
基于正则藤Copula的行业系统性信用风险传染分析
2016-06-17 03:07申敏
工业技术经济 2016年6期
申 敏
1(南京工业大学,南京 211816) 2(南京航空航天大学,南京 211100)
基于正则藤Copula的行业系统性信用风险传染分析
申敏1,2
1(南京工业大学,南京211816)2(南京航空航天大学,南京211100)
〔摘要〕本文利用国民经济中九大门类行业相关数据,将度量行业信用风险的CCA方法加以改进,并构建正则藤Copula模型,揭示了样本行业间信用风险的非线性相依结构及信用风险传染路径。实证结果显示:各行业信用风险水平不一,但都较好地拟合了实际经济;任意两行业间无条件信用风险大多表现为下尾相关性,但条件信用风险的尾部相关性总体较弱;国民经济行业体系中存在加剧和减缓行业信用风险传染的“风险催化行业”和“条件隔离行业”。最后,提出了有效控制系统性金融风险、防范金融危机的措施建议。
〔关键词〕CCA信用风险正则藤Copula
引言
作为国际银行业监管实践标杆的《巴塞尔协议Ⅲ》提出从宏观审慎的视角出发,在更为广泛的领域中强调了监测与防范系统金融风险的重要性,该协议推进了更复杂的统计工具在金融研究中的应用。构成国民经济的行业众多,某一行业的金融创新和经济发展可以带动整个市场的繁荣,但其金融风险也会影响其他相关行业甚至整个市场的发展,单纯的转移而不是消除风险很有可能最终让整个金融市场崩溃。本文将以全球面临的主要金融风险——信用风险为研究对象,研究行业间的风险传染关系。
金融危机引发宏观经济衰退最显著的特征是,负向反馈回路(Adverse Feedback Loop)导致的风险螺旋式放大机制。由于各非金融行业间的互补性或相似的经营范围,使其相关程度和违约传递非常明显。因此,行业风险的关系及其动态特征得到了学术界的广泛关注。Gray和Malone[1]在构建了国民经济四部门风险调整的资产负债表后,基于CCA方法量化了冲击以及各部门风险的非线性传递机制。Castrén和Rancan[2]构建了包含金融
和非金融部门的宏观经济网络,描述了欧元区通过信贷渠道和证券市场表现出的金融体系和企业部门的双向联系,识别出最具有风险传播效应的部门。国内对行业或部门风险的研究,主要集中在金融部门和主权部门等国民经济部门。李杨等[3]编制了我国主权资产负债表后,发现近期的风险与长期风险的主要表现。肖璞等[4]采用CovaR方法,量化了我国上市银行之间的风险溢出效应及单个银行对整个银行系统的风险贡献率。巴曙松等[5]运用Systemic CCA方法研究了我国银行业的系统性违约风险。宫晓琳和杨淑振[6]结合CCA方法和最大熵方法以及网络理论,全面量化了我国宏观金融风险及其演变机制。此外,吴恒煜[7]等利用CCA方法和面板计量方法讨论了我国行业风险的决定因素和传递机制。然而,上述文献仅仅是研究了某个行业或某几个部门的信用风险,并没有分析各行业间风险的非线性相依结构及信用风险的传染路径及传染方式。
长期以来,关于金融问题的一些重要理论都是基于多元正态分布的假设,而众多实证研究发现的对数收益率呈现尖峰厚尾现象及变量间的非
线性相关性明显与该假设相悖。目前最流行的用于刻画高维变量的联合分布的是Sklar[8]提出的Copula理论。然而,当变量维数增加时,确定适合的copula函数的最大障碍就是“维数灾难”[9]。Joe[10]最先提出将多变量的联合分布问题分解为构建一系列独立的Pair Copula模块的方法。Bedford和Cooke[11,12]对该方法进行了系统深入的研究,提出了基于图论思想构建的正则藤的概念。Cooke和Kurowicka[13]又在此基础上做了更深入的研究。Aas等[14]通过将多种类型的Copula函数应用于不同的Pair Copula,拓展了Pair Copula的应用范围。由于这种识别方式类似于构建一系列具有一定规则的树藤,因此相应的方法又称为藤Copula或正则藤Copula(R-Vine-copula)。该方法集结所有潜在双变量的Copula无疑是一种灵活又可操作的方法,非常适合为金融数据建模。Aas等[14]主要阐述了正则藤的两个特例,即C-藤和D-藤,但是这两种结构只适合于描述两类特定的相依关系。事实上,正则藤分布族包含多种形式的结构,远远不止上述两种形式,但目前为止,其他的正则藤分布结构很少被用于实证。
基于以上综述,本文确定将根据实证研究数据,利用藤Copulas中相对更灵活的正则藤Copula考察国民经济中的九个最重要的行业间的信用风险相依关系,为宏观审慎管理系统性金融风险提供政策依据。
本文的主要贡献如下:(1)利用GARCH模型将CCA方法进行改进,更能体现金融数据的时变波动性,信用风险度量更加准确;(2)建立了比C-藤和D-藤更为灵活的正则藤Copula结构,更加真实地反映了多个行业间的信用风险相依关系;(3)发现了信用风险行业间传染中的具有使风险传染程度加强的“风险催化”行业和使风险传染减缓的“条件隔离”行业,为了解信用风险传染机制及系统性金融风险的控制提供参考。
1行业信用风险指标——违约距离
信用风险属于非系统风险,难以量化,数据也较难获取。因此,它的度量远比市场风险的度量困难得多。本文首先引入度量信用风险的传统CCA(或有权益分析)方法,然后通过条件异方差模型加以改进,计算出单个行业的信用违约距离,以其作为信用风险的度量指标。
1.1CCA方法
CCA方法起源于Black和Scholes[15]以及Merton[16]的期权定价理论,具有非常直观的经济学意义,并且由于综合了市场数据与财务数据,更能动态反映企业信用风险的变化,因此在理论界得到了广泛的应用[17-19]。在CCA分析框架中,债务是有风险的,称为风险债(D),其价值源于企业资产的价值(A)。具有不同优先权(即高级索取权D和低级索取权E)的债务的价值将随着资产价值的随机变化而变化(A=D+E)。当A低于承诺的负债水平B(即无违约债务的价值或称为违约障碍)时,违约发生,E=0;当A高于B时,无违约,E=A-B,此时的风险债D即为无风险债B。因而,低级索取权E(通常表示为股权价值)可视为以资产价值A为标的,以违约障碍B为协议价格的看涨期权。
在度量信用违约风险时,常常利用违约距离DD作为信用风险指标。当假设企业资产价值At服从几何布朗运动时,根据Black-Scholes公式及Ito引理得:
Et=AN(d1)-Be-r(T-t)N(d2)
(1)
σEEt=σAAtN(d2)
(2)
(3)

在已知Et、σE、Bt、r、T-t的情形下,联立公式(1)、(2),利用牛顿迭代法,进行Matlab编程,可得出违约距离DD。
1.2改进CCA方法
将股权市值波动率σE视为常数往往不符合金融数据常表现出的自相关、尖峰厚尾及异方差性,因此,放松“同方差”的假定,将会使计算结果更加准确。
事实上,当股权市值的收益率存在自相关和异方差现象时,可利用AR(1)-GARCH(1,1)模型进行过滤,获取股权收益率的时变波动率σEt,模型如下:
(4)
将σEt代入上述(2)式即可得出体现金融时间序列条件异方差的违约距离。
如果将行业看成是由单个企业构成的组合,则CCA方法的应用范围便可以从单个企业扩展至行业层面,从而可以考察整个行业的信用违约风险。下面本文将以违约距离DD作为度量行业信用风险的指标。
2正则藤Copula模型构建
信用风险的损益分布具有不对称性,这将导致投资组合违约的概率比正态分布时要高出许多。另外信用风险通常会表现出非线性相关性,导致传统的皮尔森线性相关系数不足以准确描述个体间信用风险相依性。从而不能准确发现信用风险在整个系统中的传染机制。因此,在确定了单个行业信用风险违约距离的基础上,需要考察不同行业间的信用风险可能存在的复杂的非线性相依关系,而目前灵活度量多变量间可能存在的具有不同特征非线性相依关系的方法是正则藤Copula(R-Vine Copula)方法。
2.1正则藤Copula模型介绍
由Sklar定理[8]知,高维数据的联合分布可由边缘分布与Copula函数联合表出。但是,一般的多维Copula函数,如椭圆类或阿基米德类Copula由于其对参数的唯一性要求较高,因此不能很好地刻画多变量之间的相依关系。比如,Gaussian Copula无法刻画金融风险厚尾特征[20],而t Copula只能度量对称的尾部风险相关性[21],标准的阿基米德多变量Copula[22,23]可以度量非对称的尾部相依性,但是只有一个模型参数,即需要限定所有两两变量间都存在同一类型的相依性,显然在复杂的多变量间这一假设不一定成立。因此,更灵活的方式是将联合概率密度分解为一系列只包含边缘分布和两变量Copula的模块,这种分解方式称为Pair Copula Construction(PCC)。
考虑一个由随机变量构成的向量X=(x1,…,xd),由链式法则,联合分布密度可分解为一系列条件分布密度之积,即
(5)
对每个j,都有[10,14]
(6)
(7)
其中vj∈v,v-j=vvj,cxvj,v-j()称为Pair Copula(下文简称PC)密度函数,Cxvj,v-j()为Pair Copula分布函数。
然而,PC构建的方式却不唯一,其中五维联合概率密度有480种不同的PC构建方式,六维情形将有23040种方式,随着维数的增加,构建方式的种类会迅速增加。如何在多种方式中选择有效的构建方式?Bedford和Cooke[11]提出了基于图论思想的正则藤(R-Vine)模式。该方法通过分层构建d-1棵树,每棵树的变量都以前一棵树的变量为条件,构成树的每一段变量间的相依关系都可用相应的Copula来刻画,因此Copula类型覆盖面广且参数值也可以不唯一。
例如:五维情形:
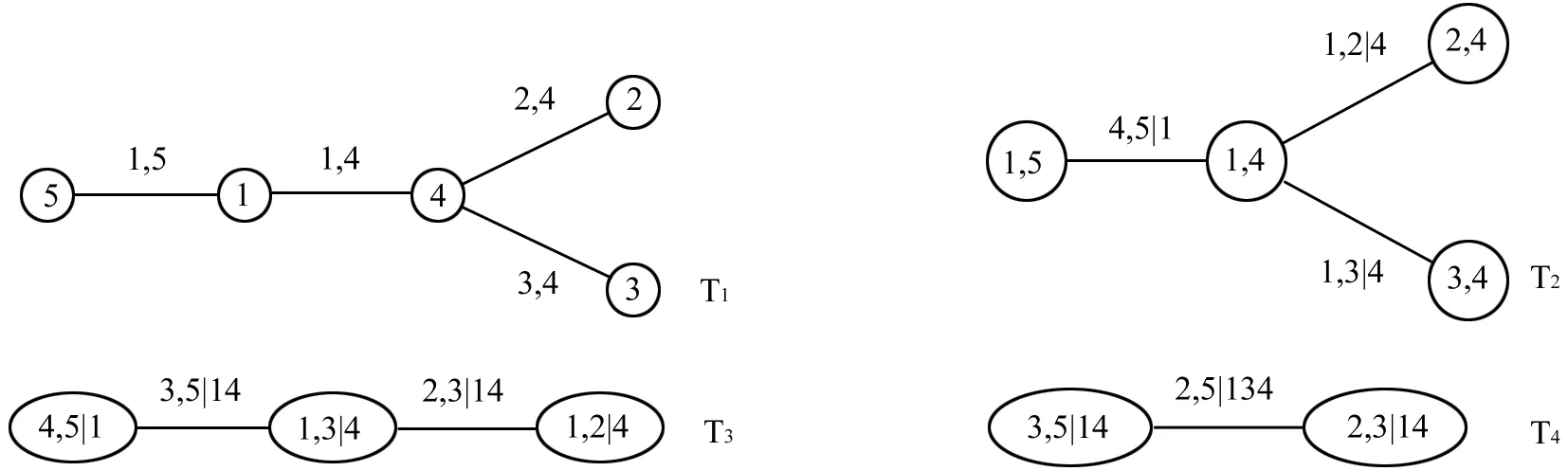
图1 五维正则藤树形结构图
f=f1·f2·f3·f4·c14·c15·c24·c34·c12,4·c13,4·c45,1·c23,14·c35,14·c25,134
(8)
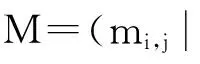

在正则藤中,最流行的也是普及最广的两类藤结构为Canonical Vines(C-藤)and和Drawable Vines(D-藤)。其中C-藤的每一棵树 都有唯一的节点与该树其他d-j点构成边,这种结构适用于系统中存在重要的核心变量的情形。而D-藤中没有节点与超过两个节点构成边,这种结构适用于系统中变量为平行结构的情形。
2.2正则藤Copula模型构建
2.2.1确定合适的PC类型
一个准确的多变量联合分布的构建以每一个不同形式的两变量PC类型的准确选择为前提。定性的选择可以根据变量间的相依关系特征,确定与之相应的Copula类别,如变量间没有尾部相依性、存在对称尾部相依、下尾相依、上尾相依等可分别选取Gaussian、t、Clyton、Gumbel Copula等。定量的选择常可利用AIC准则或Vuong检验选择合适的Copula类型,同时利用更高层树的独立变量的Copula来简化模型结构[24],或者利用贝叶斯方法:根据含有模型指标的MCMC从独立Copula和固定的Copula类型中选择。
2.2.2参数估计
关于参数估计,常采用顺序估计法[14]和极大似然估计法。由式(7)可知,第j棵树中Copula函数的自变量(即条件分布函数)是第j-1棵树的相应Copula的偏导。因此,可对每个Copula参数利用顺序估计法,将得到的参数作为初值,代入极大似然函数,利用迭代法求出极大似然估计值。
2.2.3选择正则藤树形结构
在变量个数d较小时,可以遍历所有的正则藤结构图形,结合观测数据选取似然值最大的正则藤结构,但当d较大时,这一做法是不现实的。鉴于此,J.DiBmann等[25]提到结构选择应以“具有最强相依性”为标准。

3实证研究
3.1样本与数据的选择
本文选取的样本行业来自将国民经济按照证监会行业分类标准划分的18个门类行业,依据相应行业上市公司的总市值,选取样本期内行业市值在全行业中占比始终处于前九位的行业(采矿业B、制造业C、电热水燃气业D、建筑业E、批发零售业F、交通运输仓储业G、信息软件业I 、金融业J、房地产业K),由于九行业总市值始终占全行业总市值的90%以上,因此对样本行业信用风险的分析可以代表整个国民经济的信用风险状况。样本期为2008/01~2014/09,共81个月。本文将在整个区间内利用改进的CCA模型和正则藤Copula模型分析国民经济中的九大行业信用风险的相依结构。本文所有数据均来源于锐思数据库。
3.2行业违约距离求解
利用改进的CCA模型求解每个行业的违约距离,模型中所有变量按以下方式确定:
T-t(到期时间):取为1年;
Et(行业股权市值):取行业所有上市公司月末市值之和;
Bt(行业违约障碍):根据该行业所有上市公司季度财务报表,取公司短期负债+0.5*长期负债的总和,并利用插值法将季度债务转换为月度债务;
r(无风险利率):取自中国人民银行发布的1年期定期存款基准利率,对于同一月份有不同利率的情形,取当月不同利率的平均值;
σEt(股权收益率波动率):利用LM法对行业股权市值对数收益率进行自相关效应检验和GARCH效应检验,对具有相应效应的收益率序列建立AR、GARCH或AR-GARCH模型,求出月度条件方差序列,并转化为年波动率。

表1 行业股权市值收益率的自相关和异方差检验结果
注:F1为滞后一阶自相关检验的LM统计量,F2为滞后2阶ARCH效应的LM统计量,*,**,***分别表示在10%、5%、1%水平下显著。
由表1可以看出,9个行业的收益率序列均不存在一阶自相关,但是除了金融行业以外,其他行业都至少在10%水平下接受存在ARCH效应,因此利用本文改进的CCA方法将比传统CCA方法更为恰当。
下面兼顾简洁和准确性,对除金融行业外的8个行业收益率序列建立GARCH(1,1)模型,得出月度条件异方差序列,并转化为年波动率σEit(i=1,…,7,9),对金融行业,计算无条件波动率σE8。
将上述数据代入改进的CCA模型,利用Matlab自编程序,计算出各行业的违约距离序列。结果如图2所示。
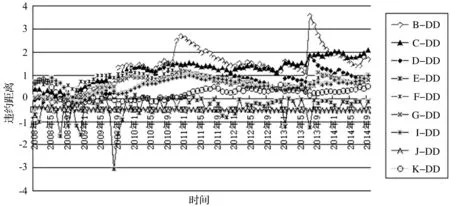
图2 行业违约距离
由图2可以看出,各行业的违约距离总体趋势大致相同,在金融危机期(2008/01~2009/08)较小,在后危机期(2009/09~2013/05)总体较为平稳,而在2013/06~2014/09期间违约距离普遍上升,说明经济缓慢回暖,与宏观经济发展趋势基本吻合。由于市场对自然资源的强大需求致使采矿业B的违约距离最大,违约风险相对最小,但在2010~2011年间及2013年后有较大的波动,波动主要归因于重大技术突破及新资源的发现,但就行业本身而言,由于资源税等抑制行业发展的因素及宏观经济不振的影响,采矿业发展处于颓势,信用风险逐渐加大。值得注意的是金融业和房地产业的违约距离一直处于低位,其中房地产业在危机初期由于房价增速过快,所以违约风险反而较小,直至2008年底才达到最大风险,之后在房地产非理性炒作和宏观调控政策的干预双重作用下,行业信用风险有所波动,但总体较为平稳地处于低位,这与房企融资主要来源于银行贷款有关。金融业在所有行业中信用风险最高,这一结果非常客观地反映了金融业的现实,也值得警惕。除了宏观经济因素以外,大量影子银行的存在也加剧了金融行业信用风险,由于过去国有银行违约损失都有政府的隐性担保,银行自身的危机意识不强。2014年8月,银监会推出允许银行破产条例,金融业的信用风险很可能演变为金融危机。由图2还可以看出建筑业信用风险与房地产业相辅相成,但波动更大。除此之外,其他五个行业的信用变化趋势均大体相同,其中,制造业的违约距离最大,信用风险最小。
3.3基于正则藤Copula结构的行业信用风险相依分析
关于违约距离序列的分布,可以利用参数或非参数方法进行分布拟合,鉴于参数法需要对序列分布类型有较准确的判断,而本文的违约距离序列分布没有明显特征,因此,本文采用非参数方法得到行业违约距离边缘分布函数序列。当边缘分布函数序列经过检验服从U(0,1)均匀分布时,则可将其应用于Copula路径选择。下表是对9个行业违约距离的经验分布函数序列ui(i=1,…,9)做K-S检验的结果。由表2显见,各行业违约距离的经验分布序列均服从均匀分布U(0,1)。

表2 K-S检验结果
注:ui(i=1,…,9)分别表示行业B、C、D、E、F、G、I、J、K的违约距离累计分布序列。
为了选择最合适的藤Copula模型,本文分别求出C-藤、D-藤、正则藤3种藤结构下模型评价指标,见表3。
由表3可见,正则藤的AIC和BIC值最小、极大似然值Loglik最大,故后文中将以正则藤模型为依据来分析行业间信用风险的相依结构。
表4列出了行业Kendall’τ相关系数矩阵,利用最大生成树MST-PRIM算法,根据行业间的最强相依关系,可以构建正则藤的第一棵树。

表3 3种藤结构模型评价指标

表4 行业间无条件Kendall’τ相关系数矩阵
由表4可以看出与采矿业、交通运输仓储业的秩相关系数较大的行业较多,说明这两个行业处于全行业中相对核心的地位,这主要是因为它们分别是在第一、三产业中处于基础地位的行业;金融业是一个特殊的行业,它与所有行业几乎均负相关或无关,尤其与制造业和采矿业的负相关性最大,说明我国最大的实体行业与最大的虚拟经济行业关系密切。事实上金融行业的主要资产恰恰是其他行业的负债,因此大多呈负相关;建筑业由于包含了除房屋建筑以外的其他建筑类别,因此表现为与其他行业的风险相关性均较弱,甚至与房地产业的相关性也较小;一直被大众关注的房地产行业与其他各行业的相关性却不大,其中与电热水燃气业和交通运输仓储业的相关性几乎为零。
通过最大生成树MST-PRIM算法,挑选Kendall’τ相关系数绝对值较大的行业对——1-3,3-6,1-2,1-6,2-3,5-6,2-8,2-6,3-5,1-7,1-8,7-9,4-6(其中1,2,…,9分别表示行业B、C、D、E、F、G、I、J、K),兼顾“初始节点要保证相关性最强的节点间连接成边”及“保证每个节点都至少有其中的一条边与之连接”原则,可确定正则藤的第一棵树形结构图,如图3:

图3 Tree1树形结构图
依据同样的原理,可选择正则藤的另外7棵树的结构,完整结构可通过如下的矩阵M表示:

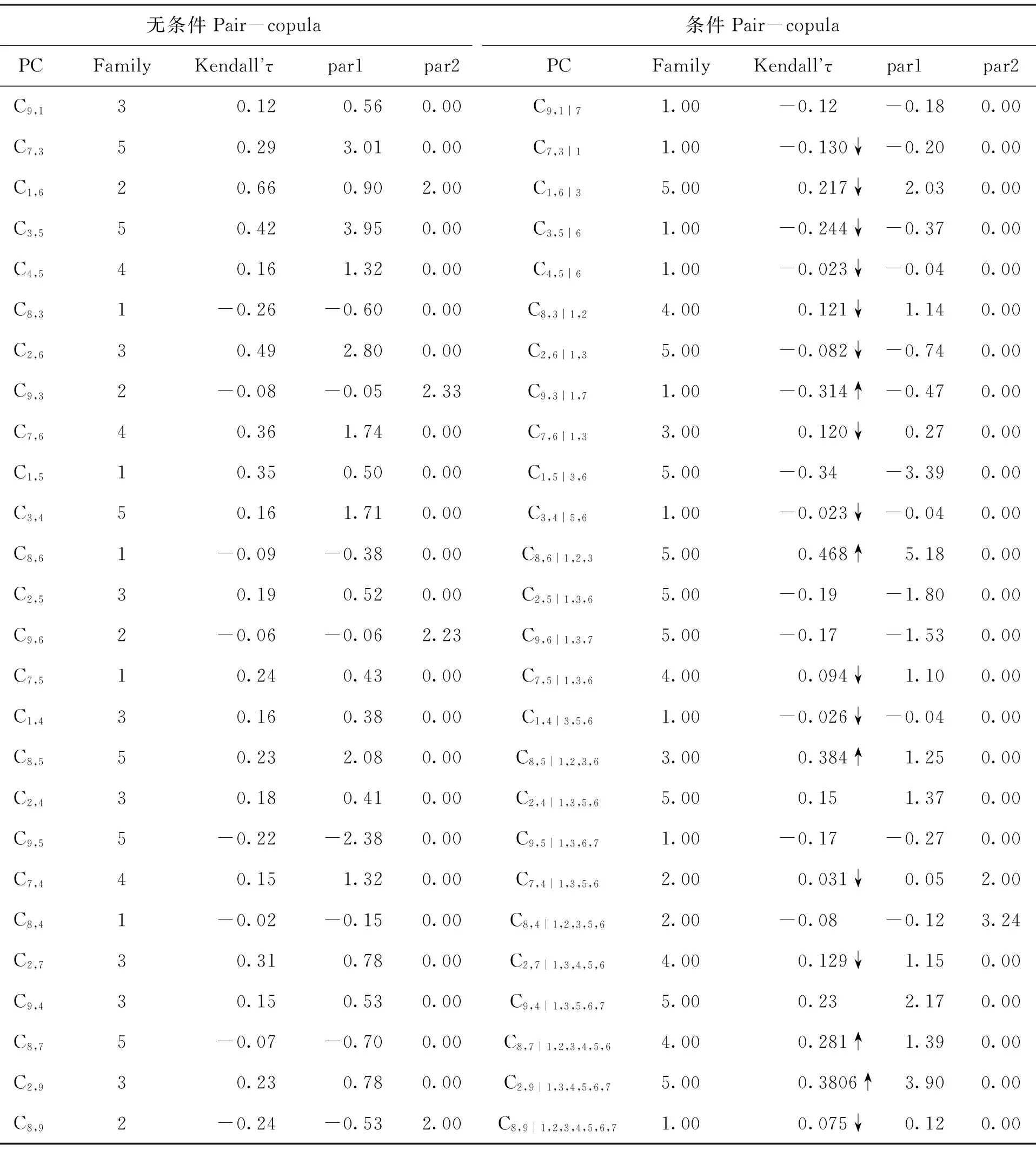
依据AIC最小原则,在常见的五类分别用来刻画变量间的不同相依特征的Copula类型族中(Gaussian,t,Clayton,Gumbel,Fank Copula),通过计算每个Pair Copula(PC)在相应Copula族中的AIC值(篇幅限制,暂不列出),最终选择了如下PC的类型见下表的Family列。利用极大似然估计法,得出Copula参数(见Par1,Par2列)。
为了便于比较,表5将条件Copula与相应的无条件Copula估计结果对比列出。
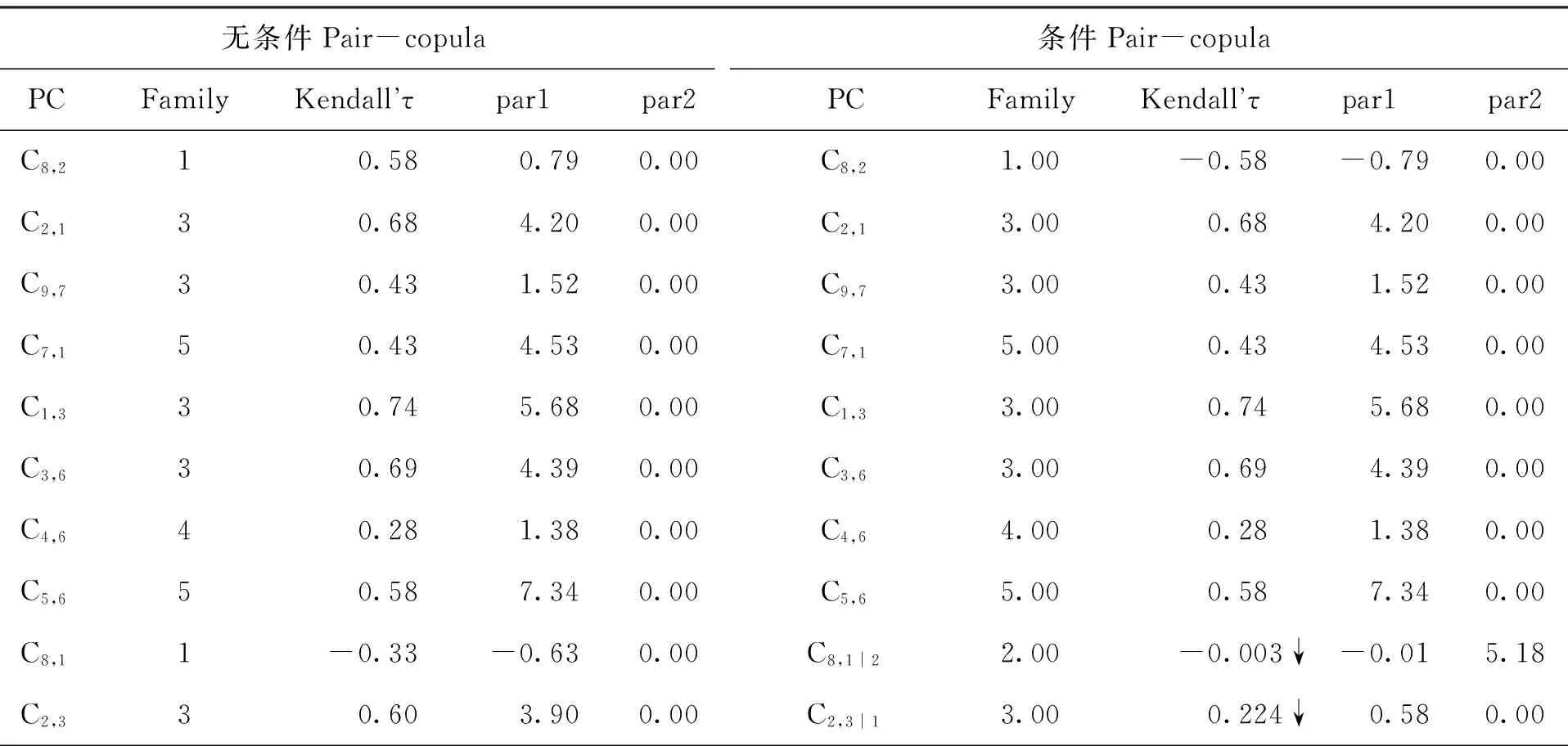
表5 正则藤Copula估计结果
续 表
注:1.Pair Copula列中的数字1,2,3,4,5,6,7,8分别表示采矿业B、制造业C、电热水燃气业D、建筑业E、批发零售业F、交通运输仓储业G、信息软件有I、金融业J、房地产业K;2.Family列中的数字1,2,3,4,5分别表示Gaussian,t,Clayton,Gumbel,Frank Copula模型;3.↓与↑分别表示条件Kendall’τ比无条件Kendall’τ偏大、偏小,为了说明问题,表中只标出τ值变化大于0.1的具有明显变化的条件PC。
首先,从表5显示的PC类型来看,初始节点间的PC类型主要表现为类型3,说明行业信用风险的下尾相关性较强,当一个行业发生信用危机时,另一行业发生危机的可能性也较大;不过建筑业与交通运输仓储业的相关类型却为4,说明行业信用风险具有上尾相关性。事实上,从第2列可见,无条件PC中,大部分表现为类型2,3,4,即具有尾部相关性,但纵观第7列发现,所有条件PC中,大部分均表现为类型1,5,即没有或只有很弱的尾部相关性,说明在条件行业信用风险已知时,一个行业的信用危机不太可能导致相关行业的信用危机。
另外,从Kendall’τ相关系数来看,主要表现出两方面的特征:
(1)存在条件隔离信用风险传染的行业。与无条件秩相关系数相比,原本几乎不相关或具有弱相关性的行业,在已知条件行业的信用风险条件下,Kendall’τ相关系数明显增加,这说明在某些行业信用风险已知的条件下,Pair行业(注:为便于说明,下面将Pair Copula所对应的行业称为Pair行业) 间的信用风险相关性加强,即条件行业成为Pair行业信用风险传染的催化剂。这种现象主要表现在房地产行业与制造业、建筑业、电热水燃气业的风险相关性以及金融业与批发零售业、交通运输仓储业、信息软件业间的条件相关性增加。说明条件行业的信用风险导致房地产行业与相关行业、金融行业与相关行业的风险传染,若要弱化Pair行业间的风险相依,应首先弱化条件行业信用风险带来的负面效应。比如作为虚拟经济代表的金融业及作为第三产业核心的交通运输仓储业,在已知最大的实体行业采矿业、制造业和电热水燃气业风险的条件下,风险相关性明显增加,可以理解为实体经济的信用危机会造成对宏观基本面的悲观预期,从而导致金融业与交通运输仓储业中任一行业的信用风险的变化都会对另一行业产生比无条件情形下更大的影响。
(2)存在催化信用风险传染的行业。与无条件秩相关系数相比,更多的行业间的条件相关性明显减弱甚至消失,即条件行业在目标行业间的信用风险传染中起到隔离作用,两行业间信用风险的传递以条件行业为媒介。具体表现为原本高度相关的制造业与电热水燃气业在已知采矿业的风险条件下、采矿业与交通运输仓储业在已知电热水燃气业条件下的信用风险相关性明显大幅减弱;而在已知制造业的信用风险条件下,金融行业和采矿业风险几乎无关;原本高度相关的制造业和交通运输仓储业在电热水燃气业、采矿业的风险已知条件下,将变得几乎无关;鉴于条件行业的这一风险隔离作用,若要降低目标行业间风险相依性,减小风险传染的可能,可以通过密切关注并控制条件行业的信用风险。比如,可以认为若要降低采矿业的风险给金融业带来的不确定性,应该充分了解制造业的信用风险等。
4结论及政策建议
本文利用修正CCA方法和构建多元联合分布的正则藤 Copula方法,以国民经济中的九大门类行业为样本,利用上市公司的财务数据和市场数据,测度了行业信用风险,发现了行业间信用风险的复杂相依关系。本文的主要结论及相关政策建议如下:
(1)各行业信用风险水平不一,其中虚拟经济中金融业和房地产业信用风险最高,实体经济中采矿业和制造业信用风险最低;建筑业信用风险也较高且波动较大,其他行业信用风险的趋势和水平均相近。监管部门需要防范信用风险水平较高的行业发生信用危机,尤其是银行和房地产业。政府要增强对房地产宏观调控的前瞻性和科学性,设计合理的房产税制度,抑制土地过度投机;银监会应加快建立诚信制度,促进金融稳定。同时促进建立多元化、规范化的金融二级市场,达到分散、化解信用风险的作用。
(2)行业间风险相关性会因对其他相关行业风险的了解而增加或减小,即条件行业的信用风险会加剧或隔离其他相关行业间的信用风险传染。因此,若要全面控制系统性信用风险,除了要控制本行业的风险外,还应关注风险信息通道的关键节点,对起到条件隔离风险传染的行业节点,应重点关注对条件行业风险的识别;对起到加剧传染作用的行业,应注意隔离信息通道,风险管控中要实行分类管理,做到既发挥协同效应,又满足风险隔离要求。
参考文献
[1]Gray D,Malone S.Macro Financial Risk Analysis[M].John Wiley & Sons,2008
[2]Olli Castrén,Michela Rancan.Macro-Networks:An Application to Euro Area Financial Accounts[J].Journal of Banking & Finance.2014,46:43~58
[3]李扬,张晓晶,常欣,等.中国主权资产负债表及其风险评估(下)[J].经济研究,2012,(7):4~21
[4]肖璞,刘轶,杨苏梅.相互关联性、风险溢出与系统重要性银行识别[J].金融研究,2012,(12):97~105
[5]巴曙松,居姗,朱元倩.我国银行业系统性违约风险研究——基于Systemic CCA方法的分析[J].金融研究,2013,(9):71~83
[6]宫晓琳,杨淑振.量化分析宏观金融风险的非线性演变速度与机制[J].金融研究,2013,(4):99~111
[7]吴恒煜,胡锡亮,吕江林,等.我国行业风险的决定因素及传递机制研究[J].当代经济科学,2014,36(5):70~80
[8]Sklar,A.Fonctions de Repartition an Dimensions et Leurs Marges[J].Publ.Inst.Statist.Univ.Paris,1959,(8):229~231
[9]Scott,D.W..Multivariate Density Estimation[M].NY:Wiley,1992
[10]Joe,H.Families of M-variate Distributions with Given Margins and m(m-1)/2 Bivariate Dependence Parameters[J].Institute of Mathematical Statistics,Hayward,1996,28:120~141
[11]Bedford,T.,Cooke,R.M..Probability Density Decomposition for Conditionally Dependent Random Variables Modeled by Vines[J].Annals of Mathematics and Artificial Intelligence,2001,32:245~268
[12]Bedford,T.,Cooke,R.M..Vines-a New Graphical Model for Dependent Random Variables[J].Annals of Statistics,2002,30(4):1031~1068
[13]Cooke,R.M.,Kurowicka,D.Wilson,K.Sampling.Conditionalizing,Counting,Merging,Searching Regular Vines[J].Journal of Multivariate Analysis,2015,138:4~18
[14]Aas,K.,Czado,C.,Frigessi,A.,Bakken,H.Pair-copula Constructions of Multiple Dependence[J].Insurance:Mathematics and Economics,2009,44(2):182~198
[15]Black S,Scholes M.The Pricing of Corporate Options and Liabilities[J].Journal of Political Economy,1973,81(3):637~654
[16]Merton R.On the Pricing of Corporate Debt:The Risk Structure of Interest Rates[J].Journal of Finance,1974,29(2):449~470
[17]Dale Gray,Marco Gross,Joan Paredes,and Matthias Sydow.Modeling Banking,Sovereign,and Macro Risk in a CCA Global VAR[J].International Monetary Fund,2013:1~60
[18]Saldías M.A Market-based Approach to Sector Risk Determinants and Transmission in the Euro Area[J].Journal of Banking and Finance,2013,37(11):4534~4555
[19]Saldías M.Systemic Risk Analysis Using Forward Looking Distance to Default Series[J].Journal of Financial Stability,2013,9(4):498~517
[20]Salmon,F.Recipe for Disaster:The Formula that Killed Wall Street[J].Peer Reviewed Journal,2012,9(1):16~20
[21]Joe,H.,Li,H.,Nikoloulopoulos,A.K..Tail Dependence Functions and Vine Copulas[J].Journal of Multivariate Analysis,2010,101(1):252~270
[22]Joe,H.Multivariate Models and Dependence Concepts[M].Chapman & Hall,London,1997
[23]Hofert,M.Efficiently Sampling Nested Archimedean Copulas[J].Computational Statistics & Data Analysis,2011,55(1):57~70
[24]Brechmann,Eike C.,Joe,Harry.Truncation of Vine Copulas Using Fit Indices[J].Journal of Multivariate Analysis,2015,138:19~33
[25]J.DiBmann,E.C.Brechmann,C.Czado,D.Kurowicka.Selecting and Estimating Regular Vine Copulae and Application to Financial Returns[J].Computational Statistics and Data Analysis,2013,59:52~69
(责任编辑:史琳)
Analysis of Systemic Credit Risk Contagion among Industries Based on R-Vine Copula Model
Shen Min1,2
(1.Nanjing Tech University,Nanjing 211816,China;2.Nanjing University of Aeronautics & Astronautics,Nanjing 211100,China)
〔Abstract〕Based on the related date of nine industries of the national economy,this paper improves the measure of credit risk industry—CCA method and constructs R-Vine Copula model to check the nonlinear dependent structure and credit risk contagion route of the industry’s credit risk.Empirical results show that:(1)The credit risk level of each industry is different,but it fits the actual economy well;(2)Any of the two industries with no conditional credit risk are mostly of lower tail dependence,but the conditional tail dependence of credit risk is overall weak;(3)Knowledge of the degree of inter industry credit risk will change as a result of the credit risk in other industries.There exists“risk catalyst industry”that can aggravate credit risk contagion and“conditional isolation industry”that can slow down credit risk contagion in industry system.Finally,according to the credit risk contagion mechanism,this paper puts forward the measures to effectively control systemic financial risk and prevent systemic financial crisis.
〔Key words〕CCA;credit risk;R-vine copula
收稿日期:2016—02—25
基金项目:国家自然科学基金项目(项目编号:71401074)、江苏省哲学社会科学基金重点项目(项目编号:14GLA003)、江苏省高校研究生科研创新计划项目(项目编号:KYZZ0099)。
作者简介:申敏,南京工业大学数理科学学院讲师,南京航空航天大学经济管理学院博士研究生。研究方向:金融风险管理。
DOI:10.3969/j.issn.1004-910X.2016.06.007
〔中图分类号〕F224.7
〔文献标识码〕A
猜你喜欢
怀化学院学报(2021年5期)2021-12-01
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
音乐教育与创作(2020年1期)2020-05-13
音乐天地(音乐创作版)(2020年2期)2020-04-18
数学年刊A辑(中文版)(2019年1期)2019-01-31
辽宁经济(2017年6期)2017-07-12
特别文摘(2016年18期)2016-09-26
特别文摘(2016年15期)2016-08-15
当代经济(2016年26期)2016-06-15
