
SPSS的聚类分析在经济地理中的应用
2016-05-13 01:38:32丁磊,冯小康
西部皮革 2016年8期
SPSS的聚类分析在经济地理中的应用
1引语
经济地理研究中,经常需要对所研究的区域进行经济区划分,以便进行分类指导。如何进行经济区划分呢?利用世界上著名的统计软件SPSS(Statistical Program for Social Science)的聚类分析功能,效果相对比较理想。聚类分析法是理想的多变量统计技术,主要有分层聚类法和迭代聚类法(苏金明,2000)。聚类分析也称群分析是研究分类的一种多元统计方法。它的基本原理是:首先讲一定数量的样品(或指标)各自看成一类,然后根据样品(或指标)的亲疏程度,将亲密程度最高的两类进行合并;然后考虑合并后的类与其他类之间的亲疏程度,再进行合并;重复这一过程,直至将所有的样品(或指标)合并为一类。
对贵州省各州市的9个地区(贵阳、遵义、安顺、黔南、黔东南、铜仁、毕节、六盘水、黔西南)进行经济区划分,就利用了SPSS的聚类分析功能。
2建立指标体系
2.1确定分类指标
进行经济区划分,应考虑的指标因素很多的。既要以经济因素为主,又要考虑自然因素和社会因素;既要有直接指标,又要有间接指标;既要有影响经济因素的指标,又要有经济现象引起的指标;既要考虑经济发展的现状,又要考虑经济发展的过程和经济发展的未来方向;既要有可以查阅到或计算出确切数据的指标,又要有无确切数据的指标。
参考有关资料,我确定了对贵州省各地区进行经济区划分的指标。有确切数据的指标如表1所示,无确切的数据的指标有煤炭资源、油气资源、建材资源和区位商贸。

表1 经济区划分指标
2.2填充指标数据
参照《贵州省统计年鉴》2011卷、《贵州省水资源公报》等书,查得或计算出表1各具体指标的数据如表2所示。
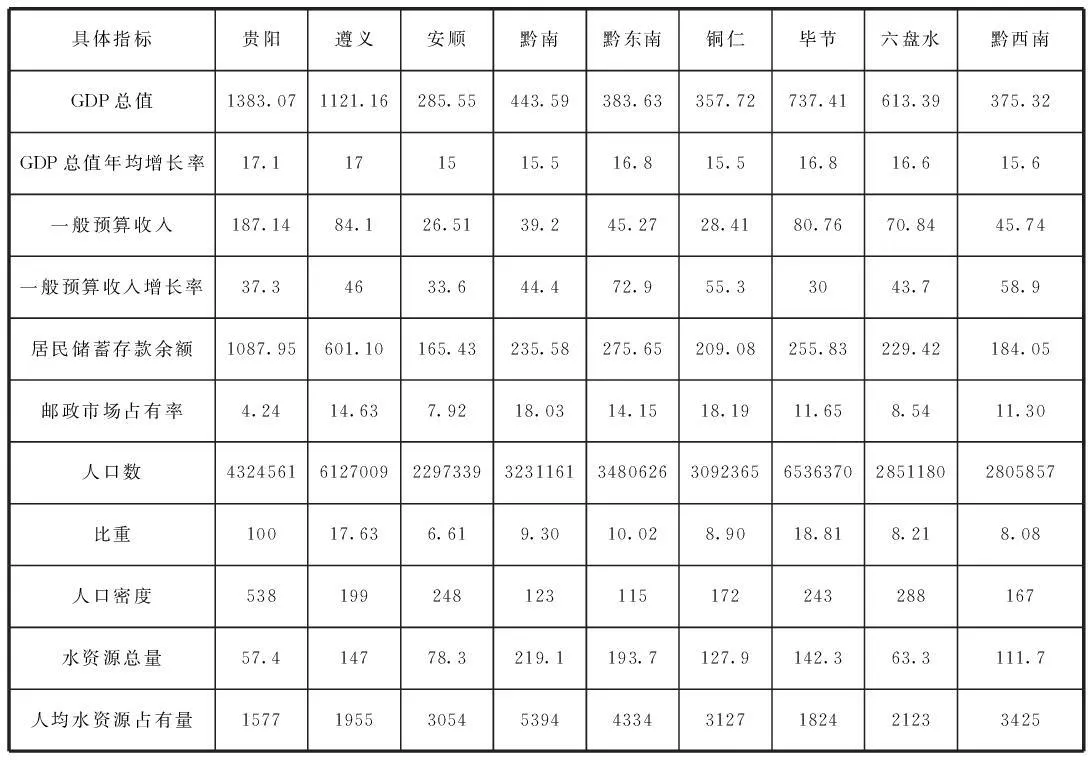
表2 贵州省各州市的9个地区经济区划分的指标数据(数据单位见表1)
2.3转换指标数据
由于不同变量之间存在不同量纲、不同数量级,为使各个变量更具有可比性,有必要对数据进行转换。目前进行数据处理的方法大致有三种,即标准化、极差标准化和正规化。为便于更直观的比较各市之间同一指标的数值大小,采用了正规化转换方式(张苏江,2003)。其计算公式为:
公式中Xi为正规划后的值,Xi为原值,Xmax为最大值,Xmin为最小值。
进行正规化转换后,0≦Xi≦1。另外,对9个地区的煤炭资源、油气资源、建材资源和区位商贸等指标也根据实际情况采用专家打分法,给出一个介于0-1的数。所有参与聚类分析的指标数据见表3。
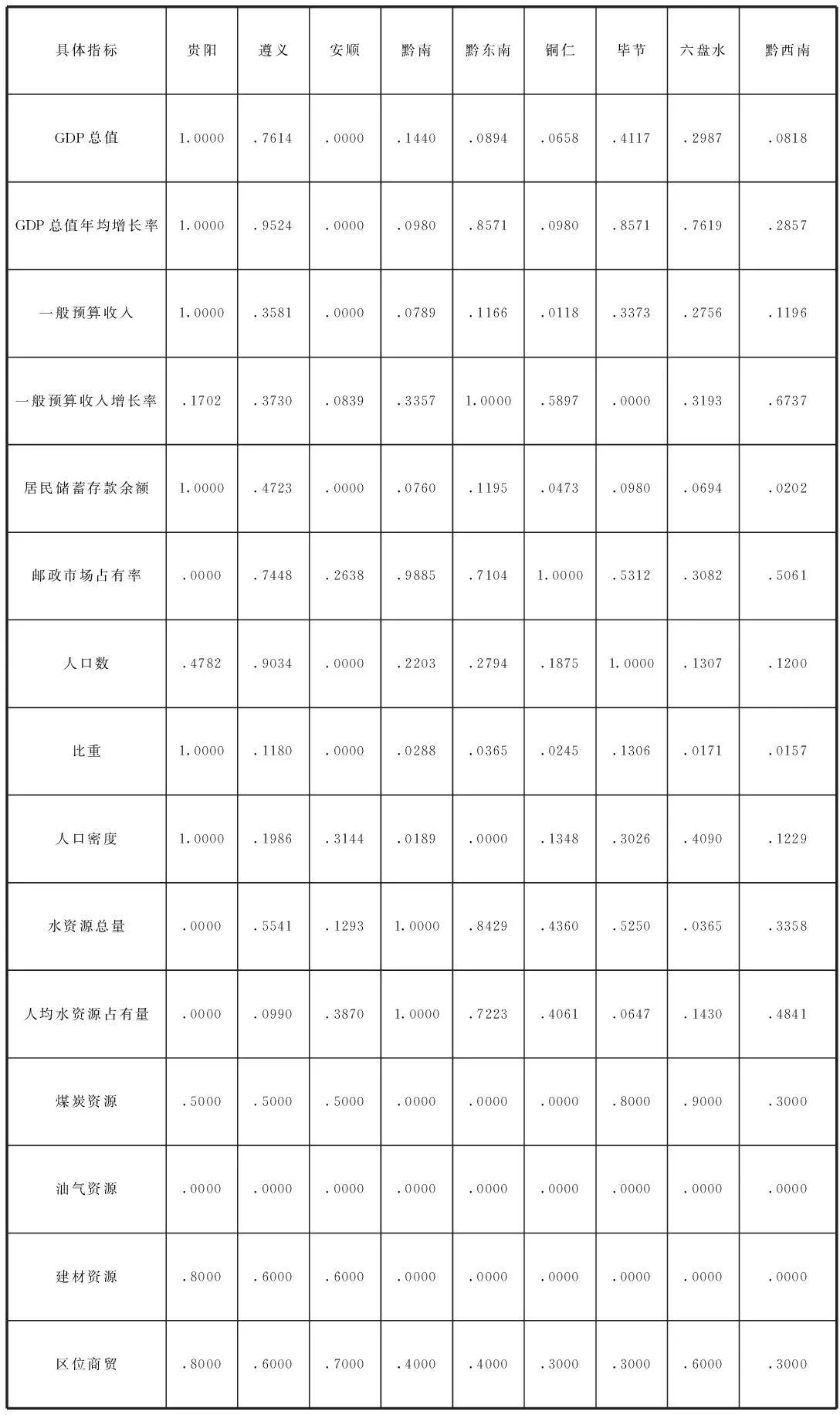
表3 贵州省各州市的9个地区经济区的聚类分析数据
说明:1.表中数据保留四位小叔;2.小数点前面的0省略。
3聚类分析
根据表3数据,利用统计分析软件SPSS对贵州省各州市的9个地区进行聚类分析,得出如下结果,包括表4、5、6和图1。
3.1解析表1
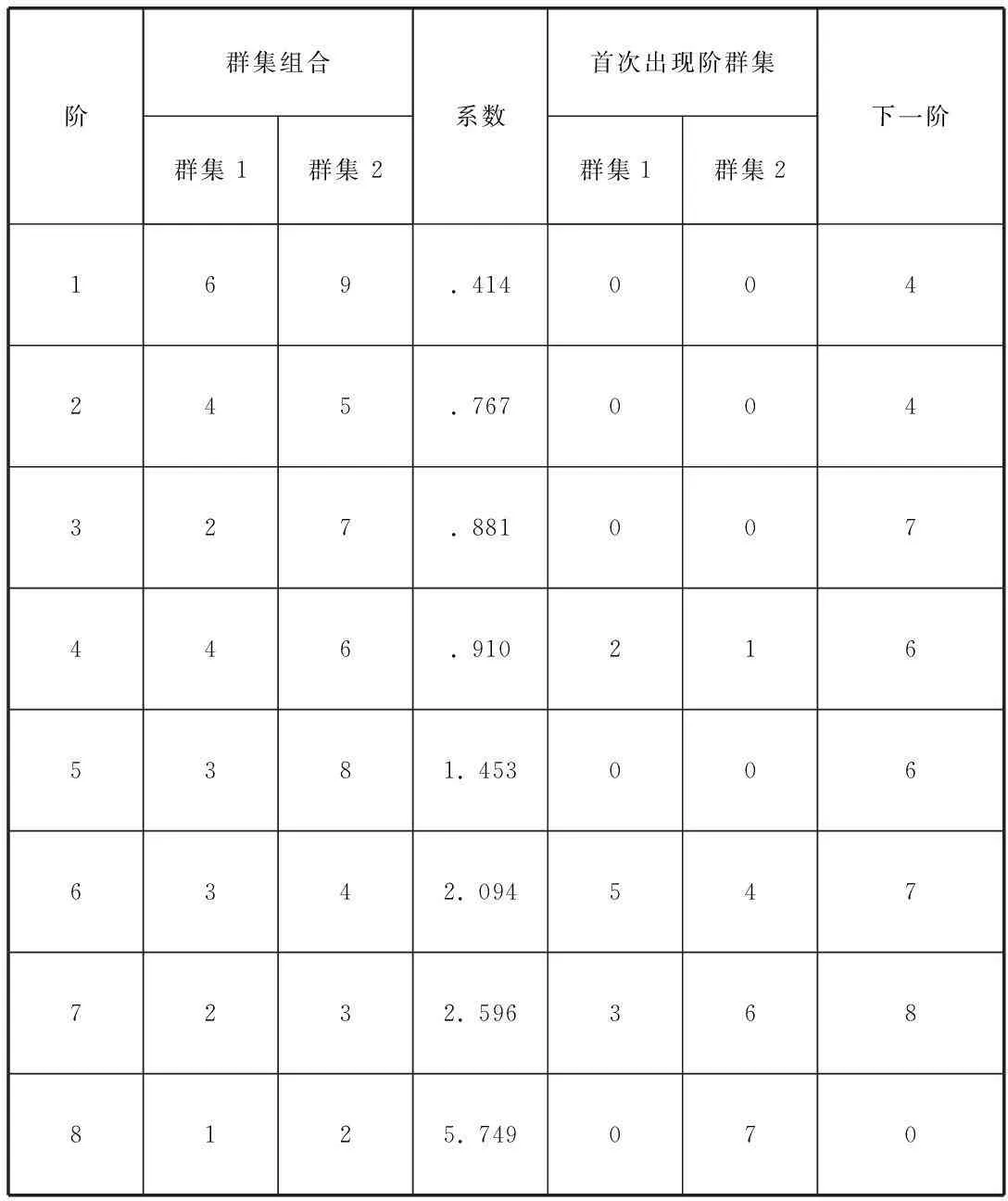
表4 聚类分析聚结表
说明:合并前的个案从1-9依次表示贵阳、遵义、安顺、黔南、黔东南、铜仁、毕节、六盘水、黔西南
3.1.1聚类步骤。从1-9表示聚类的先后顺序。
3.1.2个案合并。表示在某步中合并的个案,如第一步中个案6铜仁和个案9黔西南合并,合并以后用第一项的个案号表示生成的新类。
3.1.3相似系数。根据聚类分析的基本原理,个案之间亲密程度最高即相似系数最接近1的,最先合并。因此该列中的系数与第一列的聚类步骤相对应,系数值从小到大排列。
3.1.4新类首次出现的步骤。对应于各聚类步骤参与合并的两项中,如果有一个是新生的类,则在对应列中显示出该新类在哪一步第一次生成。如第四步中该栏第一列显示值为2,表示进行合并的两项中第一项是在第二步第一次生成的新类。如果值为0,则表示对应项还是个案。
3.2解析表2
表5聚类分析水平冰柱图表

表4中,如果个案或新类在第n步合并,则表5中倒数第n步及以前合并项对应行之间的行中用X充填,没有空格。例如表4中第一步为个案6和个案9合并,则表5中对应于第8步,个案6和个案9对应的行之间在第8步及以前用X充填。表4中第二步为个案4和个案5合并,则表5中对应于第7步,这两个个案对应的行之间在第7步及以前用X充填。如此继续下去,直至所有个案在最后一步聚为一类。
3.3解析图1
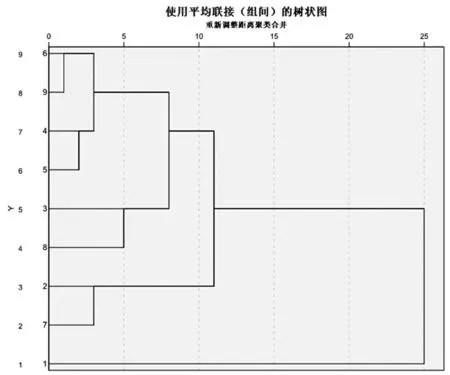
图1 贵州地区9市经济区域划分聚类树状图
图1 清晰地表示了聚类的全过程。它将实际距离按比例0-25的范围内,用逐级连线的方式连结性质相近的个案或新类,直至并为一类(张文彤,2002)。在该图上部的距离标尺上根据需要选定一个划分类的距离值,然后垂直标尺划线,该垂线将于水平连线相交,则相交的交点数即为分类的类别数,相交水平连线所对应的个案聚成一类。例如,选标尺值为10,则所有个案分为4类,即铜仁、黔西南、黔南、黔东南为一类,安顺和六盘水为一类,遵义和毕节为一类,贵阳为一类。若选标尺值为20,则聚为两类,贵阳为一类,其余为一类。
4结论
对贵州各市州进行经济区划分,究竟化为几个区合适,既不是越多越好,也不是越少越好,划分经济区的目的,就是要根据经济区特点的不同,分类指导经济活动,使人们的经济活动更加符合当地的实际,使各经济区能充分发挥各自自然、经济、社会等方面的优势,做到扬长避短,趋利避害,达到投入少、产出多,创造良好的经济效益和社会效益的目的,分区太多,就失去了分区的意义,分区太少,则分类指导很难做到有的放矢。综合,我认为分为四类比较合适。
从聚类分析中看出,铜仁和黔西南相似系数最大,最早聚合,明显是一类,遵义和毕节相似系数较大,划为一类;安顺和六盘水归为一类,黔南和黔东南地理位置就靠近,相似系数较大,作为一类,铜仁和黔西南聚为一类后又与黔南黔东南聚为一类的新类再聚为一类,9个市中,贵阳最为特殊,从经济发展水平、发展速度、产业结构等各方面都与其他市区别很大,难以成为一类。因此,我们单独把贵阳化为一类。根据以上的分析,把贵州省9个市州的经济区划分概括成表6。

表6 贵州省经济区划分
参考文献:
[1]苏金明,傅荣华,周建斌,张莲花.统计软件SPSS for Windows 实用指南[M].武汉;电子工业出版社,2000.
[2]贵州省统计局.贵州统计年鉴[M].北京:中国统计出版社,2011.
[3]张苏江,许宗运.数据统计分析软件SPSS的应用.畜牧和兽医,2003(10):47-51.
[4]张文彤.SPSS11统计分析教程[M].北京:北京希望电子出版社,2002.
SPSS cluster analysis application in economic geography
丁磊1,冯小康2
(1.贵州师范大学喀斯特研究院,贵州 贵阳 550001;2.苏州国环环境检测有限公司,江苏 苏州 215100)
摘要:对贵州省各市州进行经济地理分区,首先建立分类指标体系,然后查得或计算出有关数字并进行正规化转化,最后利用SPSS进行聚类分析得出结论。
关键词:贵州省;分类指标体系;SPSS;经济区
Abstract:Secri the province by the economic geography partition, classification index system first, and then Chad or calculate the relevant Numbers and regularized transformation, finally using SPSS clustering analysis conclusion.
Key words:Guizhou province; Classification index system; SPSS; Economic zone
中图分类号:K902
文献标志码:A
文章编号:1671-1602(2016)08-0077-03
作者简介:丁磊(1991-),男,江苏南京人。硕士,主要从事喀斯特生态建设与区域经济的研究。冯小康(1991-),男,江苏泰州人,硕士,主要从事环境工程的研究。
猜你喜欢
贵州畜牧兽医(2022年6期)2022-12-29 03:17:48
自然资源情报(2018年8期)2018-12-28 00:53:56
领导决策信息(2017年17期)2017-06-21 09:51:17
天水师范学院学报(2015年3期)2015-12-30 06:57:32
中国-东盟博览(政经版)(2015年7期)2015-08-07 14:27:36
中国交通信息化(2015年11期)2015-06-06 06:51:36
中国工程咨询(2015年5期)2015-02-16 05:35:16
