
智慧港口内涵及其关键技术
2016-07-15 03:53交通运输部水运科学研究院刘兴鹏张澍宁
世界海运 2016年1期
交通运输部水运科学研究院 刘兴鹏 张澍宁
智慧港口内涵及其关键技术
交通运输部水运科学研究院 刘兴鹏 张澍宁
摘要:智慧港口作为现代港口发展的前沿形态,是全面提升我国港口竞争力、实现我国港口转型升级的重要途径。大数据技术作为新一代信息技术的代表,为智慧港口的建设提供了重要的技术支撑,是智慧港口具备“智慧”能力的关键技术。从智慧港口的概念、目标和架构三个方面对智慧港口内涵进行详细阐述,并结合大数据处理流程,对大数据处理的核心技术GFS、MapReduce、BigTable以及开源数据处理平台Hadoop进行研究。
关键词:智慧港口;关键技术;智慧港口架构;大数据技术
随着全球经济的迅猛发展和国内外环境的急剧变化,我国港口面临全新的机遇和挑战,打造全面感知、广泛互联和智能应用的智慧港口,成为我国港口转型升级的重要途径。
在国家战略层面,2014年我国提出建设“丝绸之路经济带”和“21世纪海上丝绸之路”两大国家战略,港口作为我国连接国内外货运商贸、物流仓储以及信息服务等环节的重要载体,是“一带一路”战略的关键节点,这为我国智慧港口提供了历史性的发展机遇;在行业政策层面,2014年全国交通运输工作会议上指出,当前和今后一个时期要全面深化改革,集中力量加快推进综合交通、智慧交通、绿色交通、平安交通等“四个交通”的发展。港口作为重要的交通枢纽,大力发展智慧港口,成为“四个交通”建设的重要内容;在市场环境层面,随着全球航运市场进入“船舶大型化”“联盟超级化”“港口网络轴辐化”以及“码头高等级化”的新常态,[1]我国港口要想在激烈的市场竞争中赢得生存空间,推进智慧港口建设势在必行。
一、智慧港口内涵
(一)智慧港口概念
智慧港口是指充分借助物联网、云计算、大数据、智能感知等新一代信息技术对港口进行透彻感知、广泛互联以及信息深度挖掘,实现港口各类资源要素的无缝连接和各功能模块的协同联动,并最终实现港口智能、高效、安全、便捷、绿色发展的现代化港口形态。
(二)智慧港口目标
1.对远端资源的有效掌控
建立强大的感知体系和监控体系,对航道、锚地等远端信息资源实现有效掌控,加强港口管理部门对港口信息的全面感知能力和迅速反应能力,为客户提供更好服务的同时降低管理成本。
2.信息资源的高度共享
通过港口信息资源整合,有效集成政府部门、口岸单位、港航企业的信息资源,搭建集港口管理、航海保障、安全通信、实时监控四位一体,资源高度共享、运行机制完善、维护保障有力的服务平台,实现港口服务智能化。
3.提高港口管理决策水平
建立感知灵敏、信息流畅、智能决策的服务网络,将与港口经营生产相关的一切活动都集中在该服务网络中,实现对港口人员、设备和基础设施的实时管理,并通过港口数据挖掘和智能应用,达到港口运营的“智慧”状态。[2]
(三)智慧港口架构
智慧港口的架构包括信息感知层、网络传输层、数据层以及智能应用层四个部分,如图1所示。
1.信息感知层
通过RFID、AIS终端、视频监控、电子标签以及水文气象终端等各种感知设备对港口全方位信息进行采集。
2.网络传输层
通过互联网、移动通信网、AIS基站、海事雷达站以及VHF通信网等各种网络将感知终端采集到的数据传输到相应的服务器。
3.数据层
建立云数据中心,将感知端采集到的各种类型的数据进行处理整合,为大数据挖掘和智能应用提供数据资源。
4.智能应用层
依托云数据中心庞大的数据资源,使用大数据技术对海量数据进行挖掘,根据港口业务需求开发相应的智能应用系统,为港口管理提供决策支撑。[3]
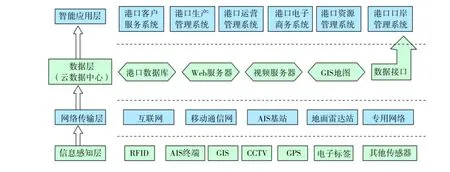
图1 智慧港口架构
二、智慧港口关键技术
(一)智慧港口与大数据技术的关系
随着物联网、云计算、智能感知等新一代信息技术在港口领域的不断应用,我国港口已经进入了大数据时代。利用大数据技术,对海量数据进行挖掘,发现大数据中隐含的知识和规律,实现我国港口管理方式由基于经验的“直觉型管理”向基于数据的“事实型管理”转变,[4]为我国港口管理工作提供决策支持,并最终提高我国港口管理水平和决策水平,具有重要的战略意义。[5]
由智慧港口的结构可以看出,大数据技术作为智慧港口的核心技术,为智慧港口的建设提供了重要的技术支撑,是智慧港口实现智慧决策的根本所在。[6]随着我国港口信息化建设的不断推进,港口管理部门以及相关单位的港口管理信息系统积累了大量的行业数据,数据类型从传统的结构型数据拓展到了电子邮件、文本文件等半结构型数据,以及由视频监控、传感器等产生的非结构型数据。[7]这些宝贵的数据资源为我国智慧港口建设打下了良好数据基础的同时,也为智慧港口的大数据处理能力提出了更高的要求。
因此,通过对智慧港口大数据技术的研究,不断提升我国智慧港口的大数据处理水平以及行业的智能应用水平,对于我国智慧港口的建设至关重要。
(二)大数据技术
1.大数据处理流程
大数据的处理流程分为数据采集、数据处理、数据分析和数据解释四个阶段,[8]如图2所示。
第一阶段,数据采集。
通过RFID、电子标签、传感器等各种感知终端对数据(包括结构数据、半结构数据以及非结构数据)进行采集。
第二阶段,数据处理。
为保证数据的质量以及可靠性,需要对所采集的数据进行“去噪”和“清洗”。通常使用数据过滤器,用聚类和关联分析方法将无用或错误的离群数据进行过滤,并针对数据种类建立专门数据库,以有效减少数据查询和访问时间,提高数据提取速度。
第三阶段,数据分析。
数据分析是大数据处理流程中最核心的部分,通常使用分布式文件系统GFS、分布式数据库BigTable、批处理技术MapReduce以及开源平台Hadoop技术[9]对数据进行分析,以挖掘数据中隐藏的价值。
第四阶段,数据解释。
数据解释是使用基于集合的可视化技术、基于图标的技术、基于图像的技术、面向像素的技术和分布式技术等大数据可视化技术,对数据分析结果进行展示,将抽象数据表现为可视图像,以方便用户对结果的接受和理解。[10]
2.大数据分析技术
大数据技术中,最核心的部分是对于数据的分析处理,而云计算是大数据分析处理技术的核心原理,最典型的就是以分布式文件系统GFS、批处理技术MapReduce、分布式数据库BigTable为代表的大数据处理技术以及在此基础上产生的开源数据处理平台Hadoop。
(1)批处理技术MapReduce。
MapReduce技术是由Google公司于2004年提出的一种典型的数据处理技术,由于其并行式处理数据的方式而成为大数据处理的关键技术。[11]MapReduce采用“分而治之”的思想,把对大规模数据集的操作分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。MapReduce把处理过程高度抽象为两个函数map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来,MapReduce数据分析流程如图3所示。
首先,将数据源分为若干部分,每个部分对应一个初始的Key/Value对,并分别给不同的Map任务区处理,这时的Map对初始的Key/Value对进行处理,产生一系列的中间结果Key/Value对;其次,MapReduce的中间过程Shuffle将所有具有相同Key值的Value值组成一个集合传递给Reduce环节;最后,Reduce接收这些中间结果,并将相同的Value值合并,形成最终较小的Value值合集。MapReduce系统的提出简化了数据的计算过程,避免了数据传输过程中大量的通信开销。[12]
(2)分布式文件系统GFS。
分布式文件系统GFS(Google File System)是Google公司为了存储海量搜索数据而设计的专用文件系统,GFS作为上层应用的支撑,为MapReduce计算框架提供了底层数据存储和数据可靠性的保障,GFS架构如图4所示。
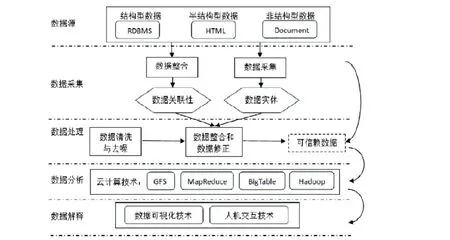
图2 大数据处理流程
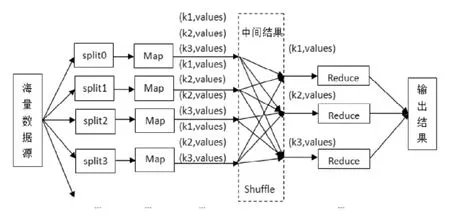
图3 MapReduce数据分析流程
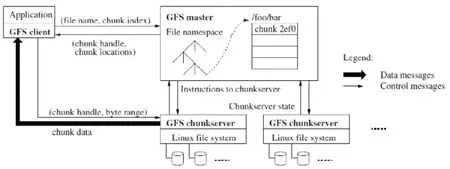
图4 GFS架构图
GFS采用主从结构,包括一个主服务器(GFS master)和多个数据服务器(chunk server),GFS的工作就是协调成百上千的服务器为各种应用提供服务。主服务器负责维护文件系统的元数据,包括命名空间、访问控制、文件—块映射、块地址等,以及控制系统级活动,如垃圾回收、负载均衡等。数据服务器负责提供存储,GFS将文件划分为定长数据块,每个数据块都有一个不变的ID(chunk handle),数据块以普通Linux文件的形式存储在数据服务器上。应用需要链接客户端(client)的代码,然后客户端作为代理与主服务器和数据服务器交互。主服务器会定期与数据服务器交流,以获取数据服务器的状态并发送指令。
(3)分布式数据库BigTable。
随着数据量的增大,数据类型的增多,传统数据库纵向扩展的方法不能高效处理这些类型复杂、价值密度低的海量数据,而Google的分布式数据库BigTable为用户提供了简单的数据模型,BigTable基本架构如图5所示。
BigTable是非关系型数据库系统,主要运用一个多维数据表的行、列关键字和时间戳来查询定位,用户可以动态控制数据的分布和格式。BigTable数据库的架构由主服务器和子表服务器构成。数据均以子表形式保存于子表服务器中,主服务器负责创建子表、将子表分配到子表服务器、检测新增和过期的子表服务器、平衡子表服务器之间的负载、GFS垃圾文件的回收、数据模式的改变等。子表服务器负责数据的读写,并在子表规模过大时进行拆分。BigTable客户端直接和子表服务器通信,它使用分布式的锁服务Chubby来对子表服务器进行状态监控,主服务器可以查看Chubby服务器以观测子表状态是否存在异常,若有异常则会终止故障的子服务器并将其任务转移至其余服务器。BigTable使用GFS来存储数据文件和日志,数据文件采用SSTable格式,它提供了Key/Value的映射关系,并最终将数据以GFS形式存储于GFS文件系统中。
(4)开源实现平台Hadoop。
Hadoop是一个包括分布式文件系统(Hadoop Distributed File System,HDFS)、分布式数据库(HBase)以及数据分析处理MapReduce等功能模块在内的大数据处理平台,[13]英特尔的Hadoop的系统构造如图6所示。
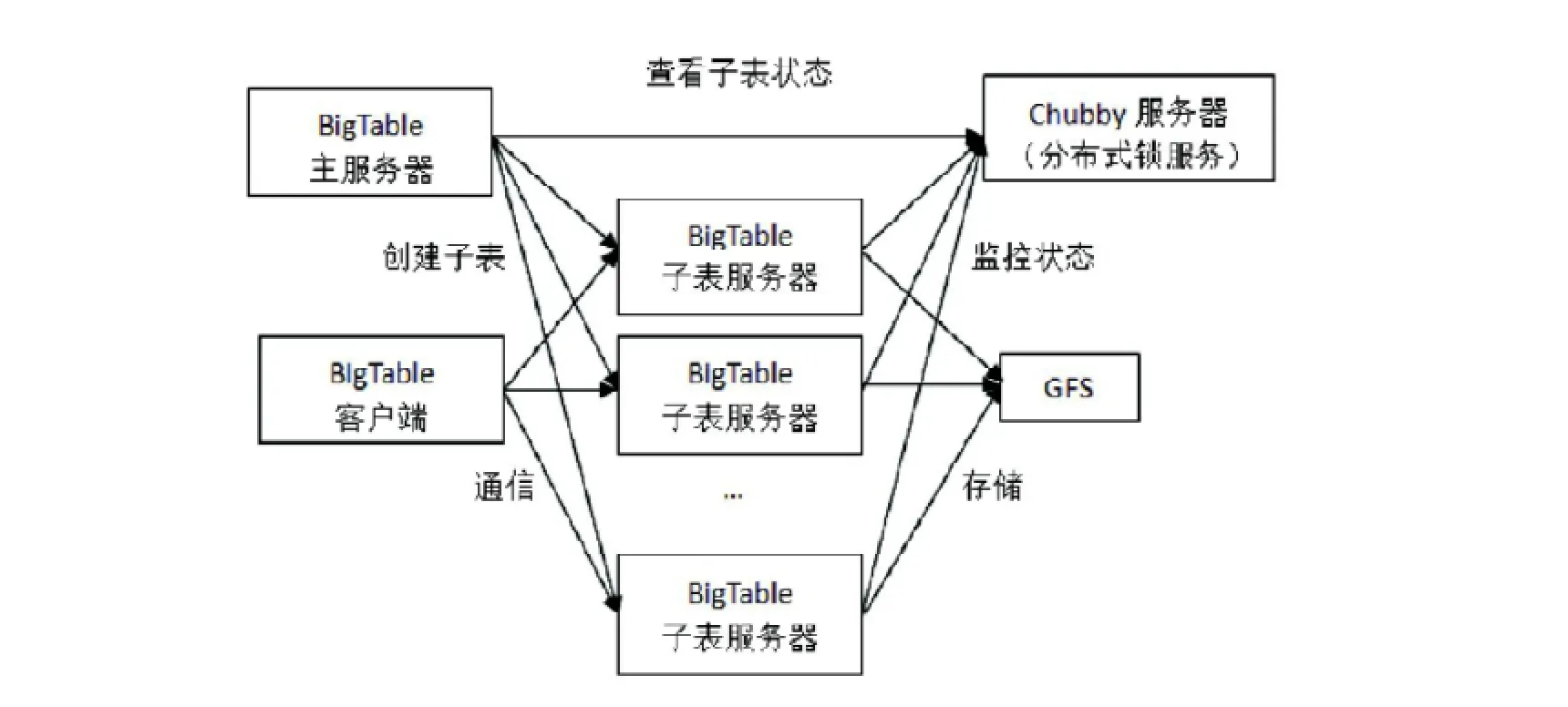
图5 BigTable基本架构

图6 英特尔Hadoop组建结构
其中:以MapReduce算法为计算框架,利用HDFS为大规模服务器集群提供高速的文件读写访问;Hbase是一个分布式、面向列的并行数据库系统,可以兼容各种结构化和非结构化的数据,提供海量数据的存储和读写;Mahout提供数据挖掘、机器学习等经典算法的实现;Hive是基于Hadoop的大数据分布式数据仓储引擎,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能;Pig Latin是数据分析处理语言,它借鉴了SQL 和MapReduce两者的优点,既可以像SQL语言那样灵活可变,又有过程式语言数据流的特点;Zookeeper是分布式系统的可靠协调系统,提供包括配置维护、名字服务、分布式同步、组服务等在内的相关功能,将简单易用的接口和高效稳定的系统提供给用户;Sqoop是将Hadoop和关系型数据库中的数据进行双向转移的工具,可以将一个关系型数据库中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到关系型数据库中,还可以在传输过程中实现数据转换等功能;Flume是分布式日志采集系统,它的作用是从不同的数据源系统中采集、集成、运送大量的日志数据到一个集中式数据存储器中。
三、结语
智慧港口是智慧技术在港口领域的深度应用,是港口发展的高级阶段。对于我国港口而言,通过打造智慧港口,优化提升港口的基础设施和管理模式,实现港口功能创新、技术创新和服务创新,已经成为我国港口提高国际竞争力,完成转型升级的重要途径。通过对智慧港口内涵以及大数据技术的研究,使我国港口信息化积累的海量数据充分发挥其巨大的数据优势,为我国港口管理部门以及港口企业提供决策支撑具有重要的现实意义。
参考文献:
[1]徐剑华.班轮业的“大时代”[J].中国船检,2015(1):22-26.
[2]刘兴鹏.基于SWOT分析的天津港“智慧港口”建设发展战略研究[J].中国海事,2015(7):31-33.
[3]包雄关.智慧港口的内涵及系统结构[J].中国航海,2013(6): 120-123.
[4]陈龙,程开明.大数据时代的决策:数据分析抑或直觉经验[J].中国统计,2014(9):20-22.
[5]徐宗本,冯芷艳,郭讯华,等.大数据驱动的管理与决策前沿课题[J].管理世界,2014(11):158-163.
[6]王习祥,胡海.基于云数据中心的智慧城乡规划决策支持系统研究[J].地理信息世界,2015(8):39-45.
[7]何军.大数据对企业管理决策影响分析[J].科技进步与对策,2014(2):65-68.
[8]刘智慧,张泉灵.大数据技术研究综述[J].浙江大学学报:工学版,2014(6):957-972.
[9]杨宸铸.基于Hadoop的数据挖掘研究[D].重庆:重庆大学,2010.
[10]刘勘,周晓峥,周洞汝.数据可视化的研究与发展[J].计算机工程,2002(8):1-2,63.
[11]李成华,张新访,金海,等.MapReduce:新型的分布式并行计算编程模型[J].计算机工程与科学,2011(3):129-135.
[12]覃雄派,王会举,杜小勇,等.大数据分析——RDBMS与MapReduce的竞争与共生[J].软件学报,2012(1):32-45.
[13]陈吉荣,乐嘉锦.基于Hadoop生态系统的大数据解决方案综述[J].计算机工程与科学,2013(10):25-35.

DOI:10.16176/j.cnki.21-1284.2016.01.001
猜你喜欢
今日农业(2021年8期)2021-11-28
今日农业(2021年13期)2021-11-26
现代畜牧科技(2021年3期)2021-07-21
落叶果树(2021年6期)2021-02-12
铁道通信信号(2018年7期)2018-08-29
现代园艺(2017年23期)2018-01-18
合作经济与科技(2016年24期)2016-12-07
新媒体研究(2016年20期)2016-12-02
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
