
基于Petri网的Hadoop性能仿真系统的设计与实现
2016-07-02 07:29北京邮电大学数据科学中心硕士研究生刘北京邮电大学数据科学中心副教授刘北京邮电大学数据科学中心副教授
信息通信技术与政策 2016年4期
关键词:性能优化
杨 生 北京邮电大学数据科学中心硕士研究生刘 军 北京邮电大学数据科学中心副教授刘 芳 北京邮电大学数据科学中心副教授
基于Petri网的Hadoop性能仿真系统的设计与实现
杨生北京邮电大学数据科学中心硕士研究生
刘军北京邮电大学数据科学中心副教授
刘芳北京邮电大学数据科学中心副教授
摘要:随着Hadoop在学术界和工业界的广泛应用,极大推动了大数据技术的发展,如何更为高效地使用Hadoop成为了业界关注的焦点。本文介绍了对Hadoop性能进行仿真的方法,及其实现机制。
关键词:Hadoop;性能仿真;Petri网;性能优化;集群搭建
1 引言
伴随着Hadoop的出现,其展现出的高效、易用、稳定、扩展性好等诸多优点,成为了学术界和工业界进行海量数据处理的首选方案,更是名符其实开启大数据时代大门的金钥匙。
数据驱动业务作为大数据时代的核心命题,如何完成海量数据的及时处理以满足业务需求,一直是当今业界最主流的研究方向。面对大型互联网公司动辄过千台的Hadoop集群规模,有效地提升计算效能尤为重要。其他各领域的公司也紧随时代脚步发展了自身的数据分析部门,满足业务需要并控制成本,则是这些公司更为注重的。因此,对Hadoop的数据处理能力进行预估,并提供集群优化指导建议是非常有必要的。
但是通过传统的测试对比分析的方法来评估Hadoop处理能力具有较大的局限性。首先,由于Hadoop作业往往完成耗时较长,测试实际运行情况效率低下;其次,Hadoop集群的配置参数复杂繁多,并且都会对性能产生影响,对比分析的方法代价高昂;最后,不同配置参数对性能产生的影响权重不同,并会由于处理Hadoop作业的不同,而产生变化。因此,本文将介绍使用仿真的方法来预测Hadoop的性能,并通过仿真结果提供集群配置优化建议。
2 仿真系统的整体设计
建立仿真模型来预测Hadoop性能之前,需要先对影响集群计算效能的参数进行抽象提取。从集群的物理计算能力来讲,硬件的配置情况起着决定性作用;从Hadoop的体系结构来讲,HDFS和MapReduce分别都具备着影响作业执行情况的因素;在集群和Hadoop两者之外,在分布式环境中运行的具体Hadoop作业也会因为其计算需求复杂情况的各异,导致各自的执行过程耗时不同。
根据参数的作用范围不同,分为代表集群硬件特征的参数、代表Hadoop体系相关的配置参数、代表作业计算复杂程度的参数三大类(见表1)。

表1 仿真参数列表
Hadoop任务调度逻辑构建在Petri网的仿真平台的基础之上,整体架构如图1所示。Petri网是1960年由卡尔·A·佩特里发明的数学模型,用于对离散的并行系统进行数学的表示,可以很好地描述异步的、并发的计算机系统模型。
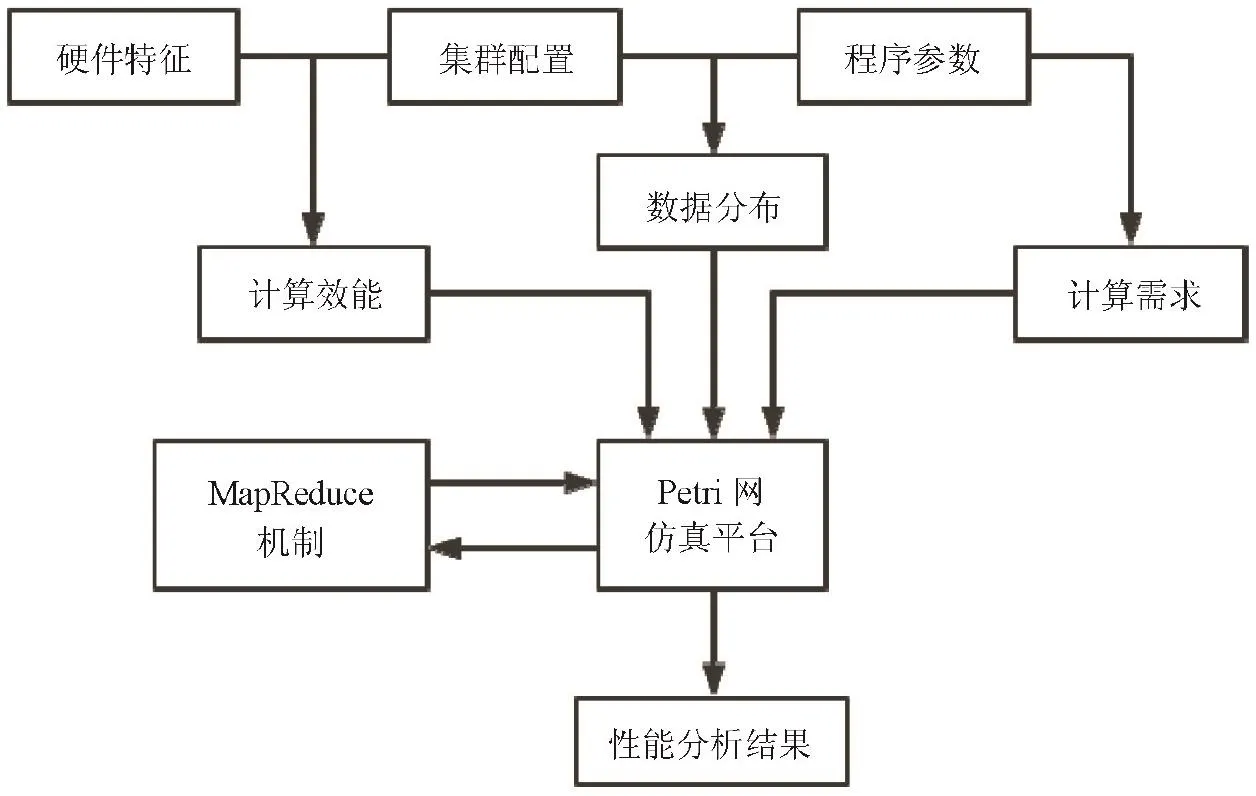
图2 仿真系统架构图
根据集群配置和程序参数,可以推算出HDFS中的数据分布信息。这里笔者做了第一个假设,认为在仿真模型中的每个数据分块均是满的。这可能会导致某些数据在实际存储的数据分片数目与仿真模型的数据分片数目不一致。因为在实际环境中,由于很多文件的大小并不恰好与数据块尺寸匹配,使得分片的数据量并不足以达到整个数据块的最大容量。
同时,仿真模型会预估出可能进行的远程调度任务的数据分片个数。非本地化执行的作业数目,会对Hadoop性能表现产生非常巨大的影响。衡量这种情况发生的比例,称之为远程调度比例,当数据分配不均,集群硬件差异较大时,这个比例也会随之增加。根据远程调度比例参数,将HDFS中所有数据分块划分为本地作业、跨节点作业、跨机架作业及跨数据中心作业。对不同类型的作业,根据其特征加以惩罚参数,从而保证整个仿真过程的准确性。
根据硬件特征与集群的配置参数,可以推测出这个实际集群的运算效能。运算效能包括两方面,一是能够同时进行并行计算的单元个数;另一个是每个计算单元的单位时间计算能力。仿真系统将具有计算能力的每个单元认为是完全平等的,这源自MapReduce的实现机制。每个CPU核心被认为是一个计算单元,在模型中它作为一个令牌,用于触发一个计算过程的执行,当计算结束后,这个令牌将被归还。通过待处理的数据量和MapReduce程序的各阶段复杂度,可以确定出计算需求。采用CPB(Cycles Per Byte)作为衡量程序复杂度的指标,CPB是处理单位数据量所需要的CPU时钟周期。值得注意的是,每个阶段的待处理数据量是发生变化的,仿真系统根据计算需求预测出各子阶段的时间耗费。
3 仿真参数的获取
通过搭建Hadoop集群测试环境,将Hadoop作业的各个阶段执行情况保存到日志中,并实现对相关仿真参数的提取。
由于不同Hadoop作业的业务需求不同,所以其对应的Mapper和Reducer对于相同输入数据量所需要的计算时间也不同,这里使用单位输入数据量所需耗费的CPU时钟周期为衡量标准。在Hadoop测试环境中,对相关类代码的修改,日志能采集到对应Mapper和Reducer任务启动、内存缓冲区读取完成、任务结束等关键时间点。以Mapper过程为例,各日志记录时间点如图2所示。
其中,时间点A、C分别为Mapper任务启动和结束的时间,时间点序列B为每组内存缓存读取完成的时间。为方便阐述,到达B点的时间将根据进入循环的次数,分别称之为B1、B2…Bn。时间点A至时间点B1,相邻时间点Bi与Bi+1之间,包括了数据从硬盘读入内存缓冲去与数据计算的时间耗费。时间点Bn至时间点C,则为最后一个缓存进行计算所占用的时间。
根据Setup到第一次ReadBuffer结束的时间耗费和内存缓冲区大小,可以计算出磁盘的平均读取速率。根据最后一次ReadBuffer结束到Cleanup的时间减去平均计算时间,在考虑内存缓冲区大小,可以计算出磁盘的平均写入速率。根据两次ReadBuffer间的时间耗费包含上一次缓冲区数据的计算时间和新一次缓冲区数据读取的时间,进而计算出CPB。
日志中除根据各阶段时间的统计之外,也包含了Hadoop本身的日志机制所记录的各个阶段所读取写出的数据量。通过统计Mapper的平均数据读取产出比,可以推算出Shuffle阶段所需要传输的数据量。在Shuffle阶段,假定所有的中间数据被均匀的分配给所有的Reducer中,这里需要考虑存在Mapper与Reducer在同节点的情况,发生比例与总节点个数相关,且近似等于(节点个数/Reducer)个数,据此仿真出跨节点Shuffle数据的时间耗费。Reducer阶段的仿真方法与Mapper阶段类似,不再赘述。
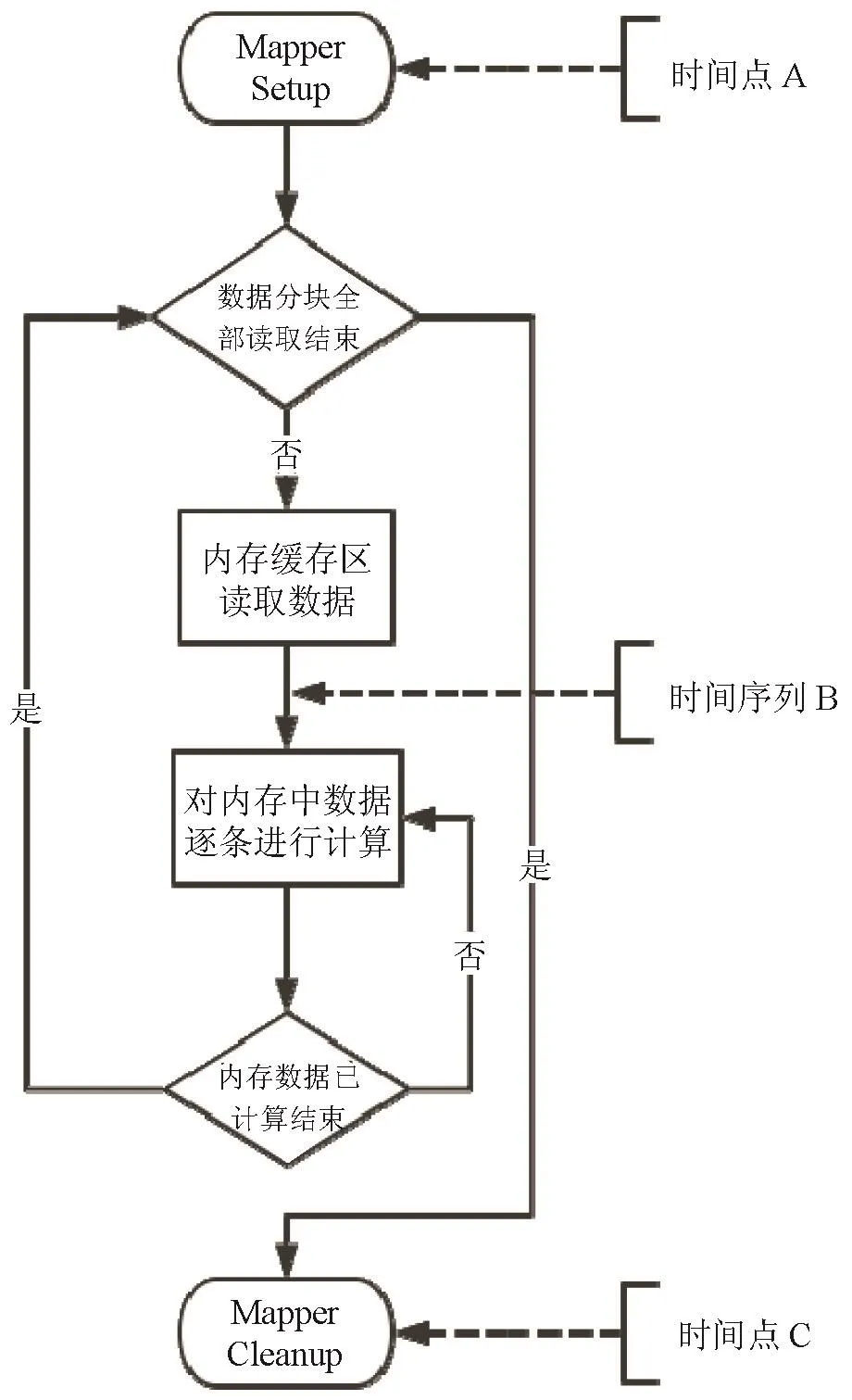
图2 Mapper日志时间点
4 仿真系统的应用
通过仿真的方法来预测Hadoop集群的性能表现,主要可以应用于两大方向。一是通过较小数据量的测试数据来预估处理海量数据的总体耗时,并通过在仿真系统中修改相关配置参数,来比较计算效能的变化,从而为优化性能提供指导建议,这是大型互联网公司的主要需求;二是根据测试结果,推测在异构集群环境中,为达到实际所需的计算效能所需构建的集群规模,这对于需要进行成本控制的集群搭建有着重要的指导意义。本文将从这两方面对仿真系统进行应用测试说明。
在Hadoop集群中,由于HDFS数据分块尺寸会对整体的计算效能产生影响,为了验证这种影响,对不同输入数据量情况下,64和128MB数据分块尺寸的WordCount作业执行时间进行了对比。Hadoop集群环境参数如表2所示。
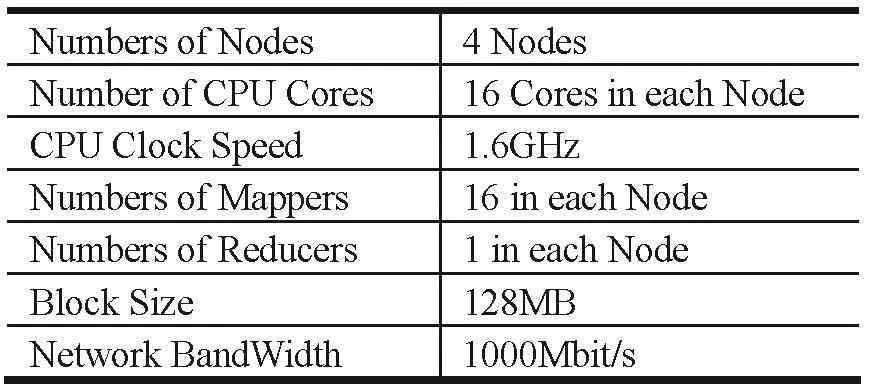
表2 Hadoop集群环境参数表
根据对3、15、30、60、120GB5组输入数据规模的仿真结果,可以发现在输入数据量超过30GB后,通过增大HDFS数据分片大小,可以有效地提高Hadoop作业的运行表现。Hadoop作业仿真时间如表3所示。
为了进一步验证仿真结果的准确性,在搭建Hadoop集群中进行了实际测试,对比结果如表4、5所示。
通过比较两者的拟合程度,可以发现仿真模型在预测Hadoop集群配置改变的情况下,可以保证平均误差小于5%,并随着输入数据量的增长拟合程度呈现上升趋势。在实际环境中,更改Hadoop集群的参数配置需要重新启动集群才能生效,因此直接进行集群参数调试代价高昂,借助仿真系统可以极大的简化这个过程,对于优化Hadoop集群性能方面意义重大。
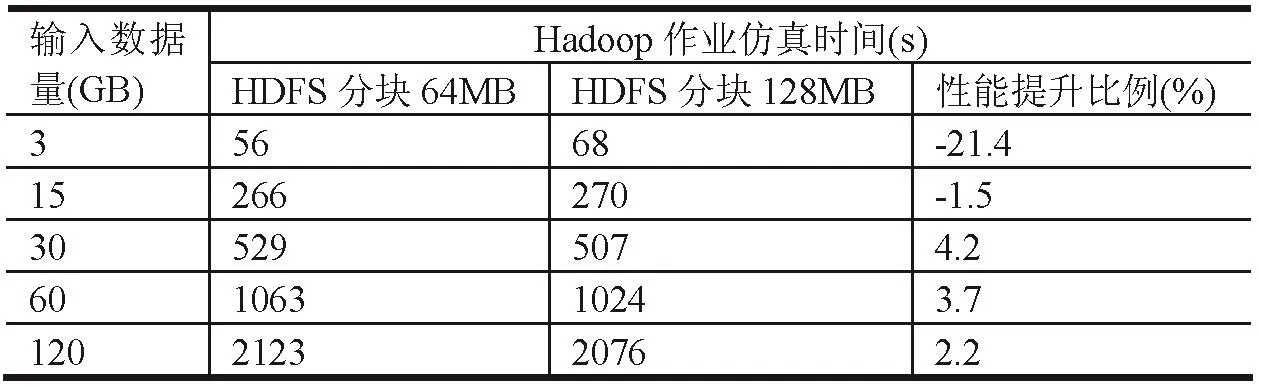
表3 HDFS分块影响仿真对比表
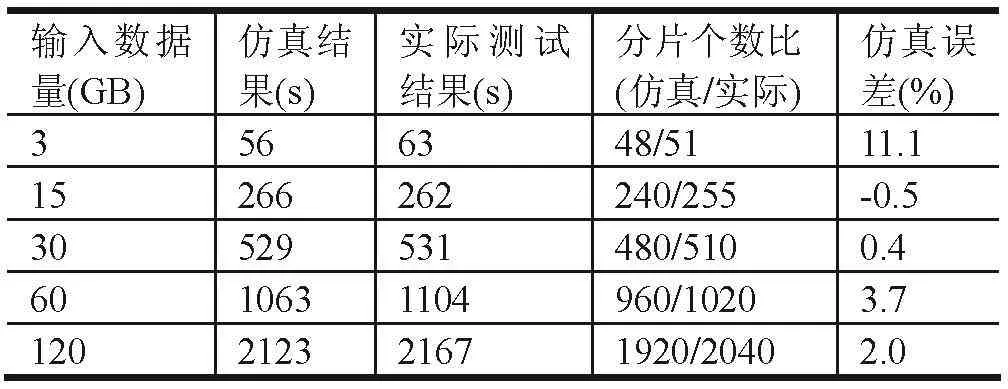
表4 HDFS分块64MB结果表
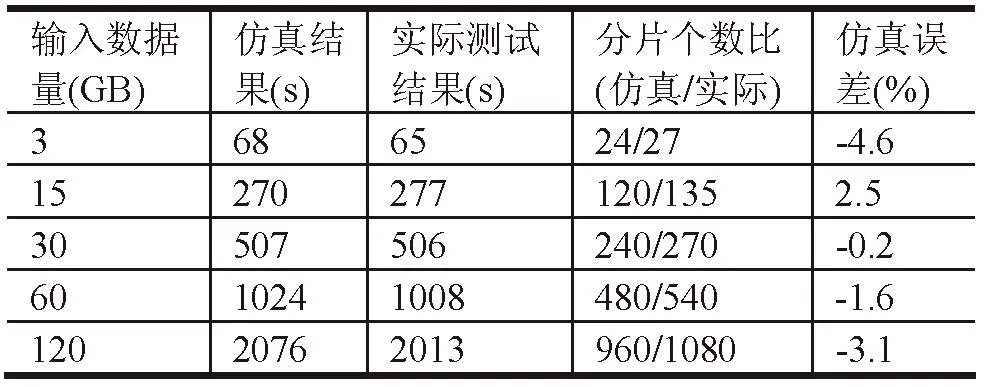
表5 HDFS分块128MB结果表
通过修改仿真模型的集群硬件参数,可以实现异构集群条件下作业执行时间的预测,从而为实现满足特定业务条件下的集群搭建,提供成本控制指导建议。测试中,对异构Hadoop集群相对地减少了节点个数和CPU核心数量,计算能力有所下降,具体参数如表6所示。
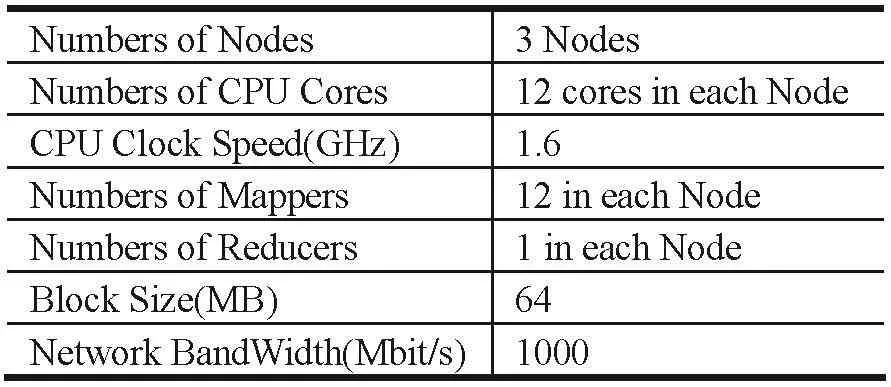
表6 异构Hadoop集群参数表
使用仿真系统预测异构集群环境下WordCount作业的执行时间,并将预测结果与在实际环境下的测试结果进行对比,结果参见表7。
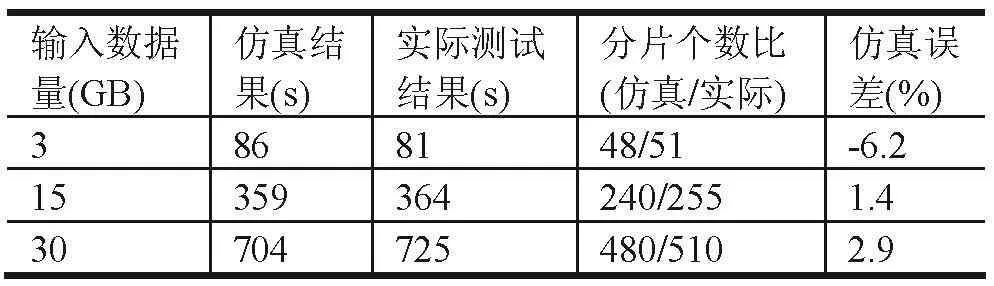
表7 集群环境变化仿真结果表
通过比较两者的拟合程度,可以发现仿真模型在预测异构Hadoop集群可以保证平均误差小于5%,借助仿真系统来预估Hadoop作业的执行时间,为集群环境的搭建提供了明确的指导。
专家视点
Design and implementation of Hadoopperformance simulation system basedonPetri-net
YANGSheng,LIUJun,LIUFang
Abstract:AsHadoop is widely used in academia and industry, the big data technology has been greatly promoted.The efficient of Hadoop become the focus of attention.The design and implementation of Hadoop performance simulation are introduced in this article.
Keywords:Hadoop; performance-simulation; Petri-net; performance-optimization cluster-structure
收稿日期:(2016-03-20)
猜你喜欢
中国新通信(2016年22期)2017-01-13
电子技术与软件工程(2016年20期)2016-12-21
电脑知识与技术(2016年10期)2016-06-16
科技视界(2016年1期)2016-03-30
