
电力企业投诉工单文本挖掘模型
2016-06-20 07:23刘兴平章晓明林少娃章琛敏国网浙江省电力公司电力科学研究院杭州310014
电力需求侧管理 2016年2期
刘兴平,章晓明,沈 然,林少娃,章琛敏,张 维,朱 斌,何 韵(国网浙江省电力公司电力科学研究院,杭州 310014)
电力企业投诉工单文本挖掘模型
刘兴平,章晓明,沈然,林少娃,章琛敏,张维,朱斌,何韵
(国网浙江省电力公司电力科学研究院,杭州310014)
摘要:以客户投诉工单和回访不满意工单为样本,引入LDA文档主题生成模型对文本信息进行中文自然语言处理和数据挖掘,发现问题属性类别,通过大数据对文本挖掘结果进行分析和监控,构建适合电力公司的投诉工单文本挖掘模型,实现对工单进行分类筛选、便签判断和初步归因。
关键词:客户满意度;诉投工单;文本挖掘;大数据分析
随着电力行业售电侧改革不断加深,对客服管理质量要求越来越高,需要进一步改善客户体验和提升客户满意度。要提升客户满意度,必须从客户不满意点出发,客户投诉的工单分析就是其中的关键环节。本文依据一般客服问题管理机制和文本挖掘理论,并结合电力企业客服特点,阐述了如何对客服投诉工单文本进行挖掘分析以及如何在系统中的应用。
业务工单中的投诉工单、客户回访处理不满意的工单能直接反映客户对产品、对服务的感知,是客户满意度的最直接反映。从现状来看,目前的工单处理方式,是由调查分析人员通过对95598客户诉求数据的分析,以此来发现客户对问题感知的不满意点。这种方式缺乏有效的辅助分析手段,分析手段单一,影响服务问题的分析和解决效率,因此需要构建客服投诉工单文本分析模型,利用中文自然语言处理、数据挖掘、人工智能等技术,结合电力领域的业务特点,对工单进行自动化的智能分析与处理,以实现文本学习、挖掘问题工单及原因、统计分析和大数据分析监控等。
1文本挖掘相关理论
1.1文本挖掘技术
文本挖掘(Text Mining,TM)是近几年来数据挖掘领域的一个新兴分支,是以文本数据为特定挖掘对象的知识挖掘。文本挖掘是抽取有效、新颖、有用、可理解的、散布在文本文件中的有价值知识,并且利用这些知识更好地组织信息的过程[1—2]。文本挖掘的要点是分词,根据文本数据中的特征信息进行分词处理,以此构建文本的中间表示[3]。原始的文本数据以结构化的数据呈现之后,再利用分类、聚类等技术转化为结构化文本,进而发现新的概念和获取相应的关系[4]。
1.2基于领域特征词表的特征词标注
以大量投诉工单中反映业务种类、问题现象、问题原因的特征词为基础,设立特征词表,进行基于特征词匹配的子句标注,并依不同维度进行工单分类。在实际应用中发现,基于领域特征词表的辅助分析,可以显著提高工单分类、聚类等的准确性和效率[5]。
1.3基于大数据的数据监控分析
通过构建检测模型和确定模型指标体系、指标阈值等参数,对工单数据进行大数据分析,采取可视化大屏全屏展示的方式进行全方位多角度的展开实时监控、分析、预警和展示,及时发现当前问题、变化趋势,并对问题点改进情况进行跟踪[6]。
2电力客服工单文本挖掘模型构建
2.1客服工单文本挖掘模型结构
从客户感知出发进行问题挖掘,选取客户投诉的受理工单、回访工单和归档工单为样本,进行文本挖掘,以发现问题、判断问题属性和类别,对问题归因分析,并通过大数据对文本挖掘结果进行分析和监控,以此构建本文文本挖掘模型。整个文本挖掘思路达到对工单的分类筛选、便签判断和初步归因的效果,从而利于在信息化系统平台的支撑下,达到对工单数据的及时分析和监控管理的目的。
客服工单的管理模型如图1所示,主要有样本选取、问题预处理、模型训练和大数据分析等大类。其中,文本学习指采取数据挖掘技术对文本进行挖掘,并与设立的特征词库进行比对;分类归因指将各个工单与相应的问题标签、原因标签对应起来,以达到问题分类和归因挖掘的目的;模型优化指通过模型的自动学习,加上专家经验辅助,不断地完善各类特征词库,使得模型准确率不断提升;统计分析指采用大数据技术、以大量数据为基础,进行多维度的统计分析;监控分析指监控各单位相关服务指标的变化,设立预警阈值,并对问题点解决情况进行跟踪分析。
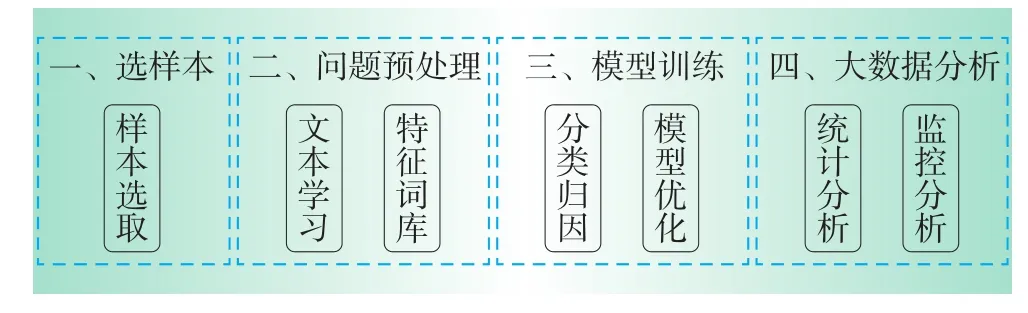
图1客服工单管理模型结构
2.2数据来源
数据的主要来源有:①国网95598客服系统中投诉受理工单、回访不满意工单信息;②营销系统和配网抢修平台提供的工单受理时间、故障区域、故障所在线路等基本信息;③反映客户主要诉求信息的投诉受理记录内容、投诉处理过程记录。
2.3文本学习
文本学习主要通过2种方式进行:专家经验和自动学习。利用专家的丰富经验,对问题的特征词和原因的特征词进行总结,例如:在投诉服务人员态度不好的工单中,工单的投诉受理记录文本或投诉处理过程记录文本会出现“态度差”等词汇,于是把“态度差”等词汇设置为态度类问题工单的特征词,特征词不唯一;在由于天气原因造成的投诉工单中,工单的投诉受理记录文本或投诉处理过程记录文本会出现“雷电、暴雨、台风”等词汇,于是把“雷电、暴雨、台风”等词汇设置为此类天气类原因造成投诉工单的特征词,特征词不唯一。
专家经验的文本学习方式是常态化机器自动学习的判断前提和补充,系统的判断也需要人工的进一步判断,在系统不断升级优化的过程中通过系统自动学习的方式,不断对问题及原因特征词库进行补充,后期系统将对各类问题及其原因在不同维度的统计分析,统计分析的结果将作为自动学习的参考依据,辅以人工辅助,进行特征词库的调整。例如:某一类问题或者原因的工单,存在某个词汇多次反复出现,十分显著,则将这个词汇自动添加到此类特征词库中。
2.4模型训练
中文自然语言文本进行自动化处理的基础是对文本进行挖掘算法建模。本文引入LDA文档主题生成模型对文本进行挖掘分析,它采用了词袋(bag of words)的方法[7],这种方法将每一篇文档视为一个词频向量,每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。针对每一篇文档,LDA主题生成主要有3个步骤:首先对每一篇文档,从主题分布中抽取一个主题;其次从上述被抽到的主题所对应的单词分布中抽取一个单词;最后重复上述过程直至遍历文档中的每一个单词。用LDA模型对大量工单进行挖掘,再与特征词库进行匹配,将不同的特征词进行分类,划分为不同的标签,再将不同标签与各个工单进行对应。其中,标签的设立也会采取专家经验进行人工辅助的方式设立。
例如:电力公司接到投诉工单的处理内容文本为:“4月2日晚,XX供电所接到投诉工单后,供电所所长立即开展仔细的调查,调查结果是:4月2日19:05,由于突然的恶劣天气,导致变电所10 kV线路的995线和991线均同时被雷击跳闸停电,为尽快恢复供电,供电所值班人员全部外出抢修,值班室内只留有保安人员一人应急处理值班电话接听工作;由于停电面积广,停电咨询电话较多,供电所3个值班电话****3901,****3832,****6866同一时间响起(当时投诉人潘先生拨打电话****6866),保安忙于处理其他2个值班电话,导致投诉人潘先生等待时间长,并产生焦急心理,待电话接通时,潘先生语气较急,认为保安拖延,服务态度差。”
从上面的工单来看,将上述文档设为D,由一个单词序列
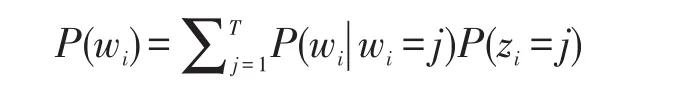
式中:zi是潜在变量,表明第i个词汇记号;wi取自该主题;P(wi|zi=j)是词汇wi记号属于主题j的概率;P(zi=j)给出主题j属于当前文本的概率。假定T个主题形成d个文本,且以W个唯一性词汇表示,为记号方便,令ψ(wz=j) =P(z=j)表示对于主题j,W个词汇上的多项分布,其中w是W个唯一性词汇表中的词汇;令φdz=j=Pz=j表示对于文本d,T个主题上的多项分布,于是文本d中词汇w的概率为
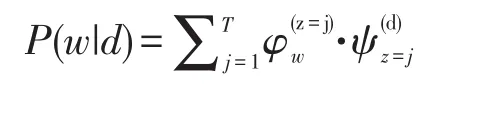
通过上述方式,文本中出现的“恶劣天气”、“拖延”和“态度差”等词汇与特征词库中“拖延”、“态度差”等词汇契合,匹配成功后,查找这2个词统属的标签,假设标签为“服务态度差”,则将问题标签“服务态度差”与该工单进行关联,将此作为该工单的问题点;将“天气恶劣”等词汇与原因特征词库进行匹配,匹配成功后,查找这个词统属的标签,假设标签为“客观原因”,则将此原因标签与该工单进行关联,将此作为该工单的原因点。通过模型的使用,特征词库的不断调整,也是一个不断优化的过程。
通过如上所述的方式,系统自动进行文本挖掘,起到工单的筛选、分类和初步归因的作用,将大量工单以标签的形式进行分类和归因,极大地减少工作量,提升工作效率,提高服务质量。
2.5大数据统计分析
2.5.1挖掘结果统计分析
通过问题点的筛选与分类、问题的分析与归因,得到一系列具有大数据挖掘价值的数据,例如:各类问题点在某时间段出现的次数、各类问题点在不同时间段出现的变化趋势、各类问题点占比等,以大量的数据为基础,进行各个维度的统计和分析:进一步进行问题点的穿透分析,找到问题原因本质,设立典型问题和专题问题,出具不同类型的解决方案;后台报表自动关联进行统计分析,包括工单反应问题和原因的时间、责任归口部门、责任人、空间分布等。
以前文提到的投诉工单为例,通过文本挖掘对工单进行标签设置,其中原因标签为“天气恶劣”,将大量的挖掘结果进行统计分析,如果在较长时间内以“天气恶劣”作为原因的投诉工单数量庞大,或在某个区域内出现此类投诉数量显著高于其他区域,则归类为专题问题,进行深层次的归因。深层次的归因分析,需要专家以统计分析结果辅助进行,出具分析报告和问题改进方案,包括改进问题点、改进措施、责任归口部门、改进措施内容、改进时间计划、阶段性改进目标等,以期达到针对性进行下一步工作的目的。
2.5.2大数据分析监控
大数据分析监控主要分为2个部分:大数据监控分析和问题点改进跟踪。
大数据监控分析主要通过监控各单位相关服务指标的变化(例如:故障抢修到达现场),设定需重点关注工单的筛选规则。通过对指标值趋势变化的分析以及指标值是否到达预警阈值从内外2方面对相关服务质量的变化进行检测。
问题点的改进跟踪主要指问题点的改进过程在系统中留有改进执行痕迹信息,例如:问题点、所属业务类型、所属业务环节、归属责任单位、归属责任部门、开始改进时间、结束改进时间等。分析人员跟踪、查询业务部门的措施执行情况,并对完成整改的措施进行执行效果评价,支持进行多次评价。在业务研判环节,如果针对同一个单位部门、相同业务类型、相同业务环节出现相同的问题点,则系统进行告警,提醒分析人员关注,结合该问题的改进执行是否已结束,综合分析该问题点的改进方案是否要调整,并对问题改进效果进行评估。
3客服投诉工单管理系统
基于客服工单文本挖掘模型的浙江电力客服投诉工单管理系统建设采用满足技术先进性与成熟性相结合的基于J2EE的多层技术构架,以提高系统的灵活性、可扩展性、安全性以及并发处理能力。
采用组件技术将界面控制、业务逻辑和数据映射分离,实现系统内部的松耦合,以灵活、快速地响应业务变化对系统的需求。系统在技术上划分为客户端、展现层、业务逻辑层(包含公用组件和业务支撑)、信息层和企业数据总线,通过各层次系统组件间服务的承载关系,实现系统功能,具体如图2所示。

图2客服投诉工单管理系统架构
客服投诉工单管理系统关联海量数据,通过样本选取、问题预处理、模型训练和大数据分析,结合专家经验,实现业务逻辑层的各项业务支撑功能;实时查找服务问题突出点和热点,实现全省电力客户服务情况综合分析和展示,及时掌握全省服务水平和状态;预警潜在投诉点,实现用户行为预测,协助一线工作人员制定个性化服务方案,同时给公司决策层提供数据支撑和依据。
4总结和展望
客服工单文本挖掘模型建立起了常态化文本挖掘模型方法,涉及问题发现、问题筛选、问题分析、归因分析、统计分析等,提高了问题点归因的可信性和准确性,降低了人力成本。
考虑到客户服务质量将在未来处于越发重要的地位,其业务复杂程度将日益加深,因此在模型调优上仍然有进步的空间。在客服投诉工单管理系统中,可以挖掘的数据庞大,需要进一步明确各类数据口径、范围、评价对象及指标价值。通过研究不断地增减和调整各类需要挖掘的对象,丰富和完善指标体系,挖掘出更多具有价值的数据和指标,在经过分析后,更好地为下一步的工作目标、工作重点起到指导作用。
参考文献:
[1]王丽坤,王宏,陆玉昌.文本挖掘及其关键技术与方法[J].计算机科学,2002(12):12-19.
[2]潘钢.上海移动公司客户投诉管理研究及应用[D].上海:上海交通大学,2013.
[3]谌志群,张国煊.文本挖掘研究进展[J].智能识别与人工智能,2005(1):65-74.
[4]陈阳,凌俊民,蒙圣光.投诉数据智能挖掘分类管理系统[J].数字技术与应用,2011(6):146-149.
[5]Kodratoff Y. Knowledge Discovery in Texts:A Definition and Applications. Proc[C]∥ISMIS’99,Warsaw,1999.
[6]高崇,韩雨.基于大数据分析的运营监测信息系统应用[J].科技与创新,2015(12):116.
[7]李文波,孙乐,张大鲲.基于Labeled⁃LDA模型的文本分类新算法[J].计算机学报,2008(4):620-621.
(本栏责任编辑徐文红)
Text mining model of electric power complaint work
LIU Xing⁃ping,ZHANG Xiao⁃ming,SHEN Ran,LIN Shao⁃wa,ZHANG Chen⁃min,ZHANG Wei,ZHU Bin,HE Yun
(State Grid Zhejiang Electric Power Corporation Research Institute,Hangzhou 310014,China)
Abstract:Taking customer complaint work order and unsatis⁃faied return visit as sample,the article introduces LDA text informa⁃tion model to Chinese natural language processing and data mining. Analysis and monitoring of the text mining results also uses the big data analysis. The model is aimed to achieve the effect of classifica⁃tion and selection,note and judgment,initial attribution. Under the support of the information system platform,the timely analysis and monitoring management is achieved.
Key words:customer satisfaction;complaints work order;text mining;big data analysis
中图分类号:F407.61
文献标志码:B
文章编号:1009-1831(2016)02-0057-04
DOI:10.3969/j.issn.1009-1831.2016.02.015
收稿日期:2015-11-19;修回日期:2016-01-08
猜你喜欢
软件导刊(2016年12期)2017-01-21
中国远程教育(2016年11期)2016-12-27
中国管理信息化(2016年21期)2016-12-27
科技传播(2016年19期)2016-12-27
电子技术与软件工程(2016年22期)2016-12-26
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
中国远程教育(2016年9期)2016-11-19
语文教学之友(2016年5期)2016-06-15
