
基于数据挖掘的火电厂设备状态检修研究
2016-08-04 18:06赵龙
大科技 2016年20期
赵龙
(安徽皖能电力运营检修有限公司 安徽合肥 230000)
基于数据挖掘的火电厂设备状态检修研究
赵龙
(安徽皖能电力运营检修有限公司 安徽合肥 230000)
设备状态检修管理关系着火电厂的高效平稳运行,是火电厂安全生产的关键环节,同时设备状态的好坏决定了发电企业的长久安全运行,对企业的效益也会有很大的影响。随着新兴技术的发展,数据挖掘技术能够被用来对火电厂的发展趋势做出可能的预测,提供有效的决策来对设备状态进行检测。本文着重研究了数据挖掘技术和电厂设备状态检修工作,并分析了利用支持向量机技术在设备故障诊断中的应用。
设备状态检修;数据挖据技术;支持向量机
引言
火力发电厂作为电力行业的主流军,在大力发展火电技术的同时对于设备状态的检修管理是发电厂安全运行的重中之重。良好的设备状态检修可以在设备运行中节能降耗、提高生产效率、减少安全事故的发生。但由于设备结构复杂,占地空间比较大,同时设备检修项目的逐渐增多,传统的检修方式难以高效准确的进行检修。在设备状态检修中关键是进行状态监测以及故障诊断,近年来新兴的数据挖掘技术在结合了计算智能、模式识别以及数据库和统计规律等相关技术,通过对数据进行分类和处理分析等,进而挖掘出隐藏的有价值的信息。将数据挖据技术应用在设备状态检修方面,能够高效快捷的对设备进行故障诊断处理,对于火电厂的经济和社会效益都带来了巨大的提升。
1 数据挖掘技术
数据挖掘是指从大量不完全的,有噪声的或模糊随机的数据中,提取隐含的有用的人们事先不知道的而又潜在有用的知识的过程[1]。数据挖掘的功能在不同的领域有不同的表达方式,如图1概括了数据挖掘的主要功能。

图1 数据挖掘的功能概图
1.1 数据挖掘的过程
数据挖据即是一种知识的发现过程,多用于在数据库、数据分析以及统计规律等方面的应用。数据挖掘在数据处理的过程中大致可分为数据的准备阶段、数据挖掘阶段以及结果分析阶段。其具体的挖掘过程如图2所示。

图2 数据挖掘的基本过程和主要步骤
数据选取是为了选择适用于数据挖掘运用中的从数据库中选择和提取的某些有用数据;数据预处理即是在消除噪声和不匹配的数据以及清楚数据集成的基础之上,可以有效的保证选取的数据质量,使得数据挖掘过程更加高效简便,提升了数据挖掘结果的可靠性;数据变换有效的降低了数据维数,缩减了挖掘过程中数据信息的特征和变量数,节省了数据分析的时间。数据挖掘阶段在确定挖掘的任务和目的之后,选择合适的挖掘算法对解决的实际问题进行处理,使得得到的分析结果具有一定的稳健性。数据结果分析阶段即是对数据挖掘得到的结果进行评估和阐释,通过适当的方法将评估结果进行汇总,进而给出对于实际问题的决策方案。
1.2 支持向量机
随着各种机器算法的不断成熟,人工智能技术也在随之不断提升。支持向量机(Support Vector Machine)是Vaonik等人提出的一种新的通用学习方法[2],其根据统计学规律,建立在理论的VC维理论和结构风险最小院里的基础上,目前仍在理论研究发展阶段。SVM在已非线性映射为理论基础的背景下,能够解决诸如小样本、局部极小点和高维数等一些实际遇到的问题。同时SVM方法在用于解决问题的过程中,有很好的“鲁棒”性,降低了计算难度,简化了算法的复杂性。如图3所示,给出了支持向量机的网络结构图,判别函数形式上输出M个中间结点的线性组合,类似于一个神经网络,每个中间结点对应一个支持向量。同时SVM可以进行实时的线上监测,使得其在用做故障诊断时能够被用在小样本决策方面,这是其在设备故障诊断的应用中的很大优势。
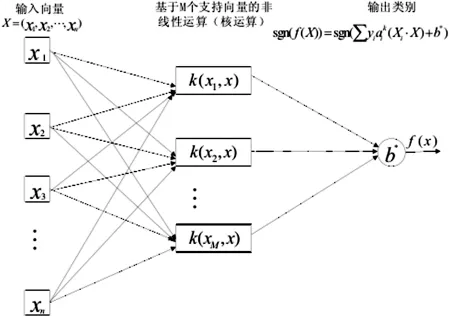
图3 支持向量机网络结构图
2 支持向量机在汽轮机故障诊断中应用
汽轮机是火力发电中的重要设备,其产生故障时通常会发出噪声或异响,其故障发生主要集中在:轮子不对中、旋转机械中轮子质量不平衡、转轴振动过大产生摩擦以及零部件松动等。通过在故障状态下检测汽轮机组的振动信号的幅度特征等,来确定故障发生的具体原因,对于发电厂的安全运行具有重要的参考价值。
在应用向量机进行汽轮机组的故障诊断过程中,需对数据进行深入挖掘才能获取到比较有用的潜在信息,具体步骤如下:
(1)在火力发电厂的信息中心数据库收集关于汽轮机组的相关故障信息;
(2)对数据进行预处理,进行归一化操作,清除无用数据,建立属性决策表;
(3)通过相关数据挖掘算法,对采样数据进行选择得到最简属性集;
(4)建立SVM多分类器,对相关参数寻优,训练SVM分类器并测试;
(5)对分析结果进行评估。
首先,通过对火电厂数据库中采集到的30组数据信息进处理,去掉缺失的数据等,通过对预处理的数据进行归一化操作,得到如图4所示的初始属性决策表。
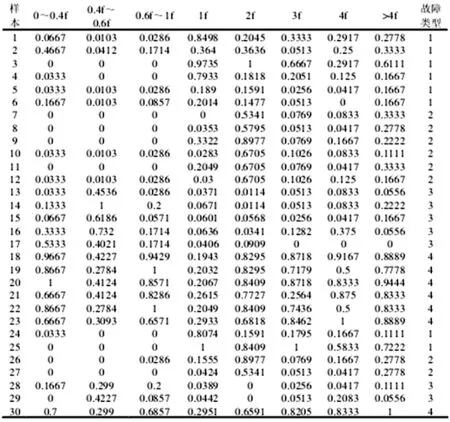
图4 初始属性决策表
在对数据进行特征选择时,采用最值聚类算法,结合关联分析方法,求出各属性的相关系数rA,B,在用于比较的情况下一般评定变量相关性强弱标准的取值范围如:0.0-0.2为几乎无关;0.2~0.3为弱相关;0.3~0.5为中等相关;0.5~0.8为较强相关;0.8~1.0为强相关。设定阈值T为0.45。结合聚类算法,选择一组频段值Xn作为第一聚类中心,然后将与第一聚类中心关联度最低的作为第二聚类中心,以此计算各频段值并确定全部聚类中心之间的相关性,确定相关系数。在构造SVM多类分类器时,为了得到良好的分类效果,可以采取一对一的多类分类方法,此方法避免了分类中两个属性间样本数据差距过大造成的分类偏移等问题,大大减低了误判率。采用一对一的多类分类法时,将收集到的30组数据分成两部分,一部分用来做训练,一部分用来做测试,建立6个多分类模型。根据以上分类后,来建立PSO-SVM分类器[3],其参数优化步骤主要包括:初始化粒子群速度调节参数C1,C2和惯性权重w,以及最大进化迭代次数;根据初始化的的位置和速度得到新的参数信息,调用算法进行SVM的学习和分类训练;计算各粒子适应度;对比各粒子,找出其经过最佳位置时的适应度取值,找出其自身适应度的取值,并比对将更好地适应度值进行更新;比较各粒子适应度值和群体粒子的最佳位置适应度值,并更新群体经历最佳位置时的适应度值;若满足最佳位置或最大迭代数,则返回最优惩罚系数和和函数宽度,进而得到PSO-SVM分类器。如图5所示,给出了在初始化速度调节参数C1=1.5,C2=1.7时的参数优化图。由图可知最佳适应度大部分集中在坐标100处,可以作出判断即最佳分类达到了100%。
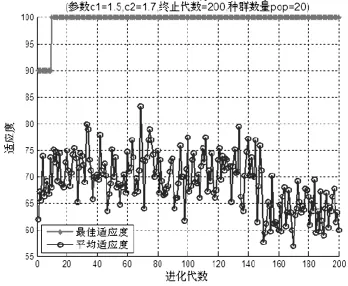
图5 PSO-SVM参数优化效果图
在对SVM参数优化选取进行评估时,当采取网格搜索和交叉验证的方法进行寻优,在进行反复试验之后,得到的最小参数范围变化始终不大。本文在进行汽轮机组故障诊断的过程中,采用了最值聚类算法和相关分析的方法相结合,从实际应用角度来讲,能够更加满足样本的代表性,在对数据样本进行处理的过程中能够降低数据维数,这样做可以极大的简化聚类算法的复杂性并且降低了相关分析方法的难度。使得SVM分类更加容易实现并且得到更加显著的分类效果。同时,在用于设备故障诊断的过程中,主要是解决了小样本的学习问题。汽轮组设备的故障诊断好坏很大程度上决定了火电厂能够安全的运行,鉴于支持向量机方法能够很好的进行小样本学习,因此在用作汽轮组故障诊断时,使得对于处理故障数据更加的灵活,也使得得到的故障样本数据更加具备代表性,为后期分析故障原因提供了有价值的数据信息等。利用粒子群优化方法,避免了支持向量机的过学习,在提高分类的准确性的基础上可以寻找最有参数,使得在对设备进行故障分析时,能够更加快速、高效的得到准确的诊断方法,更加方便的应用在工业设备的故障诊断方面。
3 结语
在电厂设备中,对汽轮机组故障的诊断至关重要。由于支持向量机可以很好的适用于小样本学习,本文采用支持向量机方法对汽轮机故障进行诊断。分别从特征选择和参数优化来分析研究,将数据挖掘技术用于电厂设备状态检修管理具有一定的理论和现实意义,可以为电厂带来巨大的经济效益和社会效益。
[1]郭海涛,段礼祥,等.数据挖掘方法综述[J].计算机科学,2009,36(4B):323~326.
[2]顾亚祥,丁世飞.支持向量机研究进展[J].计算机科学,2011,38(2):14~16.
[3]姚全珠,蔡婕.基于PSO的LS-SVM特征选择与参数优化算法[J].计算机工程与应用,2010,46(1):134~136.
TM621
A
1004-7344(2016)20-0086-02
2016-7-1
猜你喜欢
计算机仿真(2022年8期)2022-09-28
一重技术(2021年5期)2022-01-18
大众投资指南(2021年35期)2021-02-16
郑州大学学报(工学版)(2018年2期)2018-04-13
电力与能源(2017年6期)2017-05-14
中国塑料(2016年11期)2016-04-16
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
信息通信技术(2015年6期)2015-12-26
振动、测试与诊断(2014年5期)2014-03-01
河南科技(2014年3期)2014-02-27
