
基于数据挖掘技术的研究生信息库数据的研究及应用
2016-08-05 03:19李门楼
中国管理信息化 2016年11期
李门楼,郭 嘉
(中国地质大学 研究生院,武汉 430074)
基于数据挖掘技术的研究生信息库数据的研究及应用
李门楼,郭嘉
(中国地质大学研究生院,武汉 430074)
论文结合D大学研究生信息与管理系统应用的实际情况和迫切需求,针对“海量数据信息严重浪费,亟待挖掘其潜在有用信息”这一现实问题,对D大学研究生信息与管理系统多年来积累的信息数据进行深入研究与探讨,运用数据挖掘原理,对研究生选课数据、研究生科研及成绩数据、研究生毕业单位信息数据进行有效挖掘,以期得到所隐藏的有价值信息,从而指导教学管理和学生的学习方向,继而提高教学管理水平和研究生培养质量,更好更有效地为研究生的成长和发展服务。
管理信息系统;关联规则;决策树;Apriori;C4.5
1 引言
数据挖掘,简单的说,就是从大量数据中提取或者“挖掘”有用的知识,是指利用特定的算法从数据库中提取或者挖掘出潜在的、未被人知的有应用价值的信息。从学校教育角度来说,它是教育信息化建设的发展带来的产物,是新的信息数据处理技术,其功能和任务是对教育机构的信息数据库进行潜在信息数据的抽取、转化、模型化处理、结果分析等,从中获得有助于教育决策的潜在信息。但目前大部分学校都存在一个普遍的问题:学校多年来积累了海量的数据,可是其中所隐藏有价值的信息,却知之甚少,所以从教育的角度出发,需要把这些隐藏信息从中挖掘出来,使它们经深层次的挖掘和分析,为教育决策提供更多的有价值信息。
2 数据挖掘方法概要
数据挖掘是从大量的数据中挖掘有价值信息的一个过程,有时候又称为知识发现(Knowledge Discovery in Database)。本文借鉴研究常见的两种方法。
2.1关联规则
关联规则是反映一个事物与其他事物之间的相互依存性和关联性。如果两个或者多个事物之间存在一定的关联关系,那么,其中一个事物就能够通过其他事物预测到。关联规则表示了项之间的关系。典型算法是Aprior算法。
2.2决策树方法
决策树方法是建立在信息论基础上的一种对数据进行分类的方法。决策树一般都是自上而下的来生成的。任意一个结点的状态(即代表决策或者事件)都有可能产生两个或者多个状态(决策或者事件),并最终发展成为各不相同的结果。把决策的分支表示成为图形,这个图形看起来很像一棵倒立的树。典型算法是C4.5算法。
3 关联规则在研究生信息库中的研究及应用
3.1数据筛选
本次研究实验所选取的是D大学09级研究生的英语成绩数据,利用数据库技术将多个数据表进行整合,合并成研究所需要的一个成绩数据。
首先:运用Sql数据库中的视图技术,从研究生成绩库、学籍库和课程库中选取所需字段(课程名称kcbmc、学号xh、成绩cj、姓名name),抽取900条数据生成09级研究生的英语听力、英语口语、英语阅读三门课程的成绩数据视图。
其次,对以上三张数据表进行表的连接,生成一张成绩数据分析表(apriori_data_09硕士英语),这个数据表只包含学号(xh)、口语(ky)、听力(tl)、阅读(yd)四个数据字段。
对于缺考或无效的学生成绩给予去除处理。
3.2数据转换
把待挖掘数据表中数据字段的格式转换为逻辑布尔型(真和假),将数据字段中成绩大于等于80分的字段设置为“真”,即在数据中显示;反之设置为“假”,在数据中不显示。例如:某项中英语口语/听力/阅读成绩字段中的值如果大于等于80,则该项中会出现“1”/“2”/“3”,反之,则为空。
3.3 Apriori算法应用
实验所用的数据是09级研究生成绩库中的英语听力、阅读、口语三门课程的成绩数据,经过上述选择和筛选,生成了Apriori算法程序中所用到的待挖掘分析数据表apriori_data文件,如表1所示。
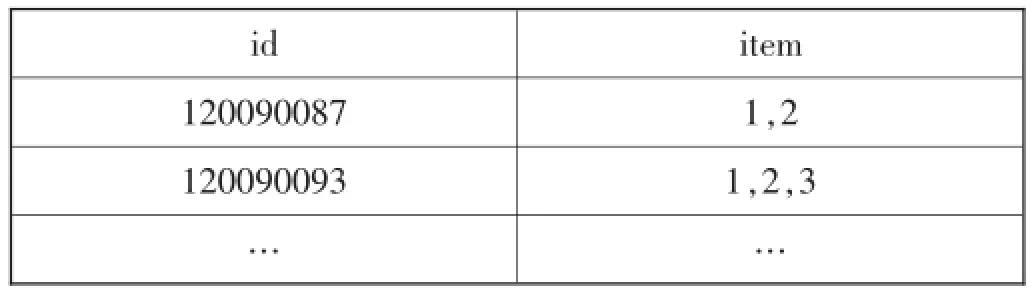
表1 apriori_data数据表
对上述apriori_data数据表中891条记录事务集,设置其最小支持度为 0.2,置信度为 0.5,应用 Apriori算法程序对apriori_data数据表中的听力、口语、阅读成绩进行关联规则数据挖掘,如图1所示。

图1关联规则数据挖掘
结果如图2所示。
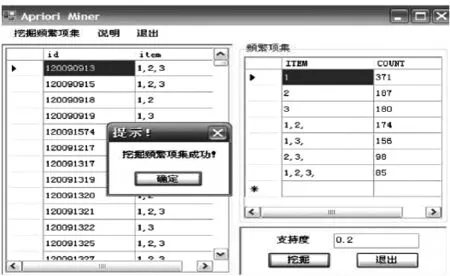
图2挖掘分析结果
频繁项集I={英语口语成绩,听力成绩,阅读成绩}= {1,2,3}的非空子集有{1,2},{1,3},{2,3},{1},{2}和{3}。由I产生的关联规则及其置信度如下:

找出满足最小置信度阈值50%的规则,最终产生的强关联规则如下:
A.当1良好,2、3同时良好的可能性大于86.7%。即:当英语口语成绩良好(达到80分以上)时,英语听力和阅读同时良好(达到80分以上)的可能性大于86.7%。
B.当2良好,1、3同时良好的可能性大于54.5%。即:当英语听力成绩良好(达到80分以上)时,英语口语和阅读同时良好(达到80分以上)的可能性大于54.5%。
从上述挖掘结果来看,可以得到一些潜在的关联:强关联规则A说明英语口语对英语听力和阅读两门课程成绩有重大影响,也就是说口语能力不强的学生,英语听力和阅读相对会差一些。这一点就给出了我们一个信号,即在开设英语课程中,要着重考虑安排英语口语课程的课时多些,这样可以无形中带动学生英语听力和阅读的能力提高。同理,根据上面的强关联规则B可以得到如下潜在信息,即说明英语听力对英语口语和阅读两门课程成绩有重大影响,也就是说听力能力不强的学生,英语口语和阅读相对会差一些,这就给出了一个信号,即在开设英语课程中,要着重考虑安排英语听力课程的课时多些,这样可以无形中带动学生英语口语和阅读的能力提高。
4 应用C4 .5 算法决策树技术挖掘研究生信息数据库
4.1建立模型
挖掘内容确定为:学生基本信息、成绩信息、家庭背景信息、科研成果信息、就业情况信息五个方面。主要字段分别为如下几类。学生基本信息包括:学号、性别、政治面貌。家庭背景信息主要包括家庭基本情况一项信息,即分为两类:一类是农民、下岗工人;二类是公务员、工人、职工、商人等。学生成绩信息包括:学业成绩绩点、英语专业水平。科研成果信息包括:助研情况、论文发表情况。就业信息包括:就业单位性质。
4.2数据提取及离散归约化
4.2.1提取
挖掘信息需要从信息系统多个模块中提取整理,分别从如下数据库中提取:
英语水平(视图 lunwen_cet表)、助研情况(视图lunwen_zhuyan表)、论文发表情况(lunwen_publish表)、学业成绩(lunwen_cj表)、家庭情况(lunwen_family表)、学生基本信息(users表)、就业单位信息(lunwen_jyxx表)。
4.2.2处理
为了便于挖掘还需对挖掘字段进行一些必要的处理过程,即要对各属性字段进行归约与离散化处理。处理规则如下表2所示。

表2对挖掘字段的处理规则
按照上述标准对原始记录处理后,得到如下表3所示。

表3原始记录数据处理结果
4.3结果分析
对以上得出的挖掘数据结果分析,可以得出各因素所在的Variable Importance比例分别是:CET:0.436、XB:0.298、CJ:0.153、PAPER:0.054、ZZMM:0.025、FAMILY:0.022、ZHUYAN:0.012,从这些数据可以得出如下结论:
(1)在对就业单位性质JYDWXZ有影响的八大因素:英语水平CET、性别XB、学业成绩绩点CJ、论文发表情况PAPER、政治面貌ZZMM、家庭情况FAMILY、助研情况ZHUYAN中,其中英语水平CET是就业单位性质JYDWXZ的最主要的影响因素;其次是性别XB因素;再其次依次是成绩CJ因素、发表论文情况PAPER因素、政治面貌ZZMM因素、家庭情况FAMILY因素,最后是助研统计情况ZHUYAN因素。
(2)从就业的角度考虑,那么发表论文情况PAPER因素便显得影响很小,起不到决定的因素作用,所以各高校近年相继做出了“取消以发表论文作为硕士研究生毕业条件”的决定,本研究从理论和数据上证明了这一决定的重要性。
(3)英语水平CET在影响就业单位性质JYDWXZ中仍然占主导作用,说明加强英语水平的训练,对于当代研究生的教育培养仍然是一项重中之重的任务。
(4)从得出的结果可以看出,性别XB因素在就业中仍然占有比较大的分量,虽然国家颁发了很多关于在就业过程中严禁性别歧视的规定,可在实际的招聘过程中仍然存在性别歧视的现象。
5 结语
本文中运用关联规则方法对学生成绩库进行挖掘作业,找到课程之间存在的潜在联系,为今后合理设置课程安排提供有效的数据支撑;同时运用决策树技术对学生就业、学籍、成绩、科研数据信息库进行挖掘作业,总结影响学生就业的关键因素,分析其原因,为培养适应社会发展需要的高学历人才制定更加合理的培养方案提供决策支持。
主要参考文献
[1]李门楼,郭嘉.研究生教育管理信息化的实践与思考[J].研究生教育研究,2011(3).
[2]廖芹,赫志峰,陈志宏.数据挖掘与数学建模[M].北京:国防工业出版社,2010.
[3][加]Jiawei Han,Micheline Kamber.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2007.
[3]李婷,傅钢善.国内外教育数据挖掘研究现状及趋势分析[J].现代教育技术,2010(10).
10.3969/j.issn.1673-0194.2016.11.099
C37
A
1673-0194(2016)11-0164-04
2016-04-08
猜你喜欢
疯狂英语·初中天地(2022年2期)2022-07-07
疯狂英语·初中版(2022年2期)2022-05-04
疯狂英语·初中版(2022年4期)2022-04-11
疯狂英语·初中版(2022年1期)2022-01-26
党员生活(2020年2期)2020-04-17
铁道通信信号(2018年10期)2018-12-06
疯狂英语·新策略(2017年7期)2018-01-03
疯狂英语·新策略(2017年8期)2017-05-31
当代教育实践与教学研究(2015年2期)2015-02-27
中国石油企业(2014年4期)2014-11-30
