
云计算环境下支持多属性查找的混合对等网络
2016-07-23 03:46杜晓锋陈世平
电子科技 2016年7期
关键词:云计算
杜晓锋,陈世平
(1.上海理工大学 光电信息与计算机工程学院,上海 200093;2.上海理工大学 信息化办公室,上海 200093)
云计算环境下支持多属性查找的混合对等网络
杜晓锋1,陈世平2
(1.上海理工大学 光电信息与计算机工程学院,上海 200093;2.上海理工大学 信息化办公室,上海 200093)
摘要针对云计算环境下,云资源的多属性查找问题,设计了一种混合结构的对等网络。该网络采用多星形拓扑结构,将云资源以统一的编码方式规范化之后部署到该网络上,可较好地实现多属性查找。文中描述了多属性查找算法,分析了网络性能,该网络旨在降低资源查找的跳数,因此文中主要分析网络查找跳数。实验表明,资源查找跳数得到优化,达到了预期效果。
关键词云计算;多属性查找;混合对等网络
云计算是通过网络为用户提供各种方便的服务。而现存的大部分云提供商均只集中提供某一种云服务,例如GoogleCloudStorage提供存储服务,GoogleAppEngine提供网络应用程序服务。不同的云提供商提供不同的云资源,但用户通常需要同时获得多种云资源,因用户同时需要多种云资源,因此必须将不同类型的云资源进行整合。云资源的多属性查找就是帮助用户快速定位云资源的关键技术。
为了更好的支持多属性查找,本文吸收了结构化对等网络和非结构化对等网络的优点,采用混合结构的对等网络。对等网络中的节点都采用常年稳定在线的云服务器构成,每个节点的处理能力、存储空间、稳定性等性能均是优秀的。因而,在研究对云资源的多属性查找时,不需要过多考虑节点性能。
1相关研究
支持云资源查找的P2P网络按照结构划分通常可分为4类:结构化P2P网络、非结构化P2P网络、分层P2P网络和混合结构化P2P网络。
结构化的P2P网络是将网络中的节点严格按照特定的结构进行组织,整个网络拓扑受到严格控制,网络中的所有节点共同维护网络拓扑的稳定。由于网络的稳定性和节点的有规律组织,结构化P2P网络通常通过DHT将查询请求映射到特定节点上来实现资源查找,结构化P2P网络中的资源查找通常速度比较快,网络利用率较高,但网络结构要求严格,不易扩展,而且不支持多属性区间查找。Chord[1]和CAN[2]是最常见的两种结构化P2P网络,Chord将节点按照环形结构组织,每个节点通过哈希的方式产生一个唯一的ID,查询复杂度是θ(logN),但只支持单属性查找。CAN以一个多维空间方式组织节点,其不支持区间查找。
非结构化P2P网络中节点的组织方式没有严格的要求,所以节点的加入和离开更加方便,网络的扩展性更好。非结构化P2P网络通常采用洪泛的方式查找资源,其查找算法简单,但会产生较多无用的网络通,如文献[3~5]所示。
分层的P2P网络通常是利用超级节点将多层的结构化P2P网络相连,利用分层逐级降低查找的属性资源维度,以实现多维属性查找。比如文献[6~8]。
混合P2P网络是结构化P2P网络和非结构化P2P网络相结合,综合两者各自的优点而建立的一种P2P网络结构。其相对结构化P2P网络有更好的可扩展性,能支持多属性区间查找,相对于非结构化P2P网络具有较少的无用网络通信,比如文献[9~11]。综合各方研究成果,本文采用混合P2P网络,能很好地支持多属性查找。
2系统设计
2.1资源编码表
本文针对的是多属性云资源,云资源具有多种属性,而每种属性的云资源均有各自的描述方式,为方便多属性查找,需要将多属性云资源进行统一编码,建立资源编码表。
将n维属性云资源看作一个资源空间,每种属性代表该资源空间的一个维度,每个维度上再进行r个区间的划分,代表每种属性的值区间,这样便形成了rn个多维属性区间。假设一类云资源具有内存和带宽两种属性,其中内存属性的值有1GB,2GB,3GB,4GB,带宽的值有100Mbit·s-1,200Mbit·s-1,300Mbit·s-1,400Mbit·s-1,则可建立如图1所示的资源编码表。其中,纵轴代表内存,横轴代表带宽,每个属性维度划分4个区间,分别用2bit来编码,则每个多维属性区间便可用4bit编码来表示。图1中 编码的属性区间就表示“内存=1GB,带宽=100Mbit·s-1”的云资源,其是资源空间中各维度属性值都最小的属性区间,称为原点属性区间。通过资源编码表的方式,多属性云资源就能实现统一编码,再与网络结构相结合即可实现多属性查找。

图1 二维属性资源编码表
2.2网络拓扑结构
该文设计的网络拓扑结构是一个多星型的混合P2P网络结构,如图2所示,是对应图1所示的资源编码表得到的网络拓扑图。图中带编号的椭圆代表资源簇,所谓资源簇就是具有相同属性组合及属性值区间的所有节点的聚集,每个资源簇内部是按照非结构化P2P网络组织节点的。图中用同种连线相连的资源簇组成一个星型,各个星形之间彼此相连,最终形成了一个多星型的混合P2P网络结构。

图2 网络拓扑图
2.3边缘区间
将n维资源空间中具有某一属性维度上最小属性值的属性区间称为边缘区间。如图1中竖线阴影部分是具有带宽这个维度最小属性值的边缘区间,横线阴影部分是具有内存这个属性维度上最小属性值的边缘区间,而(0000)区间同时是内存和带宽两个维度的最小值。边缘区间对应的资源簇都是每个星形结构的中心资源簇。所有的边缘区间对应的资源簇都会与原点中心簇直接相连。如图2中,(0000),(0001),(0010),(0100),(1000),(1100)属性区间对应的资源簇就都和原点属性区间对应的资源簇相连。边缘区间的概念将在资源查找用被利用,能优化最大查询跳数。
2.4相似区间
该文将某一属性维度编码不同而其他维度属性编码相同的属性区间称为相似区间,如图1中的任一行或任一列的4个属性区间都是相似区间。相似区间对应的资源簇属于同一个星形结构,相似区间的概念将在资源查找算法中被利用。
3资源查找
3.1多属性查找算法
(1)当某个节点 接收到用户的查询请求,首先将查询请求的资源转换成对应的资源编码,然后比对是否是该节点自身所在的资源簇,若是转到步骤(2),若请求的资源不是该节点所在的资源簇,则转到步骤(3);
(2)在资源簇中用洪泛的方式查找资源节点,若找到,则在节点与用户之间建立直接连接,将资源提交给用户,若未找到满足要求的节点,则返回查询失败。在簇中查找时会采取负载均衡措施,比如判断节点是否超负载,若超过负载,就将查询转发给其他节点,这不是本文研究重点,不再赘述;
(3)判断节点 所在的资源区间和用户请求的资源区间是否是相似区间,如果是相似区间,说明节点N所在的资源簇和请求的资源簇属于同一个星形,接着判断节点N所在资源簇和目标资源簇中是否有中心资源簇,若存在,说明两者直接相连,N直接将请求转发给目标资源簇,然后执行步骤(2),如果不存在,则N将请求转发给中心资源簇,再由中心资源簇转发给目标资源簇,执行步骤(2);若N所在的资源区间和用户请求的资源区间不是相似区间,则执行步骤(4);
(4)若节点N所在的属性区间和目标资源簇对应的属性区间都是边缘区间,则节点N将请求转发给原点属性区间对应的资源簇,再由原点属性区间对应的资源簇转发给目标资源簇,因所有的边缘区间对应的资源簇均与原点属性区间对应的资源簇相连;若节点N所在的属性区间和目标资源簇对应的属性区间不是边缘区间,则节点N所在的资源簇将请求转发给其所在星形结构的中心资源簇,由于中心资源簇对应的属性区间都是边缘区间,而所有的边缘区间都和原点属性区间对应的资源簇相连,所以将请求进一步转发给原点属性区间对应的资源簇,由该资源簇转发给与目标资源簇在一个星形结构的中心资源簇,再由该中心资源簇转发给目标资源簇,由于每个资源簇都连接多个星形,和多个中心资源簇相连,所以存在多条路径,可设计算法选择最优线路,该文算法只任意选择一条,其他路径作为备用线路。最后执行步骤(2)。
假设存在一个如图1所示的资源空间,网络拓扑情况如图2所示,(0111)属性区间对应的资源簇中的某个节点S接收到用户的查询请求“内存=3GB,带宽=300Mbit·s-1”,节点N得到查询请求对应的属性区间编码是(1010),并不是自身所在的资源簇,所以判断(0111)和(1010)这两个属性区间是否为相似区间,若发现不是,将查询请求转发给S所在资源簇相连的中心资源簇(0011)和(0100)两个属性区间对应的资源簇,本文中算法选择了(0011)属性区间对应的资源簇,由该资源簇将请求转发给原点属性区间(0000)对应的资源簇,再由原点属性区间(0000)对应的资源簇将请求转发给与目标资源簇(1010)相连的中心资源簇(0010)或(1000),本文算法选择(0010),最后由(0010)属性区间对应的资源簇将请求转发给目标资源簇,在目标资源簇内采用洪泛方式查找资源,提供给用户。整个查询过程如图3所示,其中实线箭头线表示该算法实际使用的线路,虚线箭头线表示备用线路,箭头线上的数字表示查询步骤的顺序。
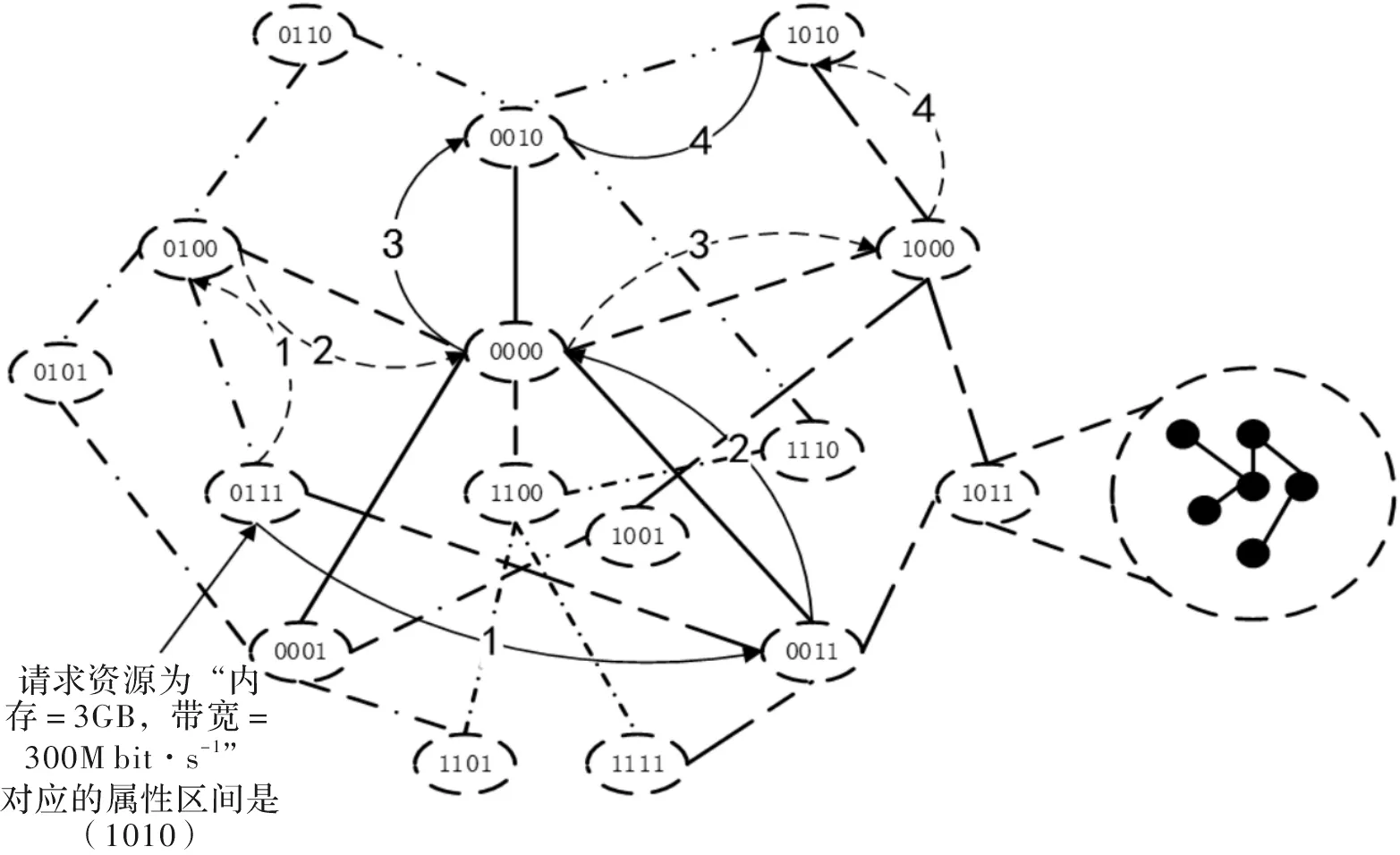
图3 查询算法示例图
3.2性能分析
本文主要优化多属性查找的跳数,因此主要对该网络的多属性查询的查找跳数进行分析,文中所述的查询跳数是指从接受请求的节点所在的资源簇找到目标资源簇所化的跳数,而资源簇内部的洪泛查找不予考虑。
由上述查找算法可看出,当目标资源簇就是接受请求节点所在的资源簇时,查询跳数为0,当目标资源簇与接受查询请求节点所在的资源簇在同一个星形结构中,且其中有一个是中心资源簇,或其中一个资源簇对应的属性区间是原点属性区间,而另一个资源簇对应的属性区间是边缘区间时,则查询跳数为1。当目标资源簇与接受查询请求的节点所在的资源簇在同一个星形结构中,且均不为中心资源簇,或两个资源簇对应的属性区间都为边缘区间,且其中没有原点属性区间时,查询跳数为2,当目标资源簇对应的属性区间与接受查询请求节点所在资源簇对应的属性区间中有一个是边缘区间且不为原点属性区间,而另一个不是边缘区间,则查询跳数为3,最复杂的情况就是如示例所示的情况,查询跳数为4。
这些查询跳数情况不仅针对二维资源空间有效,对于一个n维的资源空间,同样如此,因该文的查询算法相当于从一个n维空间的单元子空间出发,对某一维作投影,得到本文所述的边缘区间,然后转发给原点属性区间,由原点属性区间转发给目标区间在某一维度的投影,即边缘区间,再由该边缘区间转发给目标区间,因此,该文提出的算法的最大查询跳数是θ(4)级的,而文献[10]中设计的系统的最大查询跳数是θ(2n)级,其中n代表属性维度,得到了优化。
4实验
实验环境为CPU主频3.40GHz,内存2GB,Linux操作系统,JDK1.6,在1.0.5版本的PeerSim上用Java实现的一个模拟环境。
该文实验的目的在于检测网络最大查询跳数,并与文献[10]中的MAMSO系统的最大查询跳数进行对比。实验中,网络节点数分别为1000个,3 000个,5 000个,7 000个,9 000个和11 000个,在每种网络规模下,属性种类数分别有2种,3种,4种和5种,每个属性分8个值区间,每组实验做10次,取平均值,图4是在该文设计的网络结构下的结果图,图5是MAMSO系统下的结果图,由图4可知,网络规模和属性种类数都对最大查询跳数没有影响,最大查询跳数始终为4跳。由图5可知,在MAMSO系统中,网络规模对于最大查询跳数没有影响,但最大查询跳数随着属性种类数变化,是属性种类数量的2倍。对比图4和图5所示的实验结果可知,该文中的系统将最大查询跳数从 级降低到了 ,实现了优化。

图4 该文系统实验结果图

图5 该文系统实验结果图
5结束语
该文设计了一个多星型结构的混合P2P网络,支持多属性查找,提出了边缘属性区间和相似属性区间等概念,设计了资源查找算法,成功将查询最大跳数降到了常数级。但是,当系统中的属性维度较多,每个维度上属性值区间数较多时,就会产生较多的边缘属性区间,由于所有的边缘属性区间对应的资源簇都会和原点属性区间对应的资源簇直接相连,因此就会大幅增加网络连接,同时增加原点属性区间对应资源簇节
点的负载。可通过进一步细化边缘属性区间的定义,来减少边缘属性区间的数量,从而优化整个系统网络。
参考文献
[1]StoicaI,MorrisR,KargerDetal.Chord:Ascalablepeer-to-peerlookupserviceforInternetapplications[C].SanDiego,CA:AcmSigcomm2001Conference, 2001.
[2]RatnasamyS,FrancisP,HandleyM,etal.Ascalablecontent-addressablenetwork[C].SanDiego,CA:AcmSigcomm2001Conference, 2001.
[3]JinHai,NingXiaomin.Improvingsearchinpeer-to-peerliteraturesharingsystemsviasemanticsmallworld[C].Napoli,Italy: 2007 15thEuromicroInternationalConferenceonParallelDistributedandNetwork-basedProcessing,2007.
[4]QuWenyu,ZhouWanlei,KitsuregawaM.Sharablefilesearchinginunstructuredpeer-to-peersystems[J].JournalofSupercomputing,2010,51(2): 149-66.
[5]MirtaheriSL,SharifiM.Anefficientresourcediscoveryframeworkforpureunstructuredpeer-to-peersystems[J].ComputerNetworks,2014,59(3): 213-226.
[6]AdityaKurve,ChristopherGriffin,DavidJMiller,etal.Optimizingclusterformationinsuper-peernetworksvialocalincentivedesign[J].Peer-to-PeerNetworkingandApplications,2015,8(1):1-21.
[7]BeverlyYangB,Garcia-MolinaH.Designingasuper-peernetwork[C].Bangalore,India:Proceedings19thInternationalConferenceonDataEngineering,2003.
[8]WatanabeK,HayashibaraN,TakizawaM.Asuperpeer-basedtwo-layerP2PoverlaynetworkwiththeCBFstrategy[C].Vienna,Australia: 2007 5thInternationalConferenceonComplexIntelligentandSoftwareIntensiveSystems,2007.
[9]PapadakisHarris,TrunfioPaolo,TaliaDomenico.DesignandimplementationofahybridP2P-basedgridresourcediscoverysystem[C].Heraklion,Greece:JointWorkshoponMakingGridsWorks, 2007.
[10]YuYoufu,LaiHuanchou.Asemi-strucuredoverlayformulti-attributerangequeriesincloudcomputing[C].HongKong,China:IEEE13thInternationalConferenceonComputationalScienceandEngineering,2010.
[11]LaiKuanchou,YuYoufu.Ascalablemulti-attributehybridoverlayforrangequeriesonthecloud[J].InformationSystemFontier,2012(14):895-908.
A Hybrid P2P Overlay for Multi-attribute Queries in Cloud Computing
DUXiaofeng1,CHENShiping2
(1.SchoolofOptical-ElectricalandComputerEngineering,UniversityofShanghaiforScienceandTechnology,Shanghai
20009,China; 2.InformationOffice,UniversityofShanghaiforScienceandTechnology,Shanghai200093,China)
AbstractTo resolve the multi-attribute queries of cloud resource in cloud computing, a hybrid P2P overlay is proposed in this paper. The overlay is based on the combination of multi-star topology. Multi-attribute queries will be achieved if the normalized cloud resource is deployed to the overlay. In the paper, the algorithm for multi-attribute queries and the performance of the network are described. The overlay is designed to reduce the number of hops in resource searching, so the analysis to the number of hops is the point in the paper. The experimental results show that the number of hops in the overlay is reduced as respected.
Keywordscloud computing; multi-attribute queries; hybrid P2P overlay
收稿日期:2015- 11- 18
基金项目:国家自然科学基金资助项目(61170277, 61472256);上海市教委科研创新重点基金资助项目(12zz137);上海市一流学科建设基金资助项目(S1201YLXK)
作者简介:杜晓锋(1990-),男,硕士研究生。研究方向:计算机网络。陈世平(1964-),男,教授,博士生导师。研究方向:计算机网络等。
doi:10.16180/j.cnki.issn1007-7820.2016.07.014
中图分类号TP391
文献标识码A
文章编号1007-7820(2016)07-047-05
猜你喜欢
数字技术与应用(2016年9期)2016-11-09
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
科技视界(2016年22期)2016-10-18
中国新通信(2016年16期)2016-10-18
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
出版广角(2016年4期)2016-04-20
