
RBF神经网络迭加粗糙集的数据挖掘算法探讨
2016-07-29 00:42查道贵许彩芳宿州职业技术学院安徽宿州234101
湖南城市学院学报(自然科学版) 2016年1期
查道贵,许彩芳(宿州职业技术学院,安徽 宿州 234101)
RBF神经网络迭加粗糙集的数据挖掘算法探讨
查道贵,许彩芳
(宿州职业技术学院,安徽 宿州 234101)
摘 要:报告了数据挖掘技术及算法的现状,研究了粗糙集理论和RBF神经网络的经典模型,比较分析了二者优缺点,为提高数据挖掘算法的准确性,提出了 RBF神经网络迭加粗糙集的数据挖掘算法思想,实验数据验证了利用RBF神经网络优化数据,再利用粗糙集来约束和提取规则,可取得良好的数据挖掘效果。
关键词:RBF神经网络;粗糙集;数据挖掘算法
2012年,美国奥巴马政府为提高海量数据的收集、访问和整理的速度,承诺投资2亿美元加强大数据及相关产业的发展和研究。我国也于2012年批复了“十二五国家政务信息化建设工程规划”。联合国于同年发布白皮书,指出大数据对联合国及各国都是一个历史的机遇。一个开放的、共享的、智能化的大数据的时代已经来临!
1 数据挖掘及算法
分析并挖掘海量数据中所蕴藏有价值信息,就是数据挖掘的目的所在。数据挖掘就是利用技术、方法和算法来管理、分析数据以达到知识发现。在此领域中应用比较广泛的包含遗传算法、RBF(径向基函数)神经网络及粗糙集理论等。粗糙集理论是通过不可分辨关系确定某些特征属性,从而确定数据的内部属性,在大量数据处理和消除冗余的情况下粗糙集在数据挖掘领域应用比较广泛[1]。
2 RBF神经网络原理分析
RBF神经网络首先利用径向基函数将数据映射到一个高维的空间,之后再在高维空间上的实现线性建模。RBF神经网络原理如下:
研究的数据有N个训练样本组,各个层次均有不同的神经元组成,其中隐含层有i个神经元构成,输入层有M个神经元构成,然后根据这两组数据分析、总结出结构,并以高斯函数作为基函数,其中it代表的是基函数的中心,输入层含有j个神经元元素。系统中输入层与输入层之间的权值用mi1ω(m=1,2…,M;i=1,2,…i)表示;另外,隐含层设置的值域单元为0δ,其中它的输出值始终为1。假设X=[为一个训练样本,其中任意一列(n=1,2,…N)为一个训练样本,对应的实际输出为(n=1,2,…N),矢量集为D。通过以上的分析我们可以计算出此次分析中的基函数为:
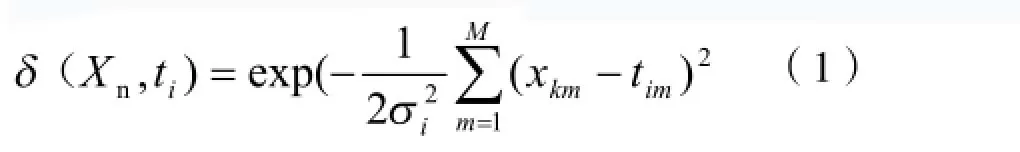
在公式(1)中iσ为高斯函数的方差,神经网络的训练样本分析中一般由两个阶段组成,第一个阶段是在没有监督的过程中形成的一种样本,而第二个阶段是在有监督的过程中形成的,两者学习规则和构成存在一定的差距,能够根据一定的学习规则调整网络的值域[2]。
3 粗糙集理论
粗集理论主要是在信息系统的分类能力下实施的一种时间约简方式,并根据此种方法分析导出问题的分类原则和方法,它主要应用于信息表描述域中有关数据模型的分析,在分析的过程中首先将粗糙集看做是一个二维表,然后根据信息表中的对象、属性以及实例分析等,对粗糙集进行多个属性的综合分析,然后再此基础上根据对属性的描述进行集合分析,最后将分析结果整理为信息表。
4 RBF神经网络及粗糙集算法设计分析
将 RBF神经网络和粗糙集这两种方法进行优势互补,在RBF神经网络及粗糙集机制下提出一种算法分析形式:采用一种网络结构形式预测信息表的原始数据和规则,并将真实决策与预测结果值进行详细的对比,并在去除干扰数据的基础上进行分析,然后再利用属性离散分析法来数据处理,使之满足粗燥集挖掘的要求,并进行简约分析和规则提取。根据以上分析的思路,可得图1所示RBF神经网络迭加粗糙集算法步骤图:
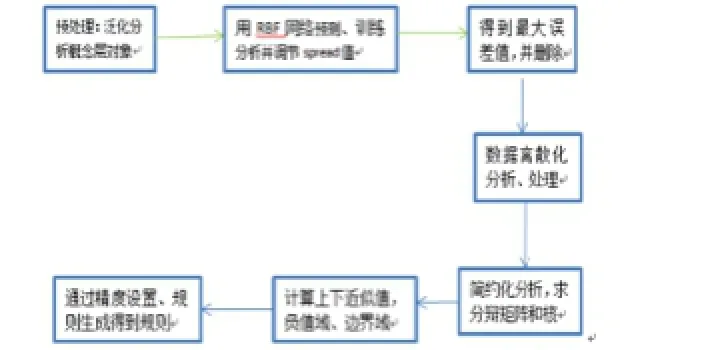
图11:RBF神经网络迭加粗糙生的算法步骤图
5 用实例分析验证
5.1预处理数据
以安徽省各地级市在万众创新大众创业的大环境下各种民营、私营企业(包括家庭式作坊,但不包括大型国有企业)的相关数据为例进行数据分析,各地级市发展不同所以各自数据信息不同但均有一定的属性关系,为此采用神经元结构的数据预处理方式进行处理,首先提取出具有代表性的地区,而后对数据进行泛化操作和属性删除,进一步分析数据信息的分析其属性值。
5.2数据处理
利用RBF神经网络对数据进行处理分析,首先将信息表的条件属性当做其训练样本,而后建立一个相关的RBF神经网络函数模型,最后对数据实施归一化处理,调节数值分析,确定 spread值。然后建立网络曲线图对数据进行估计分析。比较数据精度值,由于数据比较多,删除前后数据的精度值,利用RBF神经网络对数据进行预处理分析,提高系统泛化能力。
5.3数据挖掘分析
在数据挖掘分析的过程中为了使数据挖掘效果更加精确,我们在这里采用粗燥集理论对数据信息实施处理、分析,首先对数据进行离散分析,数据离散的方法比较多,比如等频离散法、等距离离散法等,在这里我们利用等距离离散法进行数据属性分析。
5.4属性简化分析和规则抽取
利用神经网络和粗糙集理论进行数据分析的过程中,首先利用相关软件对信息进行处理,并对数据进行简约处理,然后进行规则抽取,并将得到的规则应用于样本分析中,这时我们会得到一个相关信息为:处理后的测试精度高于未进行数据预处理的分析数据精度值。所以说RBF神经网络迭加粗糙集的数据处理更加精确,减少不可靠数据对数据挖掘的影响,提高数据精确度。
6 结束语
在数据分析中先利用 RBF神经网络所具有较强的数据分析和泛化能力,对数据进行预处理和分析,通过简约化处理和规则抽取分析,得到一个相对比较可靠的数据信息,再利用粗糙集所具备的并行处理、较强鲁棒性和效率高的特点进行数据处理,这样能够发挥粗糙集和RBF神经网络结构的双重优势,提高信息精确度,同时能够使优化后的数据降低错误率,提高数据挖掘的精确度和准确性。
参考文献:
[1]储兵,吴陈,杨习贝等.基于RBF神经网络与粗糙集的数据挖掘算法[J].计算机技术与发展,2013,23(7):87-91.
[2]杨志超,张成龙,吴奕等.基于粗糙集和 RBF 神经网络的变压器故障诊断方法研究[J].电测与仪表,2014,(21):34-39.
(责任编辑:雷 君)
中图分类号:C37
文献标识码:A
doi:10.3969/j.issn.1672-7304.2016.01.080
文章编号:1672–7304(2016)01–0172–02
*基金项目:皖北旱地小麦秸秆腐化剂选择及直接还田配套技术的研究(KJ2014A254)。
作者简介:查道贵(1975-),男,安徽安庆人,讲师,研究方向:计算机应用。
Data Mining Algorithm Based on Rough Sets Superposed upon RBF Neural Network
ZHA Dao-gui,XU Cai-fang
(Computer Information Department Suzhou Vocational Technical College, Suzhou,Anhui 234101)
Abstract:In this thesis, the status of data mining technology and algorithm is reported, the classic models of rough sets theory and RBF neural network theory are studied and the merits and faults of the two theories are compared and analyzed. In order to improve the accuracy and of data mining algorithm, the idea of data mining algorithm based on rough sets superposed upon RBF neural network is put forward. The research results show that good data mining effect can be achieved by way of constraining and extracting the rules using rough sets after optimizing the data using RBF neural network.
Keywords:RBF neural network; Rough set; Data mining algorithms
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
科教导刊·电子版(2021年6期)2021-05-06
成都信息工程大学学报(2019年2期)2019-08-28
系统管理学报(2018年3期)2018-08-13
厦门大学学报(自然科学版)(2016年6期)2016-12-07
科教导刊·电子版(2016年26期)2016-11-21
科教导刊·电子版(2016年27期)2016-11-18
科教导刊·电子版(2016年25期)2016-11-16
电脑知识与技术(2016年25期)2016-11-16
厦门理工学院学报(2016年3期)2016-11-10
