
云海大数据一体机体系结构和关键技术
2016-07-31 23:32:06亓开元辛国茂刘正伟颜秉珩
计算机研究与发展 2016年2期
关键词:可扩展性
张 东 亓开元 吴 楠 辛国茂 刘正伟 颜秉珩 郭 锋
(高效能服务器和存储技术国家重点实验室 济南 250101)(浪潮电子信息产业股份有限公司 济南 250101)(qiky@inspur.com)
云海大数据一体机体系结构和关键技术
张 东 亓开元 吴 楠 辛国茂 刘正伟 颜秉珩 郭 锋
(高效能服务器和存储技术国家重点实验室 济南 250101)
(浪潮电子信息产业股份有限公司 济南 250101)(qiky@inspur.com)
为了弥补从大数据技术到行业应用之间的鸿沟,针对当前行业用户对大数据处理平台的持续扩展、一体化和多样性需求,提出了大数据一体机的可扩展性、可定制性和多类型处理模型,并基于此设计了云海大数据一体机.该一体机采用兼顾横向和纵向可扩展的体系结构,并采用硬件可定制化设计和混合型软件架构支持多种大数据应用类型.在此基础上,针对HDFS元数据服务瓶颈问题、MapReduce负载倾斜问题、HBase的跨域问题,介绍了在云海大数据一体机中采用的多元数据服务、负载均衡和跨数据中心大表技术.在电信、金融和环保行业实际案例中的应用和测试表明,上述体系结构和关键技术是可行和有效的.
随着信息时代云计算、物联网、移动互联网等技术的快速发展,数据已经渗透到每一个行业领域,成为重要的生产因素,而数据的海量累积逐渐被公认为是与水、石油、天然气同等重要的国家战略资源,将推动生产力发展和创新[1].IDC(International Data Corporation)预测[2],2020年以前全球数据量将保持每年40%以上的速度增长,2015年将达到7.9ZB,2020年将突破35ZB.迅速积累的大数据对行业用户来说蕴含着巨大的商业价值和社会价值,通过挖掘大数据,公司的决策会建立在更加科学的依据基础上,而对于政府,大数据技术可以提高运行效率、危机应对能力和公共服务水平.
大数据虽然极具价值,但由于类型复杂、规模巨大,不论传统的数据仓库还是新兴的分布式处理方法都有特定的短板,不可能满足所有的需求,因此,要真正释放大数据的能量,推动大数据应用并非易事,主要面临着以下问题和挑战:
1)基础设施的持续扩展问题.IDC的数据显示,数据总量每2年至少增长1倍,但是硬件基础设施由于摩尔定律失效很难进行无限制扩展.即使是新兴分布式技术的扩展性有了重大的提高,也仍存在扩展上限,如Oracle RAC最大支持100个节点,Hadoop集群支持4 000个节点,并且其设计初衷是建立在大量廉价、低端服务器上的,在充分横向扩展架构的同时还需要纵向扩展才能进一步提升整体性能[3].与此同时,基础设施规模不断增大也会带来其他的问题,首先是系统的可用性,大规模分布系统中节点故障成为常态,不能因此影响业务应用的持续性.另外,随着系统规模的扩展,数据传输量快速增长,网络瓶颈也会制约系统性能的提升,限制系统的可扩展性.
2)数据处理的个性化、多样性和一体化需求问题.大数据催生了多种数据类型,无论是结构化、半结构化还是非结构化的数据,从采集到挖掘都需要精细划分,形成准结构化数据,并在此基础上进行关联性分析,最后呈现处理后的结果.在上述过程中,每一个环节对于数据、软件和硬件的要求是不一样的,用单一的软硬件无法满足所有类型应用.更为重要的是,作为大数据应用主体的行业用户并非都是IT专家,不可能独立实现上述过程以及大数据相关技术方案的整合部署、应用移植和二次开发,因此就需要一个涵盖数据采集、归类、挖掘、呈现、部署和移植的一体化解决方案.总之,多类型、多维度数据处理环节的复杂性决定了无法依靠单一类型的设备完美处理,为不同的应用类型和处理阶段提供针对性的软硬件一体化方案也是大数据应用面临的挑战.
针对上述挑战,国内外纷纷推出了针对大数据处理的解决方案或者产品来满足需求,其中备受关注的当属软硬件一体化设备——大数据一体机(big data appliance).大数据一体机是一种专为大量数据分析处理而设计的软、硬件结合产品,由服务器、网络、存储、操作系统、数据管理系统以及一些为数据查询、处理、分析用途而特别预先安装及优化的软件组成,为TB至PB级别的数据仓库提供解决方案.大数据一体机通过标准化的集成架构减化数据中心基础设施部署和运维管理的复杂性,通过预配置和调优解决多重工作负载性能问题,其中比较有代表性的是IBM PureData,Oracle Exadata,SAP HANA,EMC Greenplum等.IDC在其对亚太区ICT市场的十大预测中指出,到2015年,65%的私有云或行业云环境将部署一体机[4].
为打破国外厂商的技术垄断,我们设计并研发了云海大数据一体机(in-cloud smart data appliance,iSDA).本文首先介绍了iSDA体系结构的理论基础,提出了可扩展性、可定制性和多样性处理模型,依照上述原理设计的iSDA兼顾横向和纵向扩展能力,并可通过定制化和混合型软件架构支持多种大数据处理应用类型.在此基础上,针对HDFS元数据服务瓶颈、MapReduce负载倾斜、HBase跨域扩展等问题,介绍了iSDA采用的多元数据服务、负载均衡和跨数据中心大表技术.最后,通过在多个行业中的实际案例进一步验证iSDA体系结构和关键技术的有效性.
1 体系结构
总体来说,国外厂商在大数据一体机领域还处于领先地位,对部分产品和技术形成了垄断.然而,国外厂商的大数据一体机大都属于基于已有关系数据库(如Oracle,SQLServer,Greenplum等)进行扩展的并行数据库,虽然理论上支持上千节点的部署规模,但国内外仅有少量上百节点的部署案例,并且还无法实现真正的在线扩展;此外,国外一体机大都捆绑众多软硬件产品,价格高昂,并且从国家信息安全角度,若过分依赖国外产品,存在风险和隐患.
在国外竞争对手通过一体机发力大数据领域的同时,国内厂商也在加大对大数据一体机的研发步伐.与国外厂商相比,国内大数据一体机大都基于开源Hadoop软件以及通用操作系统、计算和存储服务器搭建而成,缺乏真正意义上自顶而下、由内而外、软硬结合的一体化设计,特别是保留着开源软件易有的弊端.例如,缺乏图形化管理工具,为部署与管理带来不便;缺乏负载均衡、任务调度等算法优化,容易在低性能或热点服务器上产生性能瓶颈;元数据节点易形成单点故障和系统瓶颈,一旦失效系统将无法读写;无法进行跨数据中心部署等.
相比较之下,iSDA采用兼顾scale-up和scaleout的体系架构,既可通过横向增加节点进行线性扩展,也可通过纵向扩展硬件得到提升,在达到4 000个重载节点情况下,也还能够实现相对较好的扩展性;采用一体化、定制化设计,行业用户可以根据各自应用特点选择不同的系列化配置,实现按需定制.此外,iSDA基于硬件平台构建面向行业多样性应用的混合型大数据软件系统,满足实时处理、交互处理、高效检索、数据挖掘和商业智能等多样性需求,在实现资源调度和作业管理分离的基础上,提供对计算、存储和网络等集群资源的统一监控和分配,提供对各类大数据处理技术的可扩展支持,并解决当前单一数据处理系统普遍存在的单点失效和安装部署困难等问题,增强系统可靠性和自动化部署能力,在提高资源利用率的同时促进对大数据技术的有效利用.
下面主要介绍iSDA在可扩展性、可定制性和应用多样性方面的设计原理和关键技术.
1.1 可扩展性设计
面向大数据的处理需要突破存储和计算能力限制,为了支撑大规模数据的存储和计算,当前往往采用多核服务器集群并行计算架构,以及Cache、内存、辅存和分布式存储的多层存储结构.随着内存价格的不断下降、服务器可配置内存容量的不断提高以及固态硬盘(solid state disk,SSD)技术的发展,基于内存计算架构完成高速的大数据处理成为重要发展趋势[5].
Gustafson定律[6]给出了固定时间内的集群加速比,但其性能模型过于理想,没有考虑网络I?O开销和单个节点的性能影响.Gustafson定律将任务划分为串行和并行部分,在考虑网络的情况下,可以将任务的网络传输部分视为影响可扩展性提高的因素.即若任务串行部分为α,网络传输部分为β,随着节点增加,为保持连通性,集群拓扑结构复杂性为
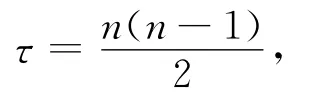
网络传输部分对集群的影响为τβ.
根据上述分析,基于Gustafson定律,iSDA集群的可扩展性模型可定义如下.
定义1.iSDA可扩展性模型.若任务串行部分为α,网络传输部分为β,单个节点的性能提升因子为s,则n节点集群的加速比为

对式(1)求导取极值点n′,可得

上述模型表明,单个节点处理能力的提升是促使整个集群处理能力提升、保障集群可伸缩性的基础.因此,在iSDA中采用了如下技术进行节点加速:
1)适用于大数据处理的重载计算单元.针对访问请求密集、数据量大且耦合度高、具有特定算法的计算密集类应用,在通用处理器同构多核架构基础上设计了基于异构协同计算架构的重载计算单元,通过CPU与众核处理器(many integrated core,MIC)融合、图形处理器(graphic processing unit,GPU)局部强化和现场可编程门阵列(field programmable gate array,FPGA)硬件加速,实现10~100倍的加速比.
2)适用于大数据处理的存储单元.充分发挥新型存储介质的作用,构建基于非易失性存储(nonvolatile memory,NVM)和传统动态随机存取存储(dynamic random access memory,DRAM)的高可靠、大容量、低功耗异构混合内存,在整个存储层次里面增加SSD作为高速缓存,并针对每个存储单元的多块磁盘实现负载均衡、冗余编码多副本和分布共享缓存,提高了I?O吞吐量.
3)大数据互联交换芯片和全局交换网络.在互连核心交换芯片中,实现了对系统级消息通信、数据交换以及I?O操作的统一支持,降低内部延迟;设计全局高速交换网络,融合数据通信与存储网络,提高了系统通信性能和扩展能力.
此外,iSDA可扩展性模型还表明,若集群规模在网络带宽范围之内,加速比由串行部分和可扩展的并行部分确定;若集群规模持续增大,网络带宽将会成为制约集群可扩展性的瓶颈,增加节点不会促进加速比提升.由于iSDA采用了完全分布式的处理架构,任务串行部分可近似为0,例如,采用NoSQL数据模型的HBase数据库避免了由于维护ACID和事务特性而引入的同步处理.由式(2)可知,若无任务串行部分,即α=0,则集群可伸缩性由网络传输部分决定,有

根据上述原理,iSDA中采用了以下优化设计:
1)高速通信网络.基于TCP?IP协议,iSDA可配置高带宽的万兆以太网乃至40Gbps的InfiniBand网络,实现一体机内部的高速互联.然而,由于TCP?IP属于传输层协议,其内部的慢启动、拥塞避免等机制造成带宽利用率不高,即便是采用万兆网也无法有效应对TB以上级数据传输,I?O瓶颈严重影响了系统整体性能.iSDA进一步基于PCIe通道构建互联网络,使得节点可以通过扩展卡连接到PCIe网络上,双向16通道带宽能够达到256Gbps.
2)减少数据传输量.由于采用了分布式并行处理架构,网络传输开销随集群规模增加而增大.若某任务节点间的网络传输为10Mbps,由式(3)可知,配置千兆网络集群规模无法超过100节点.为减少数据传输,iSDA在软件栈中全面支持GZIP,LZO,Snappy等压缩方式,并通过对数据分区、分桶以及Map-only Combine、Map Join等方法尽量减少数据传输.此外,iSDA内部的网络通信主要来自主节点和从节点间的状态同步,为了减少大量的状态数据传输量,采用状态缓存算法[7]减少不必要的网络开销,即DataNode使用SHA-256或SHA-512Hash函数记录当前节点状态,之后在只有在状态Hash值不同的情况下才发送完整节点状态,否则只发送心跳信息.通过上述优化,在达到10%的压缩率以及配置万兆网络的情况下,由式(3)可知,集群规模能够提高100倍.
1.2 可定制性设计
针对当前涌现出的多种多样的大数据处理需求,传统的方法是采用通用服务器来构建应用平台,由于与应用之间的匹配度不好,导致实际应用效能比较低.iSDA根据不同业务类型,结合各种应用负载特点,设计可定制的系列化配置来分别满足应用需求.下面给出iSDA可定制性的理论模型及其系列化设计.
定义2.iSDA可定制性模型.若节点j内存容量为mj,外存空间为pj,命中率提升因子σ,则中间结果内存命中率为
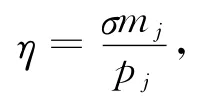
非命中率为η-=1-η,若节点在中间结果内存命中的情况下处理速度为μ,非命中情况下处理速度阻尼因子为λ,则处理速度的数学期望为
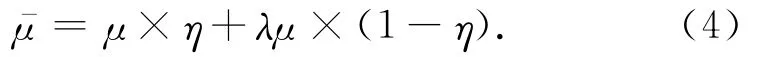
上述模型表明,可以根据CPU速度、内存容量和I?O带宽刻画节点的处理能力,通过定制进一步优化单个节点的处理能力,在式(4)中可以通过μ,λ和σ等参数体现出来.根据上述原理,iSDA的系列化配置[8]及其性能对比如表1和表2所示:
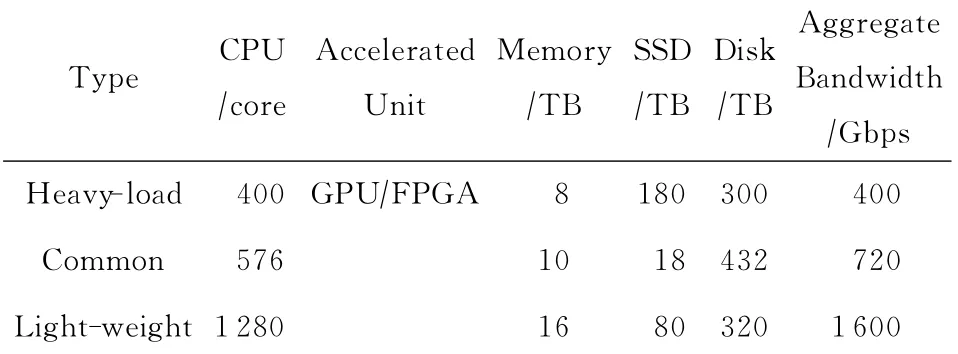
Table 1 iSDA Series Configuration表1 iSDA系列化配置

Table 2 iSDA Performance Comparison表2 iSDA性能对比
针对在线交易、视频处理、图像渲染、图像编解码、在线加解密、高性能计算等重载应用,采用CPU与GPU,MIC混合的异构协同计算架构,使用FPGA将算法固化在硬件中,并在存储层次里加大SSD缓存进行数据读写加速.
针对模式计算、商业智能和数据挖掘等通用类型处理应用,基于通用处理器设计计算、I?O、存储能力均衡的机架式和刀片式服务器来满足常规处理类应用的需求,如分布式文件系统HDFS和分布式数据处理MapReduce等.
针对企业搜索、流式处理等海量并发的轻量级应用,虽然并发访问量可达每秒数十万次,但每个请求所需的计算资源较小,因此,基于多核多线程低功耗处理器,采用最小化和并发线程优化方法设计轻量级计算模块,再配以大容量内存满足NoSQL数据库、流处理引擎需求.例如,在2U的空间里集成128个CPU核心,具有512个并发线程的处理能力,而总体功耗小于2kW.
综合可扩展性和可定制性设计,iSDA硬件架构如图1所示:
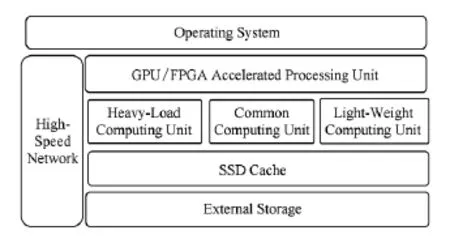
Fig.1 iSDA hardware architecture.图1 iSDA硬件架构
1.3 混合多样性设计
针对行业大数据业务需求,面向数据密集型应用的计算框架和系统不断出现,如MapReduce编程模型[9]、NoSQL高并发实时数据库[10]、内存计算引擎[11]和流式处理框架[12]等.这些系统仅针对各自的问题域提供解决方案,为了应对行业日益复杂的业务需求,需要在大规模集群或数据中心中综合运用多种处理架构来存储和处理海量数据.然而,当前的各种大数据系统是逻辑独立的,缺乏统一的集中管理,若各自采用单独集群部署,则存在不可忽略的数据冗余和资源利用率低下问题;若考虑到资源利用率和数据共享等因素,将所有框架和系统集中部署到单一集群中,则又面临着相互之间资源竞争和性能干扰等问题.
为满足行业应用对大数据的多源异构存储和多样性处理需求,iSDA采用了一种混合型大数据软件架构.该架构在融合各种分布式存储和处理技术的基础上,通过构建对于大规模、多层次异构存储的一致性数据组织和透明管理机制,进一步借助内存数据库和内存计算引擎优化大数据处理性能,并通过一体化的管理平台保障系统的可扩展性和可靠性.
iSDA混合型软件栈包括分布式数据采集层、基于内存计算的混合型分布式存储层和处理层、一体化的资源和系统管理层,如图2所示:

Fig.2 iSDA hybrid software stack.图2 iSDA混合型软件栈
1)分布式数据采集层以流水化、并行方式抽取、转换和载入数据,实现对多源异构行业数据的高速导入.支持文本、XML、传输协议、数据库、文件系统等多种数据源,以及异步Push和轮询Polling等灵活的工作模式,可按需定义清洗、编码、分发和转换等预处理操作,同时可动态扩展以提高吞吐量,并且可根据性能需求配置可靠性级别.
2)大数据存储层采用分布式外部存储、结构化?半结构化数据库、分布式内存3层存储架构,包括分布式文件系统以及基于分布式文件系统的关系数据库、NoSQL数据库和内存数据库.分布式文件系统可以直接存储客户服务系统或社会经济数据中的文本、视频和音频文件,并能够为上层数据库提供高可靠、可扩展的文件存储;关系数据库用来存储生产管理、客户关系、营销这类结构化特征强、模型驱动的、需要强一致性事务保证的数据;NoSQL数据库用来存储历史日志数据、气象信息、社会经济数据这类半结构化或者结构化特征较弱、主要考虑存取性能和可扩展性的数据;内存数据库则存储各种经常使用或需要加速处理的数据,如索引、中间结果、维表数据等.
3)大数据处理层采用基于分布式内存计算的混合型处理架构,包括内存计算引擎以及基于内存计算的批处理、图计算、交互处理和流处理引擎.内存计算引擎提供对异构存储介质的分布式内存抽象,实现缓存数据、提高I?O性能的效果,并采用并行流水化方式和线程级轻量运行环境加速数据处理性能;批处理引擎面向以离线方式进行的数据密集型并行计算,如聚类、关联分析、协同过滤等数据挖掘算法;图计算面向一类以图模型作为数据表示的特殊离线处理,如网页排序、用户行为分析、社会关系网络等;交互处理引擎用来快速响应应用层的标准SQL请求,如查询、聚合和关联等;流处理引擎面向连续、实时到达数据的流式处理,如时间窗口查询统计、清洗转换和异常报警等.此外,高性能计算引擎基于重载类型iSDA配置,使用MPI?OpenMP,CUDA?OpenCL,Verilog?VHDL等特定的编程模型[13],满足紧耦合的、多次迭代的计算密集型应用需求.
4)一体化管理平台包括集中式Web控制台和分布式集群资源管理系统.控制台通过提供采集、存储和处理子系统的安装、部署和配置功能,计算、存储和网络资源及各子系统运行情况的监控功能,以及认证、授权、加密等安全管理功能,增强系统的可管理性和易用性.集群资源管理系统一方面基于资源调度和任务控制分离方式,采用统一的资源调度框架在各子系统间进行资源分配,使子系统只需关注内部任务的控制和调度,从而减轻了子系统压力,提高了整个系统的可扩展性;另一方面通过提供监听、分布式锁、一致性存储等分布式服务监控集群节点增加、失效、退出等动态变化,记录关键信息,在任意节点失效后能够快速恢复系统状态,保证整个系统的可用性.
基于iSDA混合型软件架构,可以定义针对行业大数据各种应用类型的处理模型.
定义3.iSDA在线实时处理模型.在线实时处理的运行机制和处理过程为:
1)采集系统从政府、证券、银行等行业的系统中抽取各种客体行为数据、交易记录、实时事件等结构化数据,这类数据来源多、生成速度快,数据量通常在TB级.
2)数据经过预处理后,若属于结构化特征强的数据,则批量加载进入关系数据库;若属于历史日志数据、事件记录、社会经济数据这类结构化特征较弱、主要考虑存取性能和可扩展性的数据,则批量加载入NoSQL数据库.
3)在后台进一步对数据进行准备,形成数据索引、过滤器、维表、中间结果等经常使用或可以加速处理的数据导入内存数据库.
4)在线实时处理类应用主要是关键字查询、多维查询、模糊查询以及数据更新、插入、删除等高并发增删改查请求,要求毫秒级至秒级响应时间,根据对事务特性的需求可分为在线交易处理和在线并发处理,在线交易对ACID事务特性有严格限制,需要达到Committed Read,Repeatable Read甚至串行化隔离级别,在线并发处理只需要简单的行级锁或Check and Set语义保障读写一致性.
5)应用层在发起数据请求时先查看内存数据库中是否有索引、过滤器或缓存数据,若在内存数据库得到所有数据则返回;若内存中未获得有用数据或只获得部分数据,则在线事务处理继续针对关系数据库采用标准的SQL语句发起各种数据请求,在线并发处理继续针对NoSQL数据采用基于key? value的API发起数据请求.
6)为保障数据的可靠性,内存数据库将变化的数据同步到关系数据库或NoSQL持久化存储,同步可根据可靠性级别选择采用实时同步、日志同步和定期同步机制.
定义4.iSDA交互式分析模型.在线交互式分析的运行机制和处理过程为:
1)分布式采集系统从交通、公安、医疗等部门或互联网、银行、零售、制造等企业的信息系统中抽取各种交易、ERP、CRM等结构化数据和客体行为、系统日志等半结构化数据,数据量通常在TB级.
2)数据经过预处理后以行存文件格式批量加载进分布式文件系统,或以列式表形式批量加载进NoSQL数据库,必要时可对数据进行压缩以减少存储空间.
3)进一步对数据进行后台准备,在交互处理引擎中建立关系模型到物理层文件或列式存储的映射,指定行列分隔符、存储格式和序列化方法,并对数据进行分区、分桶、排序等预处理,将索引、过滤器、维表、中间结果等经常使用或可以加速处理的数据导入内存数据库.
4)交互式类应用主要包括数据扫描、统计、聚合、多表关联等并发请求,要求秒级至分钟级响应时间,应用层采用标准的SQL语句发起各种数据请求,交互处理引擎解析SQL语句,形成优化的查询路径并调度执行.
5)交互处理引擎在发起数据请求时先查看内存数据库中是否有索引、过滤器、维表、中间结果或其他缓存数据,若可在内存数据库得到所有数据完成处理则返回;若内存中未获得有用数据或只获得部分数据,处理引擎继续针对分布式文件系统或NoSQL数据库发起各种数据请求.
6)为保障数据的可靠性,内存数据库将变化的数据同步到关系数据库或NoSQL持久化存储,同步可根据可靠性级别选择采用实时同步、日志同步和定期同步机制.
定义5.iSDA离线批处理模型.离线批处理的运行机制和处理过程为:
1)采集系统从各种数据源中抽取系统日志、手机记录、邮件、短信、微博等半?非结构化数据,数据量达到TB级至PB级.
2)数据经过预处理后以文件形式加载进分布式文件系统,必要时可对数据进行压缩以减少存储空间.
3)离线批处理应用主要包括聚类、分类、时间序列回归、关联分析等数据挖掘和机器学习,以及社会网络等图计算,由于数据量巨大,计算逻辑复杂、迭代次数多,一般采用后台离线方式,对响应时间没有具体要求.这类应用采用Map,Filter,Combine,Partition,Reduce,Join等算子进行函数式编程,以批处理方式提交作业,批处理引擎通过数据切分、任务调度和内部通信完成处理.与普通批处理作业不同,图计算则采用基于图(如顶点、边、权值等)及相应函数(权值变换、顶点通信、图结构变化等)的编程模型.
4)基于内存计算的批处理和图处理在第1次处理或首次迭代时从分布式文件系统获得处理数据,处理完成后将中间结果缓存在内存中,以便下次处理或迭代复用.
定义6.iSDA流式处理模型.流数据处理的运行机制和处理过程为:
1)采集系统从各种数据源中实时的采集用户行为、系统事件等数据.
2)由于数据流的无限性,流式处理主要面向基于时间窗口的查询、统计和分析,以及异常事件报警和数据实时清洗转换等应用,流处理应用采用由多种算子组成的函数式编程模型.
3)在运行时,数据以持续、不间断的数据流形式进入处理系统,驱动预定义的处理逻辑连续地进行计算,其区别于批处理之处在于没有数据积攒成批、阶段同步、持久化的延迟;流处理系统将处理逻辑定义为由多个算子组成的多阶段处理网络,在数据处理的多个阶段间采用异步流水线方式,在同一阶段内采用节点间和节点内并行方式提高实时处理性能.
4)流处理结果最终输出到持久化存储或直接发送到应用层实时告警或展示页面.
2 关键技术
与开源Hadoop方案相比,iSDA增加了管理和监控工具,简化了集群的部署与管理,并进行大量的优化和扩展,如增强HDFS扩展性、改进MapReduce调度算法、优化HBase查询性能以及兼容PL?SQL等.本节针对HDFS元数据服务瓶颈、MapReduce负载倾斜、HBase的跨域组织等关键问题,介绍在iSDA中采用的多元数据服务、负载均衡和跨数据中心大表技术.
2.1 HDFS多元数据服务
大数据环境下产生的数以亿计的非结构化数据对分布式文件系统的元数据服务器产生了巨大压力,单个元数据服务器已经无法很好地满足全系统的元数据访问.例如,GFS和HDFS都采用了单元数据服务器的方法,因此文件系统的元数据规模受限于元服务器的内存容量和处理速度.为此,元数据的服务能力也需要进行扩展,通过多元数据服务器的方法可以将系统的元数据压力分布到多台服务器上,降低元数据的访问延迟,提高元数据请求的服务速率,达到较好的元数据扩展能力.
为在多个服务器上提供元数据服务,最关键的是建立从文件系统命名空间到多个元数据服务器的映射,命名空间的划分和映射方法要具有自适应性和扩展性,即能够自动适应目录空间的增长,并将目录空间中的项均衡地分布到所有元数据服务器上.基本思想是使用某种动态Hash算法将每个目录划分成很多分片,再采用某种映射算法将每个目录分片映射到一台元数据服务器上,由该元数据服务器来负责该目录分片访问和存取.如图3所示,在文件系统中,建立全局目录表(global directionary table,GDT)的特殊数据结构,它是整个全局命名空间中所有目录组成的一张映射表,将目录名映射到其元数据所在的位置.
在iSDA中,目录分片到元数据服务器的映射采用2级映射机制:第1级是将目录分片映射到数量不可变的多个虚拟元数据服务器上,第2级是将虚拟元数据服务器映射到物理元数据服务器上.如图4所示,通过第1级映射,根据文件目录名唯一确定一个虚拟服务器;通过第2级映射,可以根据虚拟服务器唯一确定一个物理服务器.这种2级映射有较好的灵活性,使得映射机制可以适应物理服务器节点数的动态变化(失效或加入),并有利用调节物理节点上的负载以达到负载均衡.

Fig.3 Global directory mapping.图3 全局目录映射

Fig.4 Data structure of immediate results.图4 中间结果数据结构
在初始时,目录的所有分片会被映射到一台物理服务器上,随着负载的增加和目录规模的增大,其分片会更加均匀地分布到多个物理服务器上.同时,为了避免在目录规模增大时目录分裂引入过多的开销,通过一致性Hash方法使得目录分裂只局限在同一个节点上,以避免过多的服务器之间数据传输.当需要进行负载均衡时,通过改变第2级映射可以利用空闲的节点或者新加入的节点资源.关于多元数据服务器方法的详细介绍可参见前期工作[14].
2.2 Hadoop负载均衡
在Hadoop的MapReduce任务中,Map的输入来自HDFS,是相对静态的数据,每个Map任务接收到的数据是经过分片处理的,除最后一个Map任务,每个Map需要处理的数据量大致相等,因此,各个Map任务是均衡的,并且其大小是确定的.而Reduce任务和Map有所不同,它的输入是Map阶段的输出,是动态产生的数据.为保证相同关键字key的记录分派到同一个Reduce任务中处理,Map的输出数据进行分区Partition操作,每一条记录按照key值被映射到唯一的Reduce任务上.由于数据是动态产生的,只有在Map任务完成之后才能确定数据的大小和分布,因此,每个Reduce的任务量不可确定,数据映射到Reduce后也不能更改,从而有可能造成Reduce任务不均衡.
通过对大量Map任务输出的分析统计得出,数据不均衡的原因可总结为2类:
1)中间结果key分散,但经过映射,过多的key聚集在同一个Reduce任务中;
2)中间结果key虽然单一,但key对应的记录数量众多,一个Reduce要处理一个key的所有记录.
在iSDA中,为加速key的存取,中间结果采用Hash B树存储,如图4.其中,MapReduce中间结果[key,list(value)]用链表组织,具有相同Hash值的key在Hash表的同一项中用B树索引,list(value)存储在B树结点中.上述数据结构在各种负载类型下都具有很高的读写性能.如果key可预测并且具有唯一的Hash值,则可以为Hash表分配足够的项来避免冲突和B树查找,插入和查找都只有O(1)的复杂度.如果key没有唯一的Hash值或不可预测,插入和查找也只有O(log n)的复杂度.
基于Hash B树结构和式(4),可以根据Reduce节点的数量和处理能力划分中间结果.在负载均衡情况下,各节点处理速度相同,因此节点j所分配的历史数据规模为
pj∝μ×(σmj×(1-λ)+λ).(5)
基于上述模型,可以根据CPU速度、内存容量和I?O带宽计算出Reduce各节点的中间结果数据划分并构造路由表,在MapReduce的Partition阶段根据路由表进行分派,就能保障Reduce节点的负载均衡.由于上述算法需要预处理阶段采样,因此特别适用于循环或迭代进行的Hadoop任务.关于MapReduce负载均衡方法的详细介绍可参见前期工作[15].
2.3 HBase跨数据中心大表
基于HDFS的HBase在无共享集群架构上实现了面向海量半结构化数据的高并发处理环境,已被广泛接受并采用.由于地域和网络条件限制,当前很多政府、行业建设的数据中心采用2级架构,即在总部和分支机构分别部署HBase集群,1级数据中心可以访问2级数据中心的数据,而1级数据中心间也可以实现互访.例如,某省的交通卡口数据监控系统采用省、市2级部署方式,传统的处理方式要从全省范围内查找某车辆信息时,需要轮询各地的HBase确定是否存在该车的相关信息,然后根据在各个地市数据查询的结果汇总反馈,计算量较大,无法满足对响应速度的要求.为了跨越多个物理数据中心建立分布式大表,突破单一数据中心由于时空矛盾无法建立超大集群的限制,需要满足以下3个理论条件:
1)数据组织方式.跨数据中心形成一个逻辑大表需要将数据按指定的分区分布至不同的数据中心HBase集群中,当访问存放在本地数据中心的数据时,无任何跨域数据交换.
2)网络条件.在广域网环境下的远程数据中心访问时,要保障网络带宽足够大,能够支持跨域的大规模数据传输.
3)异步复制.在网络带宽不能保证的情况下,由于涉及开销较大的远程数据传输,对写操作延迟比较严格的应用,不适于跨数据中心的同步更新.根据CAP定律[16],可以通过牺牲一致性换取性能并容忍网络异常,即采用异步复制方式实现最终一致性.
针对上述3个问题,iSDA采用逻辑一体化、数据本地化和复制异步化技术实现HBase大表,如图5所示:
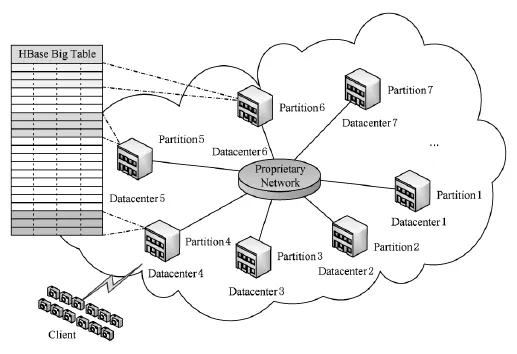
Fig.5 Structure of large table across domain.图5 跨越大表组织结构
1)逻辑一体化.建立一个基于HBase的跨域虚拟大表,每个数据中心独立运行HBase,保留其高性能、可靠、可扩展等特点;多数据中心间基于虚拟大表分配模式设定顶层数据区域划分,数据分配模式包括主键前缀、主键后缀、子字符串、正则表达式及自定义函数.顶层数据划分连同HBase的3级索引形成4级索引结构.由于顶层的索引规模较小并且不会经常性变动,因此在各个中心采用Paxos协议[17]进行同步,上层应用无需修改即可使用HBase标准API透明地访问虚拟大表,系统会自动将读写操作按指定的逻辑分布至相应的数据中心的HBase集群中执行.
2)数据本地化.指定区域位置进行数据存取,将数据优先导入本地数据中心.访问本地数据时,无任何跨数据中心数据交换,降低对广域网带宽要求.此外,基于HBase Coprocessor的分布式算法可通过在数据中心间分布并行实现高效全局数据统计汇总.
3)复制异步化.每个数据中心的HBase采用单独的HDFS实例进行数据存储,异地数据中心之间进行基于日志的数据备份.对于写操作性能要求较高的应用,可以将复制配置成异步方式,避免跨域数据中心间的同步操作.当源中心故障时可从备份中心读取数据,实现跨数据中心高可靠性.
3 验证和评价
本节以电信、金融、环保等行业实际案例中的业务应用、系统架构和测试数据来验证iSDA体系结构和关键技术的有效性,并通过与其他一体化方案进行对比进一步说明iSDA的软硬件优势.
3.1 可扩展性
验证项目1通过电信业务场景中的全库扫描案例来验证iSDA的可扩展性.全库扫描基于HDFS Scan基准测试实现,测试结果与数据节点数目以及具体配置相关.测试集群采用iSDA通用类型配置,2台控制服务器每台配置2颗6核Xeon E5-2650处理器、128GB内存、万兆网卡、内置2块2TB 7200RPM SATA盘;数据节点服务器每台配置2颗6核Xeon E5-2650处理器、48GB内存、万兆网卡、内置12块7200RPM 2TB SATA盘;集群内部采用2台64端口万兆交换机.每块硬盘数据量为500GB,单节点数据量约6TB,分别测试集群在不同节点规模下的扫描速度,测试结果如图6所示:
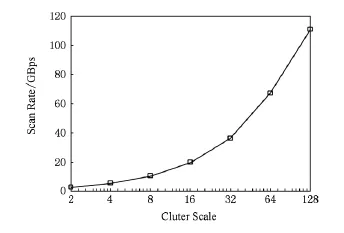
Fig.6 Scalability test results.图6 可扩展性测试结果
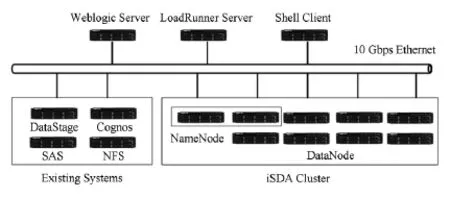
Fig.7 Topology of project 2.图7 验证项目2拓扑结构
由测试结果可知,一方面,iSDA由于集群节点采用了多核CPU和多通道外存架构设计,通过配置和优化HDFS对于多块硬盘的并行读写机制,能够提高单一节点的数据访问速度,单一节点的数据吞吐量可达1 500MBps;另一方面,iSDA集群的数据吞吐量随节点增加而增长,具有接近线性的扩展能力,在128个节点规模下数据吞吐量接近120 000MBps,相当于上千个Google高密度节点的处理能力[18].
3.2 高效性
在验证项目2中,某银行针对数据快速增长及业务现状,对iSDA进行了非常详细的测试与评估,其中包括10,20,40节点的应用功能测试、技术功能测试和并发场景测试等.项目采用的拓扑结构如图7所示,采用的通用型iSDA软硬件配置如表3和表4所示,部分应用案例说明如表5所示.在测试环境中,除iSDA集群外,WebLogic和LoadRunner服务器用来进行OLTP测试,Shell客户端用来进行批处理和日志分析等测试,已有系统中的各类服务器主要用来进行兼容性测试,下面分别介绍.

Table 3 Hardware of Project 2表3 验证项目2硬件配置

Table 4 Software of Project 2and Project 3表4 验证项目2,3软件环境
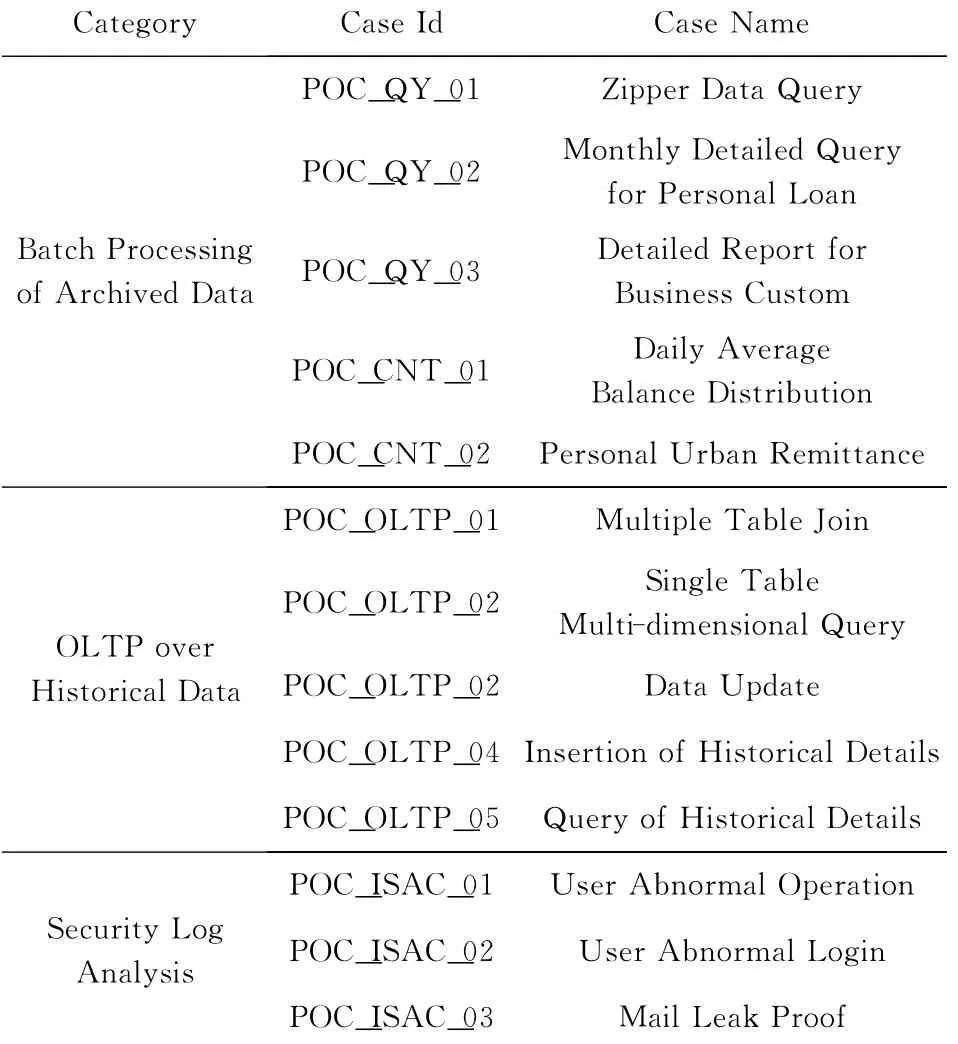
Table 5 Test Cases of Project 2表5 验证项目2测试案例
第1类测试为批处理,测试从已归档的100TB数据中获取信息以及加工计算的性能,10节点下的测试结果如图8所示.由图8可知,与原有生产系统相比,iSDA由于采用了分布式架构,在海量数据查询(POC_QY_02,POC_QY_03)方面优势明显,而在数据分析(POC_QY_01,POC_CNT_01)以及事务处理(POC_CNT_02)方面,iSDA由于兼顾了节点的性能纵向扩展,因此表现不弱于传统架构.

Fig.8 Batch processing test results.图8 批处理测试结果
第2类测试为在线联机事务处理OLTP,包括多表关联、多维查询以及数据更新、插入、查询等案例,数据量达到30TB,约50亿条.场景1是在20节点和40节点环境下分别进行多案例混合并发测试,其中TC_OLTP_03用户数占比40%(包括4个查询条件组合,各占10%),TC_OLTP_06占20%,其他各占10%,并发用户数为500,并发时间持续10min,考察处理成功率和TPS(transaction per second).在此基础上,场景2同时启动2个HBase的装载作业,分别是通过Hive向HBase表的装载和从HDFS文件到HBase表的装载.以2个装载作业作为背景,然后同时执行场景1.OLTP场景测试结果如表6所示:

Table 6 OLTP Test Results表6 OLTP测试结果
测试结果表明,iSDA的OLTP并发查询性能优秀,成功率可达到99.9%以上,TPS可达到3 500 times?s以上,并且由于采用了分布式架构,在带宽充足的情况下大规模数据的导入不会影响并发性能.而之所以扩展到40节点后TPS基本不变,是因为测试环境采用LoadRunner+Web服务方式,单点的Web服务器成为系统瓶颈.
第3类测试为日志分析,这一类应用是iSDA中的MapReduce比较擅长的,解决思路是通过对数据集进行切分,在Map阶段进行过滤、解析和分组路由,并通过Combine和中间结果压缩减少数据传输量,在Reduce阶段通过优化算法进行合并、统计、排序,测试结果表明iSDA能够填补现有系统在日志分析上的空白.
此外,验证项目2还进行了109项技术功能测试,涉及系统的可扩展性、可靠性、兼容性、易维护性、易开发性、开放性、扩展性和安全性,最终iSDA通过108项,仅不支持版本回退功能.
上述验证项目表明,iSDA的应用支持能力多样,系统性能优异,技术功能完善,完全能够满足金融行业大数据应用的需求.
3.3 跨域大表
据初步统计,目前某银行应用系统每年产生的历史日志数据已经超过1PB,如此大规模的数据如何实现跨地域的分布式存储、处理和查询是亟需解决的问题.测试项目3采用iSDA的跨集群HBase大表功能,在银行日志管理系统中进行了技术验证.测试方案的网络拓扑如图9所示,集群配置如表7所示.2个iSDA集群间通过万兆以太网连接网络,管理网络为千兆以太网,集群的软件配置如表4所示.

Fig .9 Topology of project3.图9 验证项目3网络拓扑
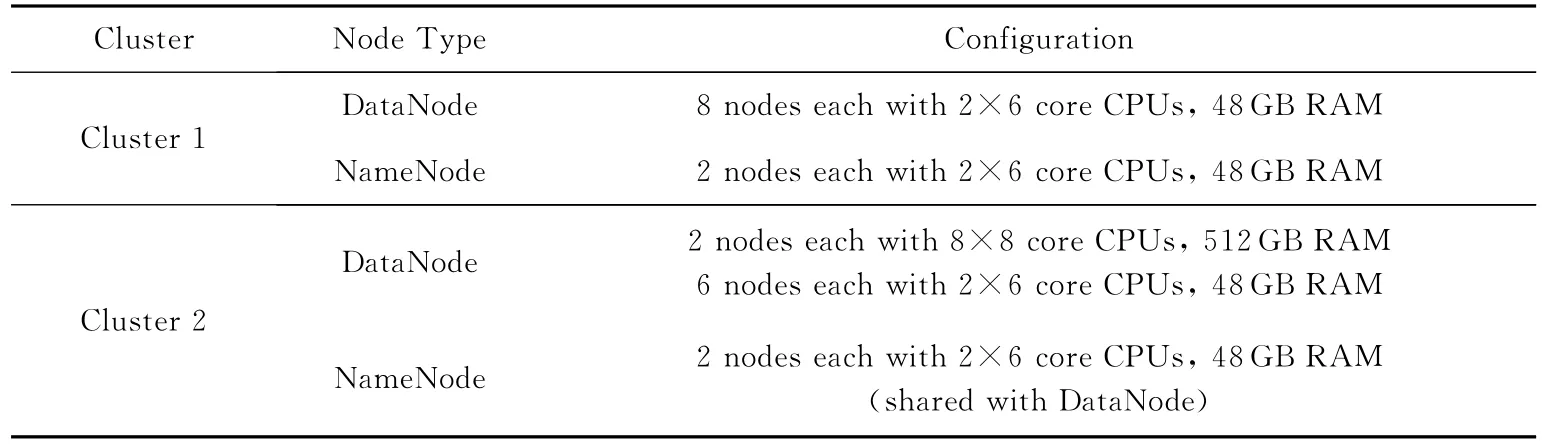
Table 7 Hardware of Project 3表7 验证项目3硬件配置

Table 8 Performance of HBase Big Table表8 HBase跨域大表性能
测试项目3采用LoadRunner+Web+HBase的方式,分别对日志系统的高并发读写性能进行了测试分析,数据量约100TB,134亿条.在100和500并发场景下,本地集群和跨集群的按关键字查询、按关键字删除、新增数据在成功率均为100%,性能测试结果如表8所示.
上述测试结果表明,iSDA可以实现跨集群的数据新增、删除以及查询功能,在万兆网络条件下性能与本地集群一样优异.上述方案的优势在于基于分布式架构的HBase大表可以充分利用集群中所有的存储资源,在高并发处理时调度所有的硬件资源进行读写访问,很容易就实现每秒数万条数据的实时写入、查询和删除,并且读写性能和已有的数据量基本没有关系,在数据量很大(例如大于10TB)的情况下,仍然可以实现高效的写入和查询,读写延迟可以控制在毫秒级.同时,HBase大表有很好的水平扩展性,当服务器数量增加时,读写吞吐量也会线性提高.此外,HBase大表的数据分布在多个数据中心,单个数据中心出现网络等故障时不会影响其他数据中心的数据访问,保证应用系统的整体可用性.
3.4 多样性应用
验证项目4通过在环保领域的应用示例介绍iSDA如何满足行业大数据应用的多样性需求.
根据定义6,环保行业流处理应用场景的iSDA执行过程如图10(a)所示,可以实现污染源(污水、供热)和大气污染物(二氧化硫、氮氧化物、烟粉尘等)的实时监测、异常报警,以及违规车辆(外埠、黄标等)的实时监控等应用.
根据定义4,环保行业交互处理应用场景的iSDA执行过程如图10(b)所示,可以实现污染源、大气污染物以及建筑工地(数量、扬尘指标)的历史曲线展示、多维度统计、对比分析等应用.
根据定义3,环保行业在线实时处理应用场景的iSDA执行过程如图10(c)所示,可以实现基于地理位置的气象信息查询、大气信息预警,以及区域、时间等多维度环境统计报表等应用.
根据定义5,环保行业交互处理应用场景的iSDA执行过程如图10(d)所示,可以实现基于污染源、气象、大气历史数据的趋势预测,综合污染源、气象、大气、工地、车辆数据的空气质量关联分析和决策分析等应用.
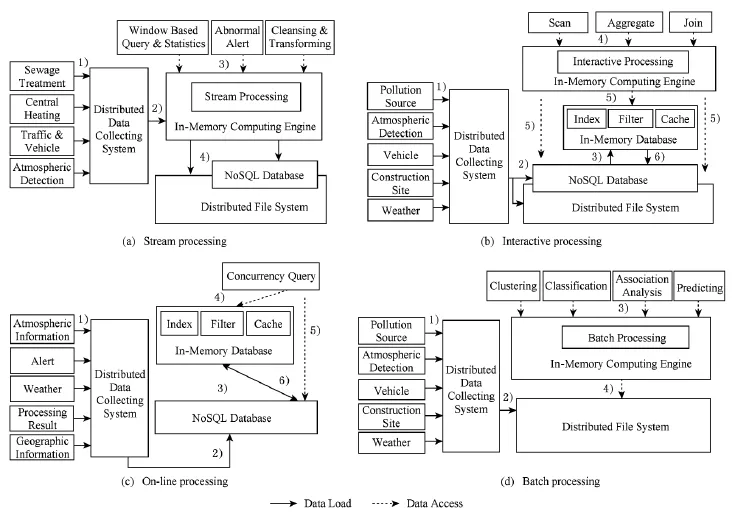
Fig.10 Multi-type processing.图10 多样性处理过程
上述应用示例表明,基于混合型软件架构的iSDA能够满足行业大数据的在线实时处理、交互分析、离线批处理以及流处理等多样性应用需求,并且通过内算计算引擎加速,能够将大数据处理性能提高10倍以上,通过一体化管理平台,能够保障系统的易用性、可靠性及可扩展性.
3.5 对比分析
与传统RDBS关系数据库、MPP数据库的一体化解决方案相比(如表9所示),iSDA在性能和可扩展性方面优势明显,但在管理工具、SQL接口支持程度、ETL?BI等上下游软件工具兼容性方面尚有差距.
与基于Cloudera,Hortonworks等Hadoop发行版的一体机相比(如表10所示),除了在可用性、安全性和可管理性上全面看齐这些主流大数据平台之外,可扩展性和可定制化设计使得iSDA在硬件特性上更具有优势,混合软件栈和多样性处理模型使得iSDA能够应对的应用类型更为丰富,广泛采用的内存计算优化使得iSDA处理性能大幅提升.

Table 9 Comparison with Traditional Database Integration Solutions表9 与传统数据库一体化解决方案比较
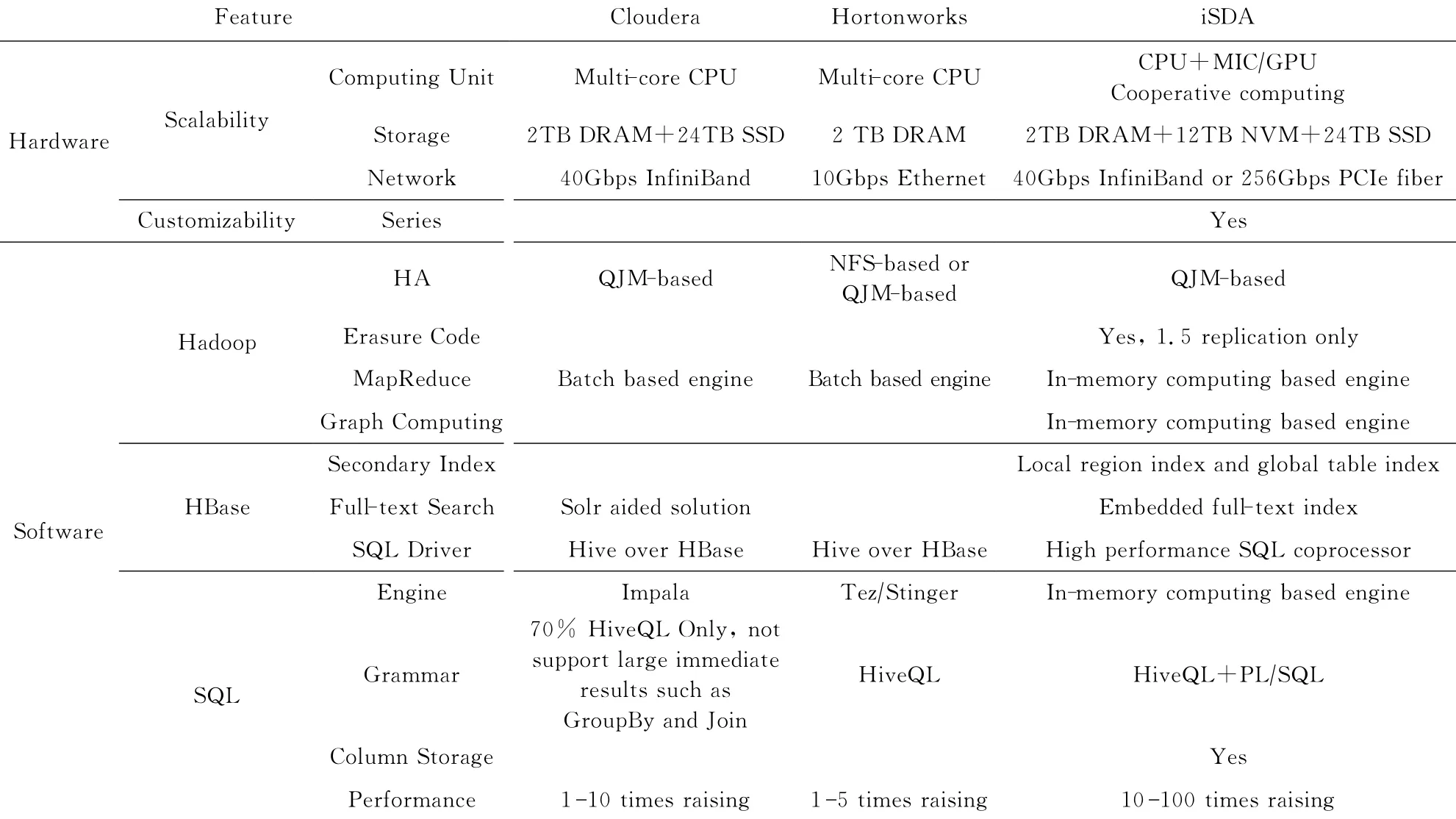
Table 10 Comparison with Hadoop Integration Solutions表10 与Hadoop 一体化解决方案比较
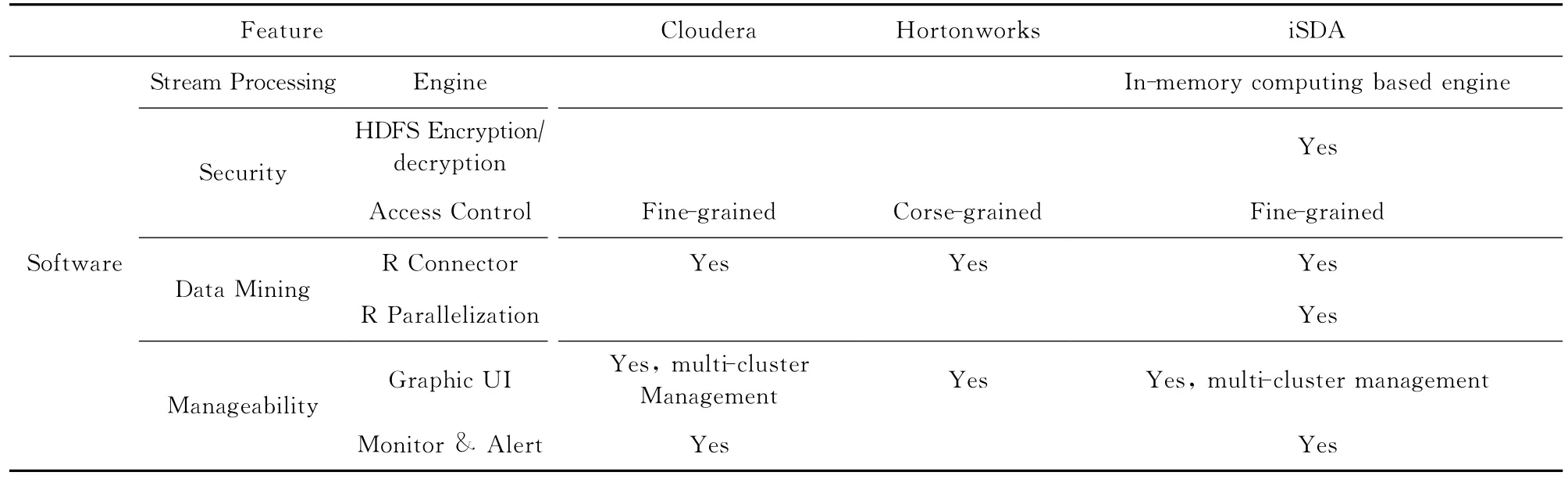
Continued(Table 10)
4 结束语
本文针对当前行业大数据应用对处理平台的需求,给出了大数据一体机可扩展性和可定制性的理论基础,建立了面向实时、交互、流式和批式等应用类型的多样性处理模型,并基于此设计和实现了云海大数据一体机iSDA.iSDA基于双向可扩展的体系结构,采用可定制化设计和混合软件栈,覆盖软硬一体全环节,满足行业应用的持续扩展、个性化和一体化需求.在电信、金融和环保实际案例中的应用和测试表明,iSDA体系结构和关键技术是可行和有效性的.下一步的工作是基于iSDA建立完善的大数据解决方案,针对数据处理的各个环节提供全程技术支持与保障,帮助行业用户明确业务需求,选择合适的软硬件架构,解决环境部署、应用移植、二次开发、调优上线、运行维护等技术难题,帮助用户跨过大数据应用的门槛.
[1]CCF Task Force on Big Data.2013White paper of China s big data technology and industrial development[EB?OL].2013[2014-08-01].http:??www.bigdataforum.org.cn? uploads?soft?131230?2013writepaper.pdf(in Chinese)(CCF大数据专家委员会.2013中国大数据技术与产业发展白皮书[EB?OL].2013[2014-08-01].http:??www.bigdataforum.org.cn?uploads?soft?131230?2013writepaper.pdf)
[2]Chinese Institute of Engineering Development Strategies.2014Report on the Development of China s Strategic Emerging Industries[M].Beijing:Science Press,2014:101 112(in Chinese)(中国工程科技发展战略研究院.2014中国战略性新兴产业发展报告[M].北京:科学出版社,2014:101 112)
[3]Ranger C,Raghuraman R,Penmetsa A,et al.Evaluating MapReduce for multi-core and multiprocessor systems[C]?? Proc of the 13th Int Conf on High-Performance Computer Architecture.Los Alamitos,CA:IEEE Computer Society,2007:13 24
[4]International Data Corporation.2013 10ICT market forecast of the Asia Pacific region[EB?OL].2012[2014-08-01].http:??www.idc.com.cn?prodserv?detail.jsp?id=NTA3(in Chinese)(国际数据公司.2013年亚太区ICT市场十大预测[EB?OL].2012[2014-08-01].http:??www.idc.com.cn?prodserv? detail.jsp?id=NTA3)
[5]O Reilly Radar Team.Big Data Now:Current Perspectives from O Reilly Radar 2013Edition[M].Sebastopol,CA:O Reilly Media,2013
[6]Gustafson J L.Reevaluating Amdahl s law[J].Communications of the ACM,1988,31(5):532 533
[7]Li Wubin,Zhao Zhuofeng,Qi Kaiyuan,et al.A consistencypreserving mechanism for Web services response caching[C]??Proc of the 20th Int Conf on Web Services.Los Alamitos,CA:IEEE Computer Society,2008:683 690
[8]Inspur Electronic Information Industry Co Ltd,Department of System Software.The white paper of in-cloud big data appliance[R].Jinan:Inspur Electronic Information Industry Co Ltd,2013(in Chinese)(浪潮电子信息产业股份有限公司系统软件部.云海大数据一体机技术白皮书[R].济南:浪潮电子信息产业股份有限公司,2013)
[9]Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107 113
[10]Chang F,Dean J,Ghemawat S,et al.Bigtable:A distributed storage system for structured data[C]??Proc of the 7th Symp on Operating Systems Design and Implementation.Berkeley,CA:USENIX Association,2006:205 218
[11]Zaharia M,Chowdhury N M,Franklin M,et al.Spark:Cluster computing with working sets[C]??Proc of the 2nd USENIX Conf on Hot Topics in Cloud Computing.Berkeley,CA:USENIX Association,2010:1 10
[12]Neumeyer L,Robbins L,Nair A,et al.S4:Distributed stream computing platform[C]??Proc of the 10th IEEE Int Conf on Data Mining Workshops.Los Alamitos,CA:IEEE Computer Society,2010:170 177
[13]Wang Endong,Zhang Qing,Shen Bo,et al.MIC High Performance Computing Programming Guide[M].Beijing:China Water &Power Press,2012(in Chinese)(王恩东,张清,沈铂,等.MIC高性能计算编程指南[M].北京:中国水利水电出版社,2012)
[14]Wang Youwei,Zhou Jiang,Wang Weiping,et al.Clover:A distributed file system of expandable metadata service derived from HDFS[C]??Proc of the 2012Int Conf on Cluster Computing.Los Alamitos,CA:IEEE Computer Society,2012:126 134
[15]Qi Kaiyuan,Han Yanbo,Zhao Zhuofeng,et al.Real-time data stream processing and key techniques oriented to largescale sensor data[J].Computer Integrated Manufacturing System,2013,19(3):641 653(in Chinese)(亓开元,韩燕波,赵卓峰,等.面向大规模感知数据的实时数据流处理方法及关键技术[J].计算机集成制造系统,2013,19(3):641 653)
[16]Gilbert S,Lynch N.Brewer s conjecture and the feasibility of consistent,available,partition-tolerant Web services[J].ACM SIGACT News,2002,33(2):51 59
[17]Lamport L.Paxos made simple[J].ACM SIGACT News,2001,32(4):18 25
[18]Melnik S,Gubarev A,Long J J,et al.Dremel:Interactive analysis of web-scale datasets[J].Communications of the ACM,2011,54(6):114 123

Zhang Dong,born in 1974.Researcher.Member of China Computer Federation.His current research interests include computer architectures,big data and operation systems,etc.

Qi Kaiyuan,born in 1984.PhD and engineer.Member of China Computer Federation.His current research interests include big data processing and cloud computing.

Wu Nan,born in 1982.Senior engineer.His current research interests include operating systems and big data processing.

Xin Guomao,born in 1981.Senior engineer.His current research interests include cloud computing,and big data processing systems and applications.

Liu Zhengwei,born in 1977.Senior engineer.His current research interests include cloud operating systems and big data storage systems.

Yan Bingheng,born in 1982.PhD and senior engineer.His current research interests include computer architectures and virtualization.

Guo Feng,born in 1982.Engineer.His current research interests include cloud operating systems and information security.
Architecture and Key Technologies of In-Cloud Smart Data Appliance
Zhang Dong,Qi Kaiyuan,Wu Nan,Xin Guomao,Liu Zhengwei,Yan Bingheng,and Guo Feng
(State Key Laboratory of High-End Server &Storage Technology,Jinan250101)(Inspur Electronic Information Industry Co.,Ltd.,Jinan250101)
To make up for the gap between big data technologies and industry applications,this paper proposes the models of scalability,customizability and multi-type processing of big data appliance,based on which the in-cloud smart data appliance,i.e.iSDA,is designed and implemented.First,the iSDA is assembled by optimally developing the cooperative computing units,heterogeneous storage and high-speed switching network to take fully advantages of both scale-out and scale-up architectures.Second,iSDA is devised to satisfy diversity requirements of industry big data applications by virtue of hardware customization from light-weight to heavy-load styles,and as well as hybrid software stack including real-time,interaction,streaming and batch processing all accelerated by the in-memory computing engine.Furthermore,in the consideration of the HDFS metadata service bottleneck,MapReduce load skew and HBase cross-domain issue,this paper as well introduces the technologies of multiple metadata servers,load balance algorithm and cross-datacenter big table used in iSDA.The practical use cases in the telecommunication,finance and environmental protection industries show that the proposed architecture and key technologies are feasible and effective,and the comprehensive comparisons with traditional MPP databases and other mainstream Hadoop distributions are also given to detail the advantages of iSDA from both hardware and software aspects.Key words big data appliance;scalability;customizability;hybrid software stack;big data industrial application
TP311.133.1;TP338.6
2014-11-24;
2015-02-28
国家“八六三”高技术研究发展计划基金项目(2015AA050203);“核高基”国家科技重大专项(2013ZX01039002)This work was supported by the National High Technology Research and Development Program of China(863Program)(2015AA050203)and the Core Electronic Devices,High-End Generic Chips and Basic Software of National Science and Technology Major Projects of China(2013ZX01039002).
亓开元(qiky@inspur.com)
关键词 大数据一体机;可扩展性;可定制性;混合型软件架构;大数据行业应用
猜你喜欢
电子技术与软件工程(2017年21期)2018-01-18 13:00:44
电脑知识与技术(2017年31期)2017-12-11 13:34:11
现代电子技术(2017年17期)2017-09-08 07:58:25
汽车零部件(2017年3期)2017-07-12 17:03:58
自动化博览(2017年2期)2017-06-05 11:40:39
电脑知识与技术(2016年34期)2017-04-15 11:46:50
电脑知识与技术(2016年14期)2016-06-30 20:29:18
现代工业经济和信息化(2016年12期)2016-05-17 05:38:00
中兴通讯技术(2016年2期)2016-03-24 00:16:48
软件导刊(2015年4期)2015-04-30 13:25:21
