
一种新的10GBASE-KR物理编码子层的变速箱设计
2016-08-04 02:07杨灿美林福江
网络安全与数据管理 2016年13期
关键词:变速箱
张 琴,杨 莹,杨灿美,林福江
(1.中国科学技术大学 信息科学技术学院,安徽 合肥 230027;2.中国科学技术大学 先进技术研究院,安徽 合肥 230027)
一种新的10GBASE-KR物理编码子层的变速箱设计
张琴1,杨莹1,杨灿美2,林福江1
(1.中国科学技术大学 信息科学技术学院,安徽 合肥 230027;2.中国科学技术大学 先进技术研究院,安徽 合肥 230027)
摘要:10GBASE-KR变速箱的功能是实现156.25 MHz下66 bit数据与644.53 MHz下16 bit数据之间的通信。该文在深入研究万兆以太网物理编码子层(Physical Coding Sublayer ,PCS)的功能以及变速箱原理的基础上,提出一种新的变速箱实现方法,将其分成读写数据转换和异步FIFO(First In First out)两个模块,完成发送通道和接收通道的设计。该方法有效减少了存储器的数目,使存储器数目由原来的528个减少到82个。本设计使用Verilog硬件描述语言,采用ModelSim进行功能仿真,并利用EDA(Electronic Design Automation)工具完成逻辑综合。仿真结果表明,该方法实现了变速箱的功能要求,并具有面积小、速度快的特点。
关键词:变速箱;万兆以太网;PCS;逻辑综合
引用格式:张琴,杨莹,杨灿美,等. 一种新的10GBASE-KR物理编码子层的变速箱设计[J].微型机与应用,2016,35(13):31-33,36.
0引言
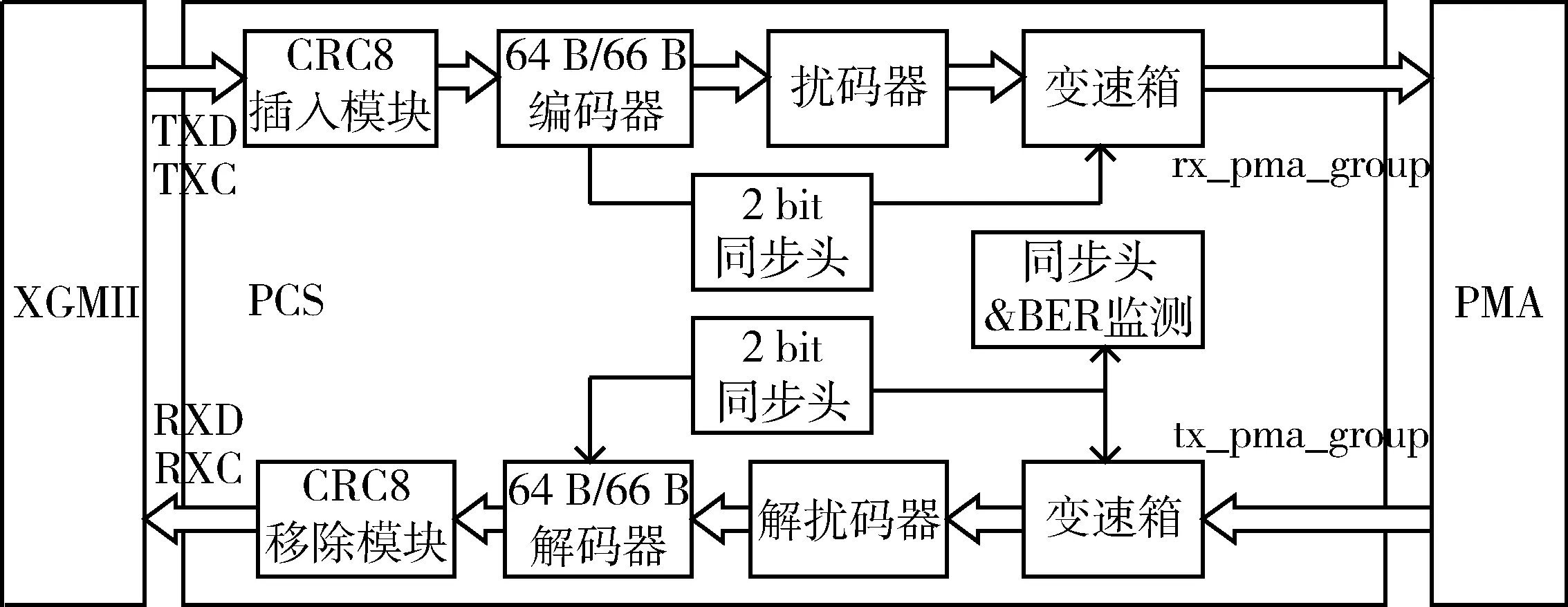
图1 PCS层功能结构图
变速箱的功能是在保证数据率不变的前提下,完成高速信号与低速信号之间的通信,广泛应用于高速通信系统中。万兆以太网作为以太网领域的先进技术,具有工作速率快、可靠性高、应用范围广的特点,有着广泛的发展前景。本文根据10GBASE-KR协议标准,设计了一种新的物理编码子层(PCS)变速箱实现方法,有效地简化了电路的复杂度。
1PCS层的功能与结构
PCS层位于媒体访问控制子层(MAC)与物理介质连接子层(PMA)之间,通过XGMII接口和PMA服务接口与上下层实现通信[1]。PCS层的结构图如图1所示。由图可知,PCS层由发送通道和接收通道构成,发送通道将XGMII传输的72 bit(两路32 bit的TXD和4 bit的TXC)数据转换成16 bit的数据发送到PMA层,包括CRC8插入模块、64 B/66 B编码器、扰码器和变速箱;接收通道接收PMA传输的16 bit的数据并转换为72 bit(两路32 bit的RXD和4 bit的RXC)数据,包括CRC8移除模块、64 B/66 B解码器、解扰码器和变速箱。整个PCS层以及XGMII接口的时钟频率为156.25 MHz,PMA层的时钟频率为644.53 MHz[2]。
2变速箱原理及传统设计方法
由PCS层结构图可知,变速箱位于扰码器/解扰码器和PMA层之间,完成156.25 MHz的低速信号与644.53 MHz的高速信号间的通信。
发送通道中,变速箱的输入为由扰码器输出的64 bit数据和64 B/66 B编码器输出的2 bit同步头构成的66 bit数据,输出是16 bit数据,并发送到PMA层;接收通道中,变速箱输入为PMA传输的16 bit数据,输出66 bit数据,并将同步后的64 bit数据传送到解扰码器以及将2 bit同步头传送到64 B/66 B解码器。
变速箱完成数据率为10.312 5 Gb/s信号间的传输,实现156.25 MHz下66 bit数据与644.53 MHz下16 bit数据的转换。
传统的变速箱结构图如图2和图3所示[3]。图2为发送通道变速箱结构图,其中,1 T~8 T是8个存储单元,深度为66 bit,总共528 bit的存储单元,每个存储单元对应每个时钟周期的输入数据,然后通过数据选择器在输出时钟有效沿到来时选择一路数据输出。该结构实现的是8个66 bit数据转换为33个16 bit数据。
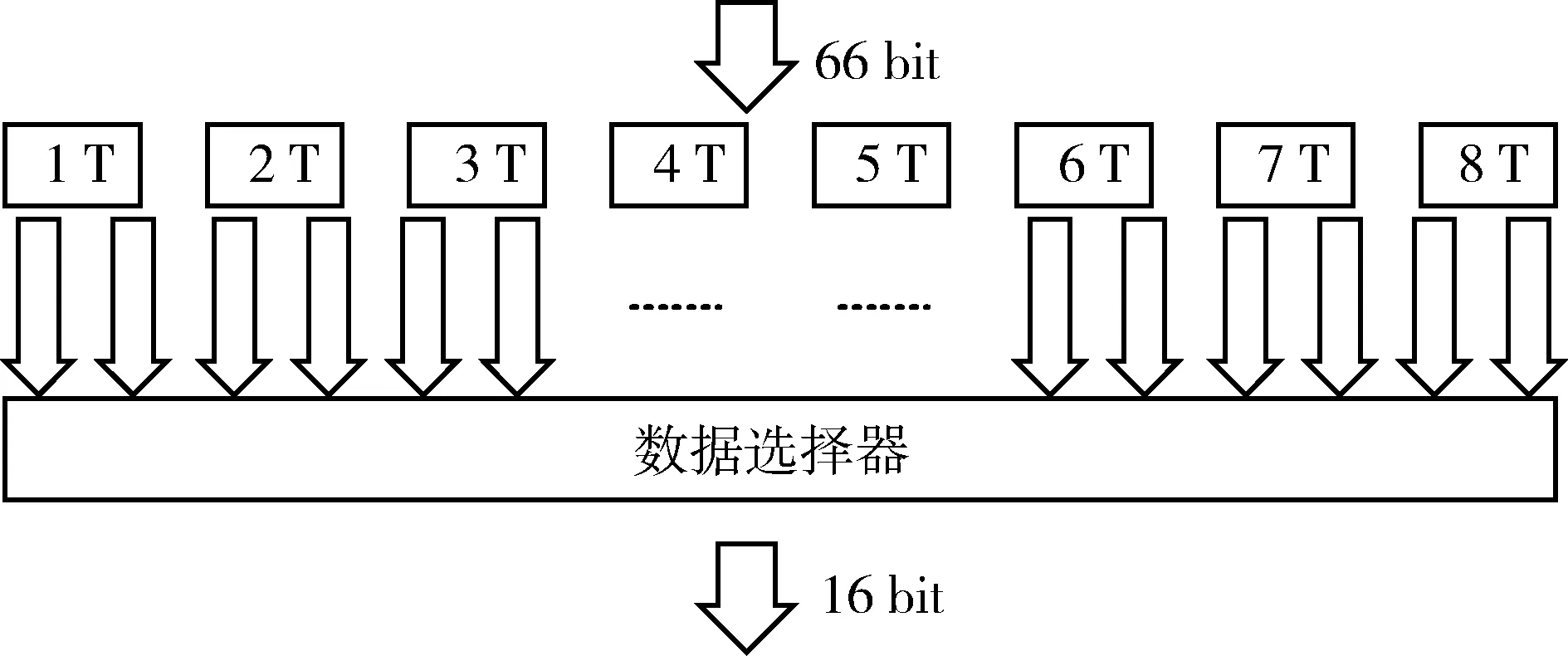
图2 传统发送通道变速箱结构图
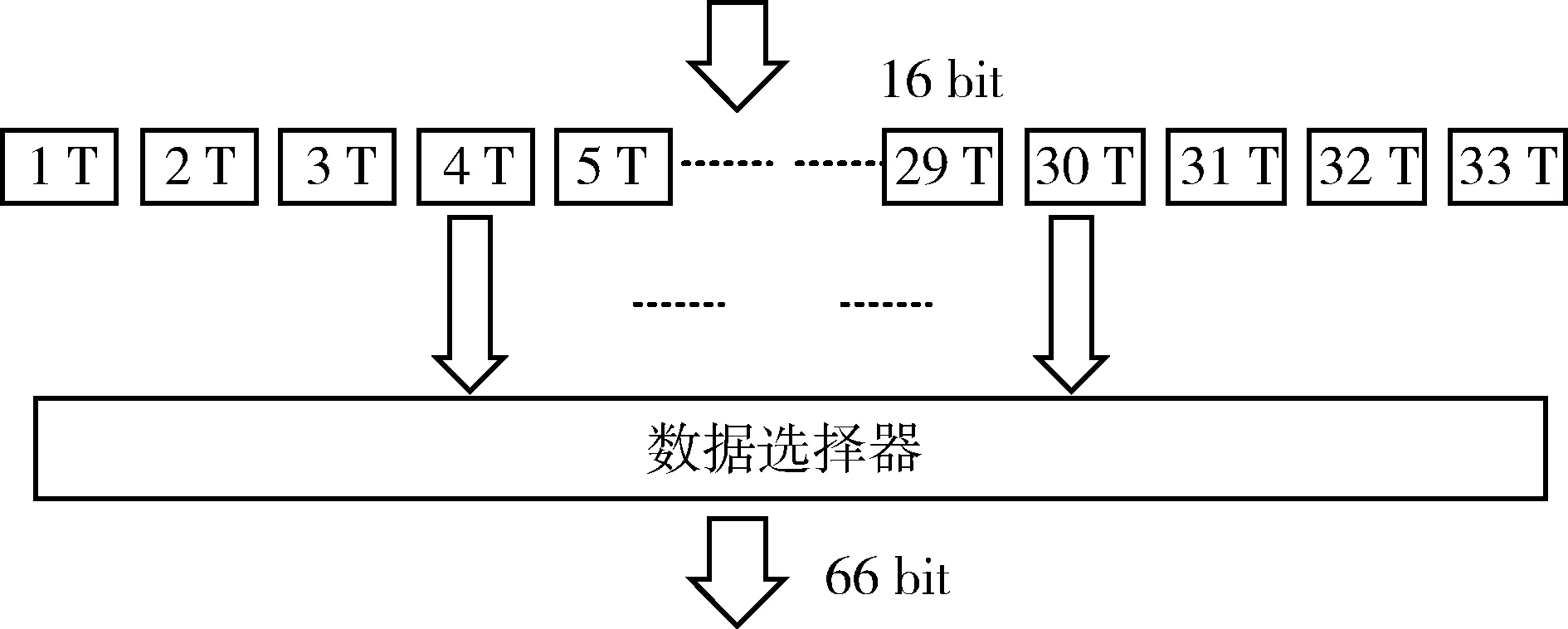
图3 传统接收通道变速箱结构图
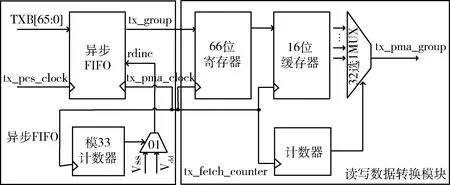
图4 发送通道变速箱电路结构图
图3为接收通道变速箱结构,其中,1 T~33 T是33个存储单元,深度为16 bit,同样耗费528 bit的存储单元,每个存储单元对应每个时钟周期的输入数据,然后通过数据选择器在输出时钟有效沿到来时选择一路数据输出。从而实现16 bit数据到66 bit数据的转换。
这种电路结构耗费的存储器太多,导致整个电路的面积很大,并且造成很大的延迟。为了保证数据输出时输入数据已经稳定建立,数据选择器的第一次输出选择的是第12个16 bit,还需人为加入17.05 ns的延迟[3]。另外,这种结构的控制信号不易产生,电路的稳定性大大降低。本文提出一种新的设计方法能够有效地解决上述问题。
3新的变速箱设计
变速箱的设计难点是输入数据宽度与输出数据宽度不成整数倍,所以每次发送或者接收到的数据不能正好全部发完,剩下的数据必须等下一时刻数据到来时再发送。而且每次剩余的数据位置是不固定的。
本文将变速箱分为两个部分:读写数据转换模块和异步FIFO模块。读写数据转换模块完成数据转换和处理剩余比特数据问题,异步FIFO模块完成跨时钟域的数据传输。
发送通道中,本文选用16位的寄存器缓存每次读取数据所余下的2 bit数据。每次写操作对应4次读操作,在第8次写操作时,16位的寄存器中缓存了16 bit的数据,所以,对应5次读操作,以实现8个66 bit的写数据转换为33个16 bit的读数据。
本设计难点在于如何设计控制信号。因为每次读写操作结束后,余下的2 bit数据在16位寄存器中的位置是不固定的。本文设置了一个与读时钟同步的7位计数器,在每次读操作结束,计数器累加16,同时,设置了一个与读时钟同步的模33计数器,控制每33个读时钟周期只读8次。电路结构图如图4所示。在PCS时钟有效沿将输入的66 bit数据通过异步FIFO与PMA时钟域同步,并通过模33计数器控制PMA的读操作,输出寄存在66位的寄存器中,将其高16 bit寄存到16位的缓存器中。
该方法有效减少了存储器的数量,由传统方法的528个存储器减少到了82个存储器(66+16=82),降低了异步FIFO的复杂度,并且减少了整个电路的面积。使用Verilog HDL[4]语言描述,部分关键代码如下:
always @ (*)
case(counter)
7′d0:tx _group= shift_reg2[15: 0];
7′d2:tx _group={shift_reg1[1:0],shift_reg2[15:2]};
7′d4:tx _group={shift_reg1[3:0],shift_reg2[15: 4]};
7′d6:tx _group={shift_reg1[5:0],shift_reg2[15: 6]};
7′d8:tx _group={shift_reg1[7: 0],shift_reg2[15: 8]};
接收通道中,设置4个16位寄存器级联,将每个寄存器的输出与输入拼接构成66 bit数据。设计难点同样在于如何设计控制信号。4个16 bit数据只能组成64 bit数据,需要拼接2 bit数据,而这2 bit数据的位置是不确定的,另外写时钟频率比读时钟频率快很多,直接利用异步FIFO将导致FIFO总是写满状态。
本文设置了一个与写时钟同步的模33计数器,控制选择正确的66 bit的拼接数据,同时控制每33个写时钟周期只写8次数据,输入到异步FIFO中,避免了由于写时钟频率比读时钟频率快很多而导致FIFO总是写满的情况。电路结构如图5所示。在PMA时钟有效沿,计数器开始计数,生成的控制信号作为8选1 MUX的选择信号,选择正确的信号作为异步FIFO的写信号。同时,模33计数器开始计数,控制写使能信号的产生,控制异步FIFO的写操作,输出正确的66 bit信号。本文中的异步FIFO均采用传统的异步FIFO设计结构[5],利用2级D触发器级联,并采用格雷码完成写地址与读时钟以及读地址与写时钟的同步,避免电路出现亚稳态。与传统设计方法相比,本设计有效地降低了电路的复杂度和整个电路的面积。部分关键代码为:

图6 发送通道变速箱仿真结果图

图7 接收通道变速箱仿真结果图
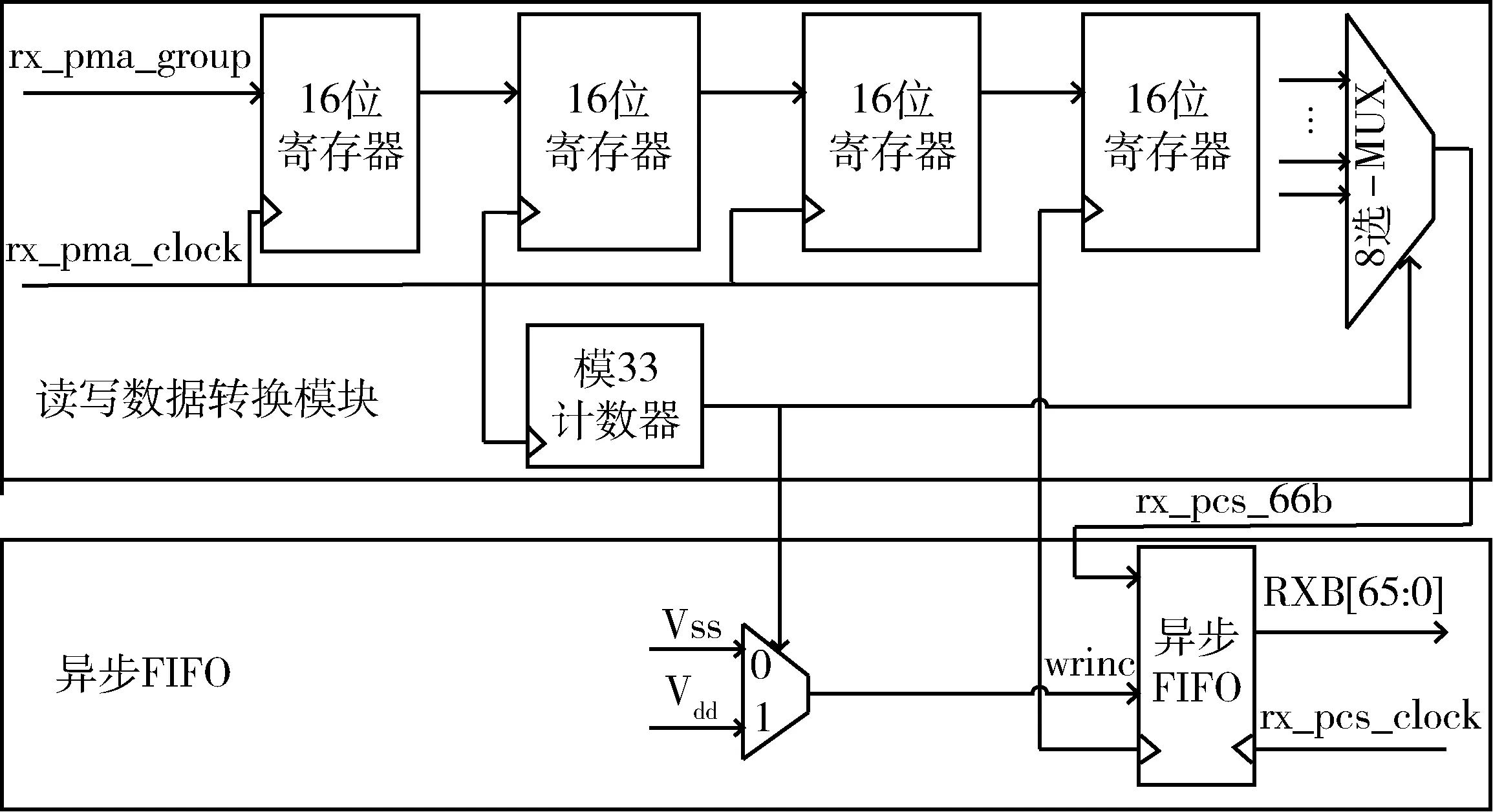
图5 接收通道变速箱电路结构图
always @ (*)
case(rx_fetch_cnt[4:2])
3'd0: rx_pcs_66b={rx_pma_group[1:0],rx_pma_group1,
rx_pma_group2,rx_pma_group3,rx_pma_group4};
3'd1: rx_pcs_66b={rx_pma_group[3 :0],rx_pma_group1,
rx_pma_group2,rx_pma_group3,rx_pma_group4[15: 2]};
3'd2: rx_pcs_66b={rx_pma_group[5 :0],rx_pma_group1,
rx_pma_group2,rx_pma_group3,rx_pma_group4[15: 4]};
3'd3: rx_pcs_66b={rx_pma_group[7 :0],rx_pma_group1,
rx_pma_group2,rx_pma_group3,rx_pma_group4[15: 6]};
3'd4: rx_pcs_66b={rx_pma_group[9 :0],rx_pma_group1,
rx_pma_group2,rx_pma_group3,rx_pma_group4[15: 8]};
3'd5: rx_pcs_66b={rx_pma_group[11:0],rx_pma_group1,
rx_pma_group2,rx_pma_group3,rx_pma_group4[15:10]};
4功能仿真与逻辑综合
本设计通过编写测试向量采用ModelSim工具完成各个模块的功能仿真,仿真结果如图6和图7所示。图6中,当输入信号为A_in时,对应的输出为A_out;当输入信号为B_in时,对应的输出为B_out。图7中,当输入信号为A_in时,对应的输出为A_out;当输入信号为B_in时,对应的输出为B_out;当输入信号为C_in时,对应的输出为C_out。为了保证信号的稳定性,人为地加入了一定的延迟。从仿真结果可以看出,输入所对应的输出都是正确的,表明本设计实现了PCS层发送通道和接收通道的变速箱功能仿真。
另外,本设计采用Synopsys公司的Design Compiler[6]工具完成了逻辑综合。综合结果表明设计完全符合PCS变速箱的时序要求。发送和接收电路分别留有4.56 ns、3.92 ns的时钟裕量,且面积小,分别使用了近1 000个逻辑门;在工作频率方面,发送电路使用了286个D触发器,最高写时钟频率分别为232.56 MHz、927.35 MHz,最高读时钟频率分别为961.54 MHz、211.42 MHz,使用了近1 300个逻辑门。与传统的设计方法[3]相比,面积缩小了近30%,工作速度提高了近50%。
5结论
本文在研究变速箱原理的基础上,根据其内在的逻辑关系,将电路分成写数据转换模块和异步FIFO两部分,设计了PCS层发送通道和接收通道的变速箱。完成了功能仿真和逻辑综合。综合结果表明,该方法有效地解决了控制信号不易设计和亚稳态的问题,缩小了面积,提高了工作速率。
参考文献
[1] Vivado design suite user guide: 10 GB Ethernet PCS/PMA v4.0[Z]. PG068 October 2, 2013.
[2] IEEE Std 802.3ap[S]. 2012 Edition.
[3] 敖志刚.万兆位以太网及其实用技术[M].北京:电子工业出版社,2007.
[4] 夏宇闻.Verilog数字系统设计(第二版)[M].北京:北京航空航天大学出版社,2008.
[5] VERILOG E, CUMMINGS C E. Simulation and synthesis techniques for asynchronous FIFO design[M]. Snug, 2002.
[6] Design compiler user guide[M]. Version H-2013.03
中图分类号:TP47
文献标识码:A
DOI:10.19358/j.issn.1674- 7720.2016.13.010
(收稿日期:2016-03-09)
作者简介:
张琴(1990-),女,硕士研究生,主要研究方向:数字集成电路设计。
杨莹(1992-),女,硕士研究生,主要研究方向:数字集成电路设计。
杨灿美(1965-),男,博士,研究员,主要研究方向:SOC架构设计。
A novel kind of the gearbox design of physical coding sublayer in 10GBASE-KR
Zhang Qin1,Yang Ying1,Yang Canmei2, Lin Fujiang1
(1.School of Information Science and Technology, University of Science and Technology of China, Hefei 230026, China;2.Institute of Advanced Technology,University of Science and Technology of China, Hefei 230026,China)
Abstract:The function of gearbox is to achieve the communication between the 66 bit data of 156.25 MHz and 16 bit data of 644.53 MHz in 10GBASE-KR. On the basis of deep research of Physical Coding Sublayer(PCS) function of the 10 Gigabit Ethernet and the theory of gearbox, a kind of gearbox design is given out, which is divided into two modules, the data conversion and asynchronous FIFO(First In First Out), to complete design of the transition and receive channels. It can reduce the number of memory effectively, from 528 to 82. The design uses Verilog hardware description language and adopts ModelSim to implement the functional simulation. What’s more, the logic synthesis is completed with the EDA(Electronic Design Automation) tools. The result shows it can meet the function demand of the gearbox, and it can reduce the area and improve the speed.
Key words:gearbox; 10 Gigabit Ethernet; PCS; logic synthesis
猜你喜欢
北京汽车(2021年3期)2021-07-17
制造技术与机床(2019年4期)2019-04-04
制造技术与机床(2018年8期)2018-10-09
车迷(2017年12期)2018-01-18
人民交通(2016年8期)2017-01-05
项目管理技术(2016年6期)2016-05-17
人间(2015年8期)2016-01-09
汽车实用技术(2015年8期)2015-12-26
筑路机械与施工机械化(2014年8期)2014-03-01
应用技术学报(2014年3期)2014-02-28
