
高校人才评估的数据结构设计
2016-07-28 07:33安徽医学高等专科学校安徽合肥230601
湖南城市学院学报(自然科学版) 2016年1期
关键词:数据分析
张 源(安徽医学高等专科学校,安徽 合肥 230601)
高校人才评估的数据结构设计
张 源
(安徽医学高等专科学校,安徽 合肥 230601)
摘 要:为了建立教育文化大数据,探索发挥大数据对变革教育方式、促进教育公平、提升教育质量的支撑作用,本文通过科学的数据分析方法设计的分析框架结构,结合大数据分析理念,为高等院校的教师人才培养提出一些科学的建议和评价,为教师的培养评估提出定量和定性综合性评价打下基础。
关键词:数据分析;交叉验证算法;定量与定性评价
1 教师人才评估体系数据分析的意义
本论文建立在相关研究的基础上,形成了比较适合高等院校的教师人才评估模型,该模型从三个维度描述教师人才的结构。本论文提出一个三层模型:师德师风、教学质量、科研质量,进而对获取数据进行分析和数据挖掘,得到一些有价值的信息。
2 研究方法
对高校教师人才评估数据的分析研究的技术框架,如图1所示
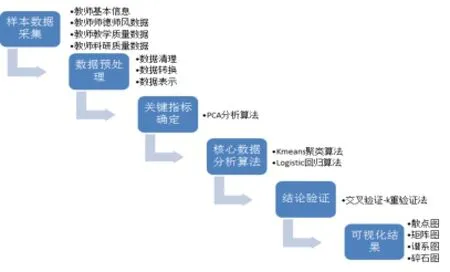
图1 教师人才培养评估的数据分析研究框架图
2.1样本数据的来源和预处理
本论文针对部分教师的师德评价、教学质量考核、科研质量数据库进行数据的采集和预处理。数据采集的来源:学生测评、同行评价,专家评价,教学质量考核数据库、科研质量赋分数据库,主要采用的评估内容包含师德师风评估表,教学质量评估表和科研质量评估表[1]。
2.2数据分析算法和工具
(1)交叉验证算法。Logistic回归作为预测时,在更大样本数据集的表现如何,其真实性如何,我们可以做一些验证算法,其中交叉验证法就是一种验证预测的回归方程的泛化能力。
所谓交叉验证,也就是将一定比例的数据挑选出来作为训练样本,其余的样本作为保留样本,在训练样本上获取回归方程,然后在保留样本上做预测,因为保留样本数据不设计参数的选择,所以此类样本获得的预测数据更为真实和准确。
假设做k重交叉验证,样本被分为k个子样本,轮流将k-1个子样本作为训练样本集,剩余1个作为保留样本集,这样我们可以得到k个回归预测方程,记录k个保留样本的预测表现结果,然后求其平均值。
(2)R语言程序编程。在大数据时代,数据分析工具有许多,例如:SASS、SPS、R语言等等,本项目之所以选择R语言作为数据分析编程工具,原因有以下几点:产品功能齐全,接口开放、开源免费、有C语言基础的上手容易。
3 实验方案设计
3.1实验机器配置
硬件要求内存在 4G以上,cpu处理速度3.5GHz PentiumⅣ CPU以上,软件安装环境要求windows7操作系统,安装MS office 2010,编程环境选择RSTUDIO,结合官方的函数包。
3.2样本数据收集
选择目前采用的评估数据作为指标变量,包含四个“师德师风考评表”、 “教师课堂教学质量评估表(包含学生测评分值)”、“科研质量评估表”作为数据收集来源,随机抽取20名已经获得“教坛新秀”或“教学名师”称号的近2年的评估数据,再随机抽取80名尚未评选成功的教师的近2年评估数据,构成100名教师近2年的样本数据。
3.3数据的整理和预处理
剔除评估分值存在异样的样本数据,异样数据的情况判断依据:缺分,超低分(大面积不合格分值)等等极端分值的数据,避免出现数据最终分析严重偏离实际情况的出现[2]。选择一级指标4个V1、V2、V3、V4分别是师德师风、教学质量、科研质量、教坛新秀或者教学名师,二级指标33个。对近2年的教师所有对应的指标数据首先进行平均值计算,得出相应的分值。
3.4算法编程实现
在R语言中使用read.delim()函数导入带分隔符的文本文件,或者使用RODBC包的函数导入excel文件,接着使用principal()、prcomp()、pca()函数分别对33个指标变量执行PCA算法确定主成分以及主成分个数,得到主成分的 Standard deviation标准差(特征值)、Proportion of Variance方差贡献率、Cumulative Proportion累计方差贡献率,通过观察这3个值确定主成分的个数,用确定的主成分代替原来的33个指标变量,写出主成分与原变量的线性关系方程,经过分析得出新的判定指标变量。再通过对主成分中的贡献度参考原始指标最终确定关键性指标,接着使用Kmeans()函数进行聚类分析得到结果,绘制谱系图,最终结合实际的指标变量描述得出关于教师人才培养的指标客观性的定性评价。到此完成教师人才培养评估的定量与定性评价。
通过选取的100名教师的数据结合这些相对重要的关键性指标,用glm()函数配合“AER”包进行Logistic回归算法分析,得到p值,也就是显著性,影响最大的几个指标变量,接着对取值进行探讨和解释,使用常规的检验手段进行检验模型拟合度,最后使用 predict()函数对于新的样本数据进行测试,如图2所示观察p值,分析p值看是否具有“教学新秀或教学名师”的潜力和可能性,也可以将结果结合实际情况对教师人才培养的现状进行预测和解释。最后使用交叉验证法,使用bootstrap包中的crossval()函数对结果进行k重交叉验证,以检验预测结果的表现。

图2 预测函数得到的p值
3.5可视化结果
将分析的结果以可视化的方式展现,使用函数包中的 screenplot()、plot()、varplot()等图像函数包,其中包括谱系图、散点图、碎石图、方差图、矩阵散点图、矩阵图等等,方便形象的对分析结果进行解释。
3.6定量和定性评价和预测
通过对编程计算后的结果,包括产生的可视化图形,结合实际的参数对分析结果进行综合评价。例如:某位教师最终得分,属于偏教学轻科研型,离优秀人才评估的分值相差较大,无论是教学还是科研仍需努力。某位教师最终得分,属于重科研轻教学型,离优秀人才评估的分值相差较少,继续努力,可以作为下一轮优秀人才评估的推荐教师,除此之外,还有双强教师,已经具备优秀人才的素质,还有双弱教师,需要找出其原因对症下药。
参考文献:
[1]俞东进.基于服务的决策支持系统研究[D].杭州: 浙江工商大学;2010.
[2]李明星.多粒度粗糙集的理论研究及其应用[D].镇江: 江苏科技大学;2014.
(责任编辑:吴湘银)
中图分类号:TB482.2
文献标识码:A
doi:10.3969/j.issn.1672-7304.2016.01.078
文章编号:1672–7304(2016)01–0168–02
作者简介:张源(1982-),男,安徽合肥人,讲师,研究方向:数据分析。
Of college talent evaluation data structure design
ZHANG Yuan
(Anhui medical college,Hefei Anhui 230601)
Abstact:In order to establish education culture big data , exploring the way big data should be utilized to change education, promote education fairness, improve education quality support. This paper hopes to design the analysis frame structure of the scientific data analysis method, combined with the idea of big data analysis,which makes some scientific suggestions and evaluation and also puts forward the foundation of quantitative and qualitative comprehensive evaluation for the cultivation and evaluation of faculty.
Keywords:Data analysis; Cross validation algorithm; quantitative and qualitative evaluation
猜你喜欢
职工法律天地·下半月(2016年10期)2016-11-30
商情(2016年40期)2016-11-28
商(2016年32期)2016-11-24
科技资讯(2016年18期)2016-11-15
考试周刊(2016年84期)2016-11-11
科技视界(2016年18期)2016-11-03
中国市场(2016年36期)2016-10-19
商场现代化(2016年22期)2016-10-18
科技视界(2016年22期)2016-10-18
