
基于句法分析和问题分类的医院导医信息问答系统的研究
2016-08-02 19:10叶辉曹东
卷宗 2016年6期
叶辉 曹东


摘 要:本文主要研究是基于医院导医业务限定领域知识的问答系统,首先通过中文分词技术、中文信息抽取技术对用户提出的问题进行分词和词性分析,并对其问题文本进行句法依存分析,定出其疑问词和关键字,最后定出句子焦点词。本文采取了关键字和焦点词匹配的方法检索出答案,并按照医院业务流程和特点,设计了一个医院导医知识规则库,通过疑问词和关键字定位出相关问题类别,再通过关键字模糊匹配的方法选择触发相关的HIS数据检索,再返回用户该问题的检索结果。
关键词:医院导医信息;问答系统;句法分析;问题分类
基金项目:2014广东省中医药局建设中医药强省科研课题(20141073),广东财政专项“重大疾病中医药防治临床科研信息一体化平台建设”
1 引言
随着医疗和信息技术的发展,医院面临着导医医疗信息服务人手不够,用户对医院服务不满意等问题。而在网络上的医疗信息呈现几何式增长,病人难于通过搜索引擎从纷繁复杂的信息当中高效准确的获取需要的医疗信息。因此本文研究一种能针对医院导医信息的智能问答系统,运用自然语言处理技术对用户的问题进行处理,并结合医疗规则库的方式回复用户的问题。,因此研究一种针对医院诊疗信息的自动问答系统具有很强的实际意义。近年来,自然语言处理的研究取得了长足的进步,为问答系统的实现提供了理论基础。自然语言的研究在词性标注、语义分析、句法分析、信息抽取等方面都取得了不错的成绩,各种信息检索的方法也层出不穷,从而促进了自动问答系统的研究。
本文研究的是限定医院医疗诊疗信息领域的自动问答系统。原理采用自然语言技术对用户提问文本进行中文分词、词性分析、中文信息抽取、关键字排序、句法依存分析提取等处理,然后按照提取的关键字匹配已有医疗信息知识库的关键字,然后配合问题句法设计一个问题分类表,按照提取的关键字进行问题分类匹配问题类型,从而从知识库中确定出一条最合适用户提问的答案。
2 系统总体设计
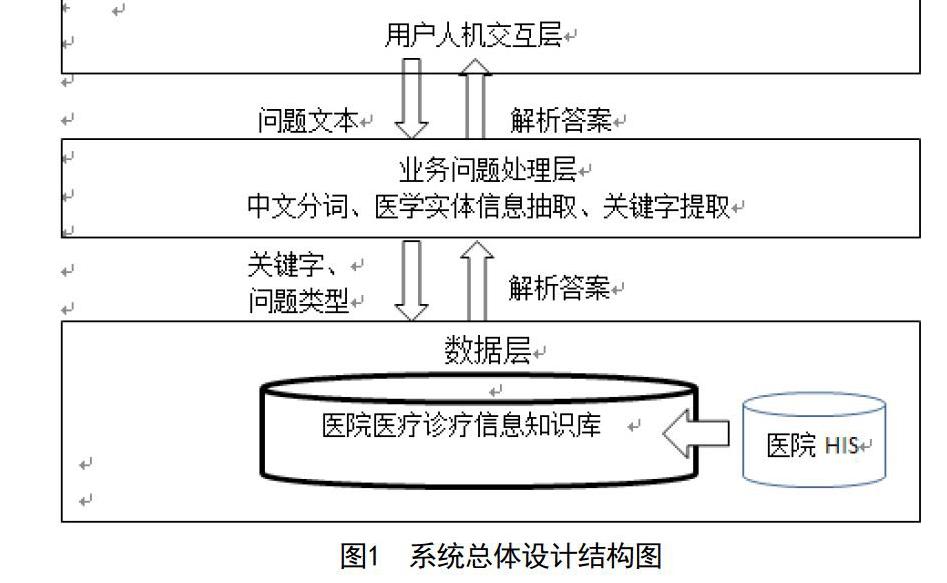
系统主要采用用户层、业务层、数据层三层架构,见图1,这样做的优势在于如果将来自然语言处理的发展更完善,能设计出更高效的算法,也不必改动用户层和数据层,只需要改动业务层即可。在数据层方面,近年来,各大医院都有自己一套成熟的医院信息管理系统,为了能最高效率地使用原有的HIS数据,问答系统的数据知识库以原有的HIS数据库为基础实现数据共享,通过HL7标准或XML进行接口数据的处理,免去将HIS数据导入到问答系统时带来数据同步的问题。
3 用户问题的理解
用户问题理解是本系统一个核心的处理某块,基本思路如下:
首先系统针对用户提问,有两个要求,一是一句话提问一个信息,二是提问文字个数不超过30个字,在输入端对用户提问先有一个预设框架,以免由于用户的随意性增加文本分析难度。
对句子进行中文分词处理。在英语当中,有类似空格之类的符号作为词语的分界线,而汉语是表意文字,词是最小的能够独立活动的有意义的语言成分,词语之间是没有明显的分界标记的,所以分词是中文问答系统中问题分析的基础。系统采用中科院ICTCLAS分词系统结合我们的医疗信息词汇词典进行加强分词,增加ICTCLAS对医院内部未登陆词汇的分词准确性。
其次对文本进行词性分析,然后进行过滤停用词的处理,所谓停用词是指那些对那些文本主题不具备表达能力的,或者表达能力可以忽略的词[1],如助词、标点符号、连词、语气词、拟声词等,这些我们都进行去除处理。如”请问内科在几楼呢?”这句话进行分词和词性分析后的结果是 “请问/v内科/n在/p几/m楼/n呢/y?/ww”,此时去掉无用词”呢”和”?”
3.1 句法分析抽取关键字
关键字代表了语句的主题含义,抽取关键字对理解语句的语义是至关重要的,它将会影响到后面答案的检索。关键字主要由名词、动词、形容词等组成,实际的应用中我们主要把过滤无关词后剩下的大部分词作为关键字。本文主要采用交叉信息熵计算每个候选词的上下文条件熵来获取关键字及其权重,但由于诊疗信息的特殊性,我们把代词和介词的权重提高一些。按照上述的关键字计算规则,如提问为“请问妇科在哪里?”这句话提取的关键字按权重Top2大小输出分别为:“妇科”/“请问”
问句的依存句法分析能更直观清楚地获取语言单位内成分之间的依存关系并揭示其句法结构,像针对医院导医系统的问题来说,主要关注是SBV和POB主谓关系和介宾关系,本文通过哈工大LTP的依存句法分析器分析出问题文本的依存句法,结合之前的提取的关键字“妇科”,联系SBV和POB提取出“在”和“哪里”这些谓词和宾语,,而“哪里”根据词性标注结果被提取成为句子疑问词关键字,然后抽取出谓语,通常距离疑问词最近的原则来抽取谓语[2]。
本系统采用的分类方法是基于句法分析结合规则的问题分类方法,它是一种基于疑问句和问题焦点相结合的方法。在提取用户问题的关键字后,按照关键字的权重大小依次对用户问题的关键字和问题类型表中的疑问词关键字进行相似性匹配,只要含有其中一个关键字或意思相近,即可使用该问题类型。下一步就要决定出用户问题的焦点所在。问题焦点就是问题中说明问题只要内容的一个名词或名词性短语。一般情况下,一个名词或名词短语是问题焦点的可能性比较大。首先,提取问句中的所有名词,然后根据名词在疑问句中的位置进行判断,经过研究统计可以得到以下判断规则:
(1)疑问词后紧跟着名词或短语,那么该名词或名词短语可能是问题的焦点。
(2)疑问词处于句子的末尾,那么距离疑问词最近的名词或名词短语可能是问题的焦点。
(3)疑问句后面跟着动词,那么句子最后出现的名词或名词短语可能是问题的焦点。
根据这个规则结合词法分析的语法依存分析,我們开发出算法对用户问题分词后的焦点词进行提取,例如:“请问妇科在哪?”,关键字的焦点主要是“妇科”,因此我们再把焦点词进行一次检索比较。
4 问答的实现
4.1 问题分类
本文采取问题分类的方法来定位相关的答案输出。问题分类是问答系统中重要的组成部分,问题分类结果的好坏直接影响问答系统的质量[3]。问题分类是根据中文信息抽取技术中的命名实体识别判断出问题属于哪一个类型。问题分类可以有效的减少候选答案的数量,提高答案的准确率。准确的问题分类有助于在问题抽取时根据不同类别的问题采用不同的答案抽取方法。结合医院导医领域的实际情况和中文问题的特征,我们以疑问词作为分类关键字,这些词汇对询问的内容的范围有很大帮助,这些词带有明显的分类特征[4]。以下定义了几种基本的问题类型,如表3-1所示。而疑问词和关键字的获取则依靠上一节描述的句法分析方法来提取。
4.2 医导答案规则数据库的搭建
本系统要构建的医导答案知识库属于限定领域知识库的范畴,构建知识库是为了使无序的内容变得有序,一个完备的知识库能够大大提高系统搜索答案的效率和准确率,但本系统为了快速显示答案,将不使用完整的自然语言输出,只考虑直接输出查询结果或答案,并不做过多的语法修饰。如果要完整的自然语言重构输出,可采用问题-答案模板的形式来出来,或者使用问题-答案相似度计算来进行模拟答案以自然语言的方式输出处理。数据字段设计如下:
如用户输入”请问妇科在哪里?”,系统分词处理后“妇科”是第一关键词,然后通过句法依存分析提取出关键字所在句法结构中和她联系密切的句法,然后提取出相关的疑问词和谓语词分别是“在/哪里”,在系统数据库中找到匹配的相关疑问词或关键字,找出对应的问句类型,然后根据问题焦点词 “妇科”进行二次匹配,如果找出相应的匹配词汇或近似匹配,就代表匹配成功,找出数据表对应的类型字段type是“地点”,然后按照Type=”地点”找出answer对应的字段里的预设好触发SQL处理过程脚本代码,如anwser对应的是SQL查询记录返回address,则此时系统会去HIS后台,通过address 字段读取相关妇科的地址在哪里,然后将答案返回给用户。如果所有关键字按照顺序,在问题分类和焦点词里面都无法找到,就返回一個找不到答案的警告给用户。
5 总结
本文先通过中文分词将用户提问进行分解,并提取出关键字和权重,然后利用句法依存分析器分析相关语句和主谓结构的谓语短语与关键字,找出疑问词。然后通过和数据库的疑问词匹配分析,定位答案回答的类型,然后通过关键字分析和焦点分析的结果,找到焦点为相关词汇的数据记录,最后答案由SQL语句进行远程HIS医院系统的查询操作,返回给用户界面。
参考文献
[1]谢晋. 基于词跨度的中文文本关键词提取及在文本分类中的应用[D]. 浙江工业大学, 2011.
[2]孙昂;江铭虎;贺一帆;陈林;袁保宗;;基于句法分析和答案分类的中文问答系统[J]《电子学报》 2008年05期
[3]文勖, 张宇, 刘挺,等. 基于句法结构分析的中文问题分类[J]. 中文信息学报, 2006, 20(2):33-39.
[4]张亮;王树梅;黄河燕;;面向中文问答系统的问句句法分析;山东大学学报;第41卷第3期;2006年6月.
作者简介
叶辉,男,广州中医药大学医学信息工程学院,讲师,主要研究方向:医学信息学。
曹东,通讯作者,男,广州中医药大学医学信息工程学院,副教授,主要研究方向:医学信息学。
