
基于聚类的热词发现与关联分析
2016-06-22 09:18:02罗旭欧阳纯萍刘志明南华大学计算机科学与技术学院衡阳421000
现代计算机 2016年14期
罗旭,欧阳纯萍,刘志明(南华大学计算机科学与技术学院,衡阳 421000)
基于聚类的热词发现与关联分析
罗旭,欧阳纯萍,刘志明
(南华大学计算机科学与技术学院,衡阳421000)
摘要:
关键词:
0 引言
随着互联网的日益普及,网络往往成为有影响力事件发布的第一平台,然而网络上产生新闻的速度远远超过人所接受的程度,如果采用人工分检的方法,肯定不能达到快速得知当前互联网的热点信息。因此,对热词进行快速识别,并对我们想要了解的热词加以关注,迅速分类与这些热词相关的新闻,可以快速了解当前舆情,及时对热点信息作出处理。
在新闻话题的发现技术中,聚类算法应用较广。习婷等[1]将两种聚类算法Single-Pass和K-means进行了比较,认为K-means虽然错检率和漏检率较低,但具有需要预先制定聚类数目和随机初始化的缺点。王伟等[2]通过对样本网页文本的特征提取,构建文本向量空间模型,使用OPT ICS聚类算法获取网页热点簇,并且为了更加精确,还根据热点簇特征向量对网页进行二次聚类,从而获取关于舆情的时间演变模式。袁方等[3]为了改善传统K-means对初始聚类中心敏感,计算每个数据对象所在区域的密度,选择相互距离最远的k个处于高密度区域的点作为初始聚类中心,得到较好的聚类结果。
在如何得到热词关联关系中,李渝勤等[4]采用命名实体识别技术和高频串统计技术进行短语串的划分,再进行热度权值的计算,通过同现率的原则确定热词类之间的关联计算。
仅仅依靠同现率来确定热词类之间的关联度存在一定的局限性,热词的出现是成簇的出现的,因此本文将新闻话题与热词关联结合起来,选择K-means聚类算法得到话题,由话题得到相应的热词类簇,再由热词类簇计算热词关联度。较为有效地展现当前的热词类的分布以及热词之间的关系。
1 热词发现系统功能及方案设计
以“南华大学”为新闻舆情监测目标,具体提供热词统计,展示热词关联关系等功能。我们围绕这些功能,主要完成以下工作:第一,将新闻从数据库中提取并进行分词,以及去除停用词等预处理;第二,在热词发现模块,进行tf-idf计算以构建VSM模型,然后使用K-means聚类算法对新闻进行聚类,得到热词类簇并进行相应处理;第三,计算热词关联度,由聚类得到的热词类簇和新闻同现率等结合一块得到热词关联关系,最后进行展示。具体步骤之间的联系如图1所示:
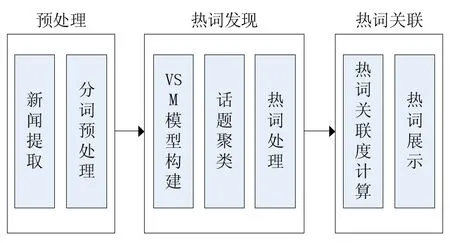
图1 热词发现与关联分析框图
2 热词发现与关联分析关键技术
2.1VSM模型构建
在最开始对新闻文本做分词处理,采用开源的Hanlp汉语言处理包中基于条件随机场的分词方法。在热词中,往往新词出现的频率较高,采用CRF分词较为合理。
要得到一篇文本的向量空间模型,首先得计算文本中每一个词汇的权重大小。本文采用以TF-IDF值作为词汇的权重值,首先计算加权词频因子tf,以计算词汇在文本出现的频率作为tf值。
IDF逆向文件频率是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到:
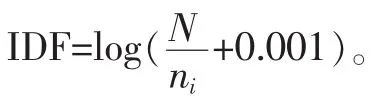
在此之上,结合了出现在文档中不同位置的词的特性[5],如meta中keyword、title和description等关键词在文档中的权重,因此tf值为
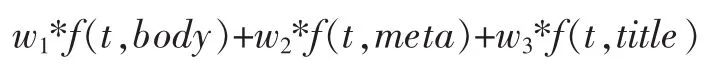
f(t,body)表示是词汇在文本正文中出现,f(t,meta)则是在网页的meta信息中出现,f函数对应各自词汇的tf-idf值,w1,w2,w3是相应的权重系数。
在计算idf的过程,因为需要得到包含该当前词汇的文件的数目,需要多次遍历计算,本系统因此做相应的优化,预处理各个词汇的idf值,使得计算速度大大加快,算法复杂度由O(n2)降到O(nlogn)。
接下来进行特征选取,如果抽取所有文本词汇作为文本特征向量集合,因为分词之后的词汇量极大,因此有必要对文本特征向量集合做降维处理,根据词权值筛选出部分词汇作为全局文本特征向量。最后就是建立每一篇文本新闻的向量空间模型,对应每一篇文本新闻,将其自身的文本特种向量投影到全局文本特征向量,由此可得到向量空间模型。对于每个新闻文本i,设Ti为其特征向量,k(i,j)是全局特征向量中的词,w (i,j)是其在当前文本i中词汇j对应的特征权值,m为全局特征词向量中的总个数,文本可表示为Ti=[(ki,1,wi,1),(ki,2,wi,2),(ki,3,wi,3),…,(ki,j,wi,j),…,(ki,m)]。
因为各个词汇的特征权值因为新闻文本的差异,会导致某些值过于太大或太小以至于某一维或某几维对数据影响过大,因此对向量进行归一化处理,对于在特征向量中的每一个词
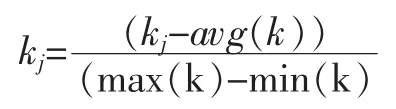
2.2话题聚类
聚类可以认为是非监督学习中最重要的问题。K-means算法基于目标的特征将目标分为K类,K为事先定义。基本思想就是定义K个中心,每一类簇都有一个中心,类簇里的物体是以计算相似度函数的大小为基准相对靠近而聚集。
算法步骤如下:预先定义K大小,随机选择K个文本向量作为中心,之后对于剩下的每一个文本,计算其到每一个类簇中心的欧几里得距离,并将其划分到最近的类簇中,遍历分配完后,重新计算每个类簇的中心,不断循环直到1.聚类中心不再移动或者2.迭代次数达到指定次数。算法时间复杂度是O(K*N*T),k是中心个数,N数据集的大小,T是迭代次数。
在选取初始中心时,算法对初始聚类中心敏感,从不同的初始聚类中心出发,得到的聚类结果也不一样,并且一般不会得到全局最优解。本系统则采用取相互距离最远的k个点作为初始中心,消除算法对初始聚类中心的敏感性,并能得到较好的聚类结果[3]。
对于文本相似度计算,采用了比较传统的夹角余弦值计算各特征项之间的距离,并且同各个类簇中心的值作比较,归类到一个和其相似度最大的类簇。向量A与向量B的夹角余弦值如下计算:
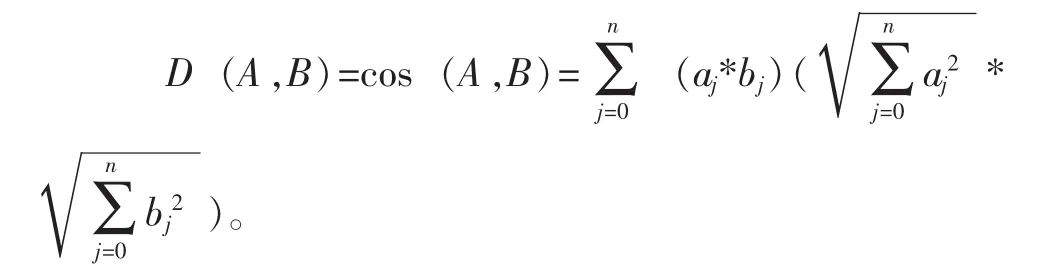
2.3热词关联分析
热词与热词之间是有联系的,这一块将之前话题聚类得的话题进一步处理,得到词与词之间,词群与词群之间的联系。
具体步骤如下:取SVM向量模型中的全局文本特征向量作为展示热词。联系的表现形式为矩阵,两两之间有相应对应关系,关系权值即为热词的关联度。矩阵由三个部分构成,新闻同现率矩阵,类别距离矩阵,热词同现矩阵。三个矩阵赋予相应的权重系数,进行累加既可得到最终的热词关联矩阵。
(1)新闻同现率矩阵定义为任意两个热词代表的新闻集合中重叠的大小。在之前的聚类模块中,可以得到每个热词具有的新闻集合,遍历两者既可得到相应的重叠率。
(2)类别距离矩阵定义为由聚类得到不同的词群,词群内部的关联度以及词群与词群的关联度就是类别距离矩阵。遍历每一个类簇中心,在这里称为词群,得到中心权重向量,为不保证权重太大或太小,进行归一化处理。在这里,因为词与词互相都有关联,矩阵将两步处理,第一步,在同一个词群里的词汇,以权重最大的词为中心点,其他词只与这个中心点形成关联,这样形成一个星状的发散结构,使得展示较为明晰。第二步,对于其它词也就是其他词群的词,以较小权值向量作为关联值。
(3)热词同现矩阵定义为两个热词在同一文章中出现的几率。因此遍历所有新闻查看是否有同时出现即可。
最后,新闻同现率和热词同现矩阵都要进行矩阵归一化处理,要保证矩阵最后均要大于零,
同时考虑到矩阵中大部分关联值为零,归一化反而使得这些值不为零,所以特殊化处理,不考虑这些零值。三者矩阵加权累加即可得到关联矩阵。
3 系统实现
本系统以南华大学相关新闻为舆情监测目标,因此采集的新闻也以南华大学新闻为主,选择2015-08-28到2015-10-04之间新浪、腾讯、红网、凤凰等有关南华大学的298篇新闻。因为新闻来源广泛,内容复杂随机,可能会引入不相干的数据。因此,在分词阶段还要进行相应的过滤,去除与南华大学不相关的“香港《南华早报》”新闻,“台湾南华大学”等,以及去除相应的停留词。
得到所有新闻分词后的词汇后,对这些进行tf-idf值计算,根据各个词的tf-idf值进行排序,筛选出10%的词汇,去重,作为全局文本特征向量。其次建立VSM模型,例如随机抽取一篇来自新浪的新闻“南华大学分专业靠抓阄招生后细化专业如何分流?”,其部分特征向量权重值如表1所示。
通过K-means获得K个类簇中心,这里预先指定k=5,从而聚类获得5个新闻热点类簇。具体如表二所示:
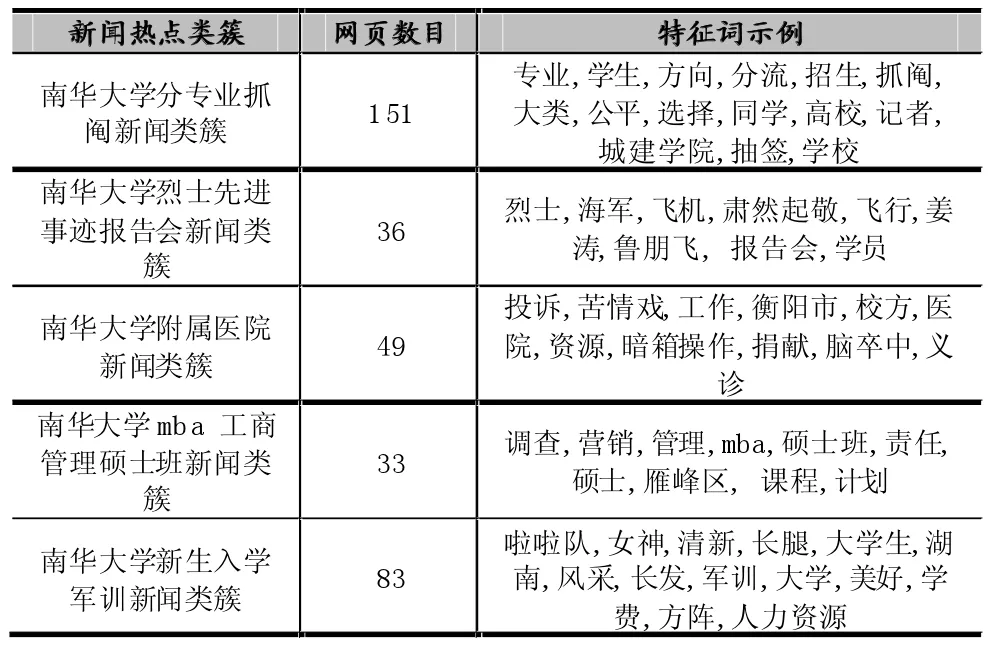
表2 新闻热点类簇
可以看到虽然新闻的热点信息多样化,但是聚类还是能够取得一个比较明显的热点区分。但是在各个热点类簇下还存在着很多与此热点不相干的新闻,精度还需要有所提高。

表1 新闻VSM模型
在得到热点类簇后,要对热词进行处理,添加热词的情感的褒贬程度以及敏感程度,进而得到每个热词的热度,并且根据类簇添加与之相关的新闻。因在展示时,热词不能太多,将全局特征词按照热词热度权值进行过滤,只获取1.5%的热词。由热词关联度模块得到关联矩阵。进行展示如图2所示:
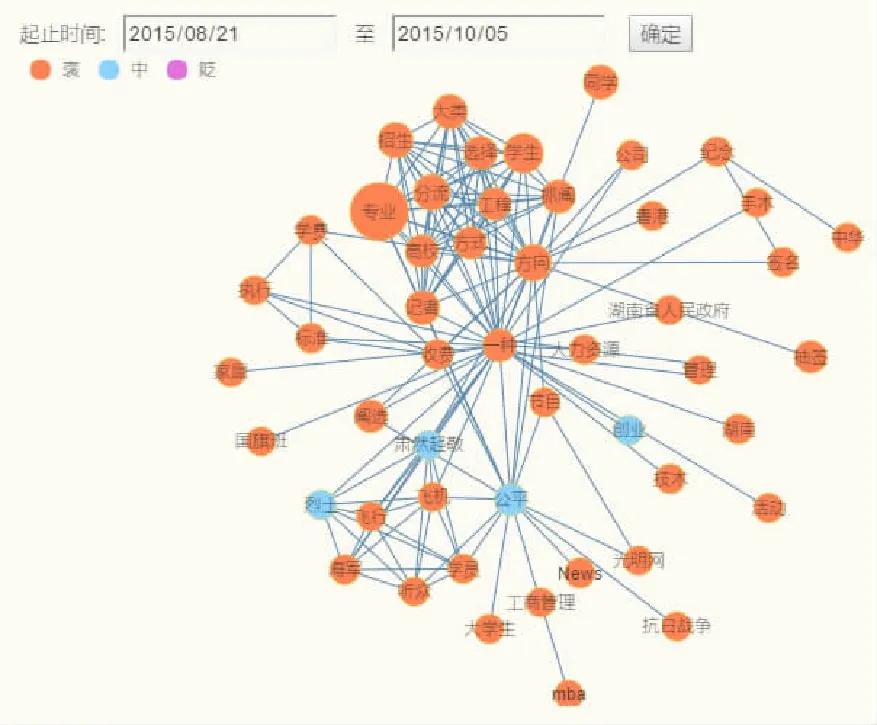
图2 热词关联展示
图中关于“专业靠抓阄”以及“海军先进事迹报告”的新闻热词较为集中,清晰地展现了两个事件具有很高的热度。根据图中节点的大小来展示不同的热度值,热度越高的词所在的节点面积将越大。例如,“专业”在这些新闻里具有极高热度因此也是最为明显的。但是不少的杂词的混入以及词汇的相对松散,导致其余热词事件不够明显。
4 结语
热词发现及关联分析已经被广泛应用,能够较为清晰地反映当前发生的新闻事件。本文提出把K-means聚类算法得到的话题运用到计算热词关联度上,能够有效地提供热词统计,展示热词关联关系。然而K-means聚类算法具有必须预先指定K数目,才能进行聚类的缺陷。但在实际中,热点数目往往是未知的,具有不确定性,因此可以考虑采用改进的Single-Pass增量聚类等算法替代K-means算法。另外,在热词选择中,热词随时间推移会出现突然的变化,即时间因子对于热词具有非常明显的印象,因此下一步可以将时间因素考虑进去。
参考文献:
[1]Ting,X.and L.Jufang,A Comparative Study between Single-Pass Algorithm and K-means Algorithm in Web Topic Detection.Atlantis Press,2014.
[2]Wei,W.,X.Xin.基于聚类的网络舆情热点发现及分析*.现代图书情报技术,2009,3(3):74-79.
[3]袁方,周志勇,宋鑫,初始聚类中心优化的K-means算法[J].计算机工程,2007,33(3):65-66.
[4]李渝勤,孙丽华,面向互联网舆情的热词分析技术.中文信息学报,2011,25(1):48-53.
[5]GESANG,D.,et al..基于Single-Pass的网络舆情热点发现算法.电子科技大学学报,2015(4).
Hot-Word Detection and Relations Analysis Based on Document Clustering
LUO Xu,OUYANG Chun-ping,LIU Zhi-ming
(School of Computer Science and Technology,University of South China,Hengyang 421000)
Abstract:
Proposes a method to discover hot-word relations based on topic clustering.For word discovering,vector space mode is built by extracting document features from news text,and the hot -spot cluster is achieved by K-means algorithm with ameliorated initial center.Up to the hot-word association,hot words relations are analyzed according to the weighted sum of three factors,which include the word category distance computed by the hot -spot cluster,the news co -occurrence rate and the hot words co-occurrence rate.This approach has been successfully applied to Public Opinion Monitoring System of University of South China and it obtains good results in practical operation.
Keywords:
提出一种将话题聚类算法应用到计算热词关联度上的方法。在热词发现阶段,通过对新闻文本的特征提取,构建向量空间模型,采用初始聚类中心优化的K-means算法,获取热点簇;在关联分析阶段,先通过热点簇计算词类别距离,再和新闻同现率,热词同现率加权累加,得到热词关联度。该方法已成功应用到南华大学舆情监测系统中,并在实际运行中获得较好的效果。
K-means;SVM;热词;词群关系
基金项目:
湖南省哲学社会科学基金(No.14YBA335)
文章编号:1007-1423(2016)14-0056-05
DOI:10.3969/j.issn.1007-1423.2016.14.012
作者简介:
罗旭(1993-),男,江苏泰兴人,本科,研究方向为自然语言处理、数据挖掘
欧阳纯萍(1979-),女,湖南衡阳人,副教授,硕士生导师,研究方向为自然语言处理、语义网
刘志明(1972-),男,湖南浏阳人,教授,硕士生导师,研究方向为大数据分析、知识工程
收稿日期:2016-03-25修稿日期:2016-04-30
K-means Algorithm;SVM;Hot Words;Words Relationship
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
南华大学学报(自然科学版)(2021年3期)2021-12-06 00:13:26
时代邮刊(2021年8期)2021-11-26 12:48:48
南华大学学报(自然科学版)(2021年4期)2021-09-14 09:10:12
新世纪智能(英语备考)(2021年4期)2021-07-28 06:21:52
新世纪智能(英语备考)(2021年11期)2021-03-08 01:09:58
南华大学学报(自然科学版)(2021年6期)2021-02-12 07:12:42
少先队活动(2018年8期)2018-12-29 12:15:54
大东方(2018年8期)2018-09-10 03:43:57
