
基于深度学习的图像超分辨率算法研究
2016-05-20 02:05胡传平钟雪霞梅林邵杰王建何莹
铁道警察学院学报 2016年1期
胡传平,钟雪霞,梅林,2,邵杰,王建,3,何莹
(1.公安部第三研究所,上海200031;2.上海辰锐信息科技公司,上海 201204;3.上海国际技贸联合有限公司,上海 200031)
基于深度学习的图像超分辨率算法研究
胡传平1,钟雪霞1,梅林1,2,邵杰1,王建1,3,何莹1
(1.公安部第三研究所,上海200031;2.上海辰锐信息科技公司,上海 201204;3.上海国际技贸联合有限公司,上海 200031)
单幅图像超分辨率算法的主要任务是根据一幅给定的低分辨率图像重建出对应的高分辨率图像。大多数基于外部样例学习的单幅图像超分辨率算法首先提取低分辨率样例图像块和高分辨率样例图像块的图像特征,然后用机器学习的某种方法学习它们之间的非线性映射关系,最后将重叠的高分辨率图像块聚合生成高分辨率图像。对基于深度学习的端到端学习架构进行改进,端到端的超分辨率学习架构无需预处理和图像聚合过程;通过加深和改进深度学习网络结构,我们提出了一种新的基于卷积神经网络的图像超分辨率算法。与其他优秀的图像超分辨率算法进行对比,实验结果证明了该算法的优越性。
单幅图像超分辨率;外部样例学习;卷积神经网络;端到端学习
图像超分辨率技术是计算机视觉领域中一个基础而重要的问题。图像超分辨率重建有许多重要的应用领域。例如:将低分辨率的影像画质转换为高清画质以匹配适应高清电视(HDTV)的接收器;医学图像(计算机断层扫描CT,内窥镜图像,核磁共振成像MRT等)超分辨率重建获取更多细节信息有助于对疾病及时准确的诊断;监控视频中超分辨率重建感兴趣目标和区域(人脸、车牌等),在分辨率和实时性方面均有较高要求[1],使其可以帮忙发现重要线索和及早侦破[2,3];遥感图像的超分辨率重建能够帮助获取更准确的气象预报信息。
多帧图像超分辨率通过给定的同一场景的多张图像重建HR图像,提高图像采样率。单幅图像超分辨率技术(Single Image Super-Resolution,SISR)基于一幅低分辨率(Low-Resolution,LR)图像重建出有很好视觉体验的高分辨率(High-Resolution,HR)图像。本文主要研究单帧图像的超分辨率算法。传统的单帧图像超分辨率方法,如双三次方法[4]和Lanzcos插值方法[5]在假定图像平滑的前提下预测未知的高分辨率像素点,因此无法修复原始图像中的高频细节信息。一些SISR方法利用LR图像局部区域自身的相似性估计未知像素点。在过去的数十年中,学者们提出许多优秀的单幅图像超分辨率算法,最有效的算法大都是基于大量的训练样本,试图从外部低分辨率图像和高分辨率图像对中学习最佳的非线性映射关系。
一、相关研究综述
在现有的SISR方法中,基于邻居嵌入的方法[6-9]和稀疏表示的方法[10-12]均可以得到比较好的超分辨率性能,这两类方法又统称为基于外部样例学习的图像分辨率方法(external exemplar-based image super-solution method)。基于邻居嵌入的SISR方法利用HR图像块和LR图像块之间的几何相似性学习它们之间的回归或映射关系,如基于局部线性嵌套的邻居嵌入方法(Neighbor Embedding with Locally Linear Embedding,NE+LLE)、非负最小平方分解的邻居嵌入方法(Neighbor Embedding with Non-Negative Least Squares decomposition,NE+NNLS)、最小平方分解的邻居嵌入式方法(Neighbor Embedding with Least Squares decomposition,NE+LS)、固定邻居回归的方法[13](Anchored Neighborhood Regression,ANR)和调整的固定邻居回归方法[14](Adjusted Anchored Neighborhood Regression,A+)等。在基于稀疏表示的SISR方法中,利用稀疏编码理论将LR图像块和对应的HR图像块分别表示为相应的词典,通过机器学习方法建立词典之间的映射关系,利用学习的映射关系生成给定单帧图像的HR图像。
基于外部样例学习的SISR方法是指通过从大量的LR图像和HR图像对的先验知识中学习它们之间的非线性映射关系,利用学习到的函数关系超分辨率化待处理的图像。通常,基于外部样例学习的SISR方法的基本架构如下所述。首先待处理的LR图像被分解为固定尺寸(如6或9)的重叠的LR图像块,然后每一个LR图像块利用学习的映射关系重建得到相应的HR图像块,最后,通过聚合所有重叠的HR图像块生成高分辨率图像。基于外部样例学习的SISR方法可以依据采取的不同机器学习方法进行分类。还有些基于外部样例学习的SISR方法采用了联合优化策略,将LR图像块的放大和HR图像块的汇聚结合起来。如JOR(Jointly Optimized Regressors)[15]从大量外部HR图像块和LR图像块中学习一系列回归函数,然后采用近似kNN的方法为待处理的每个LR图像块选择最佳的回归函数,学习回归函数集和为每个LR图像块选择最佳回归函数结合起来进行联合优化。联合优化策略有效地提高了SISR方法的性能。
大多数基于外部样例学习的SISR方法的训练过程是在提取的LR图像特征和HR图像特征之间进行的,再通过学习的非线性函数估计的HR图像块汇聚生成最终的HR图像。近年来,深度学习方法在许多计算机视觉问题上取得很大的成功,如图像分类[16]、目标检测[17]和目标分割[18]等。实践证明,深度学习方法也可用来解决低层视觉问题,如图像去模糊[19]。同时,对于SISR,学者提出了基于深度学习的端到端的学习框架[20],这是一个重大突破。超分辨率的端到端学习架构不需要特征提取的预处理过程和后续重叠的HR图像块聚合过程。在本文中,基于端到端的学习框架,通过加深和改进深度学习网络,我们提出了一种新的基于卷积神经网络的图像超分辨率算法(New Super-Resolution using Convolutional Neural Networks,NSRCNN),提升了SISR的性能。
二、基于卷积神经网络的图像超分辨率算法
(一)SRCNN算法
作为一种基于外部样例学习的SISR方法,基于卷积神经网络的图像超分辨率算法(Super-Resolu⁃tion using convolution networks Convolutional Neural Networks,SRCNN)利用深度学习的方法直接在外部的低分辨率和高分辨率图像对上进行训练学习[21]。SRCNN采用了联合优化的策略。SRCNN的深度学习网络结构包括三个卷积层,它们分别代表图像块的特征提取和表示,LR图像块和HR图像块之间的非线性映射,HR图像块的重组。
当待处理的LR图像放大倍数为3时,SRCNN的训练过程具体如下:
91幅训练图像首先用双立法方法进行1/3下采样,然后进行3倍双立法上采样,输出后的图像与原始图像(称为HR图像)尺寸大小相同。进行下采样和上采样过程后输出的图像细节丢失很多,称为LR图像。91幅HR图像和LR图像分解成一系列33*33大小的子图像,步长为14。卷积神经网络的输入是33*33的LR子图像,而不是提取子图像的图像特征,这是不同于其他基于外部样例学习的SISR算法。
SRCNN的深度学习网络中三个卷积层公式表达如下:
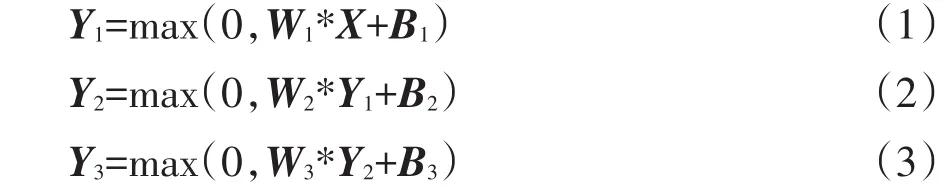
在上述公式中,矩阵X代表LR子图像,Yi(i=1, 2,3)表示每个卷积层的输出,Wi(i=1,2,3)和Bi(i=1,2, 3)分别代表每个卷积层的权重矩阵和偏置量,ni(i= 1,2,3)和fi(i=1,2,3)表示三个卷积层的滤波器数量和滤波器大小。修正线性单元(Rectified Linear Unit,ReLU)[22]应用到第一个和第二个卷积层的滤波器响应上。第三个卷积层的输出(Y3)和对应的HR子图像之间的均方误差作为驱动损失函数。
在SRCNN的测试过程中,输入是待处理的LR图像,输出是放大的HR图像。SRCNN的深度学习网络的参数设置为f1=9,f2=1,f3=5,n1=64,n2=32,n3= 1,每个卷积层的padding参数都为0。
(二)NSRCNN算法
深度学习优于一般机器学习(浅层学习)方法的主要原因在于它包含多个隐含层,具有更深的网络结构。因此,通常对于深度学习来讲,深度学习网络结构越深,网络中的学习参数越多,学习效果将会越好。例如,VGG网络[23]和Google网络[24]结构包含十几层。因此,我们可以采取加深神经网络结构的方法提升SISR性能。加深神经网络的方法包括:增加网络的层数,增加卷积层中滤波器的数量,增大卷积层中滤波器尺寸,增大训练数据的数量和多样性等。基于上述理论和SRCNN的基本架构,我们进行了大量实验试图提升SISR性能。在NSRCNN中,91幅图像用来做训练,毫无疑问更大的数据集(如ILSVRC 2014 ImageNet)能够提升图像超分辨率的性能[25]。因此,在NSRCNN的实验中,我们主要探索通过增大滤波器尺寸、滤波器数目和网络结构层数提升SISR性能。
对于深度学习在SISR方法上的应用,三个卷积层的网络结构也许不是最佳选择。然而,对于SISR,更多的神经网络层数存在收敛难题。实验证明,对于SISR,四个卷积层的网络模型是可行的。在四个卷积层的神经网络模型实验中,我们首先增大了卷积层中滤波器数量和尺寸,具体网络参数配置如下:f1=9,f2=7,f3=7,f4=5,n1=64,n2=64,n3=32,n4= 1;我们将其网络结构表示为9(64)-7(64)-7(32)-5 (1),padding参数都设置为0。然而与三层网络模型性能相比,9(64)-7(64)-7(32)-5(1)网络模型超分辨率性能提升不明显。在9(64)-7(64)-7(32)-5 (1)网络模型的训练过程中,卷积神经网络的输入为33*33的LR灰度图像;当padding参数都设置为0时,最后一个卷积层输出为9*9子图像。卷积神经网络输出的9*9子图像与对应的HR子图像最中心的9*9像素之间的均方误差作为驱动损失函数。我们设置四个卷积层中padding参数为4-3-3-2,使卷积神经网络的输出和输入尺寸相同。虽然保持33* 33尺寸导致输出的某些像素感受也超出了输入范围,但实际中并不影响学习效果,甚至会有较大性能提升,接下来的实验结果部分也说明了这点。
三、实验结果和分析
(一)与其他超分辨率算法的对比
在NSRCNN实验中,参照SRCNN方法,91幅训练图像[26,27]生成一系列的33*33大小的HR子图像和LR子图像,其中步长为14。NSRCNN的深度学习网络模型参数设置为9(64)-7(64)-7(32)-5(1),4个卷积层的padding参数分别设置为4-3-3-2。我们将NSRCNN与其他优秀的SISR算法进行比较,它们包括Bicubic,ANR[28],NE+LLE,A+[29],JOR[30]和SRCNN[31]。本文利用峰值信噪比(Peak Signal to Noise Ratio,PSNR)评价不同图像超分辨率算法的性能。
在实验结果中,表1给出了当放大倍数为3时,7种超分辨率算法在Set5数据集上的PSNR对比。在表1中,可以看到NSRCNN取得了最高的平均PSNR值,A+算法次高。表2给出了当放大倍数为3时,7种超分辨率算法在Set14数据集上的PSNR对比。在表2中,我们可以看到对于平均PSNR值来讲,NSRCNN算法性能最好,A+和JOR分别排名第二和第三,传统的双立法方法图像超分辨率性能最差。图1是7种单幅图像超分辨率算法方法放大man图像3倍时的视觉性能对比,可以看出NSRCNN视觉效果最好。
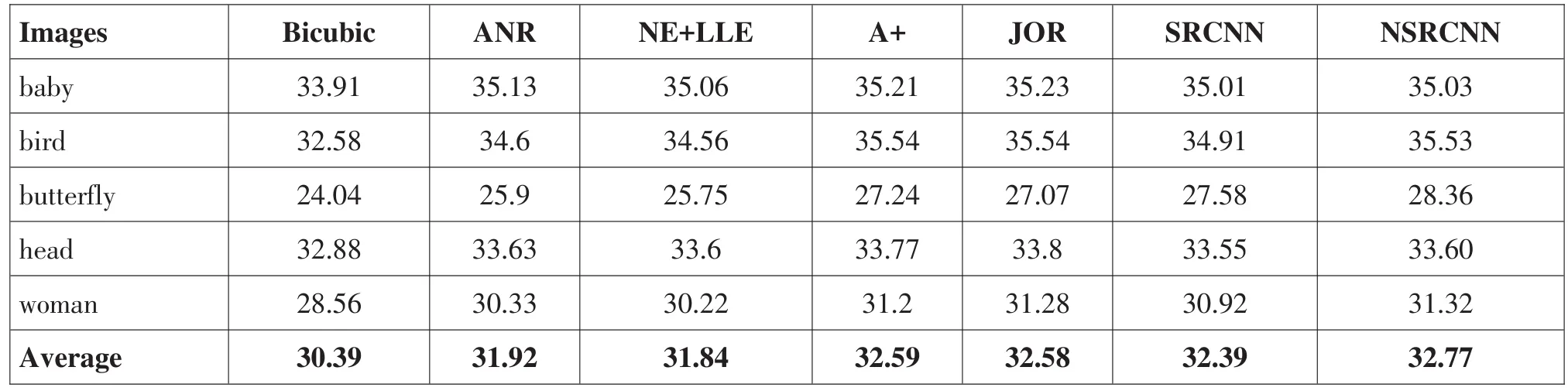
表1 七种超分辨率算法在Set5数据集上的PSNR对比(n=3)
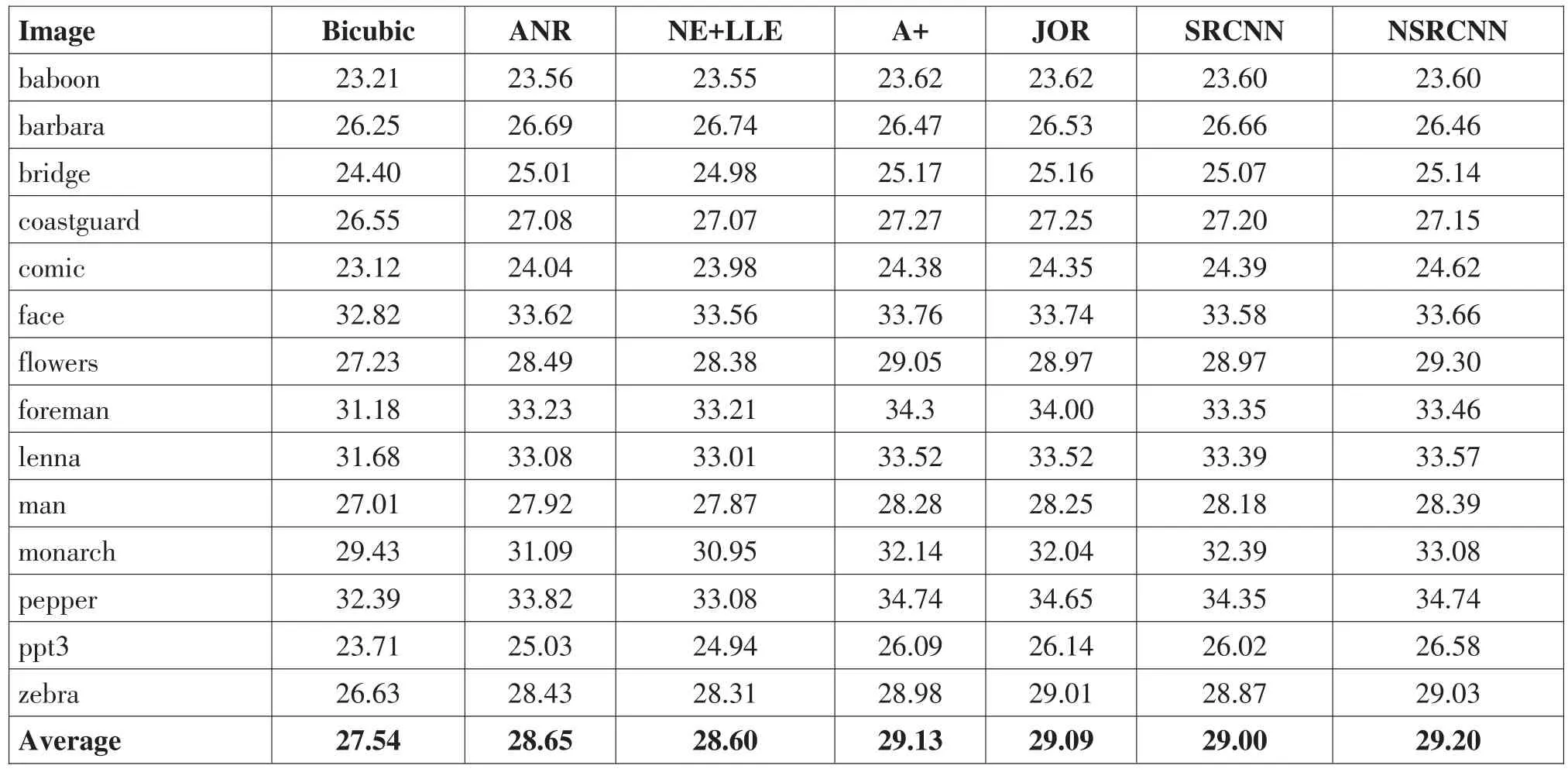
表2 七种超分辨率算法在Set14数据集上的PSNR对比(n=3)
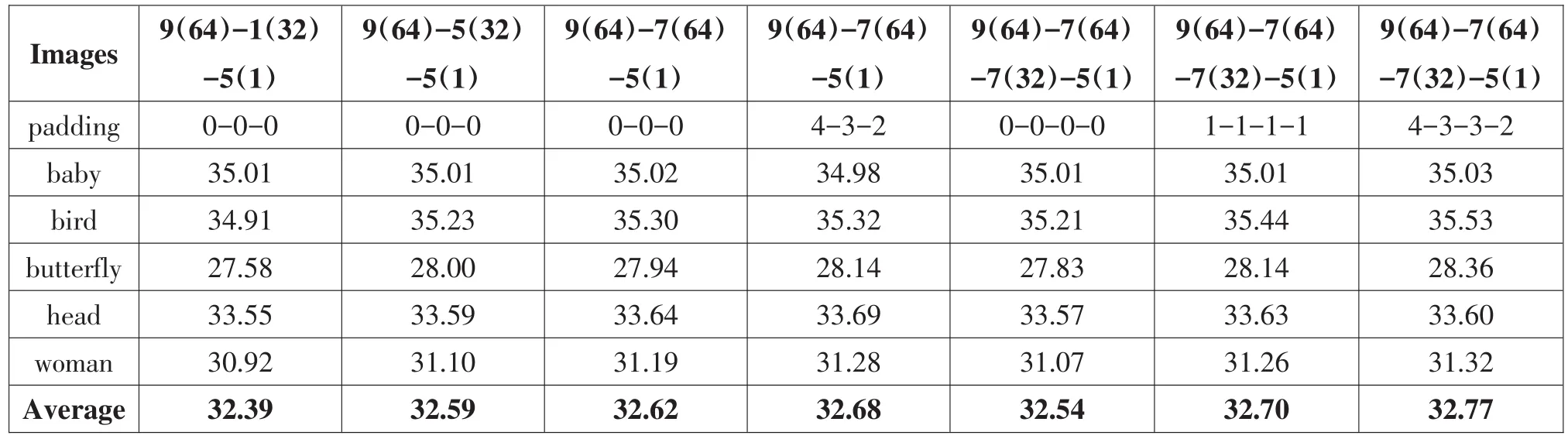
表3 不同参数配置的网络模型在Set5数据集上的PSNR对比(n=3)
(二)不同参数设置的网络模型对比
在探索改进和加深卷积神经网络提升图像超分辨率性能的实验过程中,我们对深度学习网络模型进行了不同的结构参数设置,它们包括9(64)-1 (32)-5(1),9(64)-5(32)-5(1),9(64)-7(64)-5(1)和9(64)-7(64)-7(32)-5(1),此外padding参数值设置也不同。表3给出了不同参数配置的网络模型在Set5数据集上的PSNR对比。在表3中,三个深度学习网络模型9(64)-1(32)-5(1),9(64)-5(32)-5 (1)和9(64)-7(64)-5(1)(padding参数设置都为0)的实验数据对比说明增大卷积层滤波器的尺寸和数目,更多的学习参数有助于提升SR性能。但是随着学习参数的增多,深度学习网络模型逐渐饱和,SR性能提升开始变得不明显。在9(64)-7(64)-5 (1)的网络模型中,卷积层padding参数分别设置为4-3-2与0-0-0,两者实验结果比较,前者SISR性能有些许提高。当我们采用9(64)-7(64)-7(32)-5 (1)网络模型(padding为0-0-0-0)时,与9(64)-7 (64)-5(1)网络模型对比,尽管网络层数增多,学习的参数增多,SR性能反而下降。对于9(64)-7 (64)-7(32)-5(1)网络模型而言,当padding参数设置为不同值时,包括(0,0,0,0),(1,1,1,1)和(4,3,3,2),我们可以看到SR性能逐渐大幅提升。在所有的不同结构和参数配置的网络模型中,网络模型为9(64)-7(64)-7(32)-5(1)和padding取4-3-3-2时,SISR性能最好。

图1 7种超分辨率算法放大man图像的视觉效果对比(n=3)
在探索改进和加深卷积神经网络结构提升SISR性能实验过程中,常用的深度学习优化策略,例如Dropout[32]不适用于SISR,dropout通常在深度学习大规模模型中用于防止模型过拟合。目前SISR的深度学习模型只包含4层,规模相对较小,这可能是不需要dropout的原因。
四、总结
在本文中,首先,介绍了SISR的基本原理和一些典型优秀的基于外部样例学习的SISR算法,然后详细介绍了通过改进和加深深度学习网络结构而提出的NSRCNN算法。最后,实验部分给出了不同超分辨率算法的PSNR对比和视觉效果对比,以及不同结构参数配置的神经学习网络模型的PSNR对比。将来,需要进一步探索新的深度学习网络结构提升单幅图像超分辨率算法。
[1]Chuanping Hu,Xiang Bai,Li Qi,et al.Learning Discrimi⁃native Pattern for Real-Time Car Brand Recognition[J]. IEEE Transactions on Intelligent Transportation Sys⁃tems.2015,16(6):3170-3181.
[2]Chuanping Hu,Zheng Xu,Yunhuai Liu,et al.Video struc⁃tural description technology for the new generation video surveillance systems[J].Frontiers of Computer Science,2015,9(6):980-989.
[3]Chuanping Hu,Xiang Bai,Li Qi,et al.Vehicle Color Rec⁃ognition with Spatial Pyramid Deep Learning[J].IEEE Transactions on Intelligent Transportation Systems,2015,16(5):2925-2934.
[4]R.G.Keys.Cubic convolution interpolati on for digital imageprocessing[J].IEEE Transactions on Acoustic, Speech and Signal Processing,1981,29(6):1153-1160.
[5]C.E.Duchon.Lanczos Filtering in One and Two Dimensions.JAM,1979,18(8):1016-1022.
[6][13][26][28]Timofte R,De V,Van Gool L.Anchored neighborhood regression for fast example-based superresolution[C]//Proceedings of the 2013 IEEE International Conference on Computer Vision(ICCV).IEEE,2013:1920-1927.
[7]Hong Chang,Dit-Yan Yeung,Yimin Xiong.Super Resolution through Neighbor Embedding[C]//Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR 2004). IEEE,2004,1:Ⅰ.
[8][14][29]Timofte R,De Smet V,Van Gool L.A+:Adjust⁃ed Anchored Neighborhood Regression for Fast Super-Resolution[M]//Computer Vision-ACCV 2014.Springer Inter⁃national Publishing,2014:111-126.
[9]Yang C Y,Yang MH.Fast Direct Super-Resolution by Simple Functions[C]//Proceedings of the 2013 IEEE International Conference on Computer Vision(ICCV 2013).IEEE,2013:561-568.
[10]Roman Zeyde,Michael Elad,Matan Protter.On Single Image Scale-Up Using Sparse-Representations[M]// Curves and Surfaces.Springer,2012:711–730.
[11][27]Jianchao Y,John W,Thomas H,et al.Image Super-Resolution via Sparse Representation[J].IEEE Transactions on Image Processing,2010,19(11):2861-2873.
[12]Yang J,Wright J,Huang T,et al.Image Super-Resolu⁃tion as Sparse Representation of Raw Image Patches[C]// Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition(CVPR 2008).IEEE,2008:1-8.
[15][30]Dai D,Timofte R,Van Gool L.Jointly Optimized Re⁃gressors for Image Super-Resolution[C]//Eurographics. 2015,7:8.
[16]Krizhevsky A,Sutskever I,Hinton G E.Imagenet Classifi⁃cation with Deep Convolutional Neural Networks[C]//Ad⁃vances in Neural Information Processing Systems.2012:1097-1105.
[17]Szegedy C,Toshev A,Erhan D.Deep Neural Networks for Object Detection[C]//Advances in Neural Information Processing Systems.2013:2553-2561.
[18]Schulz H,Behnke S.Learning Object-Class Segmenta⁃tion with Convolutional Neural Networks[C]//11th Euro⁃pean Symposium on Artificial Neural Networks(ES⁃ANN).2012,3:1.
[19]Sun J,Cao W,Xu Z,et al.Learning a Convolutional Neu⁃ral Network for Non-uniform Motion Blur Removal[J]. arXiv preprint arXiv:1503.00593,2015.
[20][21][31]Dong C,Loy C C,He K,et al.Learning a Deep Convolutional Network for Image Super-Resolution[M]// Computer Vision–ECCV 2014.Springer International Publishing,2014:184-199.
[22]Nair V,Hinton G E.Rectified Linear Units Improve Re⁃stricted Boltzmann Machines[C]//Proceedings of the 27th International Conference on Machine Learning(IC⁃ML-10).2010:807-814.
[23]Simonyan K,Zisserman A.Very Deep Convolutional Net⁃works for Large-Scale Image Recognition[J].arXiv pre⁃print arXiv:1409.1556,2014.
[24]Szegedy C,Liu W,Jia Y,et al.Going Deeper with Convo⁃lutions[J].arXiv preprint arXiv:1409.4842,2014.
[25]Dong C,Loy C C,He K,et al.Image Super-Resolution Using Deep Convolutional Networks[J].arXiv preprint arXiv:1501.00092,2014.
[32]Srivastava N,Hinton G,Krizhevsky A,et al.Dropout:A Simple Way to Prevent Neural Networks from Overfitting [J].The Journal of Machine Learning Research,2014,15 (1):1929-1958.
责任编辑:贾永生
The Research on Super-resolution Method Using Deep Learning
Hu Chuanping1,Zhong Xuexia1,Mei Lin1.2,Shao Jie1,WANG Jian1.3,He Ying1
(1.The Third Research Institute of the Ministry of Public Security,Shanghai 200031,China; 2.Shanghai Chenrui Information Technology Company,Shanghai 201204,China; 3.Shanghai International Technology&Trade United Co.,Ltd,Shanghai 200031,China)
The task of single image super-resolution(SISR)is to reconstruct a high-resolution(HR)image from a given low-resolution(LR)image.The most external exemplar-based SISR algorithms learn the non-linear mapping from the low to high resolution image pairs by feature extraction using a machine learning method.An HR image is finally generated by aggregating the overlapping HR image patches.On the basis of end-to-end learning framework,which is a breakthrough for SISR using deep convolution networks without the process of image feature extraction and patches aggregation,we propose a new SISR algorithm by means of deepening and the convolutional neural network.Experimental results prove the effectiveness of the Robust Super-solution method using Convolutional Neural Networks(NSRCNN)by comparison of other state-of-art algorithms.
single image super-resolution;external exemplar-based learning;convolutional neural networks;end-to-end learning
TP391
A
1009-3192(2016)01-0005-06
2016-01-04
胡传平,男,上海人,公安部第三研究所所长,研究员、博士生导师,主要研究方向为物联网应用、计算机视觉、信息网络安全等;钟雪霞,女,山东潍坊人,公安部第三研究所研究实习员,主要研究方向为计算机视觉、人工智能;梅林,男,河南遂平人,工学博士,公安部第三研究所物联网技术研发中心主任,研究员、硕士生导师,上海辰锐信息科技公司研发人员,主要研究方向为物联网应用、计算机视觉、智慧城市等;邵杰,男,河北石家庄人,公安部第三研究所助理研究员;王建,男,江苏南京人,工学博士,公安部第三研究所副研究员,上海国际技贸联合有限公司研发人员,主要研究方向为人工智能、计算机视觉、装备自动化等;何莹,女,河南商丘人,公安部第三研究所研究实习员,主要研究方向为数据挖掘、计算机视觉等。
2014年上海市国际科技合作基金项目“小型一体化移动宽带卫星通讯系统”(项目编号:15530701300);2015年上海市优秀技术带头人计划项目“智能视频监控评测服务平台”(项目编号:15XDl520200);2014年上海市科委组建上海工程技术研究中心项目“上海智能视频监控工程技术研究中心”(项目编号:14DZ2252900);2013年科技部“863”计划项目“面向城市运行管理的数据高性能分析技术与系统”(项目编号:2013AA01A603);2012年工信部物联网发展项资金项目“视频图像融合感知与智能分析技术研究及系统研制”。
猜你喜欢
心理学探新(2022年1期)2022-06-07
北京航空航天大学学报(2021年9期)2021-11-02
广东教学报·教育综合(2020年15期)2020-03-23
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年9期)2018-11-02
北京航空航天大学学报(2018年1期)2018-04-20
制造技术与机床(2017年7期)2018-01-19
自动化学报(2017年5期)2017-05-14
自动化学报(2017年5期)2017-05-14
