
基于文档向量和回归模型的评分预测框架
2016-05-21 15:54穆云磊周春晖俞东进
计算机时代 2016年5期
穆云磊+++周春晖+++俞东进

摘 要: 个性化推荐系统可以帮助用户在海量的项目集合中找到他们喜爱的项目,其被广泛地应用于岗位推荐系统、电子商务网站以及社交网络平台中。文章提出了一个基于文档向量和回归模型的评分预测框架,它利用文档向量表示模型将非结构化的评论文本用相同维度的向量表示,进而构造出刻画用户和产品的特征向量,最终融合多个回归模型进行评分预测。在基于真实的数据集上的实验表明,与基准模型相比,其显著改善了数据稀疏情况下评分预测的准确性。
关键词: 推荐系统; 数据稀疏; 评论文本; 文档向量; 回归模型; 评分预测
中图分类号:TP391 文献标志码:A 文章编号:1006-8228(2016)05-24-06
Abstract: Recommender systems typically produce a list of recommendations to precisely predict the user's preference for the items. It is widely used in post recommendation systems, e-commerce websites and social network platforms. This paper proposes a rating prediction framework based on distributed representation of document and regression model. The framework takes advantage of distributed representation of document to map the unstructured review texts into the same vector space, and furthermore constructs the feature vector of users and items. The framework trains several regression models to predict ratings. The extensive experiments on real-world datasets demonstrate that it performs better than the benchmark and alleviates the cold-start problem to some extent.
Key words: recommender system; data sparsity; review text; distributed representation of document; rating prediction
0 引言
个性化推荐系统帮助用户在网络上发现各类产品,并做出决策。越来越多的网站,如Last.fm、Amazon、Taobao、YouTube、Yahoo等,开发了推荐系统并将其提供给它们的用户。这些推荐系统可以帮助用户从海量的产品集合中找到他们喜爱的歌曲、视频、书籍以及各种商品[1]。近年来,协同过滤(Collaborative Filtering)技术在个性化推荐系统中取得了巨大的成功。其主要包括两类方法[2]:基于邻域的方法(Neighborhood-based)和基于模型的方法(Model-
based)。然而,冷启动问题[3]一直影响着协同过滤方法应用的效果。这里冷启动问题是指:当一个新用户或新产品加入系统时,用于刻画他们特征的信息非常稀少,导致为新用户推荐产品或将新产品推荐给用户变得非常困难。
值得注意的是,用户在给产品评分的同时还可能写下一段评论。传统的协同过滤方法仅仅将评分作为数据源,而忽略了蕴含在评论中丰富的信息。事实上,我们可以利用这些蕴含在评论中的信息来缓解传统方法中存在的冷启动问题。特别是,在评论中用户不仅会讨论这个产品的不同方面,还蕴含着他们对这些方面的情感。例如,当用户评论笔记本电脑时,他会对某款笔记本电脑的“外形”和“性能”等方面表达正面的情感,而对它的“续航”和“散热”等方面表达负面的情感。
本文基于文档向量和回归模型,提出一个高效的评分预测框架。该框架利用文档向量表示模型,构造出比协同过滤更加精确的用户和产品特征空间,并将多个回归模型融合以生成有效的评分预测器。在数据稀疏的情况下,框架产生的评分预测器的效果显著高于传统的协同过滤方法。
1 方法概述
本文主要解决的问题是如何在用户评分数据稀疏时利用评论文本提高评分预测的准确度。区别于传统方法中以评分作为单一数据源,本文同时使用评分和评论作为数据源,利用评论中的丰富信息缓解传统协同过滤推荐方法中存在的冷启动的问题。图1展示了一个评分与评论数据的例子,它来自电子商务网站Amazon.com。在这个例子中,用户给产品打了四颗星(评分)的同时,写了一段评论。我们的主要任务是利用用户评分与评论的历史数据,构造刻画用户和产品的特征,预测用户对未产生过行为的产品的评分。
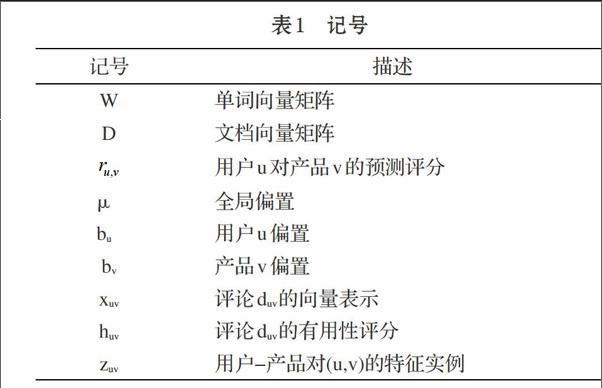
我们可将用户集合表示为,产品集合表示为。表示可见评分集合,表示评论集合,评分和评论的全集记为。本文涉及的相关记号见表1。
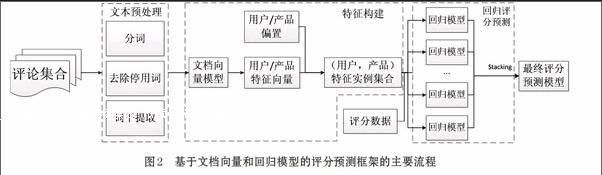
基于文档向量和回归模型的评分预测框架的主要流程表述如下。首先,对原始的评论文本进行预处理,预处理过程主要包括分词、去除停用词和词干提取,然后,通过文档向量表示模型(doc2vec)[4]构建刻画用户与产品的特征向量,接着,利用这些向量和用户和产品的偏置构造用户-产品对特征实例集合,最后,以评分作为标签,构建多个回归模型并融合为最终的评分预测模型。图2展示了基于文档向量和回归模型评分预测框架的主要流程。
该评分预测框架的特点为:①使用无监督的文档向量模型将每个评论转化到相同维度的向量空间中,并以此为基础构造分别刻画用户和产品的向量;②在①的基础上组合用户-产品对的特征实例并构造数据集;③将评分预测转化为机器学习中的回归问题,利用回归模型提高评分预测精度。
2 文档向量表示模型
文档向量表示模型[4]能够为一个变长的输入序列构造表示结构,其中变长的输入序列可以是任意长度的文本:句子、段落或者文档。它的优点是无需面对不同的任务调节单词的权重也无需依赖句法分析树。
文档向量的学习方法受到词向量[5]学习方法的启发。在词向量学习方法中,词向量被用来帮助预测句子中的下一个单词,因此,尽管词向量被随机初始化,它们作为预测任务的间接结果,仍然能够捕捉语义信息。在文档向量模型中使用相似的想法,文档向量也被用来做预测任务,这里的预测任务是预测给定多个从文档中采样的上下文的下个单词。
图3为文档向量学习框架。每个文档被映射为一个惟一的向量,由矩阵D中的列表示,同时每个单词也映射为一个惟一的向量,由矩阵W的列表示。文档向量和词向量被平均或连结以预测上下文中的下个单词。
与词向量学习方法相比,文档向量学习框架增加了文档标记,用于将每个文档向量映射到文档矩阵D中。这里,文档标记可以被认为是另一个单词,它的作用是记忆现有上下文缺失的部分,或者是文档的主题。
在文档向量模型中,上下文是从文档中通过滑动窗口采样的固定长度文本。对于从同一个文档中采样的上下文,它们共享同一个文档向量。而单词向量矩阵W则是通用的。即,对于所有的文档,表示“good”的向量是一样的。
文档向量和词向量使用随机梯度下降法(SGD)学习得到,其中梯度由反向传播算法得到。在每一步梯度下降中,可以从随机的一个文档中采样一段固定长度的上下文,然后根据图3中的网络计算误差梯度以及使用梯度更新模型的参数。
在预测阶段,对于一个新的文档,我们需要执行一个推断的步骤来计算其向量。这个步骤仍然是通过梯度下降实现。在此步骤中,模型的其余参数包括词向量矩阵W和Softmax权重等,都是固定的。
在模型训练之后,文档向量可以被用作描述文档特征。在本文的评分预测框架中,文档向量被用来将每一个评论映射到相同维度的向量空间中,并进一步地用于刻画用户和产品特征向量的构造。
3 特征实例
⑴ 用户和产品特征向量构造
通过将每个评论看作一个文档,并赋予其标记,使用文档向量表示模型,我们将每个评论都映射到相同维度的向量空间中。形式化地,对于评论duv,其对应的评论向量记为xuv,这里,。
对于用户u,我们使用其所有评论的向量平均作为其特征向量:
⑴
其中,表示用户u的评论集合。
值得注意的是,每一个评论都有一个有用性评分,直观上,有用性越高的评论,对产品的描述更加准确。有用性评分的形式一般为“有用/无用”,前者表示“认同”当前评论的用户数量,后者表示“不认同”当前评论的用户数量,为了将此形式的有用性评分转化到实数上来,定义:
⑵
其中,puv和nuv分别为对评论duv的“认同”用户数和“不认同用”户数,a和b分别为控制转换的参数。因此,对于产品v的特征向量,可以使用有用性评分对产品的所有评论向量加权平均得到:
⑶
⑵ 用户和产品偏置
除了使用评分向量构造的用户和产品特征之外,我们还使用用户和产品的偏置作为特征。
直观上,不同的用户和不同的产品评分尺度都有所不同。例如,某用户是评分严格的用户,那么他的评分一般会低于全局平均分,而某个产品质量优于其他产品,那么它的评分则会高于平均评分。对于用户u,其偏置可以定义为其评分与全局平均差的均值:
⑷
同理,对于产品v,其偏置可以定义为:
⑸
最终,使用连接的方式构造特征实例,即对于用户-产品对(u,v),其特征实例为[xu,bu,xv,bv]。
4 回归模型
回归模型是一类监督学习模型,每个输入实例通常由特征向量表示,记为x={x(1),x(2),…,x(i),…,x(n)},x(i)表示第i个特征。对于训练集的输入实例X和输出向量y,回归模型通过拟合它们得到一个拟合函数f使得f(X)=y,使用此函数可以预测未知的实例集合(测试集)的输出,即对于测试实例,求得。
本文主要使用三个流行的回归模型进行评分预测,分别是k近邻回归模型、随机森林回归模型和梯度提升回归树模型。
⑴ k近邻
k近邻算法[6],简称k-NN,是一种非参数学习算法。在k近邻回归中,输入为包含特征空间中的k个最近训练实例,输出为对象的属性值,通过计算其k近邻值的均值求得。k-NN是一种基于实例的学习算法,也被称为惰性学习,其决策函数仅仅为局部近似,而且只有在需要回归时才进行计算。
⑵ 随机森林
随机森林回归器[7]是集成学习中最重要的算法之一,它是一个包含多个树结构的回归器的集合,其中是相互独立分布的随机参数向量,回归的结果通过平均所有树的结果得到。
在随机森林中,每一个子树都是一个分类与回归树(CART)[8]。CART是一种应用广泛的决策树学习方法,对于训练数据集X,Y,其通过递归将输入空间的每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉树。
⑶ 梯度提升回归树
梯度提升回归树(GBRT)[9],又被称为多重累加回归树(MART)或树网(Tree-Net),是一种高效的提升(Boosting)学习方法。在一般的提升树模型中,损失函数通常采用平方误差损失,每一步只需拟合当前数据的残差,但对于一般的损失函数,如对数损失,其优化变得非常困难。GBRT通过计算损失函数的负梯度近似残差,以此拟合新的回归树。
5 评分预测框架构建
我们在此探讨所提出的基于文档向量和回归模型的评分预测框的构建过程。首先介绍框架的冷启动评分预测器,然后介绍评分预测框架构建算法。
5.1 冷启动预测器
当一个新用户或者新产品加入系统时,常用的方法是使用全局平均分来预测新用户或新产品的评分,我们在全局平均分的基础上,加上用户和产品的偏置来预测冷启动情况下的评分,具体预测方法为:
⑹
其中,bu和bv为用户u和产品v的偏置,分别由式⑷和式⑸求得。
5.2 评分预测框架构建算法
[算法1 基于文档向量和回归模型的评分预测框架构建算法\&输入:评分和评论集合,
输出:评分预测函数f(u,v)\&1. 使用文档向量模型训练评论语料库,得到每个评论的向量表示。
2. 使用式⑴、⑶、⑷和⑸计算用户和产品的特征向量xu,xv和偏置bu,bv,对于输入的所有用户-产品对(u,v)∈Γ,连结得到训练实例集合。
3. 使用2中的训练实例集合分别训练多个回归模型:f1,…,fs。
4. 使用Stacking技术将3中多个模型的结果融合得到最终的评分预测模型:
其中α1,…,αs为每个模型的权重,。\&]
在该基于文档向量和回归模型的评分预测框架中,首先利用文档向量模型得到评论向量,并用评论向量构建训练特征实例,然后利用训练特征实例训练一个评分回归模型,最后使用融合方法得到最终的评分预测模型。
算法1展示了该评分预测框架构建的详细步骤。第一步使用文档向量模型得到训练评论的向量表示。第二步将向量连结成特征实例。第三步训练多个回归模型。第四步使用Stacking技术将多个回归模型相融合。Stacking技术使用多个模型的输出作为输入,并使用交叉验证的方法获得最优的融合模型,其常用的融合方法是线性组合。
6 实验结果与分析
本文使用的数据集是McAuley等[10]收集的著名电商网站Amazon 的评分和评论数据集。数据集按照产品的类别被分为25个类别子数据集,数据集一共包含486万多用户,78万多产品,822万多条评分和评论。为了对比基于文档向量和回归模型的评分预测框架中单个回归模型,以及融合模型的评分预测的表现,本文将文档向量模型中的向量大小固定为100,并输出所有数据集的MSE值。
所有子数据集上评分预测的MSE结果见表2。每个子数据集上最优的MSE结果已加粗显示,括号中为标准差。从MSE结果表中可以看出,在所有的25个子数据集上,基于文档向量和回归模型的评分预测框架的评分预测精度优于全局平均预测器和标准的潜在因子模型。
相比于全局平均预测器(Offset)和标准潜在因子模型(LFM),基于文档向量和回归模型的评分预测框架的MSE结果有显著的提升。其三模型融合的评分预测效果在24个子模型上都是最优的,平均MSE为1.391。考虑单个回归模型情况,k近邻回归(KNR)表现最优,平均MSE为1.395。其次是梯度提升回归树(GBRT),平均MSE为1.416。效果最差的单回归模型是随机森林(RFR),平均MSE为1.439。它们的结果都远优于全局平均预测器并且显著优于潜在因子模型。
相比于标准潜在因子模型的改进模型(SVD++),基于文档向量和回归模型的评分预测框架的评分预测效果也有明显提升。其平均MSE结果从1.434提升到1.391,并在23个子数据集上优于SVD++。
综上所述,本文在真实的Amazon数据集上的实验表明,基于文档向量和回归模型的评分预测框架的评分预测效果确实明显优于作为基准的矩阵分解模型(LFM、SVD++)。
7 结束语
评论数据中蕴含了丰富的信息,它是改善仅将评分作为单一数据源的传统协同过滤推荐方法的关键因素之一。如何分析非结构化的评论文本成为挖掘其中蕴含的丰富信息的关键问题。本文提出了一个基于文档向量和回归模型的评分预测框架,首先,介绍了特征构建方法,包括如何使用文档向量模型将评论映射到相同维度的向量空间中以及如何使用文档向量构建用户和产品特征向量,然后,介绍了多个回归模型,最后,介绍了整个框架的构建算法。虽然本文给出的例子主要是如何解决电子商务网站中对产品的评分预测问题,但上述算法也可用于诸如个性化岗位推荐等场景,其应用前景十分广阔。未来的研究可以从评分的角度考虑更多的用户和产品特征,扩充特征空间。
参考文献(References):
[1] 刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009.19(1):1-15
[2] 邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003.14(9):1621-1628
[3] Schein, A.I., Popescul, A., Ungar, L.H., Pennock, D.M.: Methods and metrics for cold-start recommendations[C]. Proc of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Re-trieval, August 11-15, 2002, Tampere, Finland,2002:253-260
[4] Quoc V. Le and Tomas Mikolov. Distributed representa-
tions of sentences and documents[C]. Proceedings of the 31th International Conference on Machine Learning, ICML 2014. New York: ACM, 2014:1188-1196
[5] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado,
and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality[C]. Annual Conference on Neural Information Processing Systems. MA: MIT Press,2013:3111-3119
[6] Kilian Q. Weinberger, John Blitzer, and Lawrence K. Saul.
Distance metric learning for large margin nearest neighbor classification[C]. Proceedings of Advances in Neural Information Processing Systems. MA: MIT Press,2005:1473-1480
[7] Leo Breiman. Random forests[J]. Machine Learning,2001.45(1):5-32
[8] Leo Breiman, J. H. Friedman, R. A. Olshen, and C. J.Stone. Classification and Regression Trees[M]. Wadsworth,1984.
[9] J. H. Friedman. Greedy function approximation: A gradient boosting machine[J]. Annals of Statistics,2000.29:1189-1232
[10] Julian J. McAuley, Jure Leskovec. Hidden factors andhidden topics: understanding rating dimensions with review text[C]. Proceedings of the 7th ACM Conference on Recommender System. New York: ACM,2013:165-172
猜你喜欢
软件(2016年4期)2017-01-20
东方教育(2016年9期)2017-01-17
计算机应用(2016年12期)2017-01-13
电脑知识与技术(2016年28期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
农家科技下旬刊(2016年9期)2016-12-15
电脑知识与技术(2016年25期)2016-11-16
科教导刊·电子版(2016年23期)2016-10-31
商(2016年29期)2016-10-29
商(2016年28期)2016-10-27
