
一种基于FPGA指纹识别加速结构的设计与实现
2016-05-14 03:11赵锦明钱磊吴东
网络空间安全 2016年5期
赵锦明 钱磊 吴东

[摘要]指纹识别是生物识别技术中重要且广泛使用的一种。当前该领域研究的重点在如何更好地采集提取指纹特征以及指纹安全等方面,对于大规模指纹识别的研究较少。随着电子商务、公安部门的大规模使用,需要进行比对的指纹数据暴增。针对这一现状,论文在基于细节特征点的这一类指纹识别算法基础上,利用FPGA平台对这类算法进行加速,通过对算法的分析调整,在FPGA上设计实现了一种新的加速结构,并采取了相应的优化策略。通过加速,单节点FPGA能达到每秒100万次指纹比对,相对于软件性能提升了25倍,为后续新算法的大规模使用奠定了基础。
[关键词]生物识别;指纹识别;流水;乒乓操作;FPGA
[中图分类号]TP3 [文献标识码]A
1 引言
在信息化时代的今天,信息安全尤其重要,如何鉴别一个人的身份是其中一个至关重要的问题。传统方式存在易丢失、容易被伪造等问题,利用生物识别技术进行身份认定,不仅安全、准确,还便于管理,应用前景广阔。指纹具有终身不变性、唯一性和方便性,依靠指纹的生物识别技术被广泛接受与认可,相关应用也较为广泛。
指纹是指人的手指末端正面皮肤上凸凹不平产生的纹线。纹线的起点、终点、结合点和分叉点,称为指纹的细节特征点(Minutiae)。指纹识别即指通过比较不同指纹的细节特征点来进行身份鉴别。
目前指纹识别主要应用在手机解锁、门禁考勤等方面,需要进行的比对计算量小,而随着指纹识别应用领域更加广泛,如电子商务、公安部门等,指纹识别中的数据量暴增,识别过程中的计算量极大,采用传统的方法需要大量时间,这在许多应用场合是达不到要求的。已有的研究主要针对指纹识别采集阶段图像增强和特征提取,如文献;指纹识别系统的全过程自动化AFIS(Automated Fingerprint Identification System),如文献;指纹识别算法的准确率,如文献等;与此同时,也有部分尝试对指纹识别进行加速的研究,文献,但效果不够理想。
本文在此背景下,针对如何快速进行较大规模指纹比对这一问题,对常用的基于特征点的一类指纹识别算法进行了分析,基于FPGA平台,针对识别过程中计算量最密集的部分进行重构及算法调整,设计并实现了一种FPGA平台上的加速结构。并采用了一些方法进行资源优化和性能提升。加速效果明显,采用该加速结构FPGA单节点对原算法有25倍的加速效果。达到了每秒100万次指纹比对的性能:如果同时采用多节点FPGA并行,能达到更高的性能,能够初步满足大规模指纹识别的需要,并为后续同类型新算法的大规模应用奠定了很好的基础。
2 基于细节特征点的指纹识别算法
2.1 指纹识别简介
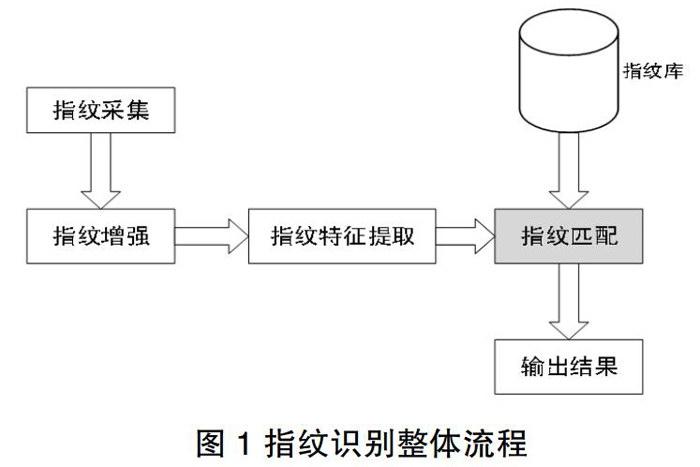
指纹识别是指通过比较不同指纹的细节特征点来进行身份鉴别的过程,其整体流程如图1所示。包括指纹库的建立、待比对指纹采集、指纹处理及特征提取、指纹匹配等主要过程。
指纹识别算法主要用在指纹匹配阶段,用于将新采集的指纹与数据库中的指纹逐一进行比对。基于细节特征点的指纹识别算法是一类典型的指纹识别算法,即指通过比较计算不同指纹的细节特征点的相似程度而进行身份鉴别的方法。
2.2 基于细节特征点的指纹识别算法原理
基于细节特征点的算法是一类典型且使用较多的指纹识别算法,该算法中指纹匹配部分比对的流程如图2所示。
将采集到的待匹配指纹EXP的细节特征点与数据库中某个指纹DEMO的细节特征点数据作为输入:先将EXP指纹特征点两两组合展开为特征向量,如图3所示:并对展开的EXP指纹特征向量按照向量角排序存储:然后将DEMO指纹根据其特征点两两展开生成特征向量,同时与已生成的EXP特征向量构建特征向量对:再根据特征向量对计算出参数对EXP指纹进行旋转、平移操作,并删除相似度较低的向量对;最后根据剩余的相似度较高特征向量对,计算出它们的全局相似度,并根据相似度判断它们是否匹配。
各步骤具体如下:
EXP指纹展开是指根据EXP指纹的细节特征点数据,将特征点两两组合生成特征向量,如图3所示,A1、A2是EXP指纹的两个细节特征点:
EXP指纹特征向量排序是指根据前面生成的特征向量,按照其角度A1方向角和特征向量长度对其进行排序;DEMO指纹展开并构建特征向量对是根据DEMO指纹特征点两两组合构建特征向量,并同时根据已生成的有序EXP指纹特征向量初步查找可能相似的特征向量,构造成特征向量对;EXP指纹旋转、平移并删减特征向量对是将EXP指纹按照比较结果进行旋转平移,并将处理后相似度较低的特征向量对删除;计算全局相似度是指根据最后剩下的特征向量对,计算两个指纹的全局相似程度:最后根据全局相似度判断输入的两个指纹是否匹配,即完成了一次指纹比对:再取出指纹库中另一DEMO指纹重复上述过程。
2.3 算法分析
该算法主要是基于遍历的思想,整体上待匹配指纹与指纹库中的指纹遍历地进行一一比较:在一对指纹比较过程中,通过细节特征点两两组合产生特征向量,然后在两个指纹的特征向量之间遍历地计算相似程度。整体过程计算量比较大,而且大多数都是重复的运算过程,软件平台上需要消耗大量的处理器资源,但硬件平台却很适合处理这一类问题。
目前该类算法在软件平台上的实现性能受处理器资源和频率限制,只能达到约每秒数万次指纹比对,远远无法达到大规模使用的要求。本文针对这一现状,尝试基于FPGA平台对这类算法进行加速。
3 基于FPGA的加速结构设计
FPGA平台具有许多软件平台无法比拟的优势,如较低的功耗、丰富的资源、天生的并行性等,因而采用FPGA平台进行加速设计是合适的。为了达到研究目标,根据FPGA平台的特点,对原算法进行适当调整,并设计一种相应的加速结构。
3.1 设计思想
通过对软件算法的流程和原理研究发现,该算法中涉及到较大的计算量,特别是其中DEMO指纹展开并构建特征向量对部分,不仅需要根据DEMO指纹细节特征点构建特征向量,同时还要从上一步已经生成的特征向量中查找相似度较高的特征向量构造向量对,并计算相似度。这一过程是计算量最大、计算最密集的部分,也是整个算法中的瓶颈部分。因此为了对该类算法进行加速,首先考虑的就是对这一部分进行调整与加速。
根据直观的想法,两个指纹相似度越高,它们之间匹配的特征向量对数目也就越多。在这一想法的基础上,本文对样本指纹数据库进行了统计分析,结果如图4所示。
从图4可以看出,随着阈值的增大,满足匹配阈值的指纹比率急剧降低,而正确率降低较慢,所以设定一个阈值对指纹库进行预过滤是可行的,本文也就是基于这一思想进行了加速结构的设计和实现。
3.2 算法调整
为了使用FPGA平台对整个算法进行加速,本文对原算法的结构进行了适当调整,算法整体采用预过滤之后精确比对的思想进行加速。通过预过滤剔除指纹库中大部分不符合的指纹,经过分析发现在特定阈值下能剔除99%的指纹库指纹,再对余下可能性较大的小部分指纹进行精确比对,从而达到整体加速的效果;其中预过滤加速部分在FPGA上进行,也是整个加速结构的核心部分。
基于上述思想,为了便于硬件的加速结构实现,本文适当调整原算法结构:将DEMO指纹展开并构建特征向量对这一过程剥离开来,先产生DEMO指纹特征向量,再和待匹配的EXP指纹特征向量进行逐一组合匹配计算。这样调整的好处在:一方面可以将计算过程分成多个模块,便于计算量的平衡;另一方面多模块的结构便于硬件环境下流水,从而加速整个计算过程。
3.3 结构设计
在上述设计思想的指导下,本文调整算法结构后初步设计的结构如图5所示。
4 加速结构实现
4.1 模块划分
根据粗筛的想法,将原算法DEMO指纹展开并构建特征向量对部分拆分为:demo_gen、pair_expand、pair_expand_all、pair_cal这四个子模块,结构如图5所示。
拆分为多个子模块一方面是为了均衡计算量,避免某个部分计算量过大,成为加速设计的瓶颈:另一方面是为了在FPGA中形成流水线,从而提高在FPGA中运行的性能
各模块的功能说明如下:
demo_gen:将DEMO指纹特征点集中的特征点两两组合生成正向和反向的DEMO指纹特征向量(对应生成的DEMO特征向量A1方向角的两种情况),并将生成的DEMO特征向量相关数据(A1方向角,A2方向角,长度Len)传到下一模块。
pair_expand:根据demo_gen模块传人的DEMO指纹特征向量数据。按照A1方向角允许误差展开查找待匹配的EXP指纹特征向量,在EXP指纹特征向量角度地址映射表(A1_addr_map)中查找ID范围(A1_addr_map中的角度映射值,对应EXP指纹特征向量缓存表linebyA1中EXP特征向量位置),并将DEMO特征向量与待匹配的EXP特征向量ID范围数据传人下一模块。
pair_expand_all:根据pair_expand模块传入的ID范围展开待匹配的EXP特征向量,生成DEMO特征向量与具体的EXP特征向量对数据,并传到下一模块。
pair_cal:计算pair_expand_all模块传人的所有特征向量对数据是否匹配,并统计两个指纹点集间局部相似度累加和,输出结果供粗筛过滤使用。
同时,在整个结构中增加到两个比较重要的数据结构。
EXP指纹特征向量缓存表(linebyA1):存储了一个EXP指纹的所有特征向量数据。并且按照A1方向角从小到大的顺序排列,建立这样一个表是为了根据A1方向角的值快速的查找到EXP指纹对应的特征向量数据,节省查找时间,其中一条特征向量的数据结构如表1所示。
EXP指纹特征向量角度地址映射表(A1_addr_map):是根据表linebyA1中A1方向角从小到大统计的特征向量数目的累加和,其映射了方向角为A1的特征向量数据在linebyA1表中的起止地址,配合linebyA1表快速的定位所有方向角为A1的特征向量:A1_addr_map表的序号对应方向角A1,每个数据表示该角度特征向量的数目。
4.2 优化策略
进行上述算法调整和结构实现后,经过实验发现加速效果并不明显。为了提高加速的效果。除采用一些主要的优化策略:计算过程多模块化、模块内循环流水及模块之间流水并行、采用新的数据结构缓存避免重复计算等,还针对资源和结构方面进行了特定的优化。
4.2.1 资源优化
为了在单节点FPGA中尽可能多的放入并行加速流水线,对单条流水线中各个模块的资源占用情况进行分析发现:demo_gen模块的LUT资源使用(约7%)是决定放入条数的瓶颈。
经过深入研究算法发现:算法中采用简单平方和之后开平方的方式计算两个特征点之间的距离。该运算需要占用大量计算资源,是资源瓶颈。为了缓解这一情况,文中采用两点距离近似计算方法,即采用移位运算来近似求解两点间的距离,且算法的精确度在能够接受的范围内,从而在使用很少资源的同时达到较高的精确度。
原算法和近似算法的资源占用情况如图6所示,FF(Flip-Flop)使用是原来的14.8%,LUT(Look-Up-Table)的使用是原来的26.3%,极大的优化了资源的使用,使得原来单节点放入加速流水结构从14条增加到20条。
4.2.2 结构优化
经过资源优化之后,整体性能有了很大提高,为了进一步提高整体性能,观察并统计各个模块的时延情况如图7所示,另一方面在资源优化后,LUT的使用下降,而第一个模块demo_gen部分的DSP资源的使用成为了瓶颈,约占全部资源的4%。
观察各模块的时延图,可以发现第一个模块demo_gen的运行时延不到最大时延模块pair_expand_all的一半,但其DSP资源的占用最多,也是影响FPGA中放人流水线数目的瓶颈。
基于上述情况,本文考虑采用双尾端的结构,即在一个demo_gen模块后面连接相同的两条尾巴。如图8所示。并且通过“乒乓”操作的方式使得demo gen模块的有效运行时间更长,从图7时延上来看这一设计是可行的。
通过这样的方式,将一条流水线中demo gen模块的资源占用平摊到两条流水线,仅占到2%左右,而单条流水线的性能基本没有影响,从而能够在同一FPGA中等效放入30多条流水线,极大的提高了加速结构的吞吐率。
4.3 整体结构
经过资源优化和整体结构优化调整后,加速结构单条流水线整体如图8所示。
5 实验及结果分析
为了测试设计的整体效果,本文在FPGA平台上对这一加速结构进行了实现。并同时在软件平台上对原算法进行了相应的比较测试。
5.1 实验平台
本文选择了常见的软硬件平台进行实验测试。软件平台:采用的X86服务器是Intel XeonE5620,主频2.4GHz,内存40GB;硬件平台:采用的是Xilinx的FPGA(zynq-7030fbg484),包含的主要资源分别是LUT(78600)、FF(157200)、DSP(400)。
5.2 结果分析
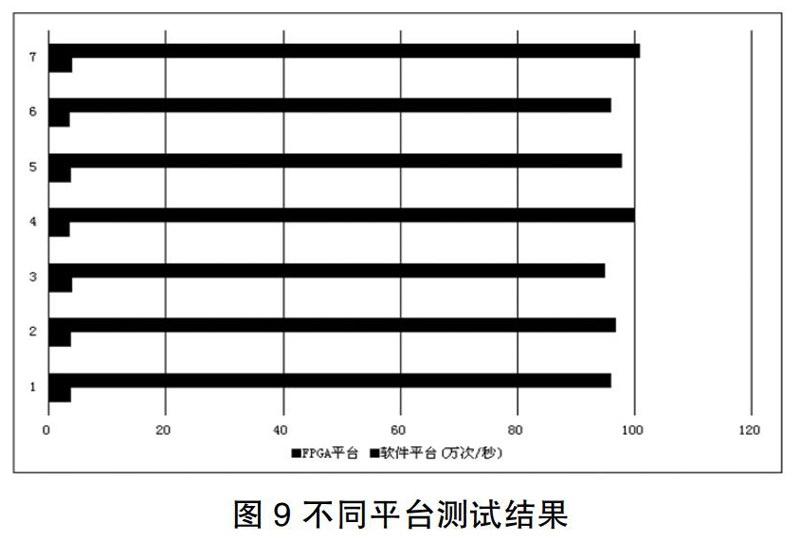
在所选择的软硬件平台上,本文针对不同的指纹数据进行了多次测试,实验结果如图9所示。
通过图9实验结果可以看出。本文所实现的加速结构加速效果非常明显:软件平台上的平均匹配速度约为每秒4万次,本文在单节点FPGA平台上实现的加速结构平均匹配速度约为每秒100万次。达到了25倍的加速效果。
另一方面,本文采用FPGA平台是可扩展的。通过使用多个FPGA节点并行的处理,整体计算速度还可以进一步提升。目前本文已在16个节点的FPGA上进行了实现,整体性能达到每秒千万次比对,能够初步满足大规模范围的指纹匹配应用。
6 结束语
本文主要针对基于细节特征点的这一类指纹识别算法在大规模指纹数据应用下的加速问题,提出并设计实现了一种加速结构。通过本文的加速,指纹匹配性能有了极大的提升,单节点FPGA能达到25倍的加速效果。16个节点并行条件下甚至能到每秒千万次比对,能够初步满足大规模指纹匹配的应用场景,达到了本文的主要目标,也为后续新指纹匹配算法的大规模应用奠定了基础。
但由于本文主要针对基于细节特征点这一类指纹识别算法,对其他指纹识别算法的加速效果没有这么明显。这是本文目前的主要问题,也是下一步需要深入研究的地方。
猜你喜欢
东坡赤壁诗词(2020年2期)2020-06-04
扬子江(2018年1期)2018-01-26
中国知识产权(2016年11期)2016-11-11
中国知识产权(2016年11期)2016-11-11
发明与创新·大科技(2016年5期)2016-05-17
个人电脑(2016年6期)2016-05-14
六盘山(2015年3期)2015-06-29
青年文摘·上半月(1993年10期)1993-01-01
