
三维模型时空子空间引导的智能视频侦查系统
2016-05-21 15:50卢涤非斯进王秋
计算机时代 2016年5期
关键词:大数据
卢涤非+++斯进+++王秋
摘 要: 为了克服传统视频处理技术面临的“语义鸿沟”等难题,借助三维模型时空子空间所蕴含的信息进行视频处理分析,提出了三维模型时空子空间引导的智能视频侦查技术。①在体形子空间的引导下从视频中匹配三维目标模型。②三维模型时空子空间引导下提取视频事件:监控对象视频+三维模型时空子空间→监控对象三维动作。③三维事件库中的动作比对分类:运动数据+三维事件库→视频类型和性质。文章涉及图形学、视频处理和刑事技术,探索了使用三维图形学技术解决视频侦查难题的新渠道。
关键词: 智能视频侦查; 三维模型时空子空间; 运动比对; 快速研判; 三维事件库; 大数据
中图分类号:TP391.41 文献标志码:A 文章编号:1006-8228(2016)05-16-05
Abstract: In order to overcome the problem of the "semantic gap" faced by the traditional video processing technology, this paper proposes a three-dimensional model of spatio-temporal subspace guided smart video detecting technology. Its core idea is that the video data is processed and analyzed with the information contained in the 3D model of spatio-temporal subspace. This paper include: 1, matching 3D target model with the video under the guidance of the shape subspace; 2, 3D model of spatio-temporal subspace guided extraction of video events: monitor object video + spatio-temporal subspace of 3D model → 3D monitored object movement; 3, Comparison of movements in 3D event Library: Sports data + 3D event library → video type and nature. This paper is related to graphics, video processing and criminal technology. It establishes new channels for the use of 3D graphics technology to solve the problem of video detection and has an important academic significance.
Key words: smart video based crime detecting; 3D model spatio-temporal sub-space; motion matching; rapid judge; 3D events database; big data
0 引言
随着大量视频探头的广泛使用,以视频内容为突破口的视频侦查逐渐成为公安机关侦破案件的重要方法。然而,传统视频侦查的成果多是在花费大量警力和时间的基础上获得的。于是,具备对海量视频有快速研判方法的智能视频侦查成了解决该问题的关键。
1 相关研究
智能视频侦查是指借助计算机视觉和视频分析的方法对视频数据进行分析,完成监控目标的定位、识别和跟踪,并判断目标对象的行为,辅助公安机关对疑难案件的侦破面对日益复杂的治安形势,智能视频侦查正逐渐成为“公安技术”学科中继刑事技术、行动技术和网侦技术之后的第四大警务技术支柱。智能视频在技术层面上都包含视频分析和视频理解这两个重要环节,其中视频分析技术主要包括背景减除检测、基于区域的跟踪以及时间差分检测等[1]。
由于二维视频图像丢失了现实场景的深度、方向等信息,这些方法都限制了特定的场景构成、相机配置、动作形式和视点角度等前提条件。在实际刑事案件中,这些前提条件基本上无法保证,导致大多数方法无法有效的处理目标对象被遮挡、短时间内消失,以及多个目标相互交错等复杂情形,因而这些无法直接应用于刑事案件中。
虽然视频分析仍是大多数研究者关注的方向,但人们已注意到视频理解才是智能视频侦查的最终目标,是智能视频侦查的核心。视频理解的关键是视频事件语义描述。视频语义内容分析是抽取用户所关心的语义内容,这会出现计算机自动理解与用户需求之间的矛盾,即语义鸿沟(the Semantic Gap)[2]。
传统视频处理技术中存在的这些难题根源在于,视频图像中特征属性和结构化信息的缺失。显然,如果能借助一些先验知识,在三维空间里对视频数据进行分析处理,这些问题就可以迎刃而解。但是依靠现有技术从视频序列中恢复目标对象的三维运动信息和三维结构是非常困难的。究其原因,主要是由于问题本身的困难性所致:包含在视频中的目标对象运动信息是不充分的,不足以用来重构三维动画,这是典型的欠约束问题。
针对于此,在前期工作的基础上[3~8],本文提出了在三维时空子空间中分析处理视频数据的新思路。利用三维时空子空间蕴含的先验知识引导整个处理过程,克服了传统人体运动识别技术需要限定前提条件和行为描述困难的不足。研究的关键问题有:①在体形子空间的引导下在视频中匹配三维目标模型;②在运动子空间引导下进行视频事件跟踪;③在三维事件库中进行动作比对分类。
2 系统目标与框架
2.1 目标
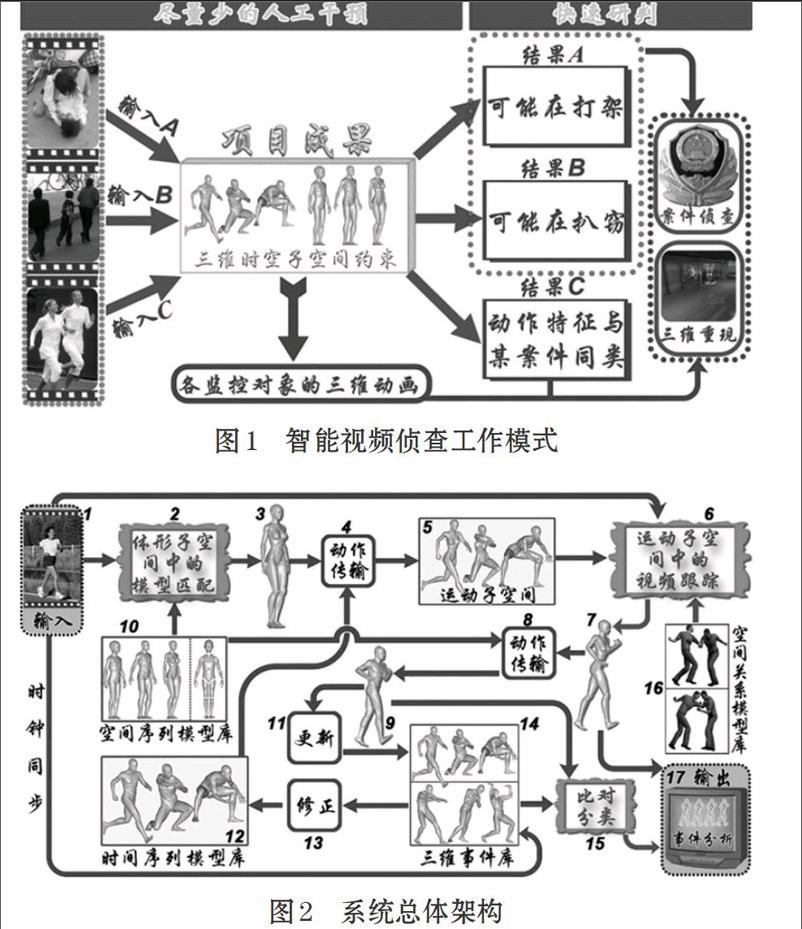
本系统在尽量少的人工干预下,通过三维模型时空子空间的引导,探索目标体型匹配、视频事件提取以及动作比对分类技术,开拓使用三维图形学的理论和方法处理视频侦查难题的新渠道,完成智能视频侦查的快速研判,图1显示了智能视频侦查的基本工作模式。
2.2 框架
人体的运动是符合一定规律的,反向运动学IK(Inverse Kinematics)[9]是描述人体运动规律的一个比较合适的方法。传统的IK一个比较大问题是定义关节结构不是一件容易的事情,其整个过程也不直观,要花大量的时间用于参数的设置工作。针对这种情况,文献[10]提出了基于网格的反向运动学(Mesh-Based Inverse Kinematics)。与基于骨骼体系的传统IK相比,该方法依赖已有的样例网格来隐含地确定各种约束条件。本文直接使用空间序列模型库、时间序列模型库和空间关系模型库来指导人体运动跟踪,通过对仿射变换矩阵的比对来匹配特定的人体运动,图2显示了本系统的总体架构。
2.2.1 体形子空间中的模型匹配
选择模型匹配模块主要作用是,对应于复杂视频场景选择最为合适的三维人体模型来跟踪视频,以有效地解决遮挡和多目标交错等问题。研究的关键点有:①人体局部插值算法的建立;②建立从二维图像生成三维人体模型的数学模型。
2.2.2 运动子空间中的人体运动视频跟踪
本系统的一个重点就是如何在空间关系模型库的支撑下完成运动子空间中的人体运动视频跟踪。人体运动是遵循运动学规律的,采用运动子空间来描述其反向运动学信息,然后把运动子空间作为运动捕捉的约束条件,以应对复杂的视频场景。研究的关键点为:①运动子空间的约束方程的建立;②动作库模型投影与视频序列匹配的约束方程的建立;③空间关系模型库的约束方程的建立。
2.2.3 三维事件库中的动作比对分类
人体运动比对分类是本文的另一个研究重点,其功能就是输入一套人体运动数据,然后在三维事件库中进行动作比对分类,用来确定最相似的动作,以确定目标特点或分析事件性质。
3 关键算法
3.1 体形子空间中的模型匹配
在跟踪视频人体运动时,首先根据空间序列模型库合成与被跟踪对象体形最为接近的三维人体模型。文献[11]对人体模型进行了比较全面的研究,提出了在指定人体模型间线性插值的方法产生新的模型。本文拓展了文献[11]的算法,其基本方案为:模型Mi可以表示为标准人体模型通过仿射变换获得的结果,把仿射矩阵极分解(Polar Decomposition),对非旋转部分可以直接采用线性插值,而对旋转部分需要先对旋转矩阵求对数,然后对矩阵对数(Matrix Logarithm)线性插值,最后通过矩阵指数(Matrix Exponential)把叠加后的值映射回原来的坐标空间。通过这种方法可以在体形子空间上构造一个函数,M是空间序列模型库中的模型集合{M1,…,Mn},ξ是参数向量{ξ1,…,ξn},ξi与Mi一一对应。
为了确定参数ξ,需要对确定的模型与视频图像进行匹配。本文使用自底向上法(bottom-up)进行匹配。匹配之前需对空间序列模型库中的模型按主要关节进行分解,采用SNAKE算法或人工分解,分解过程只需进行一次就可以反复使用。三维模型与图像的匹配问题一直是计算机视觉领域一个富有挑战性的话题,可以把此问题归结为一个高维空间中的带约束的数值优化问题。本文通过轮廓匹配(图3a)与边界匹配(图3b)来完成三维模型选择。匹配计算时,各三维模型子块只做刚体运动。
为了提高算法可靠性,需要在开始的多帧视频图像中进行模型匹配,为此设计了公式(1)表示的数学模型,其中有三个约束项,通过求取三个约束项线性组合的最优参数合成最匹配的三维人体数学模型。
⑴
其中P为投影矩阵;parti为获取人体模型第i部分的函数;T为仿射变换矩阵,不同部分的人体模型对应不同的Ti;j表示第j帧视频图像;SVideo是视频图像轮廓;E是求取三维模型透影边界的函数,Evideo是视频图像边界;V是三维人体模型顶点;C1是轮廓约束的简化表达式;C2是边界约束的简化表达式;C3保证各人体模型子块刚体运动。k1、k2和k3是权重系数,可以调整各约束条件所起的作用。求取ξ*后,就是所需要的结果。
3.2 运动子空间中的人体运动视频跟踪
对于有瑕疵的视频图像,可以先进行图像变形矫正、运动模糊去除和去雾处理。在跟踪过程中有三组约束,第一组约束就是运动子空间的约束,结合前期工作,提出如下数学模型:
其中ROI(k)表示第k个感兴趣区域(ROI);R为三维人体模型中ROI的数量;V与为变形前后的顶点坐标,变形后的人体模型是的函数,记为;N(i)是顶点Vi相邻顶点的集合;Gi是对应于顶点Vi的仿射变换矩阵,它的合成需要先把仿射矩阵的旋转部分从全旋转群SO(3)映射到Lie代数空间so(3)上,在so(3)上进行线性叠加,然后映射回SO(3)空间,对非旋转部分,直接进行线性叠加,最后两者相乘:
其中L(l1,…,lt)是运动子空间中的系数向量;Q是指仿射矩阵的旋转部分,U是指非旋转部分,Exp和Log分别是矩阵指数和对数函数。
第二组约束是动作库模型投影与视频序列匹配的约束。具体跟踪以跟踪片断(Tracklet) (图4a)为单位,每个Tracklet包含n帧,n的值需要在研究中确定。在进行下一步处理前,使用三维智能剪刀获得一个时空体(Space Time Volume,图4c),三维智能剪刀是在文献[8]基础上拓展出来的。除了采用轮廓匹配和边界匹配外,还采用3D SIFT(Scale Invariant Feature Transform)特征匹配。轮廓匹配和边界匹配概念的表达式不同,即式(4)的C5和C6。3D SIFT匹配首先需要在视频图像上计算出所有3D SIFT特征,如图4b的d就是一个3D SIFT;然后要把d和三维人体模型顶点进行匹配。具体过程如下:对第j帧的d,找出离其最近的第j-1帧三维人体模型投影点u,而u是由三维顶点V投影产生,这样就把d和V关联起来。这样,对第j帧上的所有3D SIFT特征都可以找出对应的三维顶点,可以写出3D SIFT匹配的表达式C7。为保持跟踪结果的连续性,还要使用C8约束。
第三组约束利用多目标间的空间关系来解决相互遮挡问题。如果其中一个角色被另外一个遮挡,可以把这种多目标间的空间联系作为约束条件来辅助视频跟踪。多目标空间关系的约束可以用下式表示:
其中Mi是对应于顶点Vi的仿射变换矩阵。其余符号与C4类似。联立C4~ C9,可以得到公式(2),其中k1~k6为权重系数。
⑵
3.3 三维事件库中的动作比对分类
三维事件库中的人体运动是使用标准三维人体存储的,而用于匹配的人体运动也是用标准三维人体模型表示的。经过前期探索,提出了基于三维时空子空间的人体运动比对分类方案:
记待检索人体运动为,其中Fj表示第j帧三维模型,共L帧,是对应各帧的时钟数据;类似的,可以用和表述三维事件库中的第i套人体运动,共p(i)帧。对于Fj,第k个顶点相对于初始位置的仿射变换矩阵记为;同样,对于,对应其第i套动作的仿射变换矩阵可以标记为的形式。
Fl在中匹配的数学模型为:
其中λ是对应于的系数;n为标准三维人体模型的顶点数;k1和k2为权重系数,用于调整子项的权重。计算出λ*后,需要找出其中的最大值:,然后设立阈值α>0,如 则表示匹配,形成匹配对。
4 实验结果与分析
本文使用Visual C++实现了系统初步框架。在体型库中,以浙江警察学院普通学生为蓝本,建立男和女两个模型,在动作库中,建立了走、跑、跳、蹲几个动作。在此基础上,针对简单背景的20段视频进行了测试,识别率为80%,在Intel i5 CPU和4G内存的普通PC机上平均耗时100秒钟。初步实验表明,本文提出系统是可行的。
5 结束语
本文是涉及图形学、视频处理技术和刑事技术的交叉性课题,不仅在学术上有诸多闪光点,而且为智能视频侦查在刑事侦查和治安管理等方面的应用打下了良好的理论基础。主要创新与特色之处有以下。
5.1 从方法层面看
通过三维时空子空间,把三维图形学的理论和方法引入到了视频处理中,为处理视频侦查难题提供了新的渠道,可以有效地克服视频数据结构性差和缺乏特征信息等弱点,促进了智能视频侦查技术的发展和完善。
5.2 从技术层面看
提出了基于体形子空间的二维监控目标与三维模型匹配的三维重建算法。在三维人体模型局部参数化以后,可以根据二维体形生成最为匹配的三维模型。
结合3D SIFT图像特征和三维运动子空间以及空间关系模型库中的引导信息,提出了新的运动跟踪算法,对动作进行预测,并处理遮挡问题,可以应对复杂场景的运动跟踪。
参考文献(References):
[1] WITOLD C, Real-Time Image Segmentation for Visual Serving[J]. Lecture Notes in Computer Science,2007.4432:633-640
[2] MARC DAVIS, CHITRA DORAI, FRANK NACK, Understanding Media Semantics[C].The 11th Tutorial Program of the 11th ACM International Conference on Multimedia. Berkeley, CA,USA,Nov 2003.
[3] LIU F, ZHUANG Y, WU E, et al. 3D motion retrieval withmotion Index tree[J]. Computer Vision and Image Understanding,2003.92(2-3):265-284
[4] 卢涤非,任文华,李国军等.基于样例的交互式三维动画的生成[J].计算机研究与发展,2010.47(1):62-71
[5] DIFEI LU, XIUZI YE, GUOMIN ZHOU, Animating byexample[J]. Journal of Visualization and Computer Animation,2007.18(4-5):247-257
[6] DIFEI LU, YING ZHANG, XIUZI YE. A New Method ofInteractive Marker-Driven Free form Mesh Deformation[C]. GMAI 2006:127-134
[7] DIFEI LU, XIUZI YE, Sketch Based 3D Animation Copy[C].ICAT 2006:474-485
[8] LU DIFEI,WU YIN, HARRIS GORDON et al. Iterativemesh transformation for 3D segmentation of livers with cancers in CT images, Computerized medical imaging and graphics,2015.43:1-14
[9] GROCHOW K, MARTIN SL, HERTZMANN A, et al.Style-based inverse kinematics[J]. ACM Trans. Graph,2004.23(3):522-531
[10] SUMMER RW, ZWICKER M, GOTSMAN C, et al.Mesh-based inverse kinematics[J]. ACM Trans. Graph,2005.24(3):488-495
[11] ALLEN B, The space of human body shapes:reconstruction and parameterization from range scans[C]. SIGGRAPH '2003. ACM, New York, NY, 587-594
[12] BAI X,. Video SnapCut: robust video object cutout usinglocalized classifiers[C]. In ACM SIGGRAPH 2009 Papers. H. Hoppe, Ed. SIGGRAPH '09. ACM, NY, 1-11
[13] http://www.cise.ufl.edu/research/sparse/umfpack/[OL].
猜你喜欢
中国市场(2016年36期)2016-10-19
中国市场(2016年36期)2016-10-19
中国市场(2016年35期)2016-10-19
商(2016年27期)2016-10-17
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
