
一种并行计算机互连网络中的地址转换Cache
2016-07-31 23:32:23张建民黎铁军李思昆
计算机研究与发展 2016年2期
张建民 黎铁军 李思昆
(国防科学技术大学计算机学院 长沙 410073)(jmzhang@nudt.edu.cn)
一种并行计算机互连网络中的地址转换Cache
张建民 黎铁军 李思昆
(国防科学技术大学计算机学院 长沙 410073)(jmzhang@nudt.edu.cn)
当前在大规模并行计算机中,多数并行程序的用户习惯于使用虚拟地址进行编程.因此,虚拟地址与物理地址之间的转换效率直接影响了并行程序的执行性能,而cache能够有效地提高虚实地址转换的效率并降低延迟.提出了一种在大规模并行计算机互连网络中的地址转换cache.它采用了嵌入式DRAM(embedded dynamic random access memory,eDRAM)存储器,容纳更多的地址转换表项,从而提高命中率.并设计一种eDRAM刷新机制,隐藏了刷新操作,避免刷新导致的性能损失.ATC(address translation cache)中实现了诸如纠错码与旁路机制等多种可靠性设计.在32个计算结点上运行业界公认的NPB测试程序,结果显示32个结点中ATC的平均命中率达到了95.3%,表明ATC设计的正确性与高性能.并且通过与3种传统SRAM(static random access memory)实现的cache进行对比实验,说明了cache容量是提高命中率的关键因素.
并行计算机;互连网络;虚拟地址;物理地址;地址转换cache
当前高性能大规模并行计算机通常包含成千上万个计算结点[1].结点数目众多以及大规模并行性的需求,使得互连网络的设计变得十分困难.对于多数并行程序来说,要求互连网络必须具备高带宽与低延迟的特性[2-3].因此,在大规模并行计算机中,设计实现了网络接口芯片(network interface chip,NIC)[4],以满足互连网络高带宽、低延迟的特点.而在并行应用程序中,大多数用户习惯于使用虚拟地址编程,因为使用虚拟地址编程既简单高效又易于保证程序的正确性.那么,在互连网络中传输的报文几乎都要进行虚拟地址到物理地址的转换,使得在程序运行过程中,存在大量的虚实地址转换操作,因此虚实地址转换的效率直接影响了互连网络的通信带宽与程序的执行性能[5-6].
有学者在CASES2013会议上提出了一种优化DRAM(dynamic random access memory)cache的命中延迟和失效率的方法[7],它通过一种全新的组映射策略,同时兼顾减小命中延迟和失效率.在16核的微处理器中,与经典映射策略相比,该方法能够降低29.3%的命中延迟,并且减少12.1%的失效率.而针对DRAM cache的访问带宽与访问冲突的问题,学者们在CODES+ISSS2013会议上提出了一种自适应存储体映射策略[8],以应对不同类型应用的各种cache访问模式.通过实验表明,与传统的存储体映射策略相比,本文的方法能够增加平均19.3%的吞吐率,最大可达到71%.当前多核处理器中存在SRAM(static random access memory)与DRAM cache混合使用的体系结构,其中私有L1与L2cache使用SRAM存储器,而共享L3和L4 cache采用DRAM存储器,学者们在DAC2014会议上针对大容量DRAM cache普遍存在的Tag查找的高延迟问题,提出了一种SRAM?DRAM混合Tag cache的结构[9],用于判别是否命中L3?L4cache.在一个16核处理器中,与经典结构相比,每周期的平均指令吞吐率能够提高13.3%.但是,当前业界绝大多数DRAM cache都是应用于多核微处理器中的共享L3和L4cache中,还没有人将其应用于并行计算机的互联?接口芯片中;另外,SRAM? DRAM混合结构的cache也存在设计复杂、实现代价较高的问题.
基于上述原因,在NIC芯片中设计实现了一种大容量、高性能的地址转换cache(address translation cache,ATC).ATC用于保存地址转换表(address translation table,ATT)项,并根据虚拟地址访问ATC得到相应的物理地址.为了尽量避免访问外存,从而减小访问延迟,就必须提高命中率,因此ATC共计可容纳100万项地址转换表.但由于容量巨大,如果使用SRAM实现存储体,那么芯片的设计实现将会变得极其困难.所以,ATC采用了嵌入式DRAM(embedded dynamic random access memory,eDRAM)存储器,eDRAM具有面积小、功耗低以及错误率低的特性.但eDRAM需要定期刷新,会影响读写的效率,因此在ATC中设计了一种eDRAM刷新机制,在读写操作的空闲周期进行刷新操作,从而达到将刷新操作隐藏的目的.同时为了提高访问带宽,在ATC中实现了非阻塞的深度流水线.另外,在ATC中还实现了多种可靠性设计,包括关键存储器的纠错码保护与旁路机制等.为了验证ATC的性能,构建了一个由32个计算结点组成的并行计算实验机架.通过运行业界公认且具有代表性的NPB测试程序,得到了32个结点中NIC芯片的命中率.结果显示,32个结点中ATC的平均命中率高达95.3%,表明了ATC设计的正确性以及高性能.并且设计实现了3种传统cache[10-11]并与本文提出的设计进行对比实验;由于传统cache采用SRAM实现,受限于面积无法实现更大的容量,因此本文ATC的平均命中率大大高于传统cache.
1 地址转换Cache的体系结构
地址转换cache的主要功能是保存地址转换表,并完成地址转换表的读写访问控制.所谓地址转换表就是指物理地址.由于互连网络接口芯片中每个发送或接收的报文都需要根据虚地址获取物理地址,因此需要频繁地访问远端存储器,其延迟非常大.为了减小系统处理报文的停顿以及地址转换表访问的延迟,NIC内设计实现了了ATT cache.ATT cache用于保存最近经常使用的ATT项,容量达到39Mb.由于ATT cache的容量小于远端存储器的容量,不可能保存所有的ATT项;因此,当报文需要的ATT项在ATT cache中没有命中时,则需要访问外部存储器以获得地址转换表.
ATC的容量为39Mb,映射方式为8路组相联.每个cache行包含8个ATT项,而每个ATT项包括32b的物理地址及其7b纠错码(error correcting code,ECC),那么每个cache行共计312b.ATC的每路共计16 384行,由于ATC的容量很大,因此采用了嵌入式DRAM存储器实现ATC的存储体.通常来讲,同样容量的eDRAM的面积仅是SRAM面积的1?3~1?2,功耗为后者的1?10~1?2.ATC的替换算法采用最近最少使用(least recently used,LRU)算法,以满足芯片提高性能的需求.ATC的设计采用非阻塞的工作方式,即前一个未完成的访问操作不会阻塞后续访问的执行.为了支持非阻塞访问,ATC设置了失效缓冲器,用于记录失效的报文地址.图1给出了ATC的体系结构和外部接口:
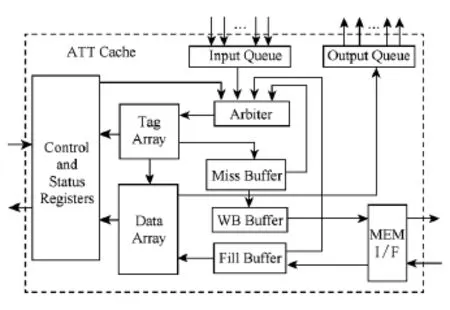
Fig.1 Architecture and interface of ATC.图1 ATC的体系结构与接口
如图1所示,ATT cache包含10个主要的模块.其中输入队列接收来自外部的请求报文,加入请求源信息,存入对应的FIFO;多个请求之间采用Round-robin仲裁策略,而后从获得授权的FIFO顶端中读出请求,发往仲裁器模块;以流水的方式操作,每个周期都可以同时接收所有请求源发送1个访问请求.而输出队列接收从数据阵列中读出的1个39b的项,而后进行ECC校验,得到32bATT项连同是否含ECC不可纠错信号,根据请求源信息,返回对应的请求源.优先级仲裁器的请求源共有4个,分别为失效引擎、输入队列、失效缓冲器和Fill缓冲器,采用优先级仲裁方式,发往Tag阵列模块.ATC Tag阵列中包含8个深度为16 384、宽度为14b的Tag阵列存储器,由SRAM实现,保存Tag信息,其中包含有效位、Tag及其ECC纠错码,该模块还包含最近最少使用LRU替换策略和相应的Tag控制逻辑.
ATC数据阵列用于存储ATC中的ATT数据,由cache体数据阵列存储器及其相应的控制模块和接口模块构成,存储体由8个深度为16 384、宽度为312b的eDRAM存储器构成.失效缓冲器包含一个SRAM实现的缓冲器,用于保存没有在Tag阵列命中的访问报文;待所需的ATT数据通过访存接口返回时,再将这些失效报文重新发射.Fill缓冲器用于保存从外部读入的ATT数据,访存的粒度为256b,每次读操作都会载入8个32b的ATT项,将其进行ECC校验,保存在一个SRAM实现的FIFO中,而后发往数据阵列,同时向仲裁器发出请求报文.写回缓冲器主要是完成ATC访存请求的缓冲与转换,由一个SRAM存储器实现的FIFO以及相应的控制模块与接口模块构成.访存接口模块完成与远端存储器之间的数据交换,主要进行组包与拆包的工作,同时发出相应的控制信号.控制与状态寄存器设置了一组寄存器,用于保存发送到ATC的控制信息以及来自ATC的状态信息.在该模块内还实现了一个失效引擎,用于控制ATC中失效ATT项的操作.
2 Tag与数据阵列的实现
Tag与数据阵列模块是ATC中最重要的2个部件.下面详细介绍Tag阵列与数据阵列模块.所谓Tag是指地址位域的一部分.由于ATC采用了8路组相联的映像策略,因此Tag存储阵列由8个深度为16 384、宽度为14b的SRAM存储器构成,其中14b的Tag项包括8b的Tag及其5b的ECC校验位以及1b的有效位.每组中的每路均有1个有效位,标识当前的cache行是否有效.
ATT cache中采用最近最少使用LRU替换策略,选择8路中的某一路被替换出去.在ATT cache中有每组有28个Used位,分别表示8路之间任意2路之间的相互关系.这些信息保存在64个深度为256、宽度为28b的Used阵列中.当有访问ATC的操作命中cache的时候,修改该路与其他7路之间的相互关系,即修改对应行的Used位.
下面给出Tag阵列与数据阵列之间的逻辑结构,以及与ATT地址之间的对应关系,如图2所示.

Fig.2 Structure of tag array and data array.图2 Tag和数据阵列的逻辑结构
根据图2,Tag阵列控制器的工作流程如下:
1)当接收到来自输入队列模块的请求报文时,包括读ID、访问地址等位域,从中解析出25b的地址,其中?16:3?位为索引(index),用于Tag阵列的寻址.
2)根据index,分别从8个SRAM存储器中读出8个Tag数据,按照有效位的标识,8个Tag数据中有效位为1的、同时与请求地址中的?24:17?位,即Tag,进行判等比较.
3)如果存在匹配项,表明当前请求报文命中Tag阵列,那么ATT数据阵列中存在该请求要读写的ATT,发送地址、命中路编号、读ID等信号到数据阵列模块;此时,若当前是失效操作,需要清除被命中Tag项的有效位,若是读操作,则需要将对应的有效位置1.
4)如果不存在匹配项,表明当前请求报文失效,那么数据阵列中没有要访问的ATT,需要从远端主存中载入,于是向访存接口模块发出读请求,同时将失效报文发送至失效缓冲器中保存.当Tag失效时,需要写入新的Tag,这时存在2种情况:①8路的有效位不全为1,那么就将请求报文的8bTag及其状态位写入有效位为0的路;②8路的有效位全为1,这时需要将其中1路替换,根据LRU算法,查询Used位阵列,得到最近最少使用的一路,而后将Tag写入该路,将其覆盖.
ATT数据阵列是保存ATT内容的存储阵列,以cache行作为单位进行组织,即每个存储单元就是1个cache行.每次读操作的粒度都固定为256b,也就是1个cache行,为8个32b的ATT项.而每个32b的ATT项都采用7b的纠一检二ECC校验码保护,那么每个cache行实际上有8×(32+7)=312b.由于数据阵列中保存100万个ATT项,因此总容量为39Mb.而如此大容量的存储器如果采用SRAM实现,耗费大量的面积与功耗,成本也会显著增加,所以在实现时使用eDRAM存储器.但eDRAM存储器的缺点是需要定期刷新存储单元,并且刷新可能会降低读写效率.因此设计了一种刷新机制,能够尽量在读写的空闲周期进行刷新操作,从而隐藏刷新操作.由于ATC是8路组相联,因此ATT数据阵列是由8个存储器构成,那么每个eDRAM存储器的容量为4.875Mb,其深度为16 384,宽度为312b,如图2所示.
ATT数据阵列处理2类请求:来自Tag阵列的读命中请求与来自Fill缓冲器的写请求.当接收到来自Tag阵列的读ATT请求时,且读请求命中Tag,那么就根据接收的地址与命中路,即请求报文所匹配的Tag阵列中的同一深度、同一路,从数据阵列中读出对应的cache行,而后根据访问ATT地址的?2:0?位,即Offset,从312b的cache行中取出相应的39bATT,其中包含了ECC信息,连同接收到的读ID信息,发送到输出缓冲区.当接收到来自Fill缓冲器的写ATT请求时,根据Fill缓冲器发出的地址,以及Tag控制器指示的空闲路,将312b的cache行写入ATT数据阵列的对应位置.
3 ATT Cache的可靠性设计
通常来讲,由高能粒子轰击和噪声干扰引发的晶体管瞬时充放电,改变电路的内部状态而导致的错误,称为软错误(soft error rate,SER).随着集成电路制造工艺的不断进步,VLSI芯片对高能粒子和噪声干扰的敏感性不断提高,这将使芯片面临越来越严重的软错误威胁,对集成电路的容错性和可靠性设计提出了更高的要求.当前在VLSI芯片中,各种存储单元尤其是cache占据了芯片面积的40%~70%,是芯片中对高能粒子最为敏感的部分.芯片发生的各种软错误故障,绝大部分来自于各种存储单元,尤其是cache.因此目前高可靠集成电路芯片大多都要针对cache进行专门保护.地址转换cache实现了3种可靠性设计:1)采用软错误率更低的eDRAM存储器;2)在Tag和数据等大容量存储体中加入了纠错编码ECC;3)设计实现了一种高效的ATT访问旁路模块.
一般来讲,eDRAM的SER率远远低于SRAM存储器,约为后者的1?250,因此在ATC中采用eDRAM实现数据阵列模块的存储体.ECC是一种常见的纠错编码,Tag和数据阵列中都采用的是经典ECC算法,实现了纠一检二功能.所谓纠一检二是指:如果在原始数据与校验码中有1b发生错误,那么该算法能自动纠正这1b错;如果在原始数据与校验码中存在2b错,那么该算法能100%检测出该错误.Tag阵列中是由8b原始数据产生5bECC校验码,而数据阵列中是由32b原始数据生成7b ECC校验码.
为了提高系统的鲁棒性和容错性,还设计实现了一个ATT访问旁路模块(ATT bypass path,ABP).如果Tag阵列或数据存储体都由于电磁辐射等原因出现不可恢复的错误,导致Tag或数据阵列无法正常工作,就通过旁路模块进行访问ATT的操作.由于ABP实现简单,逻辑较少,并且不包含存储器,因此不易受到电磁辐射的干扰,可靠性较高.ABP采用阻塞的方式处理请求报文,主要通过1个有限状态机来处理请求报文.该状态机包括5个状态:IDLE,READ0,READ1,WRITE0,WRITE1,如图3所示.
ABP状态机的各状态之间的转换过程为:
1)IDLE.初始状态为IDLE,如果检测到有请求报文到达时,转换为访存接口信号,向外部的存储控制器发出读请求,下一状态转换到READ0;否则继续在当前IDLE状态循环.
2)READ0.如果存储控制器没有返回数据,则在READ0状态循环,直至接收到读返回报文;根据请求报文的访问类型,判断当前是读操作还是写操作,若为读操作,下一状态到达READ1,若为写操作,转换到WRITE0.
3)READ1.根据读请求报文中地址域的最低3b,从返回报文中的256bATT数据(1个cache行)中,选择相应的32bATT项,构成读返回报文,发送到对应的请求源,转IDLE状态.
4)WRITE0.根据写请求报文中地址域的最低3b,将待写入的32bATT项覆盖读返回报文的256b数据中的相应ATT项,重新构成1个cache行数据,下一状态到达WRITE1.

Fig.3 FSM states transition of ABP.图3 ABP的状态转换图

Fig.4 Topology of 32Compute nodes.图4 32个计算结点的拓扑结构
5)WRITE1.将新组成的cache行数据,构成访存报文,转换为访存接口信号,写入到外部主存中,而后下一状态返回到IDLE.
4 实验结果与分析
为了评估高性能并行计算机互联网络中地址转换cache的性能,构建了一个由32个计算结点构成的并行计算实验机架,其拓扑结构如图4所示.每个计算结点包含2个高性能多核微处理器、1个硬盘、1个NIC芯片与DDR3主存.其中NIC芯片通过FPGA芯片实现,采用了Xilinx Virtex-7系列的XC7V2000T器件,便于进行仿真验证与性能对比评测.2个结点之间通过全交叉互连的光纤网络连接,也就是任意2个结点之间都有直接的物理通路进行通信.
NPB(NAS parallel benchmarks)[12-13]是广泛使用的并行计算机的测试基准程序.与Linkpack程序主要测试浮点计算性能不同,NPB的目的在于测试用户在并行计算机上运行实际应用程序的性能,综合评估计算与通信的性能.NPB测试程序所采用的算法在很多领域得到应用,能够很好地代表一般应用程序的实际性能.NPB根据测试程序规模可以分为A,B,C,D共4级.其中D级测试程序规模最大,通常运行时间也最长,能够更加客观地反映程序运行的实际性能.因此我们将NPB的D级题在32个全互连的计算结点上运行,评测地址转换cache的性能.通常对于cache来说,命中率是其最重要的性能指标,当前出现的大部分cache优化技术都是以提高命中率为目标的.表1给出了NPB的D级题运行结束后32个结点的NIC芯片中地址转换cache cache的命中率.表1中的第1列给出了结点编号;第2列表示在ATC中命中的报文个数;第3列表示各请求源发送到ATC中请求报文的总数;最后1列为命中率=命中数?请求数×100%.
从表1可以看出,对于所有32个计算结点,本文的地址转换cache的命中率都很高,为94.8%~96.1%.32个结点的平均命中率为95.3%.从NPB测试程序的代表性来看,对于大多数程序,无论是侧重于计算,还是侧重于通信,或者是计算与通信的平衡,ATC都能达到较高的命中率.这主要得益于2点:1)ATC的容量很大,达到39Mb,能容纳高达100万项地址转换表,并且采用eDRAM存储器,大大减小了所占用的面积,避免了SRAM实现导致的空间爆炸问题,使得芯片的实现成为可能.2)采用了非阻塞的深度流水线,大大提高了处理请求的吞吐率,并且针对eDRAM的刷新操作可能降低读写效率的问题,设计了一种刷新机制,尽量在读写操作的空闲周期进行刷新操作,从而隐藏刷新操作,显著降低了刷新操作带来的负面作用.
为了验证本文cache的效率,设计实现了3种容量不同的传统cache设计[10-11],进行对比实验.其中3种cache的容量分别为4.875Mb,9.75Mb,19.5Mb,采用了传统的SRAM实现cache存储体,每行的宽度都相同,为312b,仅是深度分别变为2048,4096,8192;同样采用8路组相联与LRU替换策略.由于32结点并行计算实验机架中,NIC芯片采用FPGA芯片实现,可以下载不同的设计,因此,将3种传统cache设计分别集成在NIC芯片中,进行性能对比与评测.表2给出了运行NPB程序D级题结束后32个结点中4种地址转换cache的命中率.其中第2列给出了容量为4.875Mb cache的命中率,其平均命中率为67.0%;第3列是容量为9.75Mb cache的命中率,平均命中率为72.9%;第4列代表了容量为19.5Mb cache的命中率,其平均命中率达到了81.1%;而最后1列是本文设计的39Mb cache的命中率,其平均命中率为95.3%.
由于同样容量的eDRAM的面积仅是SRAM面积的1?3~1?2,因此在同样的芯片面积下,使用SRAM实现cache最多只能达到19.5Mb,而采用eDRAM可以很容易实现39Mb甚至更大容量的cache.但是SRAM的读写访问逻辑简单、易实现,也不用考虑刷新的问题,因此读写效率比eDRAM略高.但本文设计的cache,提出了一种高效的刷新机制,在读写访问的空闲周期进行刷新操作,尽量隐藏额外的刷新操作带来的带宽损耗;再加上同样芯片面积下,eDRAM能够实现容量为39Mb的cache,因此本文设计的cache的平均命中率达到95.3%,大大高于其他3种传统cache设计的命中率.而其他3种cache设计中,主要由于容量的因素,19.5Mb>9.75Mb>4.875Mb,因此平均命中率也是81.1%>72.9%>67.0%.综上所述,对于cache的命中率来说,其容量是至关重要的因素,因此cache设计趋势是在同样的芯片面积下尽可能增加容量.
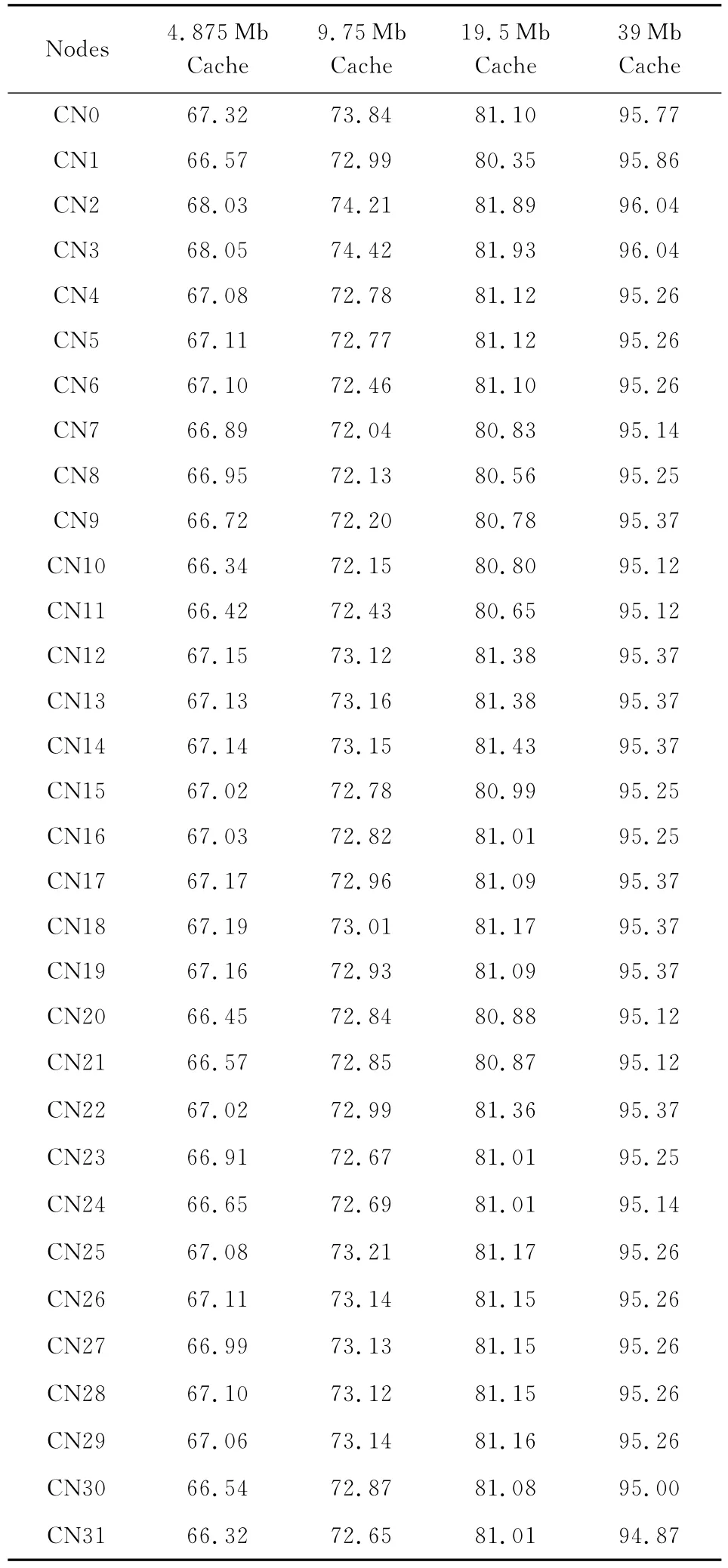
Table 2 Hit Ratio of 4Types of Cache after Running Benchmark表2 4种Cache运行测试程序的命中率%
5 结 论
提出了一种在并行计算机互连网络中的地址转换cache.ATC采用了eDRAM存储器,以容纳更多的地址转换表项,从而提高命中率;并设计一种eDRAM刷新机制,隐藏了刷新操作;实现了非阻塞的深度流水线,提高访问带宽.ATC中还实现了诸如纠错码与旁路机制等多种可靠性设计.通过在32个计算结点上运行NPB测试程序,结果表明32个结点中ATC的平均命中率达到了95.3%.并且通过与3种传统SRAM实现的cache进行对比实验,说明了cache容量是提高命中率的关键因素.下一步工作主要是在更多的并行测试程序上验证ATC的性能.
[1]TOP500Supercomputer Organization.TOP500supercomputers lists[EB?OL].[2014-06-30].http:??www.top500.org?lists? 2014?06
[2]Pritchard H,Gorodetsky I,Buntinas D.A uGNI-based MPICH2nemesis network module for the cray XE[G]?? LNCS 6960:Proc of the 18th European MPI Users'Group Conf on Recent Advances in the Message Passing Interface.Berlin:Springer,2011:110 119
[3]Xie Min,Lu Yutong,Liu Lu,et al.Implementation and evaluation of network interface and message passing services for TianHe-1Asupercomputer[C]??Proc of the 19th IEEE Annual Symp on High Performance Interconnects.Piscataway,NJ:IEEE,2011:78 86
[4]Pang Zhengbin,Xie Min,Zhang Jun,et al.The TH Express high performance interconnect networks[J].Frontires of Computer Science,2014,8(3):357 366
[5]Chun Brent N,Mainwaring Alan M,Culler Darid E.Virtual network transport protocols for Myrinet[J].IEEE Micro,1998,18(1):53 63
[6]Bhoedjang R A,Ruhl T,Bal H E.User-level network interface protocols[J].Computer,1998,31(11):53 60
[7]Hameed F,Bauer L,Henkel J.Simultaneously optimizing DRAM cache hit latency and miss rate via novel set mapping policies[C]??Proc of 2013Int Conf on Compilers,Architecture and Synthesis for Embedded Systems.Piscataway,NJ:IEEE,2013:1 10
[8]Hameed F,Bauer L,Henkel J.Reducing inter-core cache contention with an adaptive bank mapping policy in DRAM cache[C]??Proc of 2013Int Conf on Hardware?Software Codesign and System Synthesis.Piscataway,NJ:IEEE,2013:1 8
[9]Hameed F,Bauer L,Henkel J.Reducing latency in an SRAM?DRAM cache hierarchy via a novel tag-cache architecture[C]??Proc of the 51st Design Automation Conf.New York:ACM,2014:1 6
[10]Corrigan M J,Godtland P,Hinojosa J.Selectively invalidating entries in an address translation cache:USA,United States Patent 7822042[P].2010-10-26
[11]Carlos F,Fang Z,Ravi R I,et al.Buffer-integrated-cache:A cost-effective SRAM architecture for handheld and embedded platforms[C]??Proc of the 48th Design Automation Conf.New York:ACM,2011:966 971
[12]NASA Advanced Supercomputing Division.NAS Parallel Benchmarks[EB?OL].[2014-03-02].http:??www.nas.nasa.gov?publications?npb.html
[13]Yuan Wei,Zhang Yunquan,Sun Jiachang,et al.Performance analysis of NPB benchmark on domestic terascale cluster systems[J].Journal of Computer Research and Development,2005,42(6):1079 1084(in Chinese)(袁伟,张云泉,孙家昶,等.国产万亿次机群系统NPB性能测试分析[J].计算机研究与发展,2005,42(6):1079 1084)

Zhang Jianmin,born in 1979.PhD and assistant professor in the National University of Defense Technology.His main research interests include computer architecture,VLSI chip design and verification.

Li Tiejun,born in 1977.PhD and associate professor in the National University of Defense Technology.His main research interests include high performance computer architecture(tjli@nudt.edu.cn).

Li Sikun,born in 1941.Professor and PhD supervisor in the National University of Defense Technology.Senior member of China Computer Federation.His main research interests include electronic CAD,chip design methodologies,and virtual reality(lisikun@263.net.cn).
An Address Cache of Interconnect Network in Parallel Computers
Zhang Jianmin,Li Tiejun,and Li Sikun
(College of Computer,National University of Defense Technology,Changsha410073)
Most of users are accustomed to utilize the virtual address in their parallel programs running at the scalable parallel computer systems.Therefore the virtual and physical address translation directly affects the performance of the parallel programs.Cache can strongly improve the efficiency of address translation and reduce the latency of translation.In this paper,a new address translation cache(ATC)is proposed for the interconnect network of scalable parallel computer systems.To improve the hit ratio,ATC adopts embedded dynamic random access memory(eDRAM)to store more address translation table items.A new eDRAM refresh mechanism is proposed to hide the refresh operation and avoid the performance loss introduced by refresh.In ATC,there are many reliability techniques,including error correcting code and a novel bypass module.The well-known NPB benchmarks have been run at the 32compute nodes including ATC.The results show that the ATC has high hit ratio which the average value of 32nodes is 95.3%.It is indicated that ATC is well designed and has high performance.It also has been compared with three types of typical cache implemented by different capacities SRAM(static random access memory),and the conclusion is the capacity of cache is key factor to improve the hit ratio.
parallel computer;interconnect network;virtual address;physical address;address translation cache
TP333
2014-09-19;
2015-06-24
国家自然科学基金项目(61103083,61133007);国家“八六三”高技术研究发展计划基金项目(2012AA01A301);国家“九七三”重点基础研究发展计划基金项目(2011CB309705)
This work was supported by the National Natural Science Foundation of China(61103083,61133007),the National High Technology Research and Development Program of China(863Program)(2012AA01A301),and the National Basic Research Program of China(973Program)(2011CB309705).
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:24:00
中国生殖健康(2019年11期)2019-01-07 01:27:44
长江丛刊(2018年31期)2018-12-05 06:34:20
数学物理学报(2018年1期)2018-03-26 08:16:42
NBA特刊(2017年8期)2017-06-05 15:00:13
梧州学院学报(2015年3期)2015-02-28 17:55:16
环球时报(2014-06-18)2014-06-18 16:40:11
电子设计工程(2014年23期)2014-02-27 12:02:22
电子设计工程(2014年12期)2014-02-27 11:58:23
苏州市职业大学学报(2010年1期)2010-01-29 02:26:40
