
自愿性信息披露质量综合评价方法研究*
——基于熵权法
2016-06-30 02:00北京理工大学李慧云李亚楠
财会通讯 2016年13期
北京理工大学 李慧云 李亚楠 陈 铮
自愿性信息披露质量综合评价方法研究*
——基于熵权法
北京理工大学李慧云李亚楠陈铮
摘要:参考Botosan的研究思路,本文构建出一套定性与定量指标共存的自愿性信息披露质量评价体系。鉴于熵权法可以使定性指标通过归一化处理客观的反映信息披露质量,本文运用熵权法对各指标客观赋权,并对赋权后的质量评价体系进行了一致性检验,以期为自愿性信息披露质量的综合评价方法研究提供思路。
关键词:自愿性信息披露质量综合评价方法熵权法
对于上市公司而言,自愿性信息披露是一种公共行为,其目的是增加信息的透明度,减少资本市场信息不对称现象,降低道德风险和逆向选择产生的可能性,从而提高资本市场运行效率,最终保护投资者的合法利益。因此,自愿性信息披露质量越高,对资本市场运行与投资者投资决策而言越能起到增强透明度的作用。那么如何衡量自愿性信息披露质量就显得尤为重要。在衡量自愿性信息披露质量时,首先需要建立一个合理的综合评价指标体系,其次选择合适的综合评价方法进行指标权重的确定,最后运用于上市公司的自愿性信息披露质量的综合评价。鉴于熵权法不仅能全面结合各因素反映的信息量的多少;而且权重的高低是由各指标传递给决策者的信息量多少来决定的,使得在对自愿性信息披露质量的评价过程中减少了主观性的干预。因此本文采用了熵权法来评价自愿性信息披露质量。
一、综合评价方法概述
信息披露分为自愿性信息披露与强制性信息披露。信息披露质量的综合评价方法同样适合于自愿性信息披露质量的评价。目前在我国信息披露质量综合评价方法主要运用的是:基于“功能驱动”原理的赋权法,主要有层次分析法和德尔菲法;基于“差异驱动”原理的赋权法,主要有主成分分析法、因子分析法和熵权法(表1)。
在对自愿性信息披露质量进行综合评价中目前我国学者们主要采用了主成分分析法和熵权法。游茜(2013)和洪涛(2007)在对自愿性信息披露质量的测度时,运用主成分分析法对多个影响因素提取主成分,指标的减少便于进一步的计算、分析和评价。齐爱年、李红霞(2007)基于熵权法对公司内部治理结构和自愿性信息披露程度关系进行了实证研究。综上所述,目前对自愿性信息披露质量的综合评价方法运用甚少。但是信息披露领域运用得综合评价方法较多,熵权法、因子分析等方法都有出现,其中以熵权法运用得最多。在参考了上述文献之后,本文采用了熵权法来评价自愿性信息披露质量。

表1 常用的综合评价方法
二、研究设计
(一)指标体系构建本文依据Li,HY;Zhang,L(2013)参考Botosan的研究思路,以2012年修订的《年报准则》为依据,构建出的自愿性信息披露的指标体系,如表2所示。
(二)指标计算方法及步骤自愿性信息披露综合评价指标体系建立了之后,就要根据上市公司年报的披露情况,进而对照自愿性信息披露综合评价指标体系进行打分。分数分为0/1/2三档,满分为2分。具体打分规则为:描述性项目(表1中以“*”标注)没有披露得0分,简单描述得1分,详细描述得2分;分析性项目(表1中以“**”标注)没有披露得0分,仅定性或定量描述得1分,定性和定量均描述得2分。

表2 自愿性信息披露指标体系
(1)综合评价方法的选择。根据前文所述的综合评价方法选择准则,本文选择了熵权法这种综合评价方法进行自愿性信息披露质量的综合评价。德尔菲法与层次分析法虽然在指数计算时可以引入权重,但是它们一个共同的缺点是主观性与随意性太强。主成分分析法与因子分析法虽然应用也较广泛,但是其缺陷也显而易见,仅能得到有限的因子、主成分的权重,而各个指标独立的客观权重却无法获得。因此这种方法对因子之间关系相关度很低时就不太适合。而在本文建立的自愿性信息披露指标体系里,28个指标虽然被划分在4个大类中,但每个大类里的指标相对独立,相关性不是很强,因此并不适用于因子分析法、主成分分析法。而熵权法相对而言,就没有严格适用的前提条件,只要是关于评价问题中的指标权重,均可使用。除此之外,还可以在运用此方法的过程中剔除掉对结果贡献不大的指标,因此更加适用于对本文指标体系中各项指标的赋权。此外,熵权法的以下特点,与自愿性信息披露评价十分匹配:
第一,熵值不是绝对的、静态的,而是相对的、动态的,类似于像组成要素的数量、要素的种类、要素间关系及有用信息量都会对其产生重要的影响;无独有偶,自愿性信息披露质量也不是绝对的、静态的,而是相对的、动态的,它也会受自愿性信息披露的多少、自愿性信息的种类及各类自愿性信息间关系、有用自愿性信息量这些因素的影响。可见,二者之间有很强的内在一致性。除此之外,熵的特性也使得对变量做任何处理,包括数学上或者是逻辑上,信息量都不会增加。从而那种数学建模可能产生信息增量的现象不再发生,使得测度不仅是合理的,而且是更科学的。
第二,自愿性信息披露评价体系中定性指标与定量指标共存,为了使定性指标也客观的反映自愿性信息披露质量,利用熵模型所具有的可以对各指标进行量化处理这一特性,对自愿性信息披露评价体系中所包含的各个指标进行了归一化处理。
第三,在熵模型中,由于熵权系数方法本身传递的信息量就决定了各评价指标的权重。因此,不仅使得测度结果更具客观性,而且更能反映上市公司本身的固有信息。同时消除了上市公司因行业、规模不同而形成的不可比,使得最终的结果具有可比性,适用性更强。
综上,熵权法能全面结合各因素反映的信息量的多少,以此计算出一个综合的指数。且这种基于“差异驱动”原理的综合定权法,权重的高低是由各指标传递给决策者的信息量多少来决定的。采用熵权法确定评价指标权重,使得在对自愿性信息披露质量的评价过程中减少了主观性的干预,从而使得各评价指标对自愿性信息披露质量的影响也同样能得到了客观地反映,对量化评估自愿性信息披露水平来说非常有实用价值。因此,本文选择熵权法来确定自愿性信息披露评价体系中各指标的权重。
(2)自愿性信息披露指标权重的确定。熵权法确定权重的具体步骤如下:
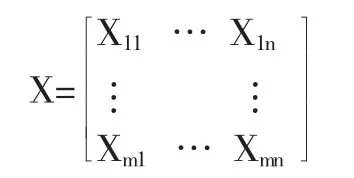
第一,建立初始矩阵。设被评价上市公司集S ={s1,s2,…,sm},指标集T={t1,t2,…,tn},m家被评价上市公司对应于n个评价指标的指标值(即分数值)构成评价指标值初始矩阵X:
第二,矩阵无量纲化。对X作无量纲化处理,得到x' = (xij')m×n,xij'是第i家被评价上市公司在指标j上的值。具体处理方法如下:
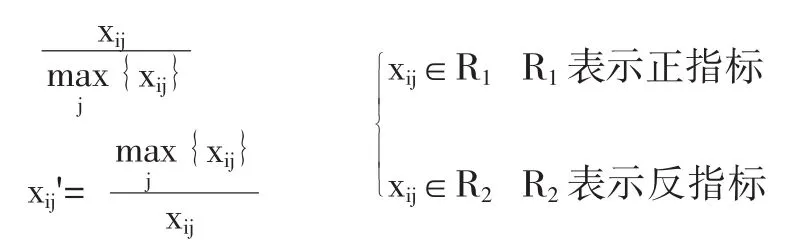
其中,正指标表示值越大越好的指标,反指标表示值越小越好的指标。对xij'进行平移,得到:xij=xij'+0.1
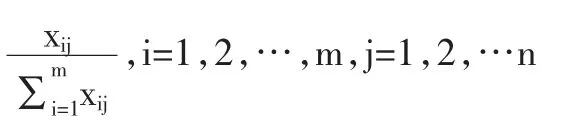
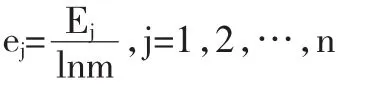
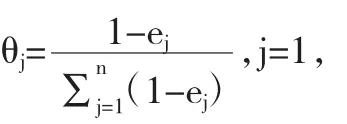
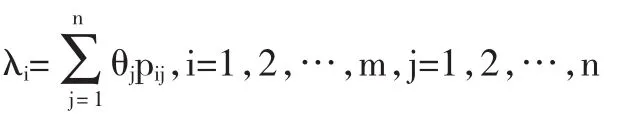
三、熵权法的运用
本文选择深市制造业380家上市公司为研究对象。采用如下规则对样本进行筛选:第一,选取深圳证券交易所的主板和中小板上市公司作为样本。原因是:目前在我国只有深圳证券交易所对在其所挂牌上市的公司每年进行信息披露考核评级;深圳证券交易所与上海证券交易所要求上市公司每年披露信息的时间不同;创业板市场主要面向符合新规定的发行条件但尚未达到现有上市标准的成长型、科技型以及创新型企业,行业覆盖面相对较窄。为了使研究结果更具有可比性的同时能得到一定程度的检验。本文选取了深圳证券交易所的主板和中小板上市公司作为样本。第二,选取截止到2013年底深市上市的制造业公司,一方面因为制造业在上市公司中所占的比重最大,达到67.64%,既包括机械设备、纺织、石油、钢铁等传统工业行业,也包括电子、生物医药等新兴行业,具有较好的代表性;另一方面是因为环保措施、劳保政策、研发计划等自愿性信息披露指标更适合于制造业公司,以制造业公司为样本具有一定的针对性。第三,样本公司的选择采取分行业随机抽样方法。从深市主板和中小板811家制造业上市公司中剔除ST(包括*ST)公司和资料缺失的公司,剩余760家公司。对760家上市公司分子行业按1/2的比例随机抽样,最终得到380家公司作为研究样本。本文需要的数据,一部分来自深圳证券交易所网站下载的公司年报、社会责任报告和信息披露考评,一部分来自万得。本文的数据处理采用Excel2010软件。
(一)熵权法下指标权重的确定按照前文所述的打分规则,首先为380家上市公司自愿性信息披露评价体系的各指标打分,然后根据熵权法确定权重的步骤进行计算,即可得到各指标的客观权重,如表3。
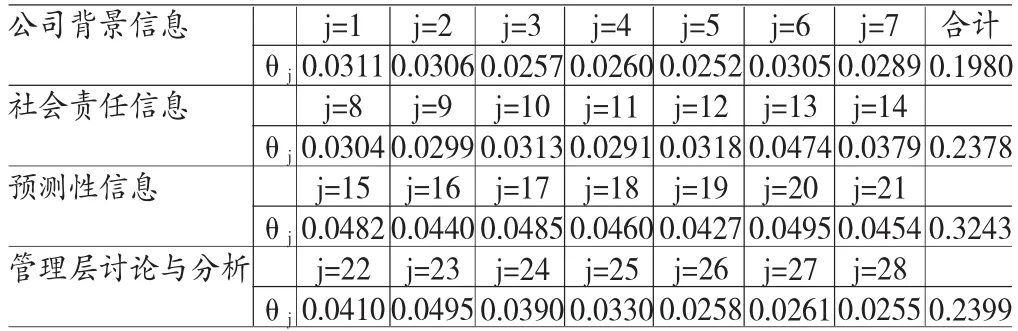
表3 2014年熵权法下各指标的客观权重
表3中可以看出,2014年权重较大的前三个二级指标分别为指标20(利润预测)、指标23(税收缴纳)和指标17(营业收入预测),权重分别为0.0495、0.0495和0.0485。说明这三项指标在自愿性信息披露的过程中差异性最大,应引起特别关注。权重较小的后三个二级指标分别为指标5(风险管理机制建设)、指标28(自主创新情况分析)和指标3(实现公司愿景的保障),权重分别为0.0252、0.0255和0.0257。说明这三项指标在自愿性信息披露的过程中差异性较小。针对四项一级指标而言,预测性信息的权重最大为0.3243,说明这项一级指标在披露的过程中差异性较大,应引起利益者相关者的注意;公司背景信息的权重最小为0.1980,说明这项一级指标在披露的过程中差异性较小,各上市公司对这一指标的披露情况大体相当。
(二)熵权法下自愿性信息披露质量的综合评价根据公式计算出2014年中样本公司自愿性信息披露质量的综合评价值,并进行了排名。由于样本量过大,本文只列取了排名前10名与后十名的样本。如表4所示。
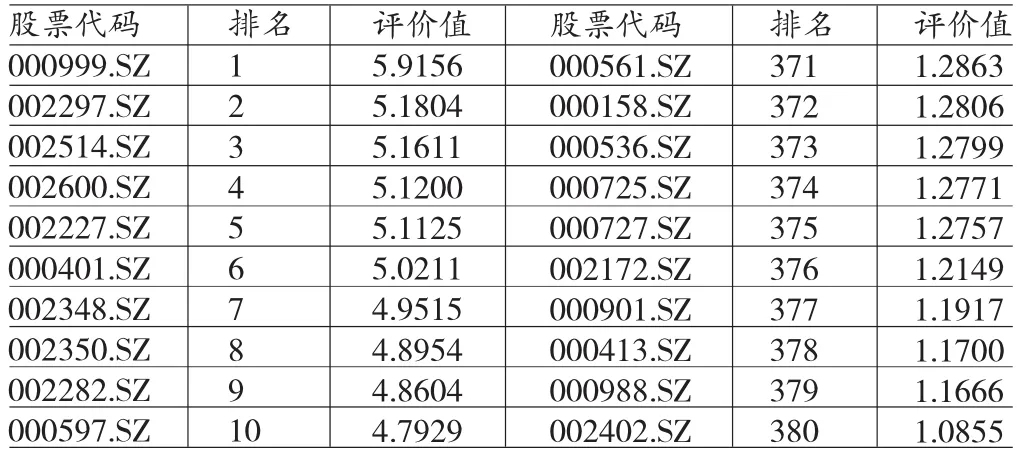
表4 熵权法下2014年样本公司自愿性披露评价值(%)及排名
从表4中可以看出,自愿性信息披露质量最高的上市公司分别是000999.SZ、002297.SZ和002514.SZ,评价值均大于5.1;自愿性信息披露质量最低的军工上市公司分别是002402.SZ、000988.SZ和000413.SZ,评价值均小于1.2。
(三)熵权法下构建的自愿性信息披露指标体系检验较好的准确度、区分度是评价一个测评体系有效与否的标准。对本文构建的上市公司自愿性信息披露测评体系最直接的检验便是与企业的真实自愿性信息披露质量进行比较,识别测评得分与其真实自愿性信息披露质量测度的差别,但是企业的真实自愿性信息披露质量我们无法也不可能获取。
目前,深交所作为我国公开发布信息披露质量考评结果的相对权威机构,公布的上市公司信息披露考评结果从真实性、准确性、完整性、及时性、合法合规性和公平性等六个方面对企业信息披露质量进行评定,并且把考核结果依据上市公司信息披露质量从高到低划分为A(优秀)、B(良好)、C(合格)、D(不合格)四个等级。本文选取深交所信息披露考评结果与构建的自愿性信息披露质量测度体系测出的结果进行对比。本文将380家样本公司进行归类,并把A、B、C、D考评结果分别赋值为3、2、1、0(见表5)。
通过表5、表6,可以看出通过熵权法计算出来的样本公司排名结果与深交所信息披露考评结果完全相同的比例为50.26%,[-1,1]之间的差异度占比为92.37%。可以看出基于熵权法算出的测度值与深交所的评级数据具有一致性。
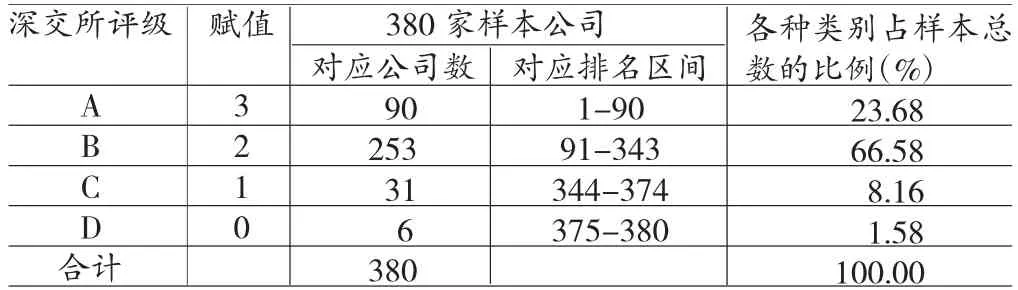
表5 2014年样本公司归类及赋值表
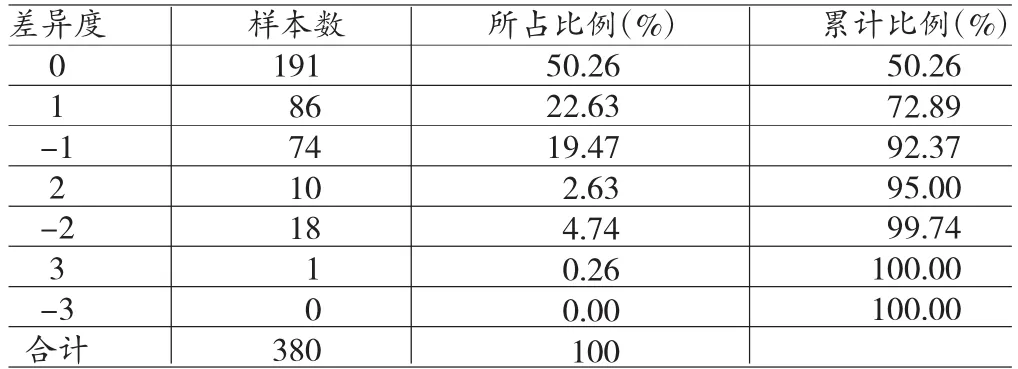
表6 2014年样本公司自愿性信息披露考评结果差异表
四、结论
本文运用熵权法对各指标客观赋权,并且赋权后的自愿性信息披露质量评价体系得到了一致性检验。本文为自愿性信息披露质量的综合评价方法研究提供了思路。
参考文献:
[1]洪涛:《主成分分析法在上市公司自愿性信息披露中的应用》,《科技情报开发与经济》2007年第30期。
[2]齐爱年、李红霞:《熵权理论在自愿性信息披露评价中的应用》,《科技与管理》2007年第1期。
[3]游茜:《管理层权力、薪酬激励与在职消费自愿性披露水平—来自中国国有上市公司的经验证据》,西南财经大学2013年硕士学位论文。
[4]陈正伟:《综合评价技术及应用》,西南财经大学出版社2013年版。
[5]郭亚军:《综合评价理论、方法及拓展》,科学出版社2012年版。
[6]Li Huiyun,Zhang Lin. Construction of the voluntary disclosure indicator system of listed companies. 7th International Symposium on Corporate Governance,2013.
(编辑刘姗)
*本文系国家社会科学基金重点项目(项目编号:13ATJ003)、国家自然科学基金(项目编号:71140006)阶段性研究成果。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
选煤技术(2022年2期)2022-06-06
心理学报(2022年5期)2022-05-16
客联(2021年3期)2021-09-10
董事会(2020年9期)2020-11-24
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
商(2016年1期)2016-03-03
