
基于信息觅食理论的数字图书馆学科服务研究
2016-07-21 06:12:59周欣
信息资源管理学报 2016年2期
周 欣
(南京晓庄学院图书馆,南京,211171)
基于信息觅食理论的数字图书馆学科服务研究
周欣
(南京晓庄学院图书馆,南京,211171)
[摘要]本文旨在从信息觅食的视角分析读者在数字图书馆的学科信息搜索行为。借鉴动物生态学中的最优觅食原理,分析读者在数字资源平台的信息搜索行为,建立基于用户行为反馈的读者信息觅食模型。通过优化分析模型预测读者在数字资源平台的觅食策略,优化读者的信息觅食环境,提高读者的信息觅食能力,最终提升数字图书馆的学科服务水平。
[关键词]信息觅食用户行为反馈日志分析学科服务数字资源服务
数字图书馆给人们在数据资源的搜索和利用上带来了极大的方便,同时也给图书馆的学科服务提出了新的挑战,如何提升图书馆的学科服务水平是本文的研究重点。当读者登陆图书馆的数字资源平台查询资料或信息时,最期盼的就是在最短的时间内达到自己的领域,找到自己想要的信息,这种在网络环境中的信息搜寻行为被学者称之为信息觅食(Information Foraging)[1]。
本文借鉴动物生态学中的最优觅食原理,将读者在图书馆数字资源平台上的学科信息搜索行为看作是动物的觅食过程,将读者在数字平台上的信息获得定义为信息收益,目标是实现读者信息收益的最大化。先对读者在数字资源平台上信息搜索行为进行采集,分析读者的信息需求规律,建立基于用户行为反馈的读者信息觅食模型。通过最优化分析模型预测读者在数字资源平台的觅食策略,以提高读者的信息搜寻能力,优化读者信息觅食行为,最终提升数字图书馆的学科服务水平。本文的研究思路是先采集读者在数字资源平台上的用户行为数据,将读者的行为数据作为训练集,采用相应的数据挖掘算法对其进行分析和挖掘,研究读者行为数据特征,分析影响读者信息收益率的关键因素。本文的研究可以为学科服务平台的设计提供参考,对不同的用户展示个性化学科信息,提升读者获取学科信息的能力。
1研究现状
随着Web2.0和云服务的发展及应用,各种商业的学科服务平台应运而生,如LibGuides学科服务平台、维普的“LDSP图书馆学科服务平台”等,部分高校自己建设的学科服务平台[2]。图书馆开展学科服务的重点已不再是代查代检等传统的服务,而是向着更深层的方向发展,由原来的基于图书馆资源的文献服务转变为以用户需求为中心,为学科用户提供基于学科需求的专业化和个性化的学科服务。20世纪后期,研究人员发现人们在互联网上积极寻找信息的行为与动物的觅食行为非常相似[3],动物在自然界寻找食物时,为了在不同的栖息地获取所需的物质和能量,会采用不同的战略权衡付出与收益之间的平衡[4]。人们在互联网上搜寻信息时,为了在最短的时间内获取更多的信息,也会根据信息环境的变化,改变信息获取的策略[5]。同样读者登陆图书馆的数字资源平台搜寻学科资料时,也期待用最少的时间获得尽可能多的学科资料,这种学科信息搜寻的思路与信息觅食的研究思想是一致的。
近年来国内对信息觅食的研究很多,但是都集中在信息觅食在学科导航上的应用。学者柯青等详细介绍了动物的觅食行为与用户在Web上导航行为的相似性[6],徐芳等将信息觅食理论用于学科导航网站的性能优化[7],彭璧玉等提出了基于觅食原理的职业搜寻理论[8]。信息觅食理论的研究,可以帮助人们在获取信息时根据信息环境的变化,通过预测信息收益来不断地修正人们的信息获取路线,达到最优的信息获取目标。研究信息觅食在学科服务中的应用,可以为学科用户构建优化的学科环境,更好的为读者服务。
读者在图书馆数字化平台上进行信息搜寻时,系统会记录读者的信息搜寻轨迹,读者的这些行为数据蕴藏了读者的真实学科信息需求。从大量的读者行为数据中,运用数据挖掘技术,从中提取出蕴藏在数据中的有用信息,分析读者的真实需求,能更好地为读者提供针对性的服务。对图书馆读者行为分析的研究也越来越多[9],如,杨晶晶提出通过分析用户在信息搜寻过程中的行为轨迹对其信息收益的影响,建立基于用户隐性反馈的信息觅食模型[10]。本文采用用户日志分析的方法来分析用户在图书馆数字化平台上的信息搜寻轨迹,获取用户隐性的行为反馈信息,建立基于信息觅食的数字图书馆学科服务模型。
2信息觅食理论
2.1信息觅食理论介绍
觅食理论(Foraging Theory)是由生态学家和人类学家提出的,研究动物在觅食过程中的行为和策略[3]。觅食行为是动物的本能行为,为了在自然界中生存与繁殖必需寻找足够的物质和能量,动物在觅食的过程中,会评估食物所包含的能量及要消耗的能量,评估不同的食物和环境之间的最优收益,从而决定是否继续留在该捕食区域还是继续寻找下一个捕食区域。同样人们在网络环境中进行信息搜寻时,也要衡量所花费的时间和精力与收到的信息收益之间关系,达到两者之间的平衡,人们把这种网络环境下的信息搜寻行为称作信息觅食。
信息觅食理论(Information Foraging)第一次由Pirolli公开提出,用来模拟和解释人们在网络环境中的信息搜寻行为[1]。信息觅食理论假定人们在某种环境下的觅食行为的收益是可以计算的,通过计算将用户的信息收益与信息期望进行比较,在特定的信息环境中对用户信息搜寻过程进行模拟。信息觅食研究如何用最低的成本获取最高的信息量。信息获取的过程中人们倾向于采用效率高的获取方法,信息觅食原理假设人们使用效率最高的信息获取策略,而最佳信息觅食者则指的是那些在单位消耗成本下获取信息收益最高的人。
2.2最佳觅食理论
信息觅食理论的基本模型有斑块模型和菜单模型,最佳觅食理论都是建立在这两个传统模型的基础上的。斑块模型假设动物所处的觅食环境中食物是以块状形式分布的,觅食者面临的是不平均分布资源,需要在不同的觅食点花费不同的觅食时间,在恰当的时间内结束觅食寻找新的觅食点。菜单模型用来解释动物在不同的环境中选择哪些食物资源的问题。两种模型在网络环境中研究最优觅食策略时同样适用,块内觅食收益率的提高意味着总收益率也得到提高。
图1给出了传统觅食模型和Charnov临界值,临界点对应的时间t最佳为最佳觅食时间,临界点处对应的斜率R最佳为最佳觅食效率,该图可以用来分析讨论互联网上的用户在信息环境中的信息收益情况[10]。最佳信息觅食描述的就是如何使用最佳的觅食策略,找到最佳的觅食时间,以便在整个觅食过程中获得最高的平均收益率。
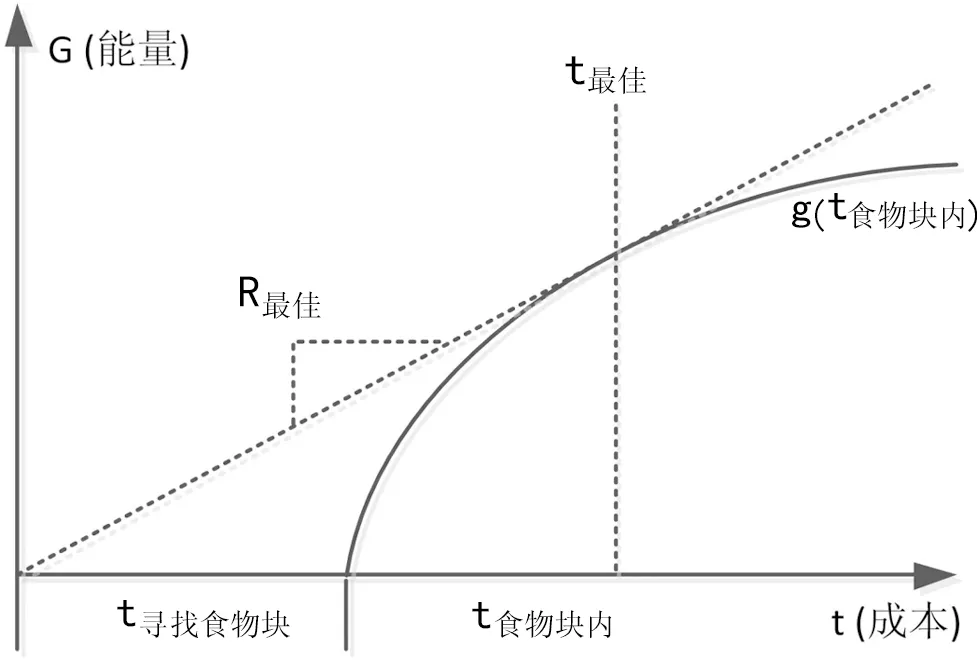
图1 传统觅食模型及Charnov临界值
读者在数字资源平台上搜寻的学科信息也是呈块状分布的,即读者所需要的学科资料分布在不同的学科网站中,学科资料搜寻时间的分配取决于每个学科网站对读者而言的获利程度、从一个网站转到另一个网站的成本以及整个学科网站的平均获利程度等。读者在每次检索的结果页面,需要点击每个链接,而每个链接的下面又有读者感兴趣的参考文献或者被引文献。有学者经过研究指出,在同一个觅食环境中如果用户的觅食过程是从能量由高到低的顺序进行,这个觅食策略将是最佳的觅食策略[10]。我们如果将读者在数字资源平台上每条反馈信息的收益计算出来,并在检索平台上按照信息收益由高到低的顺序排列,那么读者将能在最短的时间内获得最多对自己有用的信息,达到最优的觅食效果。
2.3基于用户行为反馈的信息觅食
读者在图书馆的数字资源平台上想查找某个学科的信息时,展示给读者的结果是按照某种算法给出的“权威”结果,有时候排序最前方的信息并不是读者需要的结果。然而目前大多数数字资源平台都是按照搜索文章的相关度或文章的被引量与下载量进行排序,很难满足不同读者的需求,并不能给读者提供针对性的服务。
大型的商业化购物网站,如亚马逊、京东等每天都有大量的用户检索或用户浏览轨迹,系统根据用户的访问页面进行需求分析,利用用户行为反馈给不同需求的用户呈现出不同商品信息,或者向用户进行需求相关的广告推送服务。用户行为信息记录的是用户在信息搜寻过程中的行为轨迹,能真实地反映出用户的搜索意图和需求。通过对用户的检索及浏览行为进行统计分析,利用用户的行为信息对用户的搜索行为进行优化,可以大大地提高用户的检索效率,体现个性化的需求。杨晶晶将用户隐性反馈结合信息觅食理论,应用到搜索引擎中从而改善现有的搜索页面结果排序[10],付特也提出了基于用户行为反馈的优化排序算法[11]。诸多研究表明,用户的隐性反馈与用户的满意度密切相关,如何将用户的隐性行为信息定量转化,选取何种因素来衡量用户的满意度,并将收益率计算出来将是本文的一个重点研究内容。
基于用户行为反馈的信息觅食策略,先对读者的历史访问数据进行数据挖掘,分析读者在数字资源平台上的检索信息和下载信息,计算读者当前的检索词与历史行为数据的相关性,来计算每条反馈结果的信息收益。通过此种方法计算的信息收益能真实的反应出读者的真实想法,使读者获得更好的用户体验。
3读者在数字图书馆的信息觅食行为介绍
为了满足读者的信息需求,很多高校都建设或购买了多个数字资源管理系统或学科服务平台,将图书馆的数字资源统一到一个统一的平台中管理,可以方便读者访问或下载。读者在数字图书馆搜索学科信息时考虑的问题是:如何花费最少的时间和成本来获得最大的信息收益?信息获取的极端行为会将遇到的所有相关或不相关的文章全部下载下来,再花费大量的时间慢慢浏览,这样读者将会花费大量的无用时间。如何找到平衡点?从信息觅食的角度来考虑,将读者已有的需求信息进行归类整理,利用最优化的模型可以帮助读者在信息搜寻时间与信息筛选之间寻找平衡点。
将图书馆数字资源平台上的学科资源看作块状结构分布,借鉴信息觅食理论中的块状模型,假定读者在平台中的信息总收益G是可以度量的。读者在信息觅食中花费的总时间由两部分组成:①读者检索或寻找信息块的搜索时间TB;②块内花费在信息筛选时间TW。读者的信息搜寻过程的获取信息的平均效率用R表示,简称为信息的平均收益率,则
假定读者觅食块的数量与块间觅食活动所花费的时间是线性相关的,每个信息块的平均收益为g,寻找新的信息块所花费的平均时间为tB,花费在每个信息块内的平均信息筛选的时间为tW,单位时间内搜寻到新的信息块的效率定义为λ=1/tB,则读者在平台中的信息总收益G可以这样定义:G=λTBg,同样在信息块内花费在信息筛选时间也可以这样描述TW=λTBtW,基于此,上面的公式可以这样表示:
由上面的公式可以看出,如果信息块内包含价值更高的信息,则平均信息收益率会得到提高。如果用π=g/tW描述块内的信息收益的高低,其他条件不改变的情况下,则块内觅食活动收益率的提高会使总收益率得到提高。同样从图1也可以看出,读者在某一个信息块搜寻信息时,随着块内信息搜索时间的增加,信息的收益越来越高,但是单位时间内的信息收益率则是先上升再下降,那么,如何找到最佳觅食时间t最佳,从而获得最佳的觅食效率R最佳呢?
根据最佳觅食原理,先预测信息块内每种信息的收益,然后将学科信息按照信息收益从高到低的顺序排列。例如CNKI将下载量和被引量作为预测信息收益率的大小,但是针对不同的读者,下载量和被引量并不能适合所有的读者。有大量的研究表明,用户的行为表现可以代表用户对信息收集的满意度,因此本文引入了基于用户行为反馈的读者信息觅食[10,11]。
4基于读者行为反馈的读者信息觅食模型
4.1读者信息觅食模型基本思想
图书馆数字资源管理系统或数字资源整合平台类似于统一的学科信息检索平台,数字资源管理系统与数字化校园一卡通系统对接,读者进行实名认证访问,通过读者访问日志信息可以定位到每一位读者。读者在图书馆数字资源平台上进行学科信息搜索时,系统会记录读者在平台上的所有行为操作,包括读者的来源、搜索时间、查询关键字、点击的URL、下载文章内容,在服务器上生成读者行为日志文件,经过数据处理后均会保存到数据库中,为后面的数据分析及计算读者的信息收益做准备。读者在图书馆数字资源平台上的每种操作行为都代表不同的含义,比如在检索框输入的检索关键字代表读者的信息需求内容,对搜索结果的点击意味着页面显示结果满足读者的信息需求,读者下载动作表示信息的获取等,这些读者行为操作可以度量信息觅食中信息收益的高低。本文建立一种描述读者在数字资源平台上信息觅食行为的模型,将用户隐性反馈的信息模型用于读者在图书馆数字资源管理系统上的信息觅食。
基于读者行为反馈的读者信息觅食模型分为两个部分,如图2所示。第一部分是根据读者的历史行为记录分析影响信息收益的关键因素,包括读者行为日志的获取、采用相应的数据挖掘算法对数据进行分析、历史行为记录中信息收益率的计算,见图2右侧的粗线条部分。用户在平台上搜寻信息时,服务器记录下读者的行为记录,通过文本日志处理分析后,将读者的行为记录保存在用户行为数据库中,计算读者的历史行为的信息收益,通过相应的数据挖掘算法来分析影响信息收益的关键因素。
第二部分是用户信息觅食的结果显示,见图2左侧的细线条部分,是搜索引擎的通用构架。使用网络爬虫工具,抓取读者在网站上的搜索结果,运用上述训练出的最优参数来预测网站上每条信息对读者的信息收益,然后根据页面的收益率对读者在网站上的搜索结果重新排序。
本文主要考虑两个方面的工作,一是读者在数字平台上的行为数据采集,二是读者行为与信息收益率之间的关系分析。
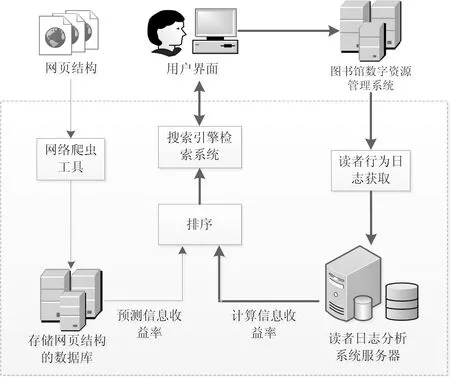
图2 读者信息觅食结构模型图
4.2读者在数字平台上的行为数据采集
杨晶晶提出的基于用户隐性反馈的搜索排序策略模型,利用用户的隐性反馈来衡量搜索引擎返回结果的好坏,用户隐性反馈数据的采集直接影响到算法的好坏[10]。本文采用的是直接读取服务器上读者访问日志,先对原始日志数据数据预处理,保存在数据库中。当用户访问图书馆的数字资源访问系统时,系统会在后台记录下读者的每一步操作日志。例如读者选取的是哪个数据库、输入的检索词是什么、之后点击了那些链接、下载了那些文章或电子书,都可以读者的访问日志里面记录下来。本文数据抓取采用直接对服务器上的访问日志文件进行分析过滤。日志处理步骤如图3所示。

图3 读者在数字平台上的行为数据获取
从系统中抓取的读者访问日志包括用户IP 地址、用户ID、用户请求访问的URL 页面、请求方法、访问时间、传输协议、传输的字节数、错误代码、用户代理等属性。电子资源访问系统的日志文件同时也记录了每个读者访问的页面、访问时间、检索词、检索内容、下载内容等。实验采用日志解析工具直接对web日志文件进行解析,把解析到的数据存储到MySQL数据库中。数据库存储读者访问日志记录如表1所示,主要包括读者的访问、检索、下载记录等。
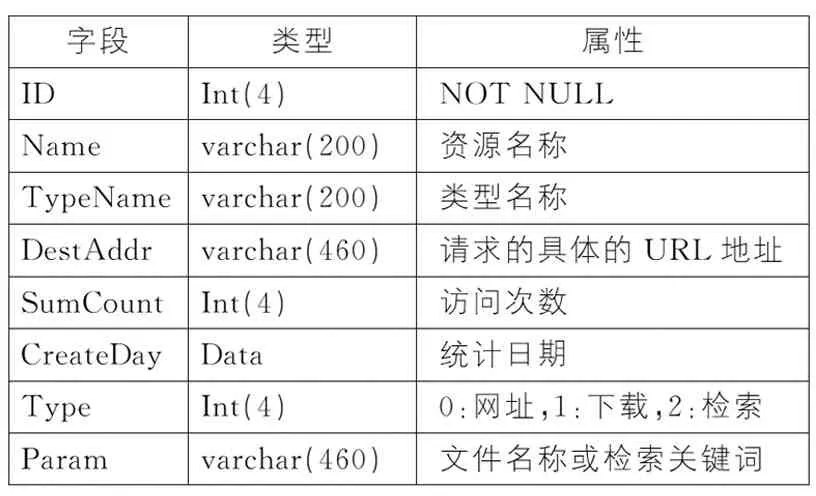
表1 读者访问日志记录表
4.3读者行为和信息收益的关系分析
有学者通过研究用户阅读新闻的行为,发现阅读时间是衡量用户的信息收益的关键性指标[12]。杨晶晶在研究中用页面浏览时间、用户拖动垂直下拉条时间、外链的点击次数以及用户的主观评价来衡量用户的满意度,也有研究发现用户的综合行为更能准确的衡量其满意度[10]。找到用户行为和G值之间的关系,从而得到各种行为对用户搜索满足的影响程度,将此与搜索结果页面上的用户行为相结合,作为搜索结果排序的依据。
一般认为页面的信息收益g与用户信息收集的表现关系密切,因为用户收集的信息都来自于其浏览过的网页的贡献,而用户收集信息的表现又可以通过用户行为来表示。将用户行为中蕴含的信息收益情况释放到每个被浏览过的页面中,计算每个页面中发生的用户行为多少,以此代表每个页面的信息收益。数字资源平台上获取的读者行为数据包含的隐性指标有读者在每个链接页面的停留时间、是否下载、标页面(文章)的下载量和被引量等。选取读者的检索次数、页面停留时间、下载行为这三个隐性行为数据作为衡量读者收益率的关键因素,来分析读者行为和用户信息收益的关系,如图4所示。

图4 读者行为和用户信息收益的关系分析
借助SPSS分析软件对读者历史行为数据进行分析,采用相应的数据挖掘算法对其进行数据挖掘,来分析这三个指标与信息收益的关系,得到这三个参数与信息收益之间的关系函数。用训练出的关系函数来预测每个读者在未来页面上的信息收益,以页面的信息收益率来衡量用户应当查看页面的优先程度,将信息含量最丰富的模块排在最前面提供给查询请求的用户。当用户在此搜索平台检索信息时,平台的“排序”模块将页面按照信息收益率降序排列后展现给用户。
5结语
本文借鉴动物生态学中的最优觅食原理,将读者在图书馆数字资源平台上的学科信息搜索行为和需求满足看作是动物的觅食过程,通过最优化分析模型预测读者在数字资源平台的觅食策略,建立基于用户行为反馈的读者信息觅食模型,为读者开展个性化的学科服务。文中只对读者的信息觅食行为做了模拟分析,研究的范围也不够全面,有很多相关的工作需要做更深入的探讨,例如信息收益率的详细度量方法,排序机制等,在以后的研究中会逐步进行完善。
参考文献
[1]Pirolli P. Information Foraging Theory[M]. New York: Oxford University Press, 2007:31-35
[2]周欣. 国内师范类高校图书馆学科服务调研分析[J]. 科技情报开发与经济,2015,16:67-69
[3]Stephens D W, Krebs J R. Foraging Theory[M]. NJ: Princeton University Press, 1986:3-36
[4]杨阳,张新民. 信息觅食理论的研究进展[J]. 现代图书情报技术,2009(1):73-79
[5]崔宇. 群体信息觅食中的干扰效应作用研究[D].北京:北京邮电大学,2012:9-17
[6]柯青,王秀峰. Web导航模型综述——信息觅食理论视角[J]. 现代图书情报技术,2014(2):32-40
[7]徐芳,孙建军. 信息觅食理论与学科导航网站性能优化[J]. 情报资料工作,2015(2):46-51
[8]彭璧玉,熊冠星. 基于觅食原理的职业搜寻理论研究[J]. 中国劳动经济学,2011(1):176-191
[9]陈雅,谭华军,郑建明. 图书馆个性化服务中的Web日志分析技术研究[J]. 图书馆杂志,2011(7):43-46,54
[10] 杨晶晶. 基于用户隐性反馈的信息觅食模型研究[D].北京:北京邮电大学,2011:9-15
[11] 付特. 基于用户日志分析的搜索引擎排序算法的设计与实现[D].武汉:武汉理工大学,2013:31-40
[12] Morita M, Shinoda Y. Information filtering based on user behavior analysis and best match text retrieval[C]// Proceedings of the 17th Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval. Dublin, Ireland: Springer-Verlag, 1994: 272-281
Study on the Subject Service of Digital Library Based on Information Foraging Theory
Zhou Xin
(Library of Nanjing Xiaozhuang University, Nanjing 211171)
[Abstract]In reference to the optimal foraging principle of animal ecology, we analyze the behavior data of the readers in the digital resources platform, and establish the reader information foraging model based on reader behavior feedback data. Through optimization analysis model, the foraging strategy of the readers in the digital resource platform is forecasted to improve the reader’s information foraging ability, and eventually to achieve the purpose of subject service.
[Key words]Information foragingUser behavior feedbackLog analysisSubject serviceDigital information service
[基金项目]本文系南京晓庄学院青年专项“基于信息觅食理论的数字图书馆学科服务模式研究”(2013NXY84)的成果之一。
[作者简介]周欣,女,硕士,助理馆员,研究方向为图书馆学,信息资源管理,Email:zhouxin0724@163.com。
[中图分类号]G250
[文献标识码]A
[文章编号]2095-2171(2016)02-0101-06
DOI:10.13365/j.jirm.2016.02.101
(收稿日期:2015-09-30)
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14
华人时刊(2021年13期)2021-11-27 09:19:02
今日农业(2020年20期)2020-12-15 15:53:19
心声歌刊(2020年4期)2020-09-07 06:37:14
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
金色年华(2016年1期)2016-02-28 01:38:19
IT时代周刊(2015年8期)2015-11-11 05:50:38
电子设计工程(2014年19期)2014-02-27 12:00:42
土木建筑工程信息技术(2013年4期)2013-10-17 02:27:50
电脑爱好者(2011年11期)2011-06-22 08:20:18
