
基于Nutch技术的垂直搜索引擎设计与实现*1
2016-07-21 00:50卜天然
通化师范学院学报 2016年4期
卜天然
(安徽商贸职业技术学院,安徽 芜湖 241002)
基于Nutch技术的垂直搜索引擎设计与实现*1
卜天然
(安徽商贸职业技术学院,安徽 芜湖 241002)
摘要:在研究垂直搜索引擎的设计思想、相关技术的基础上,利用Nutch开源框架设计实现了农业环境信息的垂直搜索引擎,支持了对特定信息的检索服务.系统采用了网页模板技术对网页信息进行提取,采用改进的TF-IDF算法提取特征词,利用基于特征词的向量空间模型进行主题相关性判定,利用朴素贝叶斯算法对网页信息进行分类.测试结果表明,改进后的Nutch具有更高的查询准确率.
关键词:Nutch;垂直搜索;信息提取
第37次《中国互联网络发展状况统计报告》中明确指出,截至2015年12月,中国网民规模达6.88亿,互联网普及率达到50.3%[1],网络已渗入到人们工作、生活的方方面面.随着Web2.0技术的高速发展,网络资源呈几何式增长.如何在海量的互联网信息中快速、准确地搜索到有用的信息,成为搜索引擎所要应对的一大挑战.在实际使用中,通用搜索引擎由于要面对互联网上所有的信息资源,使得返回给用户的信息结果并不能达到预期的效果.所以,出现了只针对某一个主题下信息检索的搜索引擎——垂直搜索引擎,垂直搜索引擎解决了通用搜索引擎对于互联网信息利用率低,而对于某一领域信息覆盖率又不高的问题.
1基于Nutch的搜索引擎设计思路
Nutch作为一个开源网络爬虫,其主要工作就是按照制定的规则从互联网上爬取网页并将爬取下来的网页分析处理后提取出有用信息建立倒排索引.Nutch的整体架构如图1所示.
利用Nutch插件机制扩展网络爬虫的功能,通过融入网页模板、向量空间模型(VSM)、朴素贝叶斯分类算法等重要技术,完成了信息提取、主题判断、信息分类,以及索引构建工作.该垂直搜索引擎的详细设计思路如下:
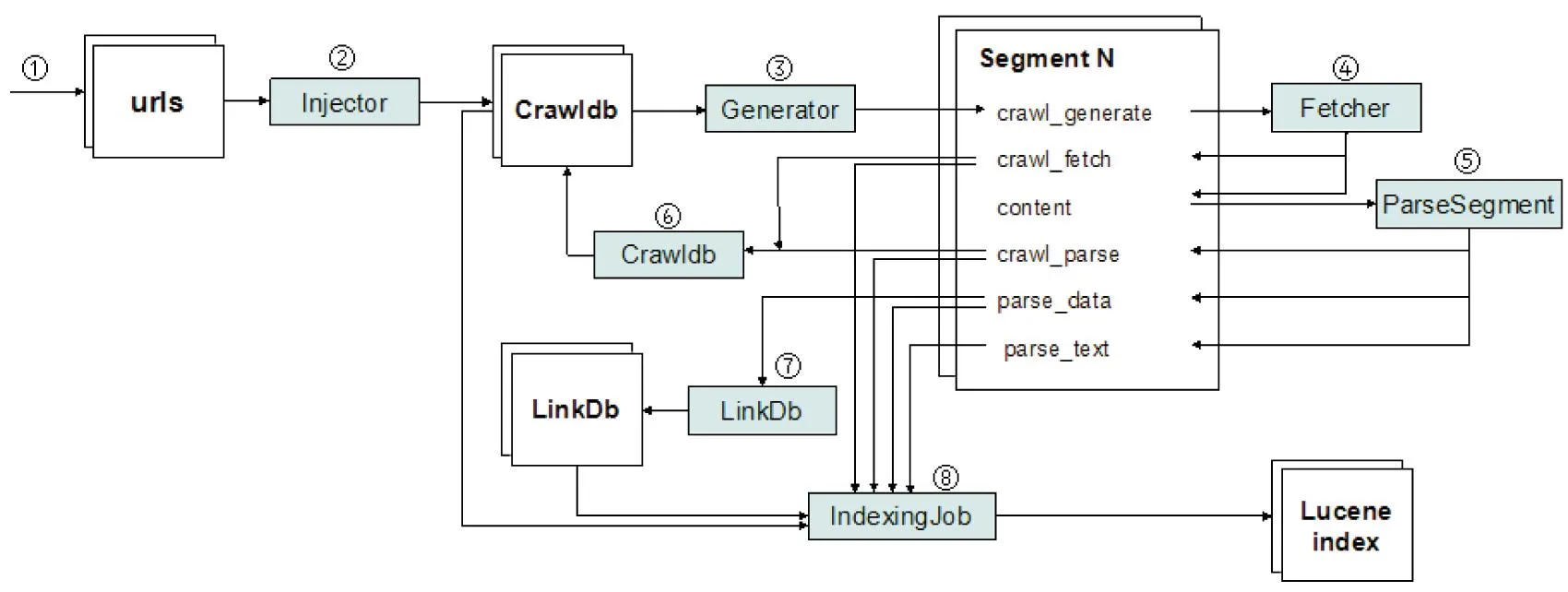
图1 Nutch的整体架构图
(1)搭建Nutch爬虫的运行环境.
(2)通过人工专家的方式选取网页爬行的初始网站.
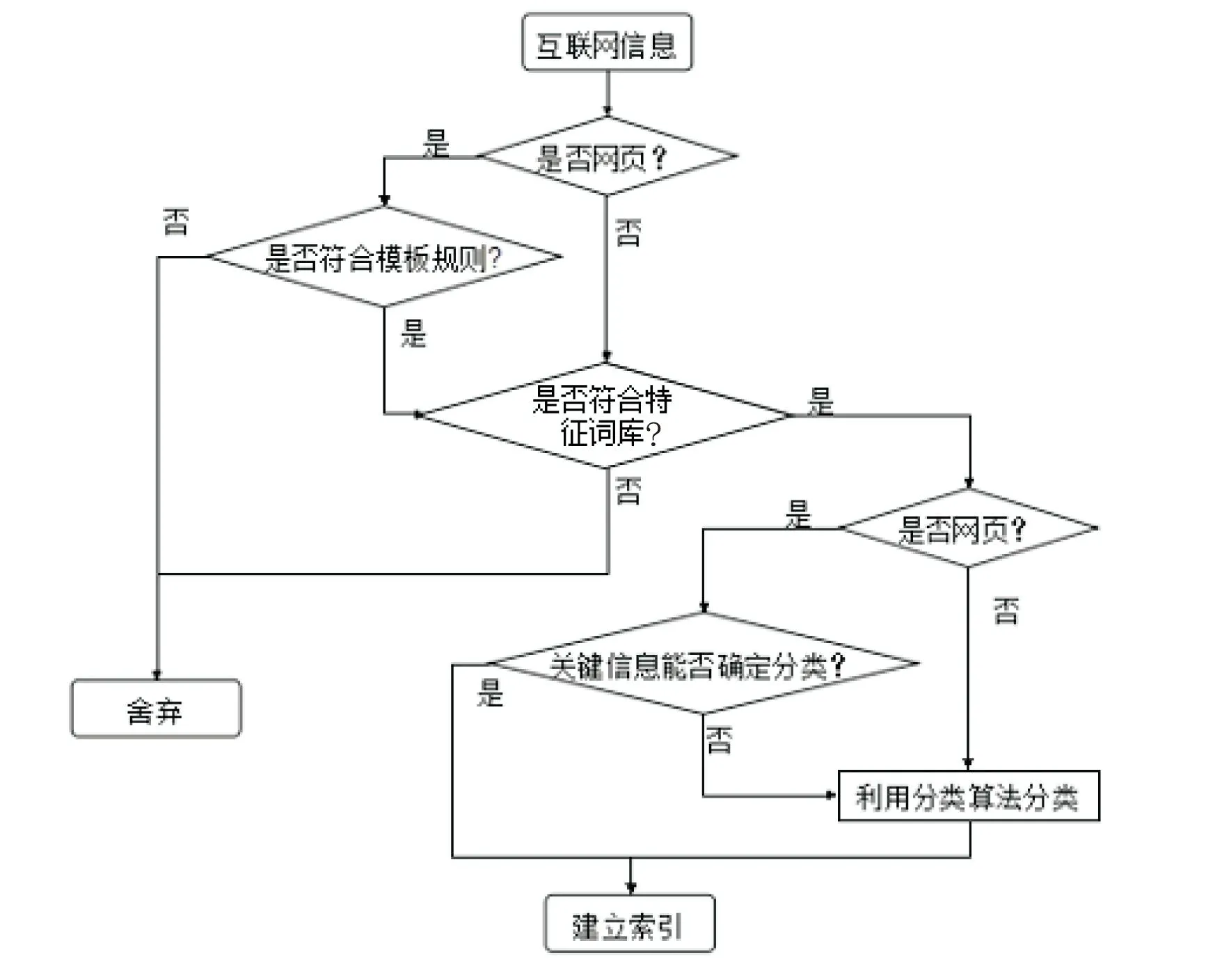
图2 信息提取、分类、索引工作流程示意图
(3)配置Nutch,限制Nutch可爬行的网站,并利用Nutch工具在限定的网站中爬取网页,获取原始网页信息.
(4)利用Nutch插件机制扩展网络爬虫的功能,通过融入网页模板、向量空间模型(VSM)、朴素贝叶斯分类算法等重要技术,完成了信息提取、主题判断、信息分类,以及索引构建工作.其工作示意流程如图2所示.
2特征词库的确定
本文设计和实现的垂直搜索引擎在两个地方需要使用特征词库,一个是在主题相关性判断时配合向量空间模型使用的主题词库,一个是在网页信息分类时配合朴素贝叶斯分类算法使用的分类特征词库[2].无论是主题词库还是分类特征词库其生成方法都是对某一类样本文档集合中所包含的词或短语的权重进行计算,然后通过设定阀值的方式选取能够代表该类特征的词或短语构成特征词库.
2.1权重的计算方法
特征词的权值计算有许多种方法,常见的有:
(1)词文档频率,这是指某一个词或短语在文档集合中出现的次数.
(2)词频,这是指某一个词或短语在文档集合中所有文档集合中出现的总次数.
(3)TF-IDF算法.该算法包含两个因子,TF表示某个词或短语在一篇文档中出现的次数;IDF表示逆文档频率,它是衡量一个词是不是常见词的因子,是由总文档数目除以包含该词的文档数目得到的.TF-IDF算法的主要思想是如果某个词或短语在某一篇文档中出现的频率高,并且在其他文档中很少出现,则认为该词或者短语对于该文档具有好高的价值[3].
TF的计算公式为:
(1)
其中ci,j表示词i在文档j中出现的次数,∑kck,j表示文档j中包含的词的次数的总和.TFi,j表示词i的词频,上式除以∑kck,j是考虑到文档有长短之分,所以进行了标准化.
IDF的计算公式为:
(2)
其中N表示文档集合中的文档总数,ni表示包含词i的文档数,N+2是为了防止IDFi出现非正数的情况,ni+1是为了防止分母为零.
这样结合公式(1)和(2)得到求解TF-IDF的公式:
(3)
上式(3)表示词i在文档j中的TF-IDF值,如果求解词i在文档集合中的TF-IDF值,就需要将每篇文档中关于词i的TF-IDF值进行求和,则式(3)变成:
TF-IDF=∑d(TFi,n*IDFi)=
(4)
本文中需要提取每一个类别文档的特征词,而TF-IDF算法考虑了词或短语在某篇文档中频率,以及在文档集合中出现的文档频率,没有考虑到有可能存在某些权重值较高的词或短语在其他类别的文档集合中也具有较高的价值.所以本文利用IDF算法的思想,考虑如果一个词或短语在多个类别中出现,则其区分不同类别的价值就越低,反之,则越高.添加这样的计算因子就可以体现出词或短语在不同类别文档之间的价值.其公式则可以写成:
TF-IDFnew=
(5)
其中L表示总类别数,L+1是为了避免出现非正数的情况,li表示特征词i出现的类别数.
2.2特征词库选择步骤
本文主要根据公式(5)计算词或短语的权重,通过设定阀值删除权重低的词或短语.特征词库确定的工作步骤如下:
(1)选取不同类别的文档作为样本文档.本文对于主题词库除了选取400篇与农业信息环境领域相关的文档也选取了400篇不相关的文档作为样本文档;对于分类特征词库,每个类别选取150篇文档作为样本文档.
(2)利用IK分词器分别对各类文本进行中文分词,并去除停用词.
(3)利用Lucene技术对各类文本建立索引,并把结果保存在索引库中.
(4)利用Lucene提供的相关方法,首先在各类别中统计每一个词或短语在集合中的每一篇文档中出现的次数,以及计算该篇文档出现所有词的总次数;然后统计该词或短语在该类文档集合中出现的文档频率,以及该类文档集合中拥有的文档总数;最后统计该词或短语出现的类别,以及总类别数.
(5)利用上一步获取的相关数据,利用公式(5)计算在每一类别样本文档集合中的每一个词或短语的权重,并将这些词或短语按照权重的大小排序.
(6)通过设定阀值去除权重低的词或短语,确定最终的特征词库.
特征词库训练流程如图3所示:
3主题相关性判别的实现
垂直搜索引擎最后用于建立索引库的信息都是属于同一个主题的,这就需要在搜索引擎实现过程中对抓取到的信息进行主题相关性判断,过滤掉与主题相关度不大的信息[4].主题相关性判别保证了用户通过垂直搜索引擎检索所需的信息时,得到的返回结果更加的专业和准确.因此,搭建高性能的垂直搜索引擎,就需要选择一个优秀主题相关性判定方法.本文采用了基于主题词库的向量空间模型来进行主题相关性判定.
3.1向量空间模型
向量空间模型(VSM)将一个文本或其中的某一个文本片段(段落或句子)看成一个文档(Document),并认为所有的文档都是由一系列字、词、短语组成.这些组成文档的基本单位则称为项(Term),所以一篇文本则可以表示成:
D=D(t1,t2,t3,…,tn-1,tn)
(6)
其中D表示一篇文档,ti表示文档中的项,每个项表示一个维度,文档可以看成是项的集合.
在文档中,每个项对这个文档的重要程度是不同的,所以,每个项都该被赋予一定的权重(Weight).这样一篇文本则可以表示成:
D=D(t1,w1;t2,w2;t3,w3;…;tn-1,wn-1;tn,wn;)
(7)
其中wi表示项的权重,ti,wi表示ti在文档D中权重为wi.实际表示中,因为每一篇文本中出现的词或短语都是有先后顺序的,所以根据这种先后顺序就可以判定每个位置上对应的词,所以(7)式一般可简写成:
D=D(w1,w2,w3,…,wn-1,wn;)
(8)
在向量空间模型中,任何一篇文档都可以用(8)式来表示成一个向量,这个向量通常称之为该文档的特征向量.所以如果需要计算两篇文档之间的相似性,则可以将两篇文档分别表示成向量,通过计算向量之间的相似性来确定文档之间的相似性.文档的相似性计算通常使用向量间的余弦距离来表示[5].如果存在两个文档D1和D2,它们的向量表示形式分别为D1=(W11,W12,…,W1n)和D2=(W21,W22,…,W2n),则文档的向量空间模型图可以用图4所示.
图4可以看出文档D1和D2之间的相似度越高,则两篇文档表示成的向量之间的夹角θ则越小,而余弦值cosθ则越大.所以利用向量余弦值表示文本之间相似度的向量空间模型的计算公式可以表示为:
(9)
3.2主题相关性判别方法
向量空间模型可以将文档表示成向量,可以使用向量之间的余弦距离表示文档之间的相似度.具体实现方法如下:
(1)根据2.1节所提供的方式,确定农业信息环境领域的主题词库(k1,k2,…,kn),并利用公式(5)计算词库中词或短语k的权重W1k,得到主题词库的特征向量D1=(W11,W12,…,W1n),其中n表示主题词库中关键词的个数.
(2)对于网络爬虫抓取下来的原始数据,通过网页模板等方式获取其中需要的内容,再利用IK分词器对网页文本进行分词,得到该网页的分词集合(t1,t2,…,tm),其中m为该网页中分词的总数.
(3)以主题词库特征向量的维度为标准,根据主题词库中的特征词对分词后得到的网页的分词集合进行相关操作[6].在网页的分词集合中去除掉主题词库中不存在的词,添加在主题词库中存在的词但在网页分词集合中不存在的词,并将其权重设为0,保留在主题词库中也存在的词,并将其权重设为1,最终得到与主题词库特征向量同样维度的网页特征向量D2=(W21,W22,…,W2n).
(4)利用公式(9),计算主题特征向量D1=(W11,W12,…,W1n)和网页特征D2=(W21,W22,…,W2n)之间的余弦距离,并将得到的值作为判定该网页与农业环境信息主题领域的相关度大小的判定值.
设定阀值,若网页与农业环境信息主题领域的相关度大于设定的阀值,则认为网页所包含的信息属于农业环境信息主题领域,并在建立索引时,将与网页相关的信息保存在索引数据库中;反之,则认为该网页与农业环境信息主题领域无关,舍弃该网页.
4搜索引擎系统模块设计
本文实现的垂直搜索引擎可以分成三个模块.第一个模块为采集模块,该模块主要是使用网络爬虫在互联网中抓取网页信息,具体工作包括设置初始种子、生成抓取队列、获取原始网页内容、获取新的URL、更新抓取队列等.第二个模块为索引模块,该模块是对采集模块中下载的原始网页进行分析,提取其中有用的数据,并把数据以Lucene索引文件形式保存起来,本文在该模块主要的工作包括中文分词、网页信息提取、网页信息分类、主题相关度判定以及索引构建.第三个模块为检索模块,该模块主要为搜索引擎和用户之间搭起交互的桥梁,本文在检索模块提供了用户检索接口,用户可以在UI界面中的搜索框里输入查询信息从索引库中获取相关的信息.本文搭建的农业环境信息垂直搜索引擎的体系结构如图5所示.
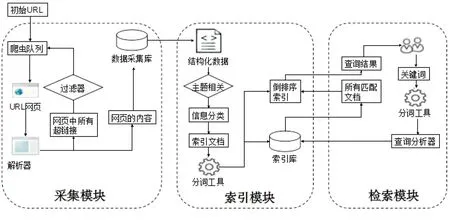
图5 基于Nutch的垂直搜索引擎体系结构图
5搜索引擎系统的搭建
Nutch是一个运行在Linux系统下的项目,在使用之前,需要先搭建它的开发环境.本文选择在Ubuntu系统下搭建Nutch开发环境.搭建步骤如下:
(1)分别从官网上下载Tomcat、JDK、SVN工具并进行安装.安装Tomcat是为了运行Solr的Web客户端程序;安装JDK是为了提供Java的开发环境.Nutch是Java语言开发的,所以对Nutch进行二次开发,以及运行Nutch都需要Java开发环境;安装SVN是为了编译Nutch项目,管理Nutch源代码.
(2)下载合适的Nutch版本.Nutch下载后,需要修改conf/nutch-site.xml文件,添加自己的代理名称.修改内容如图6所示.

图6 nutch-site.xml配置代理信息
(3)使用Nutch抓取网站时有时会出现某些网站被跳过的情况,这是因为这些网站的页面内容采用了truncate的方式分段返回,而nutch默认是不能够处理这种情况的,这就需要修改conf/nutch-site.xml文件,使Nutch能够处理这种方式,具体修改内容如图7所示.

图7 nutch-site.xml配置网页truncate方式分段返回
(4)下载合适的Solr版本.下载后,需要将Solr和Tomcat进行整合.
首先需要将Solr中的example中solr文件夹拷贝到自己建立的Solr服务器目录下(/home/zhangfei/spiderspace/solrhome/solr).
之后将Solr的web程序(solr.war)也拷贝出来,解压放到Solr的web程序目录下(/home/zhangfei/spiderspace/solrserver/solr).
(5)接下来需要在Solr配置文件solrconfig.xml中修改索引数据存放的位置,修改内容如图8所示.
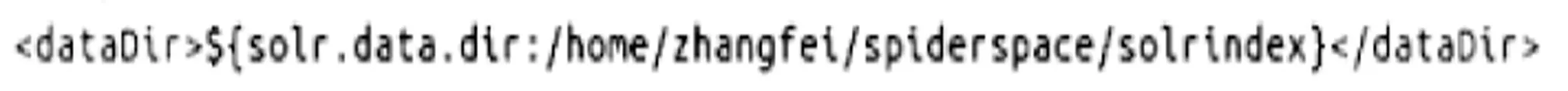
图8Solr管理索引数据位置
(6)最后需要在Tomcat的server.xml文件中配置Solr的相关信息,包括Solr服务器信息以及Solr的web程序相关信息,配置内容如图9所示.
图9server.xml配置信息
(7)将Nutch与Solr进行整合.Nutch与Solr进行整合只需要将Nutch的conf目录中的schema.xml文件拷贝到Solr的conf目录下进行替换.
(8)扩展搜索引擎的分词器,将IK中文分词器与Solr进行整合.将IK分词器所需的架包拷贝到Solr的web工作目录下的lib文件夹中,将IK分词器的配置文件IKAnalyzer.cfg.xml,相关词典拷贝到Solr的conf目录下面.最后只需要在schema.xml文件中配置上IK分词器的相关信息就可以让Solr使用该分词器了,配置内容如图10所示.

图10配置IK分词器
至此Nutch的开发环境就搭建完成了.如果想要使用Nutch抓取网页还需要利用ANT工具对配置好的Nutch进行编译.完成编译后,就可以通过输入Nutch的抓取命令,让Nutch按照预先设定好的规则抓取网页了.
6系统运行和测试
本系统Nutch经过二次开发后,可使用Ant工具进行编译,编译后的Nutch目录下会出现一个runtime文件夹,该文件夹是Nutch的运行文件夹,本文在runtime文件夹中选择local本地运行模式运行Nutch爬虫,通过输入命令运行Nutch脚本文件.Nutch抓取的运行命令为:
bin/crawl
其中bin/crawl是Nutch运行命令,后面的为运行所需的参数,seedDir为Nutch的种子文件存放文件夹;crawlDir为存放Nutch抓取数据、分析数据的文件夹;solrURL为配置的solr访问地址,numberOfRounds表示爬虫需要抓取的深度.
输入bin/crawl urls data/crawldb http://127.0.0.1:8080/solr 1后Nutch爬虫运行界面如图11所示.
图11 Nutch运行测试界面
在测试中,系统选取了400篇“农业环境信息”作为类别特征词库的实验文档,同样对使用通用搜索引擎和垂直搜索引擎进行实验对比,得到实验对比结果如表1所示.
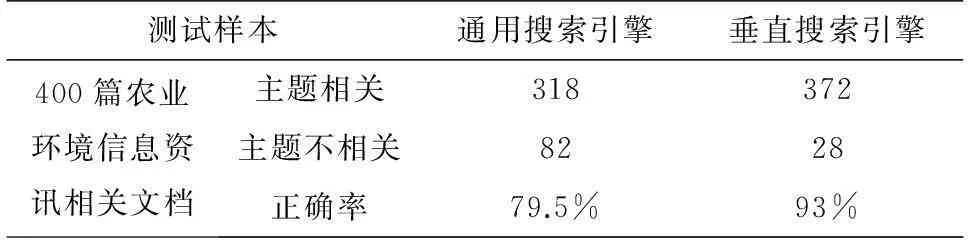
表1 主题词库实验测试结果
通过实验可以看出,选择改进的TF-IDF算法计算词的权重,经过筛选构成的特征词库相比其他方法在主题相关性判别中能最有效选择农业环境信息领域相关的文档,去除非农业环境信息领域相关的文档,在信息分类中,该方法得到的特征词库也能够最有效地将文档进行归类,所以本文选择这种方案进行特征选择.
7结束语
本文以搭建农业环境信息领域的垂直搜索引擎为需求背景,利用Nutch开源框架,结合网页模板、向量空间,以及朴素贝叶斯算法等技术,实现了垂直搜索引擎的开发.本文实现的搜索引擎系统的开发环境为Ubuntu+Eclipse+Tomcat,利用了Nutch、Solr以及Lucene开源工具完成了系统框架的搭建.实验证明,完成的搜索引擎初步实现了对农业环境信息相关信息检索的工作,降低了该领域工作人员信息获取的难度.
参考文献:
[1]中国互联网络信息中心.中国互联网络发展状况统计报告[R].2016.
[2]Guo Q, Guo H, Zhang ZQ,et al. Schema Driven and Topic Specific Web Crawling [G]//Database Systems for Advanced Applications. Springer Berlin Heidelberg,2005: 594-599.
[3]刘策.垂直搜索引擎发展前景分析[J].中国科技成果,2006(13):46-47.
[4]梁春燕.Internet主题搜索引擎设计与研究[M].北京:中国水利水电出版社,2012,2.
[5]王学松.Lucene+Nutch搜索引擎开发[M].北京:人民邮电出版社,2008.
[6]梁斌.走进搜索引擎[M].北京:电子工业出版社,2007.
(责任编辑:王前)
DOI:10.13877/j.cnki.cn22-1284.2016.04.002
*收稿日期:2016-03-14
基金项目:安徽省省级自然科研重点课题“农业环境信息监测传感器网络数据采集优化研究”(KJ2012B067)
作者简介:卜天然,男,安徽芜湖人,讲师, H3C网络高级工程师.
中图分类号:TP274
文献标志码:A
文章编号:1008-7974(2016)02-0004-05
