
TCP SACK突发分组丢失吞吐量模型
2016-07-18 11:50王志明曾孝平李娟刘学陈礼
通信学报 2016年3期
王志明,曾孝平,李娟,刘学,陈礼
TCP SACK突发分组丢失吞吐量模型
王志明,曾孝平,李娟,刘学,陈礼
(重庆大学通信工程学院,重庆 400044)
利用Gilbert分组丢失模型描述端对端突发分组丢失特性,提出了基于RFC6675的快重传和快恢复模型,推导并基于该模型建立TCP SACK吞吐量模型。数值实验和仿真实验表明,快重传和快恢复模型能准确描述基于RFC6675的快重传和快恢复过程;TCP SACK流吞吐量模型估计的准确性得到提升。
TCP SACK;快重传和快恢复;吞吐量模型;时延带宽积
1 引言
2012年,IETF(Internet engineering task force)在TCP协议中引入了基于SACK(selective acknowledge)的新分组丢失恢复机制——RFC6675,以提升突发分组丢失下TCP的性能[1,2]。基于SACK的分组丢失恢复机制,与SACK选项一起构成了基于SACK的快重传和快恢复机制,TCP的SACK扩展已得到广泛部署和使用。TCP SACK协议就是使用了SACK扩展的TCP协议。在采用SACK扩展的网络中,目前还没有基于RFC6675的TCP吞吐量模型,为准确评估采用SACK扩展的TCP协议在突发分组丢失下的性能,建立突发分组丢失下基于RFC6675的TCP SACK吞吐量模型非常必要[3,4]。
在现有的TCP SACK的吞吐量模型中,为快重传和恢复阶段网络中未被确认分组的估计数,对快重传和快恢复阶段的分析大多都是基于在快恢复阶段每收到一个重复ACK,变量就减小1,每收到一个部分ACK,变量就减小2的假设[3,4]。然而,RFC 6675中采用了更新和新的分组丢失判定策略[1]:1)中去除了已经被发端断定丢失的分组;2) 一个分组是否被判为丢失取决于收到大于其序号分组的个数或总数据块的大小。这就造成分组的重传和恢复过程发生变化,导致现有模型对基于SACK的快重传和快恢复过程描述不准确。另外,现有模型对快重传和快恢复阶段的分析都忽略了在重传最后一个丢失分组前发送的新分组。实际上,在基于SACK的快重传和快恢复阶段,发端在重传第一个丢失和重传最后一个丢失之间可能发送新分组。在低随机分组丢失情况下,一个窗口发生多个分组丢失的概率非常小,这种发送新分组的情况可以忽略,但在突发分组丢失下,一个窗口中常常发生多个分组丢失,忽略发送新分组的情况就会造成对快重传和快恢复阶段发送分组数及其持续时间的计算不准确,从而影响TCP SACK吞吐量模型的准确性。
由于现有TCP吞吐量模型中已有大量关于标准TCP的建模和分析,因此,本文重点推导了快重传和快恢复阶段发送分组数及其持续时间的期望,即基于RFC6675的快重传和快恢复模型,并基于该模型建立了TCP SACK吞吐量模型。
2 突发分组丢失模型
近年来,网络分组丢失统计特性和相关研究一致表明[5~10],互联网分组丢失率很小,但分组丢失具有突发性,且突发分组丢失率远高于网络平均分组丢失率,实时监测结果显示一些链路的突发分组丢失率甚至高于10%[11]。Gilbert模型是Gilbert提出的两状态马尔可夫链的差错模型,研究发现89%的网络分组丢失符合Gilbert模型[5]。近年来,基于Gilbert模型的分组丢失模型被广泛用于TCP吞吐量建模[5,10]。因此,本文采用Gilbert分组丢失模型描述TCP流的端对端突发分组丢失特性,并假设突发分组丢失率大于5%。
Gilbert分组丢失模型,如图1所示,有2个状态(和)和3个参数(、和)。表示突发状态,在突发状态下分组丢失率为,表示非突发状态,状态下分组不丢失,一旦发生分组丢失就会转入突发状态,其转移概率为,也称为突发事件率。到的转移概率为,由此可以得到突发持续时间,()=。
3 基于RFC6675的快重传和快恢复模型
基于RFC6675的快重传和快恢复建模就是计算快重传和快恢复阶段发送分组数的期望及其持续时间的期望。在基于RFC6675的快重传和快恢复机制中,接收端最多使用4个数据块告知发端已经收到不连续的数据块。发端根据每次收到的含有SACK信息的ACK,判断窗口中分组的状态,在窗口允许条件下决定重传分组或发送新分组[1]。当发端检测到分组丢失并重传后,发端进入快恢复阶段,此时网络中最多还有个分组。为实现快重传和快恢复建模,本节首先对快重传和快恢复阶段发送分组数的期望进行分析建模,然后根据发送分组数和持续时间的关系,得出持续时间的期望。本节用到的符号定义如表1所示。

表1 符号定义
与文献[4,5,10]中的假设类似,为方便推导,提出如下假设。
1) 重传分组不丢失。
3) 拥塞窗口为最大突发长度。窗口中除第一个丢失外,其他分组的丢失概率为突发分组丢失率。
4) 若序号为的分组未被确认而序号为+3的分组被选择性确认,则认为序号为的分组丢失。
5) 发端进入快重传前收到重复ACK不发送新分组。
3.1 快重传和快恢复模型及其近似简化
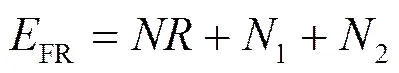
1) 重传分组数的期望
在无超时的情况下,发现第一个丢失时,仍有−个分组在网络中,其余−1丢失发生在剩余的−个分组中。因此,快重传和快恢复阶段重传分组数的期望等于窗口中的丢失分组数的期望,即
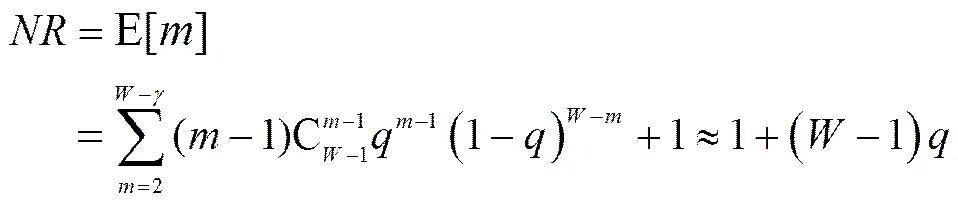
2)2的计算
当发端重传最后一个丢失分组后,每次收到一个重复ACK或部分ACK,减小1,这就允许发端发送一个新分组(拥塞窗口始终为)。直到收到最后一个重传分组的ACK,发端可以发送的新分组数为−1,这个阶段发送分组数与丢失数无关。因此,重传最后一个分组到收到其确认之间发送新分组数的期望为
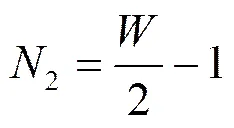
3)1的推导
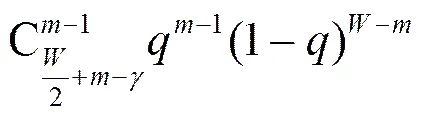
(5)
综上所述,在重传第一个分组丢失和重传最后一个分组丢失间发端发送的新分组数的期望1为
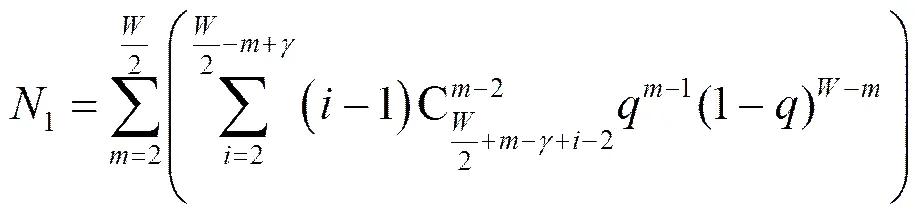
将式(2)、式(3)、式(6)代入式(1)即可得到基于SACK的快重传和快恢复阶段发送新分组数的期望。
(7)
在基于SACK的快重传和快恢复中,由于始终被拥塞窗口限制,发端每一重传周期只能发送个分组。另一方面,在快重传和快恢复阶段,就算只有一个丢失,快重传和快恢复至少持续一个重传周期。因此,可以由FR得到FR为
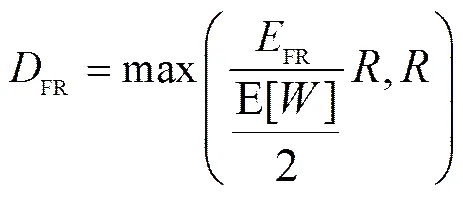
FR表达式中的1过于复杂,为易于将FR用于TCP吞吐量建模,需对1进行简化(=3)。图2通过三维曲面给出了1随窗口和突发分组丢失率的变化情况。在不变情况下,1随先增大后减小;>0.5时,1近似为0。当0.05<≤0.5时,在不变的情况下,1随窗口逐渐增大。图3为当0<<0.5时,1随的变化情况。当0.05<≤0.5时,1随线性减小。图4为当0.05<≤0.5时,1随的变化情况。当0.05<≤0.5时,1随线性增大。因此,当0.05<≤0.5时,1可利用和的线性函数逼近。在>0.5情况下,由式(6)易得1近似为0。在突发分组丢失率>5%的假设下,采用回归分析法得到1,如式(9)所示,简化结果与如图5所示,其简化误差小于1%。
(9)

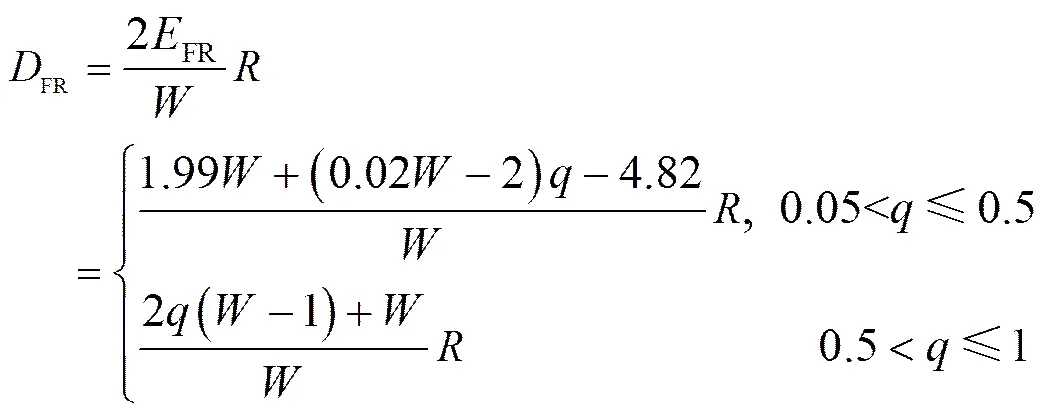
至此,基于RFC6675的快重传和快恢复阶段发送分组数及其持续时间的期望就已得出,即得到了基于RFC6675的快重传和快恢复模型(SFRR)。
3.2 SFRR模型数值实验
采用蒙特卡罗法通过软件模拟基于RFC6675的快重传和快恢复过程,并统计快重传和快恢复过程中发送分组的平均个数,并与模型估计结果对比。TST为采用部分ACK策略的吞吐量模型[3,4]对FR和FR的估计,Sim为给定突发分组丢失率下经过5 000次实验的平均值。
图6所示为在基于RFC6675的快重传和快恢复阶段发送分组数的期望FR随突发分组丢失率的变化。SFRR模型结果与模拟实验统计值相符合,而TST模型只有在=0和>0.5时才与基于RFC6675的快重传和快恢复发送分组数的期望相符。
图7所示为基于RFC6675的快重传和快恢复的平均持续时间FR随突发分组丢失率的变化情况。由图可见,当为0~0.5时,SFRR预测的FR从1个往返时延()迅速增加到逐渐逼近2个;当为0.5~1,FR逐渐增加到3。根据RFC6675,在第2个重传周期开始时,所有分组丢失都会被发现。当分组丢失数小于,在2个内就能重传完;当分组丢失数大于,则最多需要3个恢复所有分组丢失。而TST等基于部分ACK策略的重传协议在第一个周期能够重传的分组数随着丢失数的增加而减小。当分组丢失增加时,其恢复时间快速增加;当分组丢失数多余+1(近似为>0.5),则会由于重传完第一个分组丢失后不能发送新分组造成超时。
由图6和图7可知,本文提出的模型能够准确估计基于SACK的快重传和快恢复阶段发送分组的平均数FR和平均持续时间FR,现有吞吐量模型不适用于对FR和FR的估计。
4 TCP SACK吞吐量模型
不考虑超时TCP流的拥塞窗口的变化过程可以看作多个拥塞周期(TDP)的串联,一个TDP由一个拥塞避免阶段、一个快重传和一个恢复阶段组成的,TCP吞吐量建模就是对这样一连串TDP建模的过程。TCP吞吐量建模是对TCP流的稳态分析[4,5],假设:1) TCP流时间传输;2) 往返时延与拥塞窗口大小不相关;3) TCP SACK的快重传和快恢复采用RFC6675中的分组丢失恢复机制;4) 在Gilbert分组丢失模型中,突发分组丢失率>5%。
将TCP SACK的吞吐量建模分为2步:1)无超时情况下(<−3)的吞吐量模型(NTO);2)考虑超时的完整吞吐量模型FTM。记在一个TDP阶段内传输分组数的期望为TDP,持续时间期望为TDP,则其平均吞吐量为

4.1 无超时模型NTO
在不发生超时的情况下,发端至少收到3个重复ACK。在已知突发事件率,突发分组丢失率和突发长度E()情况下,则两次突发事件之间的发送分组数的期望为

用E[]、E[]和E[]分别表示在一次突发过程中发送分组数的期望、丢失分组数的期望和突发长度的期望(即最大拥塞窗口的均值)。当发现第一个分组丢失时,仍有E[]−1个分组在网络中。因此,余下的E[]−1个分组中包含E[]−1个丢失。假设E[]−1丢失服从均匀分布,则任意一次突发中分组丢失数的期望和在第一个丢失和最后一个丢失之间发送分组数的期望分别为
(14)
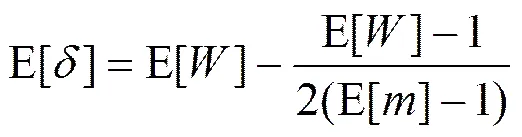
由此可得到一个TDP周期中发送分组数的期望为
(16)
TDP和TDP也可以表示为
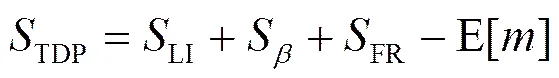
(18)
其中,LI和LI表示发端在拥塞避免阶段发送分组数的期望和持续时间的期望;S和D分别表示从第一个丢失后的下一周期开始到快重传第一个丢失期间发送分组数的期望和持续时间的期望。由文献[4, 10]可知

(20)
(21)
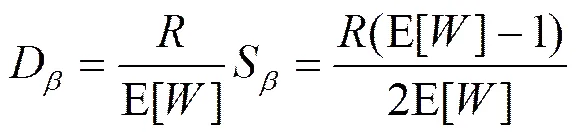
令式(17)和式(18)的右边相等可以得到
(23)
将式(10)对求期望后即为FR,与式(14)、式(19)和式(21)一起代入式(23),忽略高阶项可求E[]如下

最后将式(15)和式(17)代入式(12),并代入中间项可得到吞吐量的表达式如下
(25)
4.2 完整吞吐量模型(FTM)
考虑超时的情况下,TCP流传输过程可以看作一个个超时周期的串联,每个超时周期包含了一个慢启动、多个TDP和一个超时阶段[4,10]。记TO为超时概率,SS为慢启动阶段传送分组数的期望,SS为慢启动段持续时间的期望,TO为超时阶段持续时间的期望。则包含超时的TCP SACK吞吐量可表示为[4,12]
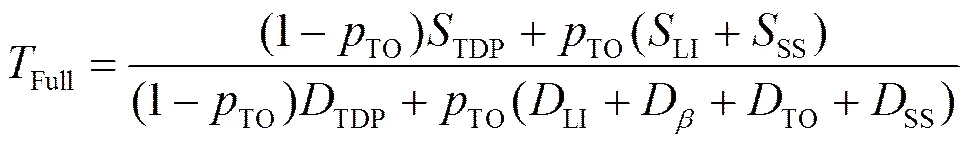
TCP SACK在2种情况会导致超时:1) 拥塞窗口里丢失超过−3;2) 快重传和快恢复阶段任意一个重传分组丢失。从快重传和恢复阶段开始,分组丢失发生的概率为下一次突发事件发生的概率。因此
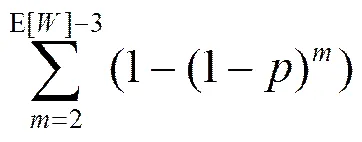
从文献[4, 12]可以得到SS、SS和TO,将其代入式(26),得到包含超时情况的TCP SACK吞吐量模型(FTM)
(28)
5 仿真验证
5.1 仿真场景
在NS2下采用如图8所示的哑铃拓扑仿真场景,R1和R2之间的链路为瓶颈链路,端对端往返时延约为70 ms,瓶颈带宽为50 Mbit/s,C1与S1之间的时延带宽积(BDP)约为7 Mbit/s,属于大BDP网络场景。仿真时间为200 s,统计结果取自50~200 s的多次仿真结果的均值。Padhye[13]和TST[3]模型的分组丢失率取平均分组丢失率。FTM表示包含超时情况的TCP SACK吞吐量模型,结果与Parvez[10]等对比。
5.2 模拟分组丢失下仿真分析
分别采用Gilbert分组丢失模型和随机分组丢失模型在R2到R1的端口上产生随机分组丢失,统计C1与S1之间TCP SACK流的吞吐量。图9~图11分别为各模型在不同突发分组丢失率场景、不同突发事件率场景和随机分组丢失率场景仿真结果,图例Measured为TCP SACK流的吞吐量测量结果。
结果显示在3种情况下,FTM能够准确地估计TCP SACK流的吞吐量。Parvez在突发事件场景下估计误差较小,在突发分组丢失场景下,其估计误差逐渐增大。由于Parvez和FTM的计算都采用突发分组丢失率,其估计误差主要来自与NewReno的分组丢失恢复算法和TCP SACK的差异,随着突发分组丢失率增加,其性能差别越明显。Padhye和TST在突发场景下均不能准确估计TCP SACK流的吞吐量。原因是在突发分组丢失模型下,总分组丢失率大于突发事件率,而Padhye和TST的计算都基于总分组丢失率,导致其吞吐量估计值远小于测量值。图9和图10的对比也表明,突发事件率对TCP SACK流吞吐量的影响要大于突发分组丢失率。在随机分组丢失场景下(如图11所示),当分组丢失率较小时,几种模型的估计值都比较接近测量值。当随机分组丢失率较大时(>1%),Parvez和FTM的估计值好于Padhye和TST。因为当随机分组丢失率较小时(多为单个分组丢失),几种协议的分组丢失恢复过程一样。当分组丢失率很大时,与突发分组丢失的情况类似。图9~图11的结果表明,FTM能够准确估计随机分组丢失和突发分组丢失下的TCP SACK流吞吐量,Padhye和TST不适用于高分组丢失率或突发分组丢失下的吞吐量估计,Parvez不能于准确估计突发丢率下TCP SACK的吞吐量。
5.3 HTTP/FTP和UDP背景流下仿真分析
实验场景采用40个HTTP流/10个FTP流和10个UDP流分别作为背景流,HTTP与FTP业务占比为4:1,HTTP业务请求间隔服从均值为0.5的负指数分布,网页大小服从均值为48 KB的Pareto分布,UDP采用1 Mbit/s的CBR业务,背景业务流随机采用TCP NewReno或TCP SACK协议传输。
图12是在大BDP网络中当HTTP/FTP流的数量为50~90时TCP SACK流的吞吐量和模型估计值。当HTTP/FTP流数增加时,TCP SACK流的吞吐量逐渐减小,突发分组丢失率逐渐增大。这是由于在瓶颈带宽不变的情况下,当TCP流个数增加时,TCP流的平均带宽减小了。图12也表明模拟场景下网络分组丢失具有突发特性,突发分组丢失率在0.228~0.455。当HTTP/FTP流数增加时,FTM都能够准确估计TCP SACK流的吞吐量,Parvez的估计值的估计误差逐渐增加,Padhye和TST的估计值偏离测量值较远。这与在模拟分组丢失模型下的结果一致,Parvez的估计误差主要是由于在突发分组丢失下,TCP SACK分组丢失恢复算法与NewReno的不同;Padhye和TST不适用于突发分组丢失下TCP SACK的吞吐量估计。
图13是当UDP流的数量为10~40时TCP SACK流的吞吐量和模型估计值。当UDP流数增加时,TCP SACK流的吞吐量逐渐减小,突发分组丢失率减小。由于增加恒定比特率的UDP流导致瓶颈可用带宽减小,TCP流的平均带宽减小,限制了业务的突发性。结果显示,FTM都能够准确估计TCP SACK流的吞吐量,Parvez的估计误差逐渐减小,Padhye和TST的估计值仍然偏离较远。这也说明突发分组丢失率降低,基于突发分组丢失的吞吐量模型和非突发分组丢失的吞吐量模型趋于一致,且不同分组丢失恢复算法性能差别减小。
基于非突发分组丢失模型的TCP吞吐量模型中分组丢失是网络拥塞的标识,在基于突发分组丢失模型的TCP吞吐量模型中突发事件为拥塞标识。在突发分组丢失的网络中,网络总分组丢失率高于突发事件率,即网络拥塞的频率。Padhye和TST在突发分组丢失和大BDP网络中,其估计的吞吐量低于实际的吞吐量就是由于这个原因。另一方面,随机分组丢失模型可以通过突发长度为1的突发分组丢失模型模拟。因此,基于突发分组丢失模型的吞吐量模型可用于非突发分组丢失的网络,但该模型是基于突发分组丢失率大于5%的假设,因此,当突发分组丢失率远低于5%时,可能不准确。
6 结束语
本文利用Gilbert分组丢失模型描述端对端突发分组丢失特性,推导了基于RFC6675的快重传和快恢复模型,并基于该模型建立了TCP SACK吞吐量模型。基于RFC6675的快重传和快恢复模型给出了基于RFC6675的快重传和快恢复阶段发送数据分组数及其持续时间的期望,该模型只与进入快重传时的拥塞窗口大小、突发分组丢失率和往返时延有关,但该模型没有考虑分组全部丢失或重传分组丢失造成超时的情况。其近似表达式是基于高突发分组丢失率的假设的,并不适用于只有随机分组丢失的情况。TCP SACK吞吐量模型给出了TCP SACK吞吐量与突发分组丢失率、突发事件率、往返时延和超时时延的关系,与其他吞吐量模型类似,该模型是基于TCP流长时间传输的假设,即TCP流传输的稳态吞吐量模型,用于短时TCP吞吐量分析可能会存在误差。另外,根据网络分组丢失特性,模型中假设突发分组丢失率大于5%,如果突发分组丢失率远低于5%,结果可能会不准确。
数值实验验证了基于RFC6675的快重传和快恢复模型和其近似表达式的准确性。模拟分组丢失模型场景和不同背景流场景的实验表明,TCP SACK吞吐量模型能够准确估计TCP SACK流的吞吐量;现有TCP吞吐量模型(Padhye、Parvez和TST)均不适用于估计突发分组丢失网络下TCP SACK流的吞吐量。
[1] Blanton E, Allman M, Wang L, et al. A conservative loss recovery algorithm based on selective acknowledgment (SACK) for TCP[EB/OL]. http://tools.ietf.org/html/rfc6675, RFC 6675, 2012.
[2] Fan Y, Amer P. Non-renegable selective acknowledgments (NR-SACKs) for MPTCP[C]//International Conference on Advanced Information Networking and Applications Workshops. Barcelona, c2013: 1113-1118.
[3] 徐伟. TCP协议的性能建模研究[D]. 安徽: 中国科学技术大学, 2012.
Xu W. Study on performance modeling of TCP protocol[D]. Anhui, University of Science and Technology of China, 2012.
[4] Sheu T L, Wu L W. An analytical model of fast retransmission and recovery in TCP-SACK[J]. Performance Evaluation. 2007, 64(6): 524-546.
[5] 曾彬, 张大方, 黎文伟, 等. 基于Gilbert分组丢失机制的TCP吞吐量模型[J]. 电子学报, 2009, (08): 1728-1732.
ZENG B, ZHANG D f, LI W W, et al. A TCP throughput model based on gilbert packet loss pattern[J]. Chinese Journal of Electronics, 2009, 37(8): 1728-1732.
[6] Mehmood M A, Sarrar N, Uhlig S, et al. Impact of access bandwidth on packet loss: a flow-level analysis[C]//IEEE Malaysia International Conference on Communications (MICC). Kuala Lumpur, c2013: 259-264.
[7] Mehmood M A, Sarrar N, Uhlig S, et al. Understanding flow performance in the wild[C]//Global Communications Conference (GLOBECOM). Atlanta, GA, c2013: 1410-1415.
[8] Hasslinger G, Schwahn A, Hartleb F, et al. 2-state(semi-) Markov processes beyond Gilbert-Elliott: traffic and channel models based on 2nd order statistics[C]//2013 Proceedings IEEE Infocom. Turin, c2013: 1438-1446.
[9] Wang W, Kato T, Wu C, et al. Behavior analysis of different TCP implementations under burst error environment[R]. IEICE Tech Rep, Tokyo City University. c2014: 17-22.
[10] Parvez N, Mahanti A, Williamson C. An analytic throughput model for TCP newReno[J]. IEEE/ACM Transactions on Networking, 2010, 18(2): 448-461.
[11] Internet health report[EB/OL]. http://www.internetpulse.net/, 2015.
[12] Bertran R, Gonzàlez M, Martorell X, et al. Counter- based power modeling methods: top-down vs bottom-up[J]. The Computer Journal, 2013, 56(2): 198-213.
[13] Padhye J, Firoiu V, Towsley D, et al. Modeling TCP Reno performance: a simple model and its empirical validation[J]. IEEE/ ACM Transactions on Networking, 2000, 8(2): 133-145.
Throughput model of TCP SACK under burst losses
WANG Zhi-ming, ZENG Xiao-ping, LI Juan, LIU Xue, CHEN Li
(College of Communication Engineering, Chongqing University, Chongqing 400044, China)
Describing the end-to-end burst loss characteristics by Gilbert loss model, the model of RFC6675-based fast retransmission was proposed and recovery and a throughput model of TCP SACK based on the fast retransmission and recovery model was derced. The numerical and network simulations show that the fast retransmission and recovery model can accurately describe the fast retransmission and recovery process, the estimation accuracy of throughput model was promoted.
TCP SACK, fast retransmission and recovery, throughput model, bandwidth-delay product
TP393
A
10.11959/j.issn.1000-436x.2016062
2015-02-05;
2015-06-14
国家自然科学基金资助项目(No.61171089, No.61302054);国家自然科学重大研究计划培育基金资助项目(No.91438104)
The National Natural Science Foundation of China (No.61171089, No.61302054), The Training Program of the Major Research Plan of the National Natural Science Foundation of China (No.91438104)
王志明(1986-),男,陕西永寿人,重庆大学博士生,主要研究方向为TCP拥塞控制与建模分析、航空自组网组网及优化。
曾孝平(1956-),男,四川广安人,重庆大学教授、博士生导师,主要研究方向为航空移动通信、计算机网络、信号与信息处理。
李娟(1989-),女,云南大理人,重庆大学硕士生,主要研究方向为航空自组网MAC协议及资源调度算法。
刘学(1983-),男,重庆人,重庆大学博士生、讲师,主要研究方向为航空自组网连通性研究、计算机网络。
陈礼(1982-),男,重庆人,重庆大学博士生、讲师,主要研究方向为民用航空移动通信网络。
猜你喜欢
现代电子技术(2022年9期)2022-05-12
云南民族大学学报(自然科学版)(2021年4期)2021-09-11
浙江工业大学学报(2019年2期)2019-03-19
计算机与数字工程(2018年9期)2018-09-28
集装箱化(2017年4期)2017-05-17
科技与创新(2016年24期)2017-03-30
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
现代管理科学(2017年1期)2016-12-26
第二课堂(课外活动版)(2015年5期)2015-10-21
