
GBase8aMPP:一种新型关系数据库的设计和实践
2016-07-02 07:29天津南大通用数据技术股份有限公司解决方案技术总监
信息通信技术与政策 2016年4期
李 瀚 天津南大通用数据技术股份有限公司解决方案技术总监
GBase8aMPP:一种新型关系数据库的设计和实践
李瀚天津南大通用数据技术股份有限公司解决方案技术总监
摘要:随着行业大数据应用的迅速发展,对基于海量数据的行业大数据的存储、处理和管理提出了更高要求,传统的小机+存储阵列的架构已经无法满足海量数据增长和系统扩展性的要求。本文总结了一种基于MPP架构+列式存储设计的新型关系数据库技术的产品——GBase8aMPP的技术设计思路,这些技术有效解决了传统架构下的扩展性问题和大规模并行计算问题,并且通过内部高可用机制实现在低价计算平台上的大数据平台可靠性。
关键词:大数据;MPP(大规模并行计算)关系数据库;列式存储;关系运算
1 引言
关系数据库是20世纪70年代基于关系代数理论发展的数据管理技术,它将数据以表为单位组织,每个表的数据表现为一个实体,并通过基于范式的数据组织和关联运算使用SQL言语实现对数据的动态关系生成,这种数据管理概念最大程度反映了应用的实际需求,简化了信息系统开发时从模型设计到计算程序开发的流程,所以在信息处理领域具有重大的意义。在过去40年的关系数据库发展中,数据库一直基于集中存储和集中计算的计算模式来实现其架构,因为这种模式十分适合关系计算的特征。早期的关系数据库应用主要适用于金融等典型的交易型领域,后随着关系数据库应用的发展,应运产生了数据仓库应用和BI等相关领域,关系数据库的应用到达了一个顶峰。随之,数据量逐渐增大,企业在数据库相关的基础设施的投入上,负担也越来越大,“小机+存储阵列”模式的系统架构曾经一度成为大企业构建数据库的标准平台,对于这样的平台,企业动辄用数千万元投资去维持系统对海量数据的支撑和管理。随着大数据时代的到来,传统架构和传统数据库所面临的问题愈加显著,系统面临着数据库系统可扩展性难题,企业开始对传统数据库能否管理好如此大规模的数据量,能否可以处理海量数据等发生了怀疑。
传统数据库所面临的问题列举如下:
(1)数据计算模式依存于集中存储,而集中存储的限制引起“小机+存储阵列”模式无法承载更加大量数据的存储和处理,并且造成I/O成为瓶颈。此模式下扩展性差,通过传统Scale UP模式的系统能力几乎到达极限。
(2)关系数据库为了按照元组单位管理数据,建立了基于AVL树的索引机制,这种平衡树结构虽然引擎能够保证按照最小路径寻找数据,但当数据量增长后,索引结构的维护代价将随着数据量的增加越来越大,导致大数据应用下的数据批量写入自身就成为难以解决的问题。
(3)随着数据量增加,更多的数据无法保证维持在内存中,I/O的瓶颈效应将进一步显著化。
(4)为了保证数据库数据的持久性和一致性,传统数据库管理系统提供基于日志的恢复机制,关系数据库事务中对数据的更新需要首先记录到日志中,而日志需要按照预先定义的策略(如WAL)更新到磁盘上,这个无疑会降低数据处理的性能。
(5)单一SMP服务器下的处理能力已经到达极限,对于海量数据条件下的关系运算的关联运算和聚集运算所需要的计算能力难以满足。
基于以上问题,从结构上调整传统关系型数据库的体系架构就成为必然。其中,NoSQL和NewSQL技术就是解决上述传统关系数据库问题时发展而来的新型技术,它们均采用了以ScaleOut为代表的横向扩展性技术,并且在存储结构上引入了列式存储和I/O读取时的智能过滤技术;在事务控制技术上,NoSQL和NewSQL技术都采用了一系列的弱化或者简化措施,使得海量数据的处理一致性保障机制获得一定简化。
而NewSQL比较NoSQL,它保持了关系数据库处理复杂关系运算的特性,使关系数据库中的多表关联和其他复杂的SQL运算等的高级功能在分布式结构上仍能得到实现,对于需要与结构化数据和关系计算相关的“高级功能”时,NewSQL就成为最佳的选择。而除去互联网等行业,对于广大行业大数据应用而言,结构化数据的相关处理占据了70%以上的行业大数据市场,这也是以MPP数据库为代表的NewSQL得以存在和发展的实质原因。
2 传统关系数据库的改造设计原则
针对以上传统数据库所面临的在存储、处理结构和事务处理机制上对于大数据应用场景的瓶颈,在新型关系数据库设计之初,考虑了以下几方面的技术设计思路,这些设计思路符合当前对关系型大数据平台的架构设计的基本趋势。
(1)为了实现存储和处理能力的扩展性,采取MPP分布式架构,通过ScaleOut方式实现横向扩展。
(2)通过分布式架构下的SharedNothing架构实现并行I/O,从物理上解决集中存储所面临的I/O瓶颈问题。同时,为了保证数据的快速读取,应尽可能保证数据存储规则和处理查询规则的一致性,为了解决这个问题,采用Hash规则实现对各元组入库时的规则摆放,从而实现SharedNothing架构下的数据快速定位。
(3)通过列式存储和数据压缩技术实现数据I/O量吞吐的减少,节约了缓存的消耗。
(4)随着数据量增加,为了保持数据存取性能的线性,建立更加简单的索引结构,通过对某一大小的数据单元生成摘要的方式,实现对数据条件的过滤,即从为数据精准定位的索引机制过渡到数据过滤机制,从基于元组的细粒度的索引过渡成为基于数据块的粗粒度索引机制。
(5)充分考虑关系计算的各个特征,例如Select (Where)、Join、Group By、Order By、Distinct、窗口函数、Insert Into等,最大限度实现在分布式架构下对这些操作符的并行处理能力,并同时减少节点之间的网络流量。
(6)对于大数据平台,更新操作,系统内部实际通过Appendonly+有效标记位的位置实现,同时通过有效标记控制数据提交和读取结果(系统内部可以通过保存多个版本的有效标记位数组来实现事务隔离),这样可以简化大数据处理下的事务控制。而数据的恢复,因为系统为了保证更新写的性能,所以无法按照传统数据库的WAL机制实现细粒度日志,而是通过副本作为数据标准,实现故障恢复。这些机制既能保证大数据量下的数据写的正确性,也能实现处理效率的提升。
3 传统关系数据库的分布式化设计中的课题
对于任何技术革新,在引入新技术设计概念的同时,都是有代价的——必然同时引入另一些的问题,对于MPP分布式关系型数据,则可以列举以下问题:
(1)当一个关系数据库集群规模扩大时,对于一个大规模集群控制所需的集群协议,协议执行的通信代价将以节点数的平方规模扩大,通信模式的复杂性将导致集群崩溃的可能性增大。
(2)对于关系计算,即使通过MPP+SharedNothing结构实现了数据的物理分离和在分布式存储上的规则摆放,但很大程度上还是需要将数据层面当作一个整体看待,尤其对于多表Join处理,这就需要一个在分布式上透明实现相关能力的全局机制。
(3)数据划分是按照Hash Sharding的分片方式实现,所以数据分布与节点个数存在紧耦合性,数据节点一旦出现变化,需要有Hash重新计算的过程,所以扩容实施代价高。
(4)同样基于以上类似的原因,当一个Hash Sharding下的数据分片是一个按照某种规则连续摆放在一起的数据文件时,它的副本也必然是一个较大片连续的数据单元,这种单元比起单纯物理上的文件块要大很多,所以这就决定了副本分布的集中性,由此导致1台服务器宕机后,存有和它同样分片数据的服务器上要增加处理包括副分片在内的活动数据,从而使副分片上数据处理能力迅速降低从而导致“木桶效应”,进而引起集群整体的性能下降。这一点对于会频繁发生故障的PCServer服务器所组成的大规模MPP集群尤其重要,因为PCServer服务器的故障率比小机类型要高出近10倍以上,并且随着集群规模的增加,在整个集群中1台PCServer发生故障的概率会明显增加,而MPP集群的高可用结构造成1台PCServer宕机就会引起全MPP集群能力的下降。
(5)数据在按照列式组织存储时,导致实现表一级的锁操作,从而导致锁粒度的升高,造成并发能力的下降等。
4 GBase8 a MPP作为一种新型关系数据库的技术设计思路
GBase8aMPP作为一种典型的NewSQL型的新型关系数据库产品,是天津南大通用数据技术股份有限公司(简称“南大通用”)完全自主开发的一套国产化支撑结构化大数据处理的MPP型关系数据库,它于2007年开始了产品开发立项;2010年正式发布第一代单机型列式存储数据库;2011年发布了MPP集群版数据库;2012年参加了中国移动集团VGOP投标的大规模集群测试;于2013年之后,开始了GBase8a MPP在电信、金融等核心行业领域的国产MPP数据库的实际应用;截至2016年1月,已经在全国70家行业中有过实际应用,共安装部署节点超过1000台,实际承载数据量达到5PB级别,对于50节点以上节点数的超大规模MPP集群,GBase8aMPP几乎覆盖了超大规模MPP集群部署和使用的主要案例。下面就GBase8aMPP集群的主要技术设计思路进行说明和介绍。
4.1GBase8aMPP的整体架构设计和构成元素
GBase8a MPP集群由GCluster、GNode和GCware 的3个处理要素构成,这3个要素构成了MPP集群的任务调度、实际数据的存储和任务执行以及集群控制的3项基本要素,作为一个比喻,它们分别相当于MPP集群的“头”、“脚”和“神经”,具体参见图1。下面是3个构成要素的具体功能:
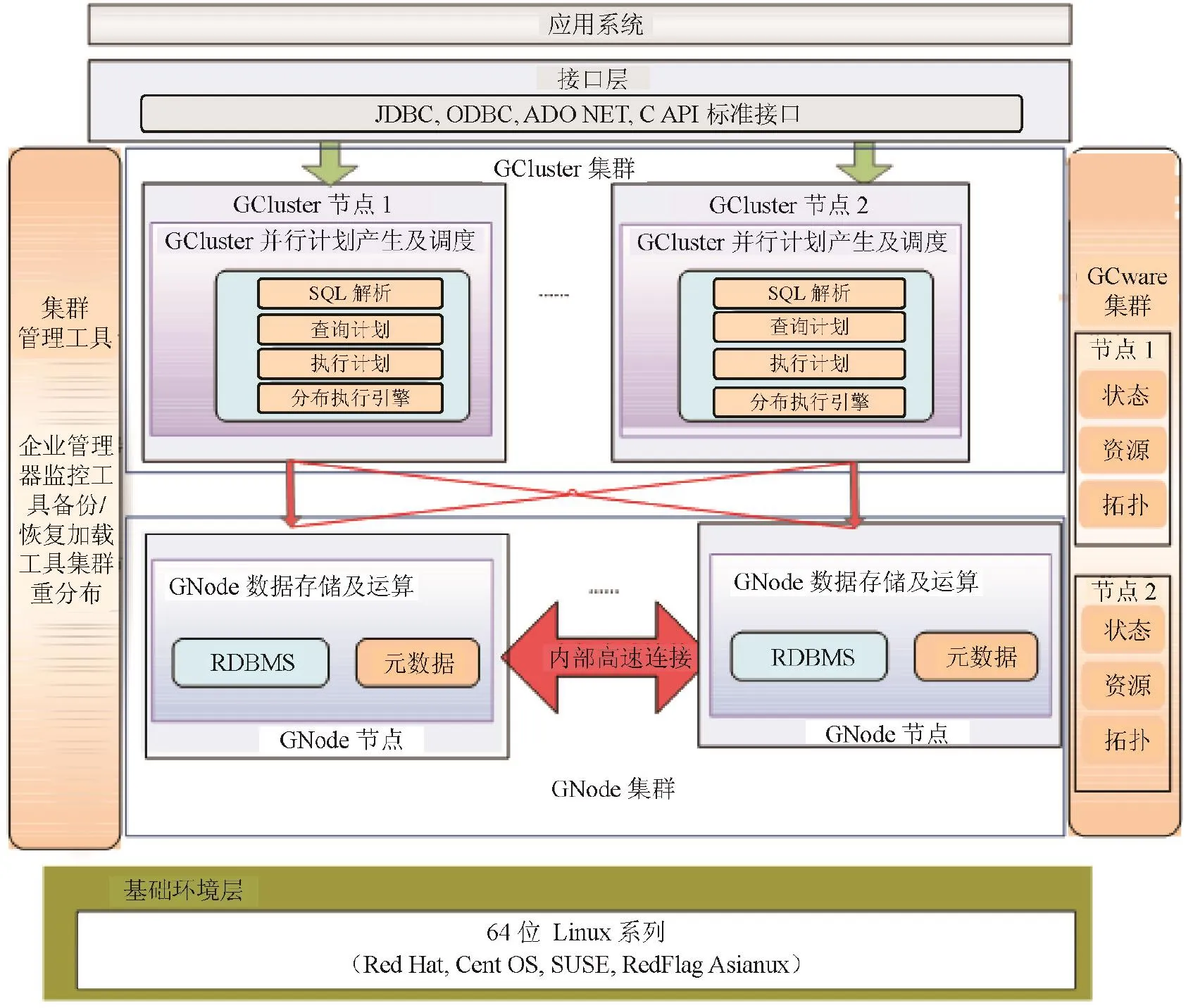
图1 GBase 8a MPP功能架构图
(1)GCluster集群
从GCware获得节点的拓扑和节点数据分片的状态,使用GCware提供的信息(包括集群结构、节点状态、Eventlog等),并负责SQL解析、SQL优化、分布式执行计划生成、执行调度。
(2)GCware集群
通过集群各节点之间的广播通信协议,维持各节点间共享集群状态信息(包括集群结构、节点状态、节点资源:包含Scn、Tableid、集群锁、Eventlog信息等),以及控制故障时的任务切换和故障恢复时的数据修复,并在多副本操作中控制各节点数据的一致性状态。
(3)GNode集群
集群中最基本的存储和计算单元。GNode负责集群数据在节点上的实际存储,并从GCluster接收和执行GCluster产生的执行计划,执行结果返回给GCluster。数据加载时,GNode直接从集群加载服务接收数据,写入本地存储空间。
4.2GBase8aMPP的海量数据的存储设计
对于承载大规模海量数据的GBase8a MPP平台,首先要解决海量数据在平台上有效的存储和管理,其中对于关系数据库,一个重要的需要解决的问题就是数据定位,以及简化存储路径的问题。
首先,GBase8a MPP在集群层次会依照在建表时指定的Hash规则,对数据进行在节点之间的精确摆放,数据的摆放原则,可以简单理解为通过2层的映射,对数据确定准确的摆放节点。
设一个记录的哈希键值为Hashkey,对应这条记录的Hashvalue = Hash_func(Hashkey),继而对应这条Hash Value的摆放节点为:HashNode = HashMap (Hashvalue)。
对于同一节点内部的数据定位,GBase8a MPP采取了数据列式存储和智能索引技术。列式存储下,各个列上的数据是按照列式文件的格式进行存储的,也就是说数据列一旦确定,数据文件就可以确定,从某种意义上说,这就像行式存储下的分区存储,通过对逻辑上同一张表的数据在物理存储上的分解,可以进一步确定一个数据的存储区域。数据在按照列式存储时,又以65536行作为一个I/O单位(GBase8a将这个单位叫做一个DataCell,即一个数据块)对其进行压缩和智能索引的编制工作。智能索引可以起到很好的数据过滤作用,并且它具有很好的空间和时间效率。这里将1 个DataCell数据块中的数据作为1个集合,而智能索引使用一些标志性的摘要信息来表征一个数据块中所包含数据的特征集合。实际数据读取时,不需要直接扫描数据本身,而只需要查看智能索引中的特征集合,就可以判断要查询的数据是否在这个数据块中存在,而特征集合的数据要大大小于存储数据本身的数据量,并且这个特征集合生成的代价不会因为表内整体数据量的增加而不断增大,即它是线形的,这与基于传统关系库的索引结构有本质不同,传统数据库的索引是与表整体的全局数据相关联的,表的数据量越大,传统关系库的索引生成代价就越大。作为这个智能索引中包含的数据特征,在GBase8a中包含这样几个基本信息,数据的MaxValue,MinValue或者使用Hash函数构成的位数组等,但数据可能会产生误判(即数据实际不在该数据块中,但智能索引中的特征集合又表明数据可能存在于该数据块中),为了减少误判,就需要数据在入库时尽量达到一定的有序性(即使是局部有序性,也可以达到减少误判的效果)。
读取数据时为了减少数据I/O吞吐,GBase8a利用列式存储下数据的相似性,实现了3~30倍的数据高压缩比(具体数据压缩比还依存于数据自身的特征和所选择的数据压缩算法)。
对于不同的数据类型,GBase8a提供不同的压缩算法。
(1)对数值类型的压缩算法
●轻量级压缩。
●PPM压缩(压缩速度快、解压速度慢)。
●RAPIDZ压缩,适用于对性能要求较高的用户场合。
(2)对字符类型的压缩算法
●轻量级压缩。
●PPM压缩(压缩速度快、解压速度慢)。
●RAPIDZ压缩,适用于对性能要求较高的业务场景。
在实际应用中,这些算法可以根据实际需要,去适应性地适配不同种类数据的压缩,例如对大规模海量数据的存储,可以根据历史周期,对近期数据的存储采用较轻量级压缩算法;而对于沉淀较长的历史数据,由于实际参与处理的机会较少,可以使用PPM算法对其压缩,这样会在提供高压缩率的同时,会部分牺牲解压处理时的性能等。
4.3GBase8aMPP集群的可扩展性设计
GBase8aMPP从设计之初,就充分考虑了作为集群数据库的可扩展性。随着行业大数据的飞速发展,单一集群的数据承载量正在从十TB级,到百TB级,再到PB级,所以早期的十数节点集群,和现在的数十节点集群很快就将无法满足作为大数据处理平台的MPP集群的规模需求,对于GBase8aMPP集群能否支撑上百节点乃至数百节点的MPP集群规模就成为设计关键。GBase8aMPP在设计上,从集群协议栈设计,和数据在节点之间的组织和重分部算法的两个层面作了优化设计,使MPP集群解决了大规模节点支持的问题。
在架构设计上,GBase 8a MPP采用了Shared Nothing的联邦分布式架构,由GCluster集群、GCware集群(实际上GCluster和GCware集群往往部署在1个物理集群上)和GNode集群组成。GCluster集群和GCware集群部署在相同的物理节点上,每个物理节点上部署GCluster服务和GCware服务,GCluster服务负责集群任务的调度,GCware服务用于各节点GCluster服务间共享信息。GNode集群的物理节点上部署GNode服务,每个GNode服务就是最基本的存储和计算单元。
在联邦架构的集群内部,无论是处理协调调度的GCluster层,还是实际进行数据存取处理的GNode层,都构成了各自处理层的集群结构,从而解决了集群的单点瓶颈或者单点故障问题。而对于集群内部的数据元数据和集群结构元数据的一致性范围,在联邦架构下,仅仅局限在了上层的主节点集群上(GCluster集群),这样达成元数据一致性所需要的节点之间的广播也将被约束到小范围节点内,从而防止了因节点数增加而导致的节点间广播量的膨胀,对于更大规模的处理工作集群(GNode集群),因为节点之间不需要达成共享元数据一致性,所以这一层集群的节点之间不存在复杂的广播通信机制(节点之间除了副本数据同步,以及在执行Join或者Aggregation运算时的节点之间拉表处理等外,节点之间不存在P2P的通信)。作为GNode集群状态的维护,主要通过上层集群(GCluster)节点与下层集群(GNode)节点之间的Heartbeat简易通信机制来实现(简易的HB机制是有别于集群层面的协议的,HB机制主要用于两点之间的死活确认,而不需要在集群中的多个节点间具备达成状态一致性的通信算法)。这样联邦架构下的可扩展性因素中,就突破了集群协议的规模限制,考虑GCluster节点上最大Socket张开数等物理限制条件和并发处理数等,最大合理的集群数可以达到300节点程度。
集群的可扩展性,还依存于数据在节点之间重分布的复杂度,对于MPP集群,当它在集群计算Join结果还是扩容时算出搬运结果集时,它都需要对各个纪录进行HashValue的重计算,而这种重分布计算会严重影响数据搬运的速度,例如对于实际扩容处理来说,当考虑实际的HashValue重计算等因素,真正的数据在节点之间的搬运速度只有60MBytes/s左右,而理想的I/O的落地速度可以达到200MBytes/s,也就是说为了维持MPP集群内节点之间数据分布的Hash规则性,数据的搬运效率下降了近70%,这个也是MPP比较NoSQL或者Hadoop等非结构化的分布式平台在扩展性上的天然不利因素。为了解决这一问题(其实这一问题和后来的高可用专题也有相关),即将每个MPP物理节点下的分片再进行细分,在数据第一次入库时就将Hashvalue类似的数据列分布在同一列簇文件上,这个列簇文件的粒度越细,在进行数据重分布时,就越能减少Hashvalue重计算的压力,甚至在一些情况下(如扩容时,当扩容后集群规模恰好是扩容前2倍时),可以将这些细粒度的分片列簇文件直接整片地传输到新的节点上,这样扩容时数据搬运速度就会接近理想的磁盘I/O速度,此扩容方式参见图2。
4.4GBase8aMPP内部复杂关系计算的实现设计
GBase8a MPP执行复杂查询以及生成执行计划时,要遵循以下几个基本目标:
(1)最大程度地进行并行化。(2)最大化数据局部性,即计算离数据越近越好。(3)关联(Join)运算的两个表的数据,要符合“关联临近性”原则,实现在同一物理节点上进行。
在这里最终目标是为了尽可能减少MPP节点之间的网络数据传输。
而对于MPP型的关系数据库引擎,在生成执行计划逻辑树时,有一些基本的原则是与传统关系数据库相类似的,例如:
(1)尽可能将一元运算迁移到查询树的底部(树叶部分),使之优先执行一元计算。
(2)利用投影和选择的串接定律,缩减每一关系,以减少中间结果集数据尺寸。
(3)将叶子节点之前的选择运算作用于所涉及的表,以减少后期运算的结果集。
(4)在查询树中,将连接运算下移到并运算(Union All)之前执行。
(5)消去不影响查询运算的垂直片段。
遵循以上规则得到逻辑层的执行计划,从计算逻辑上可以降低每个中间步骤的结果集,从而降低物理上的网络传输量和I/O代价。
而GBase8a MPP在从上述原则得到最佳逻辑树后,需要进一步将逻辑树转换成为物理执行树,这其中关键就是要利用MPP集群的跨节点的并行计算能力,而针对关系数据库的各个操作符的特点(包括Scan、HashJoin、HashAggregation、Union、TopN等),对操作符节点树进行划分,划分为若干计划分片,GBase8aMPP内部的逻辑执行计划与物理执行计划之间关系如图3所示。下面是最典型的关系操作符的并行化策略:
(1)Join操作
采用静态Hash或者动态Hash以及复制广播方式,实现MPP集群下的数据并行关联运算。所谓静态Hash,就是关联表之间的HashKey重合,并且关联键与Hash Key重合,此时MPP数据库的GCluster只要将关联操作直接下发到各个单节点上,从各个单节点返回的结果集的合并结果就是关联运算的结果集;而所谓动态Hash,就是关联表之间的Hash Key不重合时,将对关联键与Hash键不重合的表的数据按照关联键进行重分布,从而使Hash重分布后的两个表的数据成为HashKey重合的状态(就是类似静态Hash的数据分布状态);而作为复制广播方式,也是在HashKey与关联键不重合的方式下的使用的又一种关联执行机制,这种方式下一般关联的两个表中一个表较小,即可以将这个小表通过广播的方式向所有节点进行动态复制,这样就可以保证在全节点上并行执行关联操作。
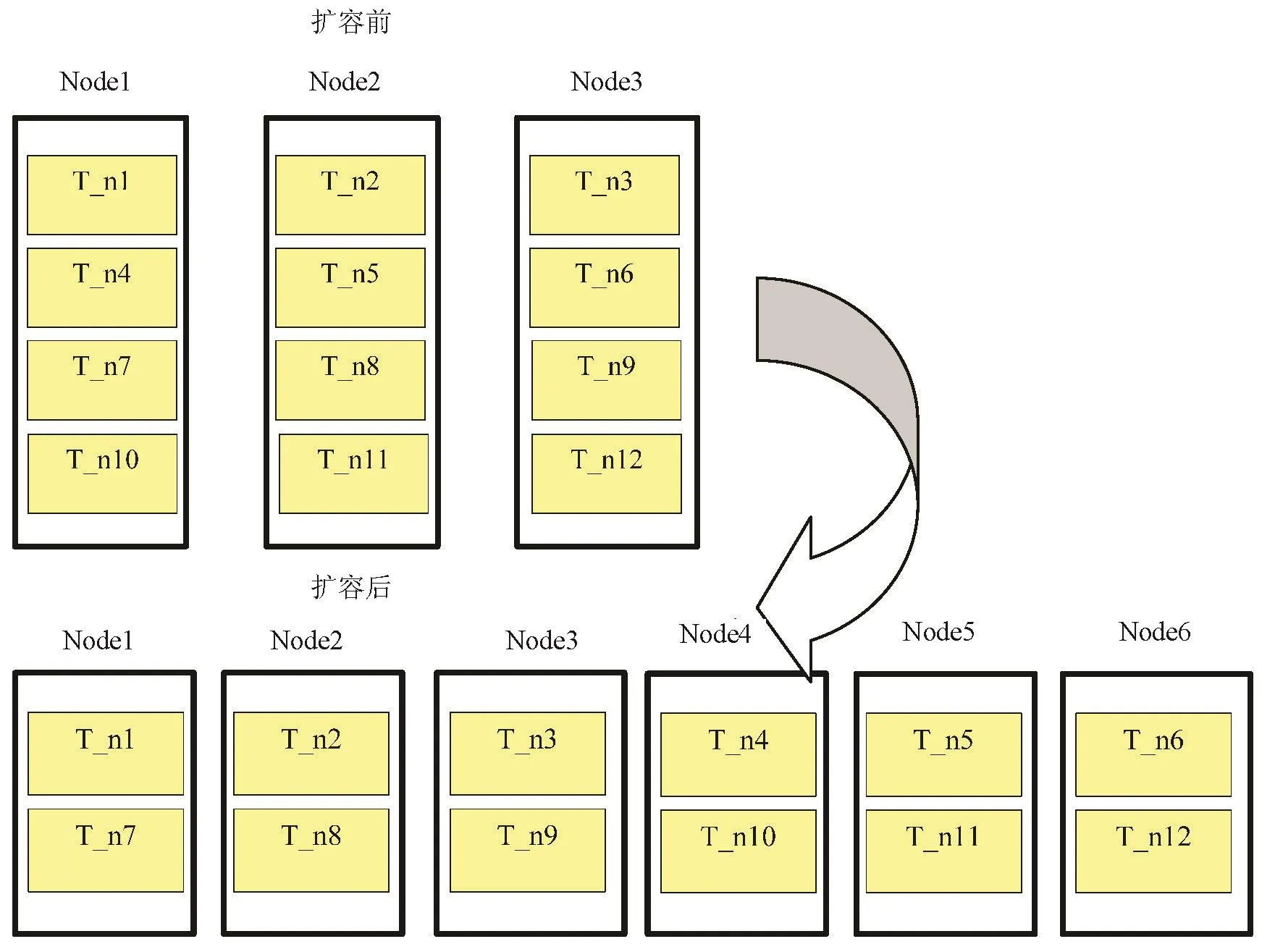
图2 基于分片文件搬运的扩容方式
(2)聚合操作
操作符节点首先在各个单节点上执行局部聚合,之后做全部聚合操作。有时也根据Group by键的Distinct个数,对于这个数字很大的Groupby键,则在聚合运算的第二阶段,按照Groupby键将第一阶段的聚合结果再次进行重分布,在第二阶段以并行计算的方式继续进行全局聚合结果。
(3)Orderby排序操作
操作符节点首先执行本地的Orderby操作,之后对局部排序后的信息进行全局的Order by操作。GBase8aMPP对Orderby可以进行局部排序与全局排序间的流水式并行。
GBase8aMPP作为关系数据库同样采用基于成本(CB-Cost Based)的执行计划优化器方式(CBO),主要基于数据动态的统计特性,实现执行成本的估算。这些统计信息一般包括表数据的行数,生成中间关联结果集的大小评估,各列的宽度,以及列的Distinct值等。GBase8a MPP的引擎会根据这些统计信息,在执行一个复杂SQL时,去估算一个查询任务的代价,并且生成多条执行路径以进行执行成本的比较,从其中选择代价最小的执行路径执行本次查询任务。
4.5GBase8aMPP的可用性设计
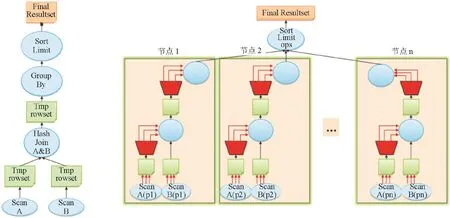
图3 MPP内部高度并行的执行计划
MPP数据库为了实现最大的并行,采用了计算和存储紧密耦合的设计策略,这样可以有效控制每行数据的存储位置和每个数据块的存储格式,在统计分析场景中性能表现优越。
具体说,MPP分片是按照数学规则(如Hash函数)来分布的,所以数据的分片规则不能像Hadoop那样按照数据块(Block)这样的小粒度单位任意实现(这种小粒度分片可以使1台物理机上的数据分片的副本分散到多台物理机上),这样的数据集合单位无法实现更加细粒度的数据分离,而作为高可用的策略的数据副本的分布策略,也是依存上述的数据分片策略下的集合粒度。
如果1台物理服务器上只设置1个分片,就会使单个分片和对应这个分片的副本的粒度过大,从而导致1台服务器宕机后,持有副本的那一节点的负载成为故障切换前正常状态的2倍。而对于MPP这样的集群系统,系统的处理能力将取决于集群中处理最慢的那一节点,这种效应就是木桶效应,因为故障切换,导致Safegroup(是一种GBase8a MPP的高可用的旧机制)的另一节点的处理能力会下降一半,并根据上述的木桶效应,整个集群的处理也将会下降一半。
为了解决上述问题,GBase8a MPP实现了基于虚拟分片的副本分布机制:即1个物理节点可以部署多个逻辑分片,并且每个逻辑分片的副本分片可以部署在不同物理机上,这样一台物理机宕机后,这台物理机上逻辑分片的副本因为分散到多台节点上,所以可以保证宕机服务器的负载不仅可以实现故障转移,而且可以实现故障服务器上负载在故障转移后的负载均衡,具体基于虚拟分片的高可用机制实现如图4所示。
图4 GBase 8a PP的虚拟分片和副本技术
4.6GBase8aMPP下的事务控制设计
作为数据库系统与文件系统的最大区别,就是数据库系统要支持基于DML操作的数据更新,并且作为关系数据库的又一关键特性就是要保证数据的一致性和在任务并发时的读写数据之间的逻辑一致性。传统数据库提出WAL(预写日志记录,Writeahead Log)机制保证了这种数据的逻辑一致性,但它的代价很大,因为这种机制会在执行任意更新时需要将更新永久化到磁盘的日志文件上。GBase8aMPP数据库设计之初就是要考虑数百亿,数千亿行所组成的表的数据管理,所以它无法采用WAL式的做法,并且GBase8aMPP在内部进行任务数据写处理时,包括load加载处理,还是insert,update操作,最终都是通过对各个列式数据文件(多个分片时,就被分割成为列簇文件)的Append处理实现的。与传统数据库不同,不可能对数据更新设置更大的Buffer区域,数据写入磁盘的操作基本是按照之前说的数据块(DataCell)单位进行的(也可以设置DC的Windows Size,这样就可以按照Windows Size个数个DC进行批量写入操作),数据更新基本就是按照写满1个DC之后(或是1个DC窗口),就永久化到磁盘的方式进行更新的。而一个MPP下的事务单位很大,有可能是成千上万个DC,所以MPP为了标记已经一时写入到磁盘上的DC的有效性,就设置了1个Valid_flag数据有效性标志,当途中不断将数据写入到磁盘时,数据的有效标志设置为“0”,这说明这个数据块的数据暂时无效,如果同时发生读操作时,这样的数据是不会被读到的。但当任务完成,数据集体提交时,各个数据上的Valid_flag会批量更新成“1”,从而使数据对其他任务也生效,可以让其他任务开始读取到这里提交的数据。对于Update这样的操作,在将更新后的数据完成Append处理后,它还要进而对更新前数据进行Valid_flag=“0”的重置操作,最终才能进行提交操作(对更新后数据对应的Valid_flag置为“1”)。当然在整个过程中,如有出现系统故障,系统会保持更新操作前的Valid_flag状态,从而保证数据更新到中途的内容不会被其他任务看到。GBase8aMPP内部的有效符机制如图5所示。
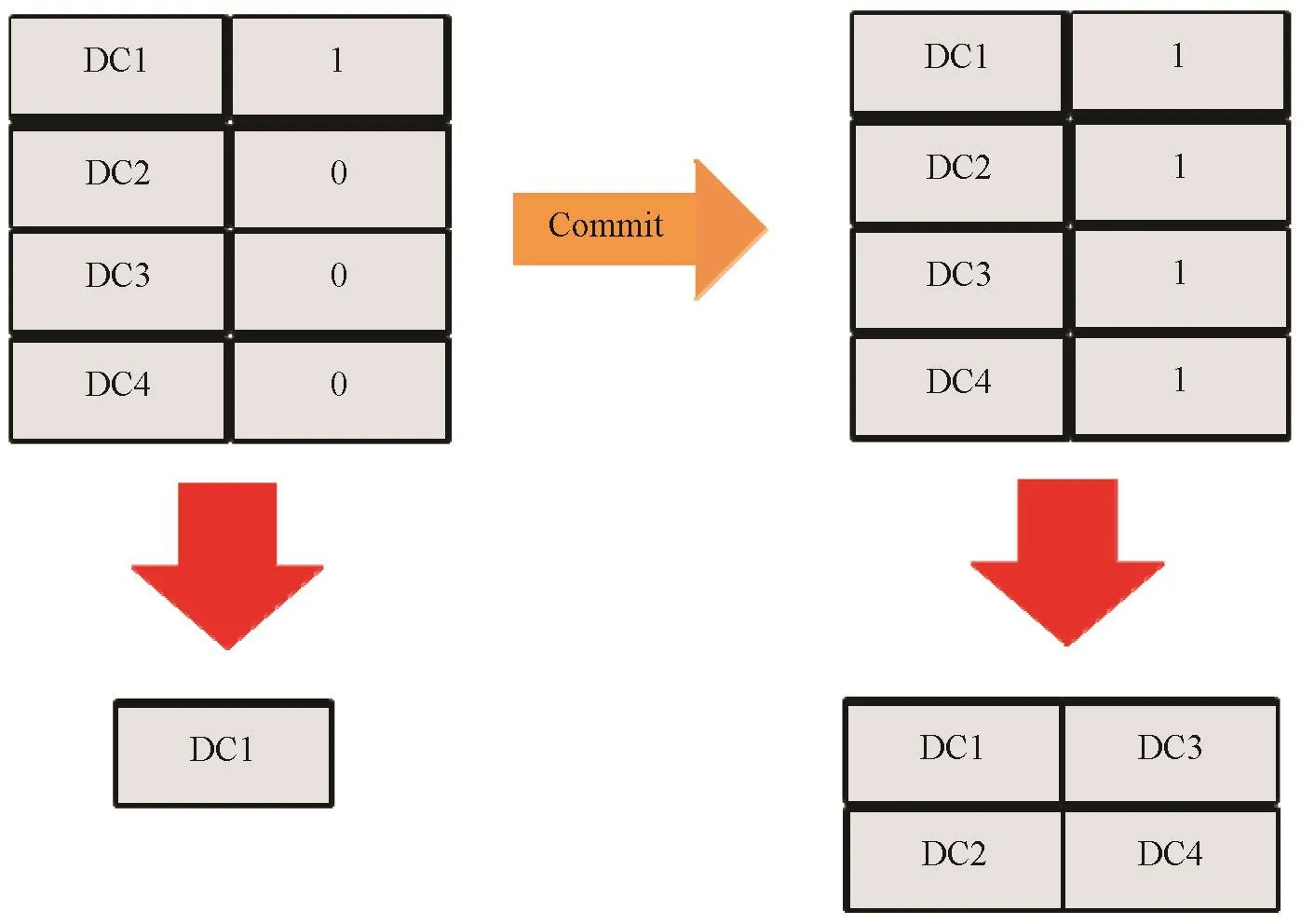
图5 GBase 8a MPP内部的有效标识符
而对于Valid_flag自身的更新操作,考虑其数据量较小,可以使用类似WAL预写日志的方式,保证Valid_flag提交时的事务性。对于事务自身参照自身产生的数据时,则采用对Valid_flag的多版本管理(MVCCforValid_flag)机制实现对自身更新中数据的最新参照。
对于1个MPP集群系统来说,还必须考虑主分片与副分片之间的数据一致性,主副分片的一致性机制一般可以通过经典的预备提交(也称两阶段提交)来实现,GBase8aMPP可以通过两种方式实现:
(1)一种方式是在两个分片上同时处理DML等关系数据库操作,当主分片需要提交时(即按照上述的Valid_flag置位方式实现),会向副分片发出提交请求,如果副分片已经处理完本次任务,它会直接返回主分片一个ACK+消息,如果副分片还没有完成本次任务,它会返回主分片一个ACK-消息,表明还需要等待(GBase8a MPP可以设置等待超时),当主分片接到从副分片发来的ACK+消息时,它会指示副分片一块提交更新完的数据。
(2)作为另一种方式,是先更新主分片上数据,再由主分片将数据转发到副分片上,这个数据转发机制可以保证更新数据按照增分传输的方式,准确传输到副分片上,而当主分片完成数据更新后,它会按照与上面第一种DML提交同样的方式,提交本次更新。GBase 8a MPP内部的副本生成机制如图6所示。
实际MPP集群对副本的一致性进行了一定的缓和,即当主副分片中有任意一个分片无法工作的时刻,集群可以允许主副分片之间的数据非一致性,并允许集群整体的事务可以强制提交,这时集群的GCware会在健康的分片上保留1个Eventlog事件日志,记录故障分片上丢失的那个操作(这个操作可能是一个DML数据更新操作,也可能是一个DDL操作),而此后当故障节点上的那个分片恢复正常的时候,GCware会从Eventlog的事件日志中探测出需要恢复的操作,进而调用相关进程完成故障节点分片向健康分片上数据的数据追平,从而完成故障后数据恢复。
此外,对于GBase8aMPP集群,为了完成并发下的事务正确的执行能力,采用了适合于MPP和列式存储的并发控制策略。作为GBase8aMPP采用的最简单的并发控制方式,是采用表级锁机制,之后采用对DCWindowssize内的连续数据块的DC锁机制从而减少锁粒度,这种机制实际上就是在内存区域上设置了针对各个事务的独立的数据更新区域,既提高了写操作的速度,也同时提高并发的处理能力。随着GBase 8aMPP的分片文件自身的细化,数据分片将变得更小,将数据从内存中的DC写入到分片文件时,由于分片文件存在多个,1个Hash段内的DC数据在向对应分片数据写入数据时,如果遇到文件被锁住的情况,它还可以将另一Hash段内的DC数据写入其他分片文件上,这样就减少了因锁而导致的数据写性能的下降。
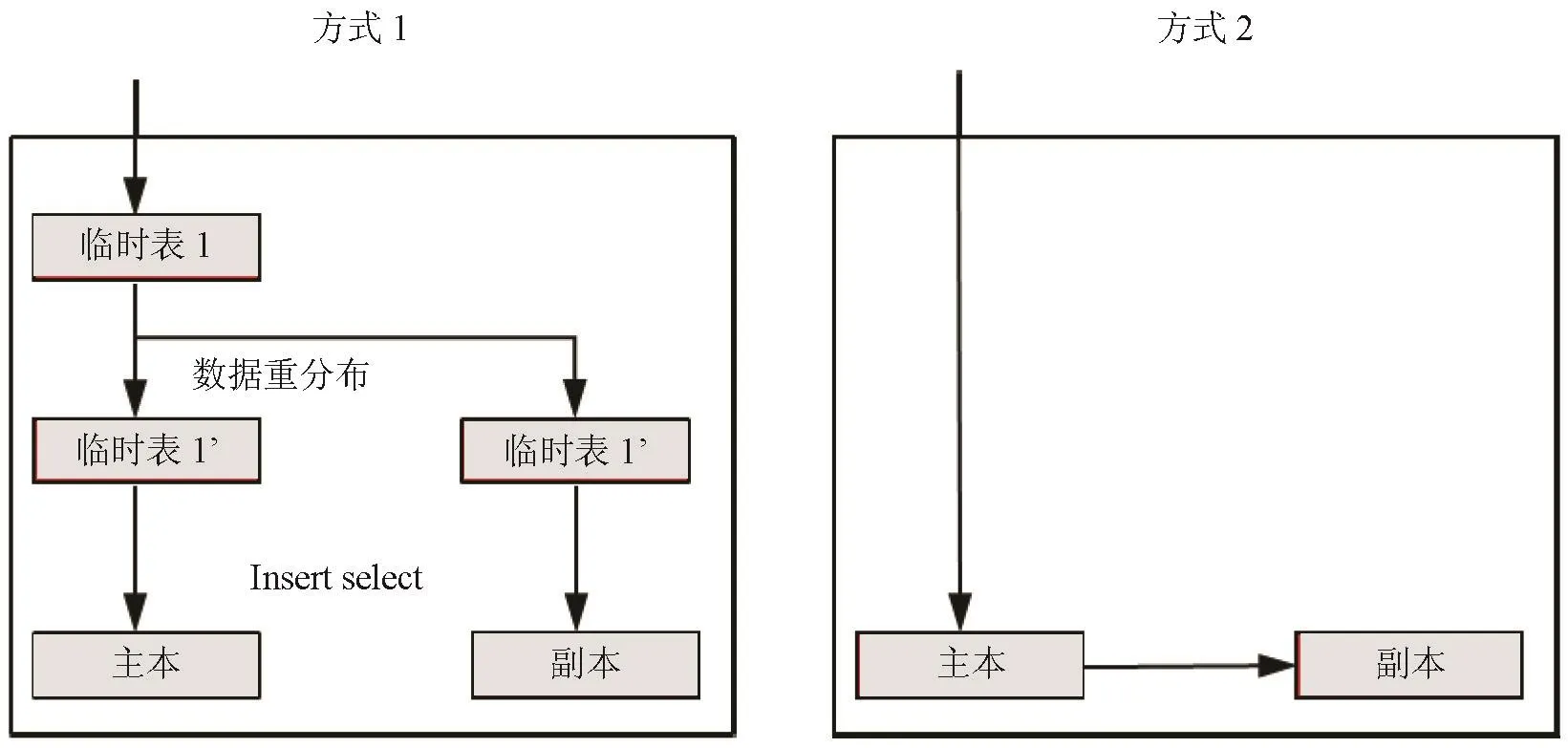
图6 GBase 8a MPP内部的副本生成机制
5 GBase8 aMPP数据库的应用实践
GBase8a MPP作为一种分布式的列式关系数据库,已经应用到了电信和金融等核心行业,从实际项目中我们总结了大量项目经验,这些经验对于充分发挥MPP数据库的能力是十分有益的。
5.1基于MPP+Hadoop的混搭技术
MPP作为一种基于分布式列式关系数据库,能够支撑在海量结构化数据基础之上的关系运算,但作为非结构化数据的处理和关系型运算以外的算法,MPP并不擅长,而作为实际的大数据应用,则发现大数据的4V特性经常会同时成为需求特征,这就需要构建一个综合的大数据平台,而从实际工程中,总结了MPP+ Hadoop的混搭结构能够有效解决此类问题。作为一个最典型的场景,Hadoop作为MPP的前端ETL平台,可以对非结构化数据进行结构化转换和低层汇总,或者是从图像等完全非结构化数据中提取特征量等,之后将提炼的结构化数据结果集载入MPP,利用MPP库内强大的数据表的关联能力,将Hadoop平台的生成数据与载入MPP的从其他业务系统数据源载入的数据进行关联融合,从而得到传统数据仓库下无法实现的深度分析能力。对于一个电信运营商的大数据系统,就经常使用这一模式构建大数据平台,使用Hadoop对信令和位置信息进行结构化转换和低层汇总。另外,从BOSS、CRM等业务系统整合而来的业务结构化数据同Hadoop加工后的数据结果一并放入GBase 8a MPP,在GBase8aMPP库内综合客户资料和用为行为轨迹以及上网行为等的全用户图像信息(这些信息可以适用于精准营销场景中)。
5.2Hashkey的合理选择
合理设置数据表的Hash Key对于提高MPP的计算并行度以及减少节点之间的数据传输至关重要,所以HashKey的选择在GBase8aMPP工程实施过程中,是作为数据模型设计阶段最重要的工作被认知,根据众多工程经验,总结以下因素是在建立HashKey时最重要的考虑因素。
●尽量选择Count(Distinct)值大的列做Hash分布列,让数据均匀分布,避免数据倾斜产生木桶效应。
●优先考虑大表间的Join,尽量让大表Join条件的列为Hash分布列(相关子查询的相关Join也可以参考此原则),以使得大表间的Join可以直接分布式执行。
●其次考虑Groupby,尽量让Groupby带有Hash分布列,让分组聚合一步完成。
●通常是等值查询的列,并且使用的频率很高的应考虑建立为Hash分布列。
5.3列式存储下宽表的使用
列存以列为单位组织底层文件存储,在Select投影列一定的情况下,表宽对查询性能没有影响,并且考虑数据压缩等优势,利用宽表设计可在无任何负面影响的前提下,提升关系计算结果集生成时的效率。工程项目现场总结的经验:对于需要大表关联生成查询结果的一些场景(多个大表关联并有一些过滤条件),在数据膨胀率可接受的情况下可以将大表关联提前进行预处理,并将预处理结果保存为一张宽表,将原来的基于大表多表关联的查询转化为基于预处理结果表的单表查询,可以有效提升这类SQL查询的执行效率,同时提高此类查询的并发能力。
5.4合理利用压缩算法
压缩在节省存储空间的同时,可减少I/O吞吐,从而提升性能。但考虑解压等因素等,压缩在某种场景下,如果使用不合理,可能会导致性能的“不生而降”。
对于GBase8aMPP的实际应用场景,总结了以下经验:
●如果对存储空间要求高,对性能不太要求时,建议使用高压缩比压缩算法。
●如果对存储空间要求不高,对性能要求高时,建议使用一般压缩比压缩算法。
5.5提高数据质量以提高处理效率
GBase8aMPP处理的效率直接依存于入库时的数据质量,数据质量的恶劣可能导致数据Hash分布的无效性或者智能索引的无效性。下面是针对GBase8a MPP在实际项目中运用时,总结的一些和数据质量控制相关的最佳经验。
●数值类型的处理性能比字符串要好,建议选择数值类型。
●对于表间关联常用的字段,各表应该设计成同样的字段类型。
●在表关联运算中,如果对各表的Hash分布列加Rtrim、ltrim函数会改变Hash Join的执行计划,必须去掉。为回避此类情形,必须保证加载入库前的数据文件内的数据质量,以保证字段数据的正确性。
类似经验还很多,出于文章篇幅原因,这里不再一一讲解。但有一点要注意,就是GBase8aMPP虽然作为一种关系数据库,由于其存储架构和处理架构上的不同,所导致数据库设计规范会与传统关系数据库有所差别,从传统数据库迁移到GBase8aMPP时,需要考虑相关的调整因素,以充分发挥迁移到MPP后的应用性能的改善效果。
6 结束语
GBase8aMPP作为一款在国内行业大数据市场最广泛使用的新型关系型数据库(NewSQL),在设计上根本突破了传统型关系数据库的限制,在列式存储架构和MPP+Shared Nothing大规模处理并行架构设计上作了各种富有创造性的功能特性开发,在充分发挥MPP型列式数据库的处理优势同时,回避了由于MPP分布式和列式存储等所导致的新派生问题,并且保证了系统的可靠性。
同时,GBase8a MPP在进入行业市场的近6年时间里,从工程实施到实际运用部署,积累了大量的实践经验,这些都有力消化了新技术在向实际行业应用导入时的各项风险,并且通过迅速的技术迭代,GBase8a MPP正在成为大数据行业最有竞争力的逐步成熟的大数据平台级产品。
参考文献
[1]舍恩伯格.大数据时代[M].杭州:浙江人民出版社,2012.
[2].张俊林.大数据日知录:架构和算法[M].北京:电子工业出版社,2014.
[3]陆嘉恒.大数据挑战与NoSQL数据库技术[M].北京:电子工业出版社,2013.
[4]邵佩英.分布式数据库系统及其应用[M].北京:科学出版社,2005.
[5]George Coulouris,Jean Dollimore,Tim Kindberg,Gordon Blair.分布式系统:概念与设计(原书第5版)[M].北京:机械工业出版社,2013.
[6]BonifatA,ChrysanthisPK,OukselAM.Distributeddatabases and peer to peer database:past and present[J]. SIGMOD record,2008.
[7]Copeland GP,Khoshafian SN.Adecompositionstoragemodel [C].ProcofThe1985ACMSIGMODInternationalconferenceon ManagementofData,1985.
AnewSQLtechniques’s architecture design and practice for relational database
LIHan
Abstract:With the rapid development of the industrial big data, the Big Data applications in industrial fields have proposed more higher demands for data management techniques such as data storage and data processing.As traditional architecture of mini-computer and array storage,it has limited the capacity and scalability ofDBMSsystem. This paper have summarized the key techniques a kind of NewSQLDBMS-GBase 8a MPPbased on MPPand column-oriented architecture. By the advanced techniques of GBase 8aMPP, we can effectively solve the restrications faced by traditional database such as scalability, parallel computing capacity for massive data, and high availability under inexpensive hardware conditions.
Keywords:big data; massive parallel processing; relational database; column-orientedDBMS;relational operator
收稿日期:(2016-03-28)
猜你喜欢
山东冶金(2022年2期)2022-08-08
科学技术创新(2020年22期)2020-01-09
青春岁月(2016年21期)2016-12-20
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
江西理工大学学报(2013年1期)2013-03-20
