
基于随机森林CA的东莞市多类土地利用变化模拟
2016-05-19 01:31张大川刘小平张金宝
地理与地理信息科学 2016年5期
张大川,刘小平,姚 尧,张金宝
(中山大学地理科学与规划学院,广东广州510275)
基于随机森林CA的东莞市多类土地利用变化模拟
张大川,刘小平*,姚 尧,张金宝
(中山大学地理科学与规划学院,广东广州510275)
城市土地利用及其变化对城市环境有着重要影响。很多学者已经结合元胞自动机和机器学习算法对城市扩张进行了相关的模拟研究,但针对复杂的多类土地利用相互变化过程的研究仍然较少。该文提出了一种基于随机森林算法的多类元胞自动机(RFA-CA)模型,并将其用于模拟和预测复杂的多类土地利用变化。该模型使用随机森林算法提取元胞自动机的转换规则,并计算了各空间变量的重要性,在东莞市2000-2014年土地利用动态模拟结果中,Kappa系数和整体精度分别为0.73和84.7%。针对每一种土地利用类型,计算了影响东莞市土地利用变化的各空间变量的重要性,结果显示,交通、区位因素对东莞市土地利用变化格局的形成有重要影响。文中引入的POIs邻近因素反映了城市空间开发程度的高低,同样对多类土地利用格局的形成具有重要作用。
多类元胞自动机;随机森林算法;土地利用变化;变量重要性
0 引言
对城市土地利用动态变化的模拟有助于探索城市发展与土地利用变化的关系,以便于在发展城市经济的过程中更好地保护土地资源。元胞自动机(Cellular Automata,CA)近年来已被很多学者应用到复杂的动态时空模拟中[1-3],CA在模拟城市土地利用覆盖变化方面的潜力受到了持续关注[4],并被广泛应用于城市增长模拟中[5-11]。但这些模型往往只关注了城市用地及非城市用地这两种用地类型,并没有揭示复杂的多类土地利用之间相互变化的动态过程及变化趋势。
CA模型的核心是获取元胞转换规则[12]。模拟城市系统时,许多学者提出了采用机器学习的方法获取城市CA模型转换规则的方法,如逻辑回归方法[13]、蚁群智能算法[14]、遗传算法[15]、神经网络算法[16,17]等。传统的逻辑回归算法要求输入模型的各空间变量之间是线性无关的[18],但大多数的空间变量很难满足这种关系,比如邻近城市中心的元胞往往也邻近于道路;蚁群智能算法和遗传算法具有较强的参数自适应和优化能力,但算法计算所需求的时间复杂度较高,且易陷入局部最优;神经网络算法在模拟复杂的非线性系统时精度较高,黎夏等验证了神经网络算法模拟城市多类土地利用的可行性,并取得了显著的成果[16,17],但神经网络算法自身训练过程属于“黑箱机制”且容易出现过拟合现象,不利于揭示复杂的多类土地利用变化的机制。
针对以上问题,本文尝试采用随机森林算法(Random Forest Algorithm,RFA)提取多类CA模型的转换规则。RFA已经被证明能有效解决过拟合问题,且算法精度高、时间复杂度适中,适用于耦合较多空间变量的分类/拟合问题,并且能较好地度量各空间变量的贡献度[19,20]。本文基于RFA-CA模型模拟了东莞市2000-2014年6类土地利用变化,并根据挖掘出的多类土地利用转换规则预测了2025年土地利用变化的格局。
1 基于随机森林CA的土地利用变化模拟
在多类土地利用模拟中,当参与模拟的土地利用类型为N(N>2)类时,在不限制所有土地利用类型相互转变的情况下,理论上共N2种土地利用转变形式,形成了复杂的土地利用变化模拟的难题[16]。黎夏等提出了使用神经网络(ANN)模拟复杂的多类土地利用变化的方法[16,17],有效地简化了CA模型的结构,模拟得到了较高的多类土地利用变化精度。但受限于神经网络(ANN)算法的暗箱操作机制,模型不能很好地揭示特征变量间的相互关系和重要程度。RFA是由美国科学院院士Leo Breiman提出的一种利用多棵决策树进行预测的组合分类智能算法[19]。大量理论和实例表明,RFA具有极强的数据挖掘能力和极高的预测准确率,适用于处理复杂的多类分类问题[21];RFA对异常值和噪声容忍度高并且不容易出现过拟合,能获取较高的模拟精度[22];RFA能结合袋外数据(Out-Of-Bag,OOB)从庞大的数据集中计算特征变量的重要程度,从而揭示各特征变量间的复杂关系。相比于常规的机器学习算法,RFA算法模型构建简单、直观,所需参数少,且对特征变量本身没有严格的要求,允许各变量之间是相关的。
本文提出的RFA-CA模型由训练和模拟(预测)两部分组成(图1)。首先在训练模块中,构建训练样本集X i,利用X i训练得到RFA多类分类器;然后在模拟模块中,该多类分类器被用来进行多类土地利用模拟运算。在训练模块中,RFA本身对样本集Xi的构建是用Bootstrap方法有放回地随机抽样而成,因而样本集X i由原始训练集X中约64%的样本构成,X中另有约36%的样本不会出现在Xi中,这些数据构成OOB。RFA-CA模型可以利用OOB进行袋外预测,计算OOB误差并评价空间变量的重要性。RFA-CA模型确定多类CA转换规则,模拟多类土地利用转变的流程如图2所示。同所有的CA模型一样,RFA-CA模型的核心是获取元胞的多类别转换规则,包含多类别转换概率、邻域效应、随机因子、限制性发展因素4个部分。

图1 RFA-CA模型结构Fig.1 Structure of RFA-CA model
(1)计算多类别转换概率。RFA通过训练M棵决策树分类器集合而成一个多类组合分类器,它具有优秀的处理多类分类问题的能力。式(1)表示待分类数据集θ落入每一种类别的概率;式(2)是RFA最终的分类结果[23]。

具体而言,H(x)是随机森林多分类器分类结果,hi(x)是单棵决策树的运算结果,Yi是单棵决策树的分类结果,I(*)是分类结果指标函数。式(1)和(2)说明,RFA的分类结果是基于多数投票规则。
本文利用RFA处理多类分类问题的优秀能力,可以准确地计算每一个模拟的元胞k在t时刻从现类别到第l类别的转换概率Pg(k,t,l)。因为式(1)中Pi(x)为待分类数据θ被分为第i种类别的概率,所以转换概率Pg(k,t,l)可以表示为:
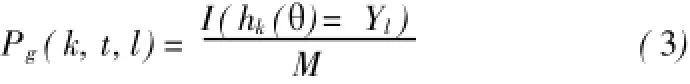
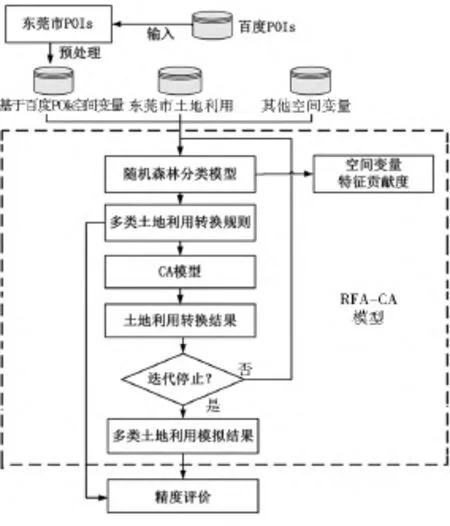
图2 RFA-CA模型土地利用模拟流程Fig.2 Flow chart of land use simulation by using RFA-CAmodel
(2)计算邻域效应。邻域效应是CA模型中反映当前元胞受邻域元胞相互作用的函数。对于N种土地利用类型,某元胞的领域函数可表示为:

式中:Ωt
k表示t时刻元胞k的n×n邻域作用值,n>3;con(*)为条件函数;Stk为元胞当前状态;Landusei为第i种土地利用类别。在多类CA模型中,针对每一种土地利用类别,如果当前元胞为该土地利用类别元胞,则值为1,否则为0。
(3)引入随机变量。影响多类土地利用模拟的空间变量比较复杂,常规的空间变量很难反映诸如自然灾害、气候改变、政策调整、经济环境等因素对模型的影响,因此,把随机项引入RFA-CA模型中[16],以使模拟更接近真实情况。该随机项表示为:

其中,γ为[0,1]范围内的随机数,α是一个控制随机变量大小的参数。
(4)引入限制性发展因素。在多类土地利用模拟中,各类别间相互转变的机制十分复杂,很难找到适宜的空间约束条件来合理地限制类别间的转变,但针对某些特殊的转变类型,可以引入一些限制性条件来约束元胞的发展。如水体向城市的转变,优质农田向其他类别用地的转变等,这些特殊的转变类型构成了限制性发展因素con(Stk),即判断在t时刻,当前元胞k是否受到限制性发展,是则con(Stk)值取0,否则con(Stk)值为1。
因此,在RFA-CA模型中,在t时刻从现类别到第l类别的发展概率可以表示为:

若参与模拟的土地利用类别有N种,且不考虑限制性发展因素对转变类型的限制,则在式(6)中,l的取值也存在N种情况,计算出的P(k,t,l)值也对应有N个值。在t时刻对于某元胞k只能转变为一种土地利用类型,因此元胞k的发展概率为N个P (k,t,l)值中的最大值,即表示为:

2 实验和讨论
2.1 研究区和数据
本文选取位于珠江三角洲的东莞市作为研究区,东莞市是连接珠江三角洲两大经济中心广州和深圳的咽喉要道,是珠江三角洲核心城市之一,近20年来土地利用不断发生变化[24]。使用RFA-CA模型模拟东莞市的土地利用变化,可以为城市规划提供有价值的信息,并能利用随机森林算法挖掘空间变量的重要性,揭示东莞市城市发展和土地利用变化格局的隐含机制。
本文利用东莞市2000年、2005年、2010年Landsat7 ETM+影像和2014年Landsat8 ETM+影像作为数据源,通过数据预处理及影像解译,获取该地区30 m分辨率土地利用分类图。模拟中涉及的土地利用类型有耕地、草地、林地、水体、城市用地、未利用土地6类。模拟过程从2000年开始,使用RFA-CA模型得到2010年和2014年土地利用变化模拟结果。
土地利用变化的概率往往取决于一系列的距离变量、邻近现有土地利用类型的数量、单元的自然属性等[25]。其中,邻近现有土地利用类型数量这一因素可以在计算转换规则的邻域效应时采用统计邻域窗口内用地类型数量的方法来计算。
过去的研究由于数据的限制,对城市的一些基础设施考虑不多,事实上,城市基础设施是城市政治、经济、文化、社会活动中所产生的物质流、人口流、交通流、信息流的重要载体,良好的城市基础设施必然对其周边的其他土地利用类型转变为城市用地有促进作用[26]。随着大数据时代的到来,可以通过网络获取各种POIs(Points of Interest)数据,这将提供大量反映城市基础设施分布的信息。因此,在本文中,利用网络爬虫技术引入了8种POIs邻近因素作为影响土地利用变化的空间变量。本文选择的POI点包括了医院、公园、公交站点等公共设施点以及工厂点、商业点等,考虑了这些POI点在空间上的分布以及点密度使得智能算法输出的土地利用变化分布尤其是城市用地发展分布与城市空间品质、空间结构更加合理、细致。因此,本文将空间变量分为自然因素、交通因素、区位因素和POIs邻近因素四大类共15个变量,其中自然因素、交通因素、区位因素使用ArcGIS欧氏距离功能计算获得,POIs邻近因素通过ArcGIS点密度计算功能获得。所获取的15个变量的空间分布见图3。
2.2 RFA-CA模型训练
本文算法处理过程采用C++编程语言实现, RFA采用开源库Shark(http://image.diku.dk/ shark/)中的C++随机森林算法,将随机森林算法直接输入训练数据集即可完成训练,计算精度高、运行速度快。对RFA-CA模型的训练过程如下:1)选取前后两期土地利用分类数据,计算得到土地利用变化图;2)在土地利用变化图上随机选择50 000个采样点,构建训练数据集D如式(9)所示,Yi表示第i个土地利用变化类型,i=1,2,…,6。
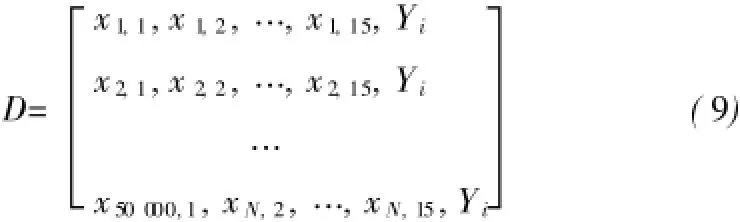
本研究中,6种土地利用类型相互转换会产生36种土地利用变化类型,如果对每一种土地利用变化类型采样相同,一些比较重要的变化类型所占的比例会比较小,而一些不重要的变化类型又会被分配到过高的比例,很容易产生过拟合的问题。因此,本文中使用了一种能够平衡采样点数量的随机采样方法,即每种土地利用变化类型的采样点个数与此类型占总像元的比例有关,并将总计50 000个采样点按照这一比例分配到每种土地利用类型中。
2.3 土地利用变化的动态模拟和预测
在RFA-CA模型中,可以通过训练好的随机森林算法计算得出每种土地利用类型的转换概率,并在此基础上结合元胞邻域效应、随机因子、限制性发展因素的共同作用,计算出元胞向每种土地利用类型转变的发展概率,实现动态模拟。模拟以2000年土地利用分类数据(图4a)作为初始状态,通过RFA-CA模型模拟得到2010年(图4c)、2014年土地利用情况(图4e)。在模拟过程中,邻域内已转变的各土地利用类型元胞数在每次迭代过程中动态计算。预测以2014年土地利用数据(图4e)为初始状态,结合东莞市土地利用变化趋势,通过RFA-CA模型得到2025年东莞市土地利用分布图(图4f)。
2.4 精度检验与评价
由图4(彩图见封3)可知,本文采用RFA-CA模型模拟得到的土地利用结果在整体空间分布上同真实情况十分接近,呈现出耕地、草地、林地面积减少以及城市面积扩张明显的趋势。预测得到的2025年土地利用结果显示,这种侵占耕地、草地、林地的城市扩张趋势会持续进行,东莞市城市面积将持续扩张,用地格局将更加紧凑。
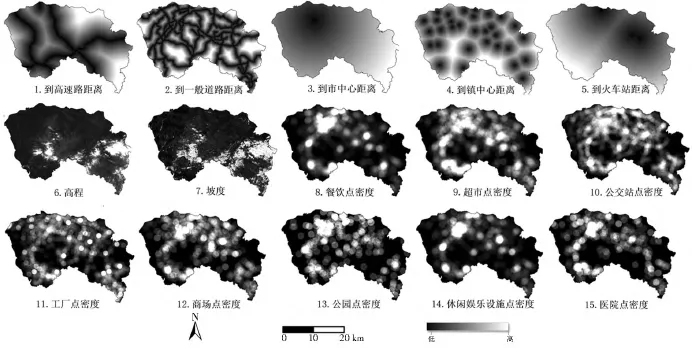
图3 东莞市土地利用动态模拟空间变量Fig.3 Auxiliary spatial variables of land use simulation in Dongguan

图4 东莞市2000-2014年多类土地利用动态模拟及预测与实际情况对比结果Fig.4 Actual and simulated land use comparison in Dongguan from 2000 to 2014
本文分别计算了2010年和2014年实际与模型模拟土地利用混淆矩阵(表1),总体精度分别为82.2%、84.7%,Kappa系数分别为0.77、0.73,模型效果理想。表2、表3是本文基于RFA-CA模型和神经网络元胞自动机(ANN-CA)[17,18]模型通过混淆矩阵得到的模拟精度的对比结果。如表2所示, RFA-CA模型的总精度和Kappa系数均高于ANNCA模型。从表3可知,相比ANN-CA模型,RFACA模型模拟得到的多类别土地利用结果与真实土地利用一致性更高,其对未来土地利用预测的精度和可靠性也较高,同样适用于对土地利用格局的预测。

表1 实际与模型模拟土地利用混淆矩阵Table 1 The confusion matrix between the actual and simulated land use

表2 RFA-CA模型与ANN-CA模型精度对比Table 2 Accuracy comparison between RFA-CA model and ANN-CA model

表3 RFA-CA模型与ANN-CA模型各类别精度对比Table 3 Accuracy comparison of all classes between RFA-CA model and ANN-CA model
在多类CA中,邻域效应是影响元胞发展概率的重要因素,由于土地利用类型的复杂性,在对邻域效应的计算中不能只统计单一类别的元胞数量,如公式(4)所示,往往需要采用一个较大的邻域计算所有土地利用类型的数量,进而充分考虑中心元胞向其他所有土地利用类型转变的可能。但邻域选择过大可能会造成邻域内不同土地利用类型的数量过于接近,降低模型的精度。因此,如表4所示,本文针对多类CA的元胞邻域窗口的取值进行实验,发现模拟精度受到邻域大小取值影响较大,针对本文2000-2014年东莞市多类土地利用的模拟,最优邻域单元为5个,邻域大小为5×5邻域。
2.5 变量重要性分析
随机森林算法可以利用袋外数据求得OOB误差以估计随机森林模型的精度,并用来评价变量的重要性。随机森林模型衡量特征变量重要性的常用方法有两种,分别是平均精度减少法和平均基尼系数下降法[19]。平均精度减少法是将某一变量的取值变为0或随机数,而其他变量保持不变,使用误差传播公式,通过分析改变该变量后模型的误差增加情况来估计该变量的重要程度;平均基尼系数下降法则是遍历所有树节点,统计每个特征变量对应的基尼系数下降总和作为该特征的贡献度,本文采用该法计算变量的贡献度。在本文中,对随机森林分类器训练后,除未利用土地(所占比例过小)、水体(限制性约束条件),针对每一种土地利用类型在分类器中使用袋外数据对各空间变量重要性进行了计算,结果如图5所示。

表4 不同邻域取值对应的模拟精度Table 4 Simulation accuracy of different neighborhood
根据图5a变量重要性计算的结果可以看出,对于整体上东莞市土地利用的变化情况,到道路(一般道路、高速路)距离、到火车站距离、到市中心距离等交通区位因素重要性最高,这说明,随着近20年东莞市城市用地的不断扩张,耕地、林地等用地面积不断被侵占,道路通达性越高、位置越优越的地区更便于与其他地区之间商品、信息、资金等的流通,进而促进其他用地向城市用地的转变,强烈地影响了东莞市土地利用格局的变化。对于POIs邻近因素,餐饮、超市、工厂和休闲娱乐设施的分布密度对模型的精度影响较大。东莞市的经济很大程度上依托于第二、三产业的发展[24],工厂的分布影响了东莞市资金和技术转移的路径,餐饮、超市、娱乐设施等提供了吸引市民消费、方便市民生活的基本条件。因此,这些POIs因素丰富了东莞市土地利用变化的驱动力, POIs分布的密度也在一定程度上影响了东莞市土地利用变化的格局。
对于城市用地(图5b),超市作为城市生活密切相关的场所,其分布密度重要性最高,此外,区位因素对模型精度的影响较大、重要性较高;这是因为距离城市中心越近的地方,享受到城市良好的基础设施、丰富的教育、卫生机构条件的机会越大,从而推动周边非城市用地向城市用地的转变。经济增长与耕地数量之间存在类似库兹涅茨曲线型关系[27],耕地资源流失量与城市的经济发展有着密切的关系,尤为明显表现在城镇周边和交通沿线[28,29];如图5c所示,东莞市的耕地类型变化同样强烈地受到了东莞市城市扩张的影响,距离主要道路和城镇中心越近的地区,耕地更容易被侵占,从而造成耕地资源的减少。高程是影响林地变化十分重要的因素[30,31],这是因为随着高程的上升,林地向其他用地转变的比例会降低,而在低海拔地区,林地则会大量的转变为园林、城市用地等用地类型;从图5d中直观看出,东莞市林地受高程的影响较大,在高海拔处制约了林地向其他用地的转变,在高程较低的地区,尤其是在高速路周边,容易发生林地向城市用地的转变。草地的分布具有一定的生态序列性,与高程、坡度等地形因子具有一定的联系[32];如图5e所示,高程、坡度对东莞市草地的变化影响很大,高程和坡度越小的地区越容易发生草地向其他用地的转变。
3 结论

图5 空间变量重要性度量Fig.5 Importance of each spatial variable
确定CA模型的转换规则一直是CA模型研究的重点,运用CA模型模拟复杂的多类土地利用变化问题难度很大[16,17]。本文构建的RFA-CA模型运用随机森林算法计算出了元胞多类别转换概率,进而获取了多类CA转换规则,可以有效地模拟出复杂的土地利用动态变化的过程。
本文为了反映城市基础设施对周边用地向城市用地转变的促进作用,在空间变量中引入了POIs邻近因素,并联合获取到的交通因素、区位因素、自然因素共同作为模型的自变量,6类土地利用变化作为模型因变量,运用RFA-CA模型获取了东莞市多类土地利用转换规则,模拟并预测了东莞市多类土地利用的动态变化。模拟和预测结果显示,东莞市近20年耕地、林地、草地面积逐渐被侵占,城市面积不断增多,具有强烈的城市化趋势,并且到2025年,这一趋势将持续下去,使得城市面积更加扩张,耕地、草地等面积更加匮乏。通过精度检验和对比发现, RFA-CA模型在实验中具有较高的精度,相比于传统的逻辑回归模型具有一定优势,更适用于模拟和预测复杂的多类土地利用变化。从对于整体土地利用格局和对于不同土地利用类型两方面,本文通过随机森林算法对各空间变量的重要性分别进行了度量。结果显示,对于不同的土地利用类型,空间变量的重要性均不相同,所得出的重要性排序可以为因地制宜地保护土地资源提供有价值的辅助信息;在整体上,交通区位因素以及餐饮、工厂等部分POIs分布的密度对模型精度影响较大,对东莞市土地利用变化有着重要影响。
本文利用RFA计算出医院、公园等POIs分布密度重要性较低,对模型精度的影响较小。然而,这些POIs密度同样是反映城市空间开发程度的重要指标,对体现未来城市发展趋势将起到一定的指导意义,因此,本文中未利用RFA对这类较低重要度的空间变量进行筛选。此外,本研究没有将RFACA模型应用于较大研究区,在今后的研究中,需要使用模型完成如珠三角、长三角等较大研究区的模拟和预测,以验证模型的适用性以及比较不同区域之间土地利用变化规律的异同。
[1] WARD D P,MURRAY A T,PHINN S R.A stochastically constrained cellular model of urban growth[J].Computer Environment and Urban Systems,2000,24:539-558.
[2] 周成虎,孙战利,谢一春.地理元胞自动机研究[M].北京:科学出版社,1999.
[3] 罗平,杜清运,雷元新,等.地理特征元胞自动机及城市土地利用演化研究[J].武汉大学学报(信息科学版),2004,29(6):504 -513.
[4] 廖江福,唐立娜,王翠平,等.城市元胞自动机扩展邻域效应的测量与校准研究[J].地理科学进展,2014,33(12):1624-1633.
[5] CHEN Y,LI X,SU W,et al.Simulating the optimal land-use pattern in the farming-pastoral transitional zone of Northern China[J].Computers,Environment and Urban Systems,2008, 32:407-414.
[6] CHENG J,MASSER I.Cellular Automata based temporal process understanding of urban growth[A].Cellular Automata[C].2002. 325-336.
[7] LI X,L AO C,LIU X,et al.Coupling urban cellular automata with ant colony optimization for zoning protected natural areas under a changing landscape[J].International Journal of Geographical Information Science,2011,25:575-593.
[8] HUANG G,GAO W.Simulating study on CA model based on parameter optimization of genetic algorithm and urban development[J].Procedia Engineering,2011,15:2175-2179.
[9] 刘明皓,安广文,李超.基于动态邻域思想的ACO-CA城市动态模拟——以重庆市沙坪坝区为例[J].地理与地理信息科学, 2016,32(3):74-89.
[10] 何春阳,史培军,陈晋,等.基于系统动力学模型和元胞自动机模型的土地利用情景模型研究[J].中国科学(地球科学), 2005,35(5):464-473.
[11] 陈凯,刘凯,柳林,等.基于随机森林的元胞自动机城市扩展模拟——以佛山市为例[J].地理科学进展,2015,34(8):937-946.
[12] 黎夏,叶嘉安.知识发现及地理元胞自动机[J].中国科学(地球科学),2004,34(9):865-872.
[13] WU F,WEBSTER C J.Simulation of land development through the integration of cellular automata and multicriteria evaluation [J].Environment and Planning B,1998,5:103-126.
[14] 刘小平,黎夏,叶嘉安,等.利用蚁群智能挖掘地理元胞自动机的转换规则[J].中国科学(地球科学),2007,37(6):824-834.
[15] 杨青生,黎夏.基于遗传算法自动获取CA模型的参数——以东莞市城市发展模拟为例[J].地理研究,2007,26(2):229-237.
[16] 黎夏,叶嘉安.基于神经网络的单元自动机CA模拟及真实和优化城市模拟[J].地理学报,2002,57(2):159-166.
[17] 黎夏,叶嘉安.基于神经网络的元胞自动机及模拟复杂土地利用系统[J].地理研究,2005,24(1):19-27.
[18] KNOL M J,LE CESSIA S,ALGRA A.et al.Overestimation of risk ratios by odds ratios in trials and cohort studies:Alternative to logistic regression[J].Canadian M edical Association Journal,2012,184:895-899.
[19] BREIMAN L.Random Forests[J].Machine L earning,2001, 45(1):5-32.
[20] 李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(4):1190-1197.
[21] 方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2011(3):32-38.
[22] IVERSON L R,PRASSAD A M,MAT TEWS S N,et al.Estimating potential habitat for 134 eastern U S tree species under six climate scenarios[J].Forest Ecology&Manag ement, 2008,254(3):390-406.
[23] BIAU G E R.Analysis of a random forests model[J].T he Journal of Machine Learning Research,2012,13:1063-1095.
[24] 郑艳婷,刘盛和,陈田.试论半城市化现象及其特征——以广东省东莞市为例[J].地理研究,2003,22(6):760-769.
[25] BATT Y M,XIE Y.From cells to cities[J].Environment and Planning B:Planning and Design,1994,21:531-548.
[26] 董超.“流空间”的地理学属性及其区域发展效应分析[J].地域研究与开发,2012,31(2):5-14.
[27] 刘凤朝,孙玉涛.耕地减少、农民失地与经济增长的关系分析[J].资源科学,2008,30(1):52-57.
[28] 潘佩佩,王晓旭,杨桂山,等.经济快速发展地区耕地质量时空变化格局研究[J].地理与地理信息科学,2015,31(4):65-70.
[29] 陈永林,谢炳庚,李小青,等.长沙市城市扩张对边缘区景观格局的影响[J].地理与地理信息科学,2016,32(2):94-99.
[30]卜心国,王仰麟,沈春竹,等.深圳市地形对土地利用动态的影响[J].地理研究,2009,28(4):1011-1021.
[31] 秦佩恒,武剑峰,刘雅琴,等.快速城市化地区景观可达性及其对林地的影响——以深圳市宝安区为例[J].生态学报,2006, 26(11):3796-3803.
[32] 赵连春,刘荣堂,杨予海,等.基于地形因子的草地遥感分类方法的研究[J].草业科学,2006,23(12):26-30.
Simulating Spatiotemporal Change of Multiple Land Use Types in Dongguan by Using Random Forest Based on Cellular Automata
ZHANG Da-chuan,LIU Xiao-ping,YAO Yao,ZHANG Jin-bao
(School of Geography and Planning of Sun Yat-Sen University,Guangz hou510275,China)
Urban land use information plays an important role in urban environment.China′s land resources are under increasing pressure due to the rapid development of economic growth and urbanization process.Many previous studies have focused on urban area expansion by integrating Cellular Automata(CA)and M achine Learning(ML)algorithms.However,simulation of multiple land use changes using CA model is difficult because there are numerous spatial variables and the change types have to be settled.T his paper proposes a new method to simulate spatiotemporal complex multiple land uses by using Random Forest Algorithm(RFA)based on CA model.One significant advantage is that this algorithm can reduce error upper limit of the generalized model.RFA-CA model can extract the complex land use conversion rules and measure the importance of the spatial variables,which could explain the influence of variables in different land use change.We apply RFA-CA model on simulating and predicting the dynamics of multiple land uses in Dongguan during 2000-2014(Dongguan is a modern city in South China with rapid economic development in recent 20 years).T he result shows that RFA-CA model has high accuracy with Kappa 0.72 and overall accuracy 84.7%.Additionally,when compared to ANN-CA model,the results are also improved to varying degree. Through measuring the importance of some spatial variables including POIs variables which are introduced in our study,we obtain different regular for each land use type.Taking all land uses as a whole,we find that the traffic,position and a part of POIs factors play an important role in forming Dongguan′s land use pattern.
multi-classes cellular automata;random forest algorithm;land use change;variables importance
F301.24
A
1672-0504(2016)05-0029-08
10.3969/j.issn.1672-0504.2016.05.005
2016-07-15;
2016-08-20
张大川(1993-),男,硕士研究生,主要研究方向为大数据与城市模拟。*通讯作者E-mail:liuxp3@mail.sysu.edu.cn
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
农业工程学报(2022年7期)2022-07-09
模具制造(2022年3期)2022-04-20
模具制造(2022年1期)2022-02-23
鸭绿江(2021年17期)2021-10-13
模具制造(2021年5期)2021-08-12
吉林大学学报(理学版)(2020年3期)2020-05-29
自动化学报(2018年7期)2018-08-20
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
