具有重要的意义。
目前,情感倾向性分析主要包括基于规则和基于统计两类方法。基于规则的方法一般是通过情感词典获取词的情感倾向性,然后通过句法规则对微博消息进行处理,最后通过加权计算获得微博消息的情感倾向性。2012年,冯时等人[2]提出了一种基于句法依存分析技术的博客文本情感倾向性分析算法SOAD(Sentiment Orientation Analysis Based on Syntactic Dependency)。通过分析句法依存树得到含有情感词的依存关系对,然后依据设定的规则计算博客文本的情感倾向性。2013年,Guo等人[3]改进了依存句法分析技术,并将其用于微博的分析。该方法在句法树中考虑了表情符号和标点符号的影响,通过句法树中词语到核心情感词的距离来计算词语的情感倾向。基于规则的方法需要对文本进行句法分析,但是微博消息一般比较简短,存在着大量的集外词,上下文存在交错,往往不具有标准的句法结构,这使得基于规则的方法适用性受到了限制。
基于统计的方法分为有监督的方法和无监督的方法[4]。其中,有监督的方法一般是通过有标注的训练数据提取特征并训练分类器,再对测试数据进行情感分析。2010年,Barbosa等人[5]利用已进行情感分类的Twitter数据作为训练数据,使用得到的特征信息对Twitter进行情感分类。2012年,谢丽星等人[6]使用了表情符号的规则方法、情感词典的规则方法和基于SVM的层次结构的多策略方法对微博的情感分析进行了深入细致的研究,并指出与英文微博相比中文微博语义更加丰富,主题更加多样。有监督的方法一般可以得到较高的准确度,但是其性能与训练数据的质量和数量有很大的关系。由于很难获得大规模高质量的人工标注数据,有监督方法的性能受到了限制;并且有监督的方法存在领域可移植性较差的不足,在一个领域数据上训练得到的模型移植到新的领域时性能会明显下降,需要在新的训练数据上重新进行训练。无监督的方法一般是通过对数据进行统计分析,通过概率模型计算微博中的情感分布,然后进行情感倾向性判断。2009年,Lin等人[7]提出了一种基于LDA(Latent Dirichlet Allocation)模型改进的模型,称为JST模型。JST模型在LDA模型的文档和主题之间加入了情感层,使其成为一个4层的概率模型,在采样过程中对每个词采样主题标签和情感标签,通过统计主题标签和情感标签的对应关系得到每个主题的情感分布。2011年,Jo等人[8]提出了ASUM模型。假设每个句子只有一个主题,在采样过程中对每个句子采样其主题标签和情感标签。2013年,Ding等人[9]提出了HDP-LDA(Hierarchical Dirichlet Process-Latent Dirichlet Allocation)模型。该模型利用了HDP模型可以自动确定主题个数的优势,挖掘短语级别的情感倾向,但是该方法需要通过词性标注识别短语对,短语识别的准确度会影响情感分析的结果,并且该模型中需要设定大量的参数,降低了其领域可移植性。基于主题模型的情感倾向性分析取得了较传统方法更准确的结果,但是从大量的实验和实践中发现,LDA模型、PLSA(Probabilistic Latent Semantic Analysis)模型等主题模型并不适用于大规模数据的训练和处理。该类模型中都需要假设数据服从指数分布,但是真实环境下的数据,尤其是互联网上的数据,服从的是长尾分布[10]。该类模型过于偏重从高频数据中归纳语义,忽视了对低频数据的处理,所以并不适用于描述长尾数据。
为了发挥无监督方法可移植性好的优势,同时结合微博数据量大,内容多样的特点,本文提出了一种基于Skip-gram模型的微博情感倾向性分析方法。Skip-gram模型是Mikolov等人[11]提出的一种可以在大规模数据集上进行训练的神经网络语言模型。本文使用Skip-gram模型在中文数据集上进行训练,得到词向量后,将其用于微博的情感倾向性分析。实验结果表明,本文提出的方法较传统的无监督的方法性能得到了有效提高。
1词向量
词向量的基本思想是将每个词映射成一个k维实数向量,一般取1000维以下。Mikolov等人[11]指出相比于传统的语言模型,基于神经网络语言模型[12]NNML(Neural Network Language Model)得到的词向量对词的表示更加准确。Mikolov等人[13]提出的Skip-gram模型是对现有模型的改进,它可以快速地完成对数十亿词的大规模数据的训练,得到的词向量在词语表示上更加准确。Skip-gram模型可以通过Hierarchical Softmax[14]和Negative Sampling[13]两种框架构造实现。本文使用的是基于Hierarchical Softmax构造的Skip-gram模型。
目前对词向量的研究主要是针对词聚类、同义词判断和词性分析等任务,主要是利用词向量对词语进行表示,通过向量计算词与词之间的相似程度。本文使用Mikolov等人[11]提出的Skip-gram(http://code.google.com/p/word2vec)模型在中文数据上进行训练,对得到的词向量进行实验发现,词向量在中文词语的表示上也表现出较好的性能。例如使用词向量计算“北京”、“和谐”、“奸商”和“贪污”这4个词语两两之间的相似度时,“北京”与“和谐”、“奸商”与“贪污”的相似度明显高于其他组合。
根据Mikolov等人[13]的研究,使用Skip-gram模型训练得到的词向量除了用来计算词与词之间的相似度之外,一定程度上还满足加法组合运算。Mikolov等人在文献[11,13]中都举了例子对这点进行说明:
vector(″Paris″)-vector(″France″)+vector(″Italy″)
≈vector(″Rome″)
(1)
vector(″King″)-vector(″Man″)+vector(″Woman″)
≈vector(″Queen″)
(2)
vector(″Russia″)+vector(″river″)≈vector(″Volga River″)
(3)
如式(1)、式(2)所示,“King”和“Man”的关系类似于“Queen”和“Woman”的关系,当使用“King”和“Woman”的词向量减去“Man”的词向量得到的结果非常接近于“Queen”的词向量。“Paris”、“France”、“Italy”和“Rome”也满足类似的关系。式(3)中“Russia”和“river”的词向量的和与“Volga River”很相近,这说明对词向量进行加法运算,得到的向量仍然是有意义的,而且其表示的语义与之前的词都是相关的。在中文数据上进行测试,也存在类似的关系:
vector(″中国″)-vector(″北京″)+vector(″华盛顿″)
≈vector(″美国″)
(4)
vector(″中国″)+vector(″男篮″)≈vector(″姚明″)
(5)
2微博情感倾向性分析
使用Skip-gram模型训练得到的词向量不仅在词语的表示上较传统的方法更加准确,而且能通过加法组合运算挖掘词与词之间的语义关系。本文根据这些特点提出了一种新的微博情感倾向性分析方法。
在微博的情感分析中,由于微博长度较短,包含的词语较少,使用向量空间模型进行表示时会出现严重的特征稀疏。而且在微博中常常会有网络语言和流行新词出现,基于知识库的方法受到更新速度的限制,一般无法及时收录这些词语或是更新已有词的新含义。因此本文方法中将微博表示成其包含词的词向量的集合,使用大量公开数据进行训练得到词向量用于挖掘词语之间的语义关系。
wbm={v(w1),v(w2),v(w3),…,v(wNm)}
(6)
其中wbm表示序号为m的微博消息,v(wi)表示wbm中第i个词的词向量,Nm表示wbm中词的个数。
Skip-gram模型训练得到的词向量一定程度上满足加法组合运算,将多个词的词向量进行相加得到的新向量仍然表示与这些词相关的语义。因此本文提出关于微博向量的假设如下:
假设一条微博消息所包含词的词向量进行相加得到的向量和仍然与这条微博的语义相关,并且可以反映其情感倾向。微博向量的计算式如下所示:
(7)
其中v(wbm)表示wbm中所有词的词向量相加并进行归一化之后得到的向量,本文将其称为微博向量。通过实验证明,这样的假设是符合真实情况的,例如式(8)、式(9)所示:
vector(″英雄″)+vector(″出″)+vector(″少年″)
≈vector(″英勇″)
(8)
vector(″中国″)+vector(″需要″)+vector(″这样″)+
vector(″人才″)≈vector(″真才实学″)
(9)
这两条微博都来自NLP&CC2012微博情感分析测试数据中“90后当教授”事件相关的微博中。从内容来看,两句都反映的是正面的情感,计算向量和之后得到的向量也与反映正面情感的词相近,这说明可以使用微博向量对微博消息进行表示。
本文还通过对情感词典中的正负情感词进行词向量相加定义了正面情感向量和负面情感向量的计算式如下:
(10)
(11)
其中,S+表示正面情感,S-表示负面情感,v(POS)和v(NEG)分别表示正面和负面情感向量。当对一条微博消息进行情感倾向性分析时,通过式(12)的判别函数进行判断。
(12)
(13)
(14)
其中,S0表示中性,sim(v(wbm),v(POS))表示微博向量与正面情感向量的余弦相似度,sim(v(wbm),v(NEG))表示微博向量与负面情感向量的余弦相似度,t是判断微博情感倾向的阈值。当sim(v(wbm),v(POS))>t时,说明wbm的情感与正面情感更相近,判断wbm属于正面微博;当sim(v(wbm),v(NEG))>t时,说明wbm的情感与负面情感更相近,判断wbm属于负面微博;当微博与正负情感向量的相似度都较小时,说明微博的正负倾向性都不明显,判断wbm是中性微博。
当只需要进行正负情感倾向性判断时,判别函数可以简化如下:
(15)
3实验与结果分析
3.1实验数据
实验的训练数据来源于“搜狗实验室”的“全网新闻数据”(http://www.sogou.com/labs/dl/ca.html),包含3.79亿个词。使用的情感词典是通过合并HowNet情感词典[15]、NTUSD词典[16]、学生褒贬词典[17]得到的。测试数据集来源于微博情感倾向性分析研究领域的通用数据NLP&&CC2012[18],包括20个话题,每个话题标注大约100条微博,共记2023条微博。其中包含正面情感倾向微博307条,负面情感倾向微博1406条,以及310条中立倾向的微博。由于现有研究很多都没有考虑中立倾向的微博,为了便于对比,本文实验只分析微博的正负面情感倾向性。
3.2评价方法
为了评价情感倾向性分析方法的性能,本文实验选取与NLP&&CC2012相同的评价方法,即准确率P(Precision)、召回率R(Recall)以及F1值:
(16)
(17)
(18)
其中,S表示情感倾向,S={S+,S-},PS、RS和FS分别表示在对情感倾向为S的类别进行评价的准确率、召回率和F1值。整体的情感倾向性的性能可以通过F1S值加权求和得到,公式如下:
(19)
其中,Favg表示正负面微博F1值的加权平均值,NS表示情感倾向为S的微博消息的数量。
3.3实验设置与结果分析
为了验证该方法的有效性,本文选取文献[7]提出的JST和文献[8]提出的ASUM进行对比实验,结果分别记为JST和ASUM;本文方法结果记为MBV(Micro-Blog Vector)。JST和ASUM按照文献[9]中的方法设置最优参数;MBV中Skip-gram模型的参数按照文献[11]中设置。设置以下2组实验:
(1) 综合性能对比实验
分别利用上述3种方法进行实验,评估其综合性能。其中,对JST、ASUM和MBV的结果取10次求平均作为其最终结果。其中,Ppos表示正面微博的准确率,Rpos表示正面微博的召回率,Fpos表示正面微博的F1值,Pneg表示负面微博的准确率,Rneg表示负面微博的召回率,Fneg表示负面微博的F1值,Favg表示正负面微博F1值的加权平均值。综合性能对比情况如表1所示。

表1 不同方法的综合性能对比实验
由表1可以看出,三种方法结果中MBV的Favg值为0.840,明显高于JST的0.607和ASUM的0.574,而且MBV在正面微博和负面微博的情感倾向性分析中也都显示了明显的优势。三种方法的Fpos都较低,这是因为实验数据不平衡,负面倾向的微博有1406条,远多于正面倾向的微博,将负面微博误判为正面微博的数量更多,造成正面微博的准确率相对较低。除此之外,因为JST和ASUM都是基于主题模型的方法,当实验数据中正负面情感的微博数量不平衡时,通过主题模型得到的主题中包含负面情感词的概率较大,将微博判断为负面的概率也随之增大,这进一步导致JST和ASUM的Rpos较低。与此同时,这种情感判断的倾向性会使得JST和ASUM的Pneg较高,但是Rneg较低,Fneg也相对较低。ASUM的Fpos高于JST,这是因为ASUM假设数据中正负面微博比例相当,导致相当一部分负面微博误识别为正面微博,使得Rpos较高,从而导致Fpos偏高,但是ASUM的这种假设会导致Fneg相应偏小,整体性能低于JST。MBV中以词语的词向量表示为基础,训练过程中不需要对训练数据中正负面内容的比例进行规定。除此之外,通过情感词的词向量计算情感向量作为对正负面情感的表示也可以避免情感词典不平衡和不完整对情感分析的影响。总的来说,MBV使用微博向量对微博包含的语义信息进行表示。通过计算微博向量与正负面情感的语义相似度进行情感倾向性判断,更符合对人类认知内容的过程,实验结果也表明该方法明显优于JST和ASUM。
本文提出的方法是在大规模无标注的训练数据上进行训练,具有良好的领域可移植性。为了验证本文提出的方法在单个微博事件的情感倾向性分析中的性能,本文对实验中使用的20个事件的情感倾向性分析结果进行了单独计算,得到的结果如表2所示。

表2 单个微博事件情感倾向性分析
从表2中可以看出,“皮鞋果冻”、“疯狂的大葱”、“名古屋市长否认南京大屠杀”等事件对应的Favg高于其他事件,这是因为与这些事件相关的微博中大部分都是表示谴责和批评,使用了较多具有强烈的负面情感倾向的词,使微博向量明显的倾向于负面情感向量。而在“苹果封杀360”、“国旗下讨伐教育制度”等事件中,有较多的微博包含了支持一方反对另一方的内容,如“他的勇气实在令人佩服,这个社会就是黑暗的”等。由于本文的方法将微博内容看成词袋,无法区分评论的对象,当包含多个对象多种情感时该方法的准确性降低。总体来说,本文提出的方法在大多数属于不同领域的单个事件的情感倾向性分析中都取得了较好的结果,说明本文的方法具有良好的领域可移植性。
(2) 平衡数据上的对比实验
实验(1)中,由于实验数据中正负情感倾向的微博数量差别较大,数据存在不平衡。为了增强实验对比的可靠性,本文从实验数据中分别选取正负面微博各307条构建了一份平衡数据用于进行对比实验,结果如图1所示。
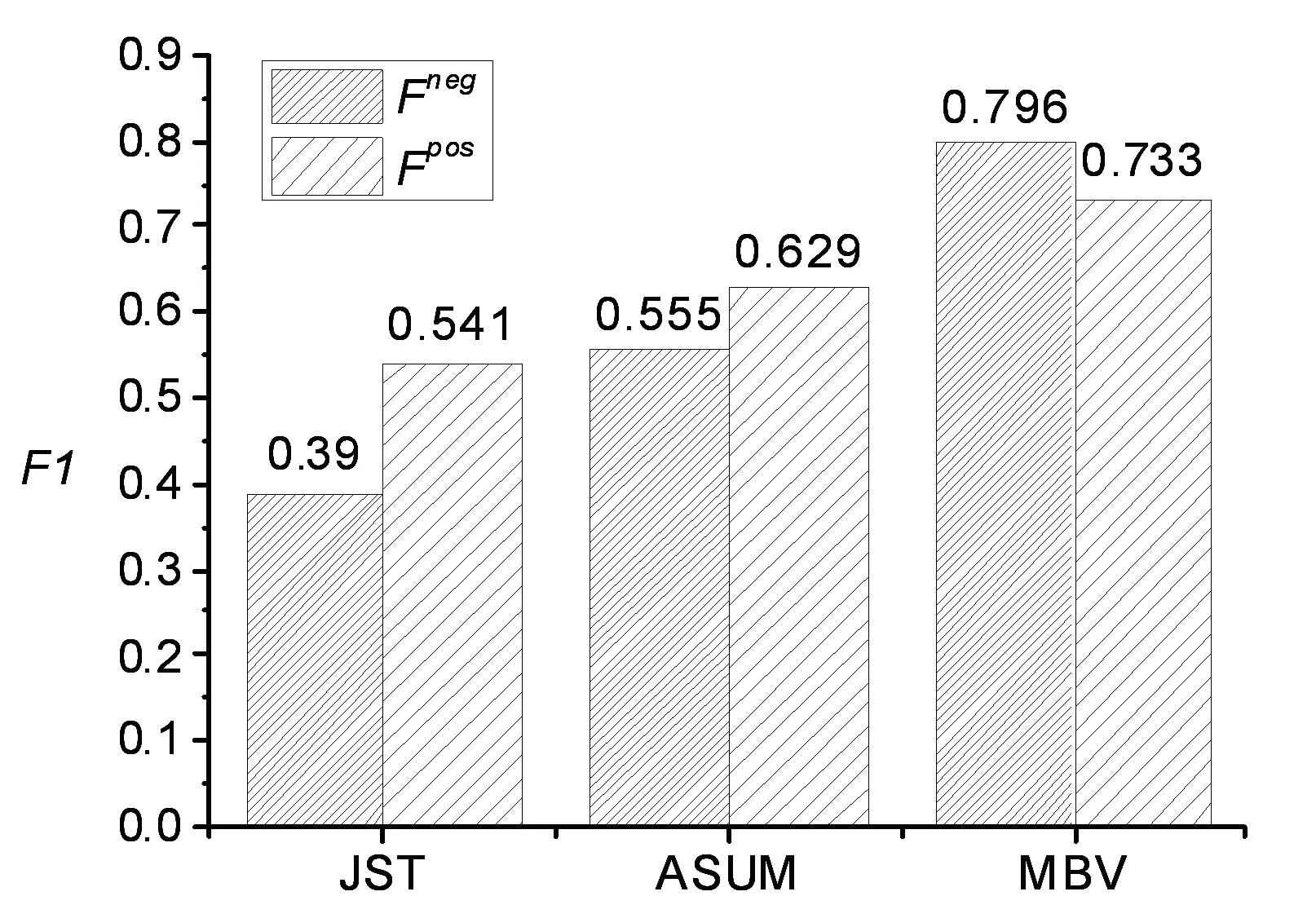
图1 平衡数据对比实验结果
由图1可以看到,在平衡数据上进行实验,MBV的Fpos和Fneg均明显高于JST和ASUM。三种方法的Fpos都高于实验(1)的结果,这是因为负面微博被错判为正面微博的数量减少,使Ppos得以提高,进而提高了Fpos。JST和ASUM的Fneg都低于实验(1)中的结果,这符合之前的结果分析。除此之外,ASUM在平衡语料上的结果优于JST,这是因为平衡语料符合ASUM正负面微博比例相当的假设,ASUM表现更好。MBV对每条微博计算一个微博向量作为其表示,与正负面情感向量计算语义相似度进行情感倾向性判断。不同微博计算微博向量表示和进行情感倾向性判断的过程是相互独立的,因此不会受到待测数据中正负面内容的比例不同的影响。综合实验(1)和实验(2)的结果,本文的方法具有良好的领域可移植性,在非平衡数据还是平衡数据上,性能均优于传统方法,这充分证明了本文方法的有效性和优越性。
4结语
本文利用Skip-gram模型在中文数据上进行训练,利用词向量在词语表示上的优势,以及在一定程度上满足加法组合运算的特性,提出了一种使用微博向量对微博进行表示,并将其用于微博情感倾向性分析的方法。通过在非平衡数据和平衡数据上分别进行实验,证明了本文提出的方法较传统的JST模型和ASUM模型性能上有了很大的提高,并且具有良好的领域可移植性。本文的方法中是使用微博向量对一条微博进行表示,该方法同样可以适用于其他句子级的情感倾向性分析任务中。除此之外,Skip-gram模型对词语表示的准确度可以通过扩大训练数据的规模和领域范围进行提高,所以本文方法的性能还有进一步提高的空间。
本文的方法中还存在一些不足,主要包括以下两个方面的问题:首先是没有对微博中用词不规范的情况进行处理,在微博中经常会出现错别字、散光字、火星文等,如“老白姓”、“弓虽”等,当微博内容较短时会影响结果;其次是本文虽然取得了较好的结果,但是构造微博向量的方法较为简单,没有考虑词语的前后顺序及否定词的影响。在下一步工作中,如何解决这两个问题,将是研究的重要方向。
参考文献
[1] 中国互联网络发展状况统计报告(2014年7月)[R].北京:中国互联网信息中心,2014.
[2] 冯时,付永陈,阳锋,等.基于依存句法的博文情感倾向性分析研究[J].计算机研究与发展,2012,49(11):2395-2406.
[3] Fuliang Guo,Gang Zhou.Research on micro-blog sentiment orientation analysis based on improved dependency parsing[C]//Proceedings of the 2013 3rd International Conference on Consumer Electronics,Communications and Networks,Xianning,China,2013:546-550.
[4] Bing Liu,Lei Zhang.A survey of opinion mining and sentiment analysis[M].New York:Springer US,2012:415-463.
[5] Barbosa L,Junlan Feng.Robust sentiment detection on twitter from biased and noisy data[C]//Proceedings of the 23rd International Conference on Computational Linguistics,Uppsala,Sweden,2010:36-44.
[6] 谢丽星,周明,孙茂松.基于层次结构的多策略中文微博情感分析和特征抽取[J].中文信息学报,2012,26(1):73-83.
[7] Chenghua Lin,Yulan He.Joint sentiment topic model for sentiment analysis[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management Hong Kong,China,2009:375-384.
[8] Jo Yohan,Oh Alice.Aspect and Sentiment Unification Model for Online Review Analysis[C]//Proc. of the fourth ACM international conference on Web search and data mining,2011:815-824.
[9] Wanying Ding,Xiaoli Song,Lifan Guo.A novel hybrid HDP-LDA model for sentiment analysis[C]//Proceedings of the 2013 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technology,Atlanta,USA,2013,1(1):329-336.
[10] Kevin P Murphy.Machine Learning-A Probabilistic Perspective[M].Cambridge,Massachusetts London,England: The MIT Press,2012:2-3.
[11] Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[C]//International Conference on Learning Representations,2013.
[12] Yoshua B,Rejean D,Pascal V,et al.A neural probabilistic language model[J].The Journal of Machine Learning Research,2003,3(6):1137-1155.
[13] Mikolov T,Sutskever I,Chen K,et al.Distributed Representations of Words and Phrases and their Compositionality[C]//Neural Information Procesing Systems Foundation,2013.
[14] Frederic M,Yoshua B.Hierarchical probabilistic neural network language model[C]//Proceedings of the international workshop on artificial intelligence and statistics,2005.
[15] 董振东,董强.HowNet情感词典[EB/OL].[2013-07-28].http://www.keenage.com.
[16] Ku Lunwei,Lo Yongsheng,Chen Hsinhsi.Using Polarity Scores of Words for Sentence-level Opinion Extraction[C]//Proc.of NTCIR-6 workshop meeting,2007:316-322.
[17] 张伟,刘缙,郭先珍.学生褒贬义词典[M].北京:中国大百科全书出版社,2004.
[18] 中国计算机学会.微博情感分析评测数据[EB/OL].[2012-09-12].http://tcci.ccf.org.cn/conference/2012/.
收稿日期:2014-12-13。李天彩,硕士生,主研领域:情感分析,会话抽取。王波,副教授。毛二松,硕士生。席耀一,博士生。
中图分类号TP391.4
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.07.027
ANALYSING MICROBLOGGING SENTIMENT ORIENTATION BASED ON SKIP-GRAM MODEL
Li TiancaiWang BoMao ErsongXi Yaoyi
(ThePLAInformationEngineeringUniversity,Zhengzhou450002,Henan,China)
AbstractIn order to represent microblogs better and to improve the accuracy of microblogging sentiment orientation identification, we presented a Skip-gram model-based microblogging sentiment orientation analysis method. First, we used Skip-gram model in training on Chinese dataset to get word vector; then, we took use of the advantage of word vector on word representation and its feature of satisfying in certain extent the addition combinational operation to obtain the vector representation of microblogs and the positive and negative sentiment vectors by vectors addition; finally, we determined the microblogging sentiment orientation by computing the similarity between microblogging vectors and positive and negative sentiment vectors. Experiment was carried out on NLP&CC2012 data, the results showed that our method could effectively identify the sentiment orientation of microblogs, and improved the average F1-measure by 23% and 26% respectively compared with traditional JST and ASUM.
KeywordsMicrobloggingSentiment analysisSkip-gram modelWord vectorMicroblogging vector
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:42
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
能源(2018年8期)2018-09-21 07:57:22
知识经济·中国直销(2018年6期)2018-06-29 07:55:52
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新闻研究导刊(2015年17期)2015-12-25 12:36:42
新高考·高二数学(2015年11期)2015-12-23 18:17:44
语言与翻译(2015年4期)2015-07-18 11:07:43
中央民族大学学报(自然科学版)(2014年3期)2014-06-09 08:54:32
