
基于PTLD的长时间视频跟踪算法
2016-05-11 02:14刘建郝矿荣丁永生杨诗宇东华大学信息科学与技术学院上海060数字化纺织服装技术教育部工程研究中心上海060
化工学报 2016年3期
刘建,郝矿荣,,丁永生,,杨诗宇(东华大学信息科学与技术学院, 上海 060;数字化纺织服装技术教育部工程研究中心,上海 060)
基于PTLD的长时间视频跟踪算法
刘建1,郝矿荣1,2,丁永生1,2,杨诗宇1
(1东华大学信息科学与技术学院, 上海 201620;2数字化纺织服装技术教育部工程研究中心,上海 201620)
摘要:对于化工厂、电厂等重要场所,火灾、爆炸和有毒物质泄漏等安全生产举足轻重。因此对工业现场的监控至关重要。作为一种有效实时的视频目标跟踪算法,TLD算法(tracking-learning-detection)吸引了全世界的广泛关注。提出了一种PTLD的改进算法(prediction-tracking-learning-detection)。它是通过将卡尔曼预测器用于估计目标的位置以降低探测器的扫描区域,提高检测速度;增加基于目标运动方向的预测用于跟踪目标与背景相似的情况。通过增加位置和速度的预测并使用时空分析有效提高视频跟踪精度和速度。实验结果表明,PTLD算法为鲁棒实时的视频跟踪提供了一种方向。
关键词:预测;模型;时空分析;实时跟踪
2016-01-03收到初稿,2016-01-10收到修改稿。
联系人:郝矿荣。第一作者:刘建(1986—),男,博士研究生。
引 言
为了现代化的大规模生产,化工厂需要投入巨大的能源。带来的后果是生产过程中经常发生火灾、爆炸、有毒物质泄漏等危险事故。远程视频监控是在无人监控化工厂的必要手段。这些都需要视觉跟踪技术。在未知环境中的长时间视觉跟踪是一个非常具有挑战性的难题:可能无限长的视频序列,运动目标的快速移动,跟踪目标出现各种形变,跟踪目标被短时间或长时间遮挡等。在这样的环境中,就需要一个鲁棒的跟踪算法以应对上述几种特殊的难题。
现有提出的视觉跟踪方法,如粒子滤波(particle filter)算法和均值偏移(mean-shift)算法,完成视频跟踪需要假定目标没有完全遮挡或消失[1-3]。这些方法的研究侧重于提高速度和精度以延长跟踪器的跟踪时间。但它们不解决跟踪失败后的行为,因此不能直接使用在长期跟踪问题。检测过程和跟踪过程是视觉跟踪中最重要的步骤。在最早的视频跟踪算法中,检测过程和跟踪过程是独立的,或是只通过检测算法跟踪目标,或是只通过跟踪算法对目标进行跟踪。例如先跟踪后检测算法(track-before-detect)和利用检测的跟踪算法(tracking-by-detection)。可以称这两种算法为TBD算法。TBD算法在计算量和算法复杂性方面是比较简单的,但是却只能被称作短期跟踪算法。因为它在跟踪模块失败时才进行全屏的检测。长时间视觉跟踪问题的优势就是提升它的一些检测能力,它的检测模块是一直工作而不仅是在跟踪失败后[4]。利用检测的跟踪方法是集成一个跟踪器和一个检测器,用于解决上述问题[5]。但是这种方法严格分开训练阶段和测试阶段。这意味着训练集从来没有表示外观变化而成为模型的一部分。 2012年Kalal[6]提出了TLD算法,即把长时间跟踪任务分为3个子任务:跟踪、学习和检测。每个子任务是由一个单一的模块处理。跟踪模块利用帧与帧的跟踪对象的漂移,检测模块是把目标与模型库中的模板进行匹配识别,学习模块是更新模板库中模板。这种算法的优点是:①3个模块相互协作,同时工作,而不是跟踪失败时才启动检测模块,而且PN学习模块使检测模块和跟踪模块更加鲁棒;②分类器和目标模型库实时更新,从而使长期实时跟踪成为可能。
上述提出的算法表现出的某些方面的不足和缺陷需要解决:①因为长时间的遮挡而丢失跟踪目标或跟踪错误的目标。②由于跟踪目标是移动的,多个跟踪目标相互重叠。③跟踪目标快速移动。 ④跟踪目标和背景过于类似,如图1所示。

图1 跟踪失败示例Fig.1 Tracking failure
本文提出在TLD算法基础上添加预测模块的PTLD算法。改进的部分包括采用Kalman预测器用于估计目标的位置以降低探测器的扫描区域,提高检测速度;增加基于目标运动方向的预测以应用于跟踪目标与背景相似的情况。通过增加的位置和速度的预测并使用时空分析有效提高视频跟踪精度和速度。
1 TLD算法
TLD算法[3]的设计用于未知目标的长期视频跟踪。其框图如图2所示。跟踪算法的实现是利用连续帧之间对象的运动。但是为了成功跟踪到目标,需要假设帧与帧之间的运动是有限的,而且跟踪目标必须是可见的。当跟踪对象移动出摄像机视域,跟踪器很可能失败并且无法恢复。检测器独立地对每一帧图像进行整幅图像的扫描,利用模板库中的模型定位跟踪目标的位置。与其他检测器不同的是,TLD检测器有两种类型的检测样本:假阳性和假阴性。学习模块的功能是:观察跟踪器和检测器的性能,估计误差检测器,并产生训练样本,以避免在将来重复同样的错误。学习模块可以允许跟踪器和检测器失败。利用学习模块,检测器可以成功检测到更多的物体外观模型和相类似的背景模型。
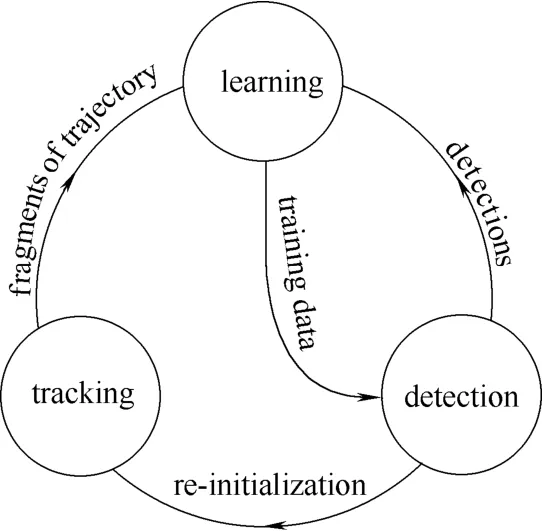
图2 TLD算法Fig.2 Block diagram of TLD framework
TLD算法的目标是利用实时视频处理算法提高目标检测器的性能。对于视频的每一帧,希望评估目前的探测器、识别错误并更新模板库使它在未来避免这些错误。P-N学习的关键思想是探测器的错误可以被两种类型的“专家”标示,P-expert只标识假阴性, N-expert只识别假阳性。由两种类型专家独立地检测错误。且其独立性能相互补偿自己的欠缺部分。
同时,TLD算法有明显的不足应该解决:①因为长期的遮挡而丢失跟踪目标或跟踪错误的目标;②由于目标的运动,多个移动目标互相重叠;③对象快速行动;④目标和背景太相似。
2 卡尔曼预测位置信息
使用卡尔曼滤波器来估计当前帧位置的中心目标,并确定TLD在当前帧的目标探测区域[7]。卡尔曼滤波是一种动态系统状态序列的线性最小均方误差估计算法。通过系统之前的状态序列预估下一个状态的最优估计,使用的当前状态测量值修正估计。卡尔曼滤波的数学模型描述为:状态方程

观测方程

式中,xk为k时刻的系统状态向量,zk为k时刻的系统观测向量,A为系统状态转移矩阵,H为观测矩阵,wk1−和vk是两个相互独立的零均值高斯白噪声,分别表示状态转移噪声和观测噪声。
选取每帧图像中目标的中心位置信息来构建滤波器中的状态变量和观测值,即:
状态变量
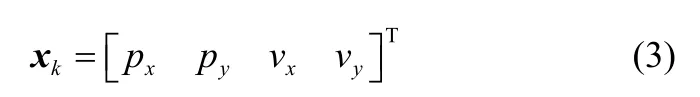
观测变量

式中,px和py分别代表目标中心在水平方向和竖直方向上的坐标分量,Vx和Vy分别表示目标在水平方向和竖直方向上的速度。在实际视频序列中,相邻两帧间的时间间隔很短,可以认为目标在相邻两帧间做匀速运动,系统为线性模型。
2.1 对跟踪模块的卡尔曼预测
将卡尔曼滤波器应用到视频跟踪需要3个重要的假设:①建模系统是线性的;②预测和测量噪声是白噪声;③噪声是高斯分布。第1个假设是k时刻的系统状态等于k1−时刻的状态和参数矩阵的乘积[8-9]。第2个和第3个假设是噪音与时间无关,只有振幅均值和协方差有关。基于卡尔曼滤波器的3个假设,要求系统必须是线性的。在实时跟踪时,由于相邻两帧的时间间隔很小(约10 ms),故相邻几帧的目标运动可以近似认为是线性的。因此,使用卡尔曼滤波器来提高跟踪的TLD算法性能是可行的。本文在检测模块、跟踪模块和学习模块的基础上添加了预测模块,其流程如图3所示。
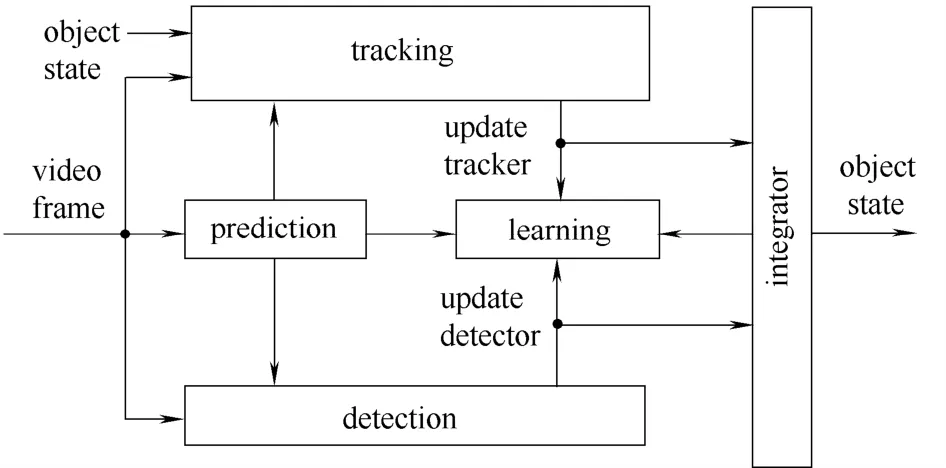
图3 PTLD算法流程Fig.3 Block diagram of PTLD framework
该算法的主要思想如下:首先,在系统初始化时,中心边界框的起始点提供pt-current和pt-predict,并作为滤波器系统的状态初始测量和预测。利用最初的卡尔曼滤波器的这两个起始点去跟踪每一帧,可以预测pt-predict给出的系统状态的时间。同时,中值流跟踪已确定目标的位置中心的边界框位置并提供pt-current。使用新的系统状态预测和后一个新系统卡尔曼滤波状态正确地测量。通过卡尔曼滤波器预测目标边界框中心点,然后使用跟踪框的宽度和高度恢复跟踪目标边界框。
在更新pt-current之前对每一帧的处理是在一个新的系统状态测量之前,利用旧系统状态的记录pt-last进行测量。目的是获得两帧之间的目标位移更新系统状态预测方程中的卡尔曼滤波参数矩阵F。
每一帧的目标是预测下一帧的边界框位置。为了得到这个结果,必须计算分类可信度,即计算结果和最近邻分类器也是相似的。如果可信度大于0.85(实验验证所得),即确定这个边界框为最精确的边界框。用其替换中值流的结果并将结果传递给后续的检测模块和学习模块。相反,如果实验可信度小于0.6,将使用中值流跟踪结果初始化状态测量系统和系统状态预测对卡尔曼滤波器进行初始化。
尽可能地拟合非线性系统,每一个特定的框架,系统状态测量和预测将被初始化,流程如图4所示。
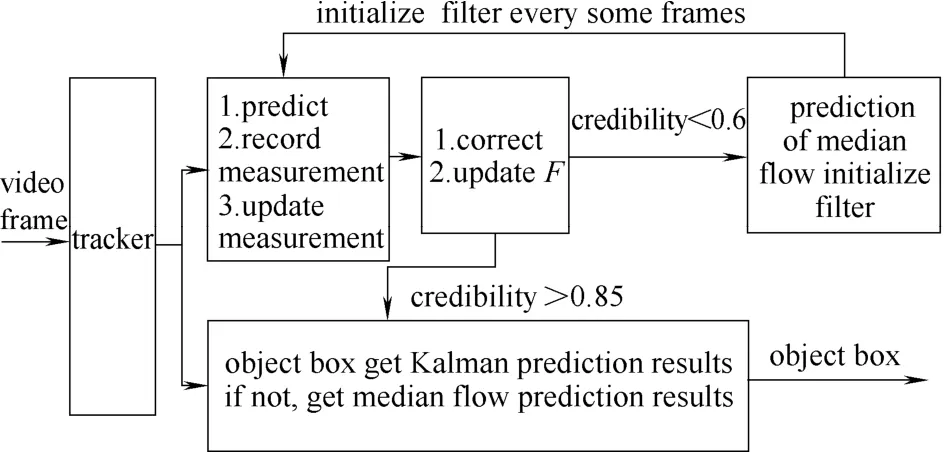
图4 基于卡尔曼预测的目标检测模块Fig.4 Object detect module based on Kalman prediction
2.2 分析测试仪器
检测器是基于TLD算法的窗口扫描。探测器需要扫描每个可能包含目标的图像子窗口来确定图像窗口中的对象是否为跟踪目标。因为TLD算法可以设置子窗口的大小却不能设置子窗口的位置,所以子窗口的数量需要检测。例如一幅470×310像素的图像,TLD算法可能需要检测大约30000子窗口。大多数的子窗口不包含跟踪目标造成了极大的资源浪费。因此,利用卡尔曼滤波器预测可以缩小目标的检测区域。具体方法如下:
(1)卡尔曼滤波器估计当前帧目标的中心;
(2)在中心位置画一个矩形区域,其长宽比与跟踪框的长宽比保持一致,将当前帧中的矩形区域作为待检测区域(如图5中黑色矩形框);
(3)找出所有的指定矩形区域的所有重叠子窗口,将它变成检测器,检测器子窗口的对象有可能就是目标。
图5显示了使用卡尔曼滤波器来缩小检测区域。在图中,矩形框由卡尔曼滤波器估计,结合目标框架的大小和位置信息给出当前帧的大致区域。图5显示了A、B、C 3个子窗口。两个子窗口与矩形框都与重叠区域的矩形框有交叠,因此A和B被保留到检测器测试,而子窗口C与预测目标区域不重叠,将不再被检测。

图5 检测重叠区域的子窗口Fig.5 Detecting child windows in intersection area
3 目标被遮挡时的预测
跟踪目标可以由目标对象及其周围背景信息来确定(见图6矩形内红色标记)。外界环境保持不变时两个连续帧之间的变化可以认为是光滑的,即时间间隔通常很小。因此,连续帧中包含跟踪对象局部区域存在一个强大的时空关系。例如,图6中的目标遮挡使对象出现显著变化。然而,包含对象的局部情况不会改变整体外观。这些连续帧短暂的邻近信息可以应用到视频检测[10-12]。此外,对象之间的空间关系和其本地位置的上下文信息提供了某些场景的特殊信息。

图6 预测方向演示Fig.6 Predict for orientation
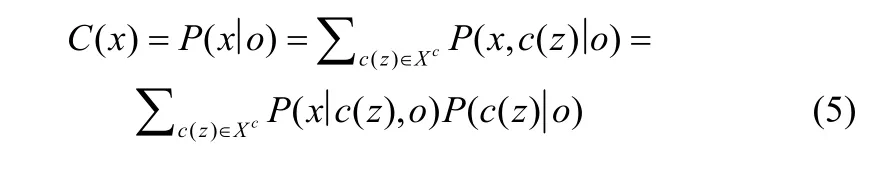
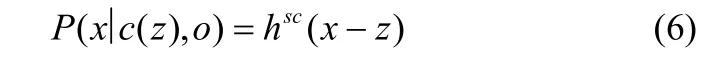
4 实验结果与讨论
实验是基于一些公开视频测试库验证完成[13-18]。利用5个视频序列评估所提出的PTLD算法在特殊环境下的跟踪情况,例如跟踪目标长时间遮挡、计算时间太长、跟踪目标快速地移动、亮度信息发生较大变化和跟踪对象突变等。在第一帧初始化跟踪目标,找到感兴趣的跟踪目标。跟踪框的性能评估由平均百分比确定,而后者是按照边界框之间的重叠和真实的边界框至少50%计算[19]。
图7实验跟踪目标是篮球运动员。普通的TLD在一开始可以跟踪目标,但其良好的性能不会持续很长时间。如在29帧,跟踪性能就出现恶化,即黄色矩形框逐渐出现偏差。尽管TLD算法可以在一段时间后进行修正,但常规的偏差可能导致错误的跟踪。PTLD算法可以预测下一帧与前一帧的中心位置并完成修改跟踪偏差。根据中央位置的预测模块,可以检测图像框在中心位置,而不是所有的屏幕的子图像。从而也减少检测时间。

图7 传统TLD算和PLTD跟踪篮球运动员第29帧结果Fig.7 Results from TLD and PLTD algorithms tracking basketball player in 29 frame
图8实验的跟踪目标是快速变向的小球。乒乓球从上向下降落到桌面之后迅速反弹。普通的TLD算法会在第30帧跟踪失败,但PLTD算法可以成功地跟踪,如图8(b)所示。最后的跟踪结果是跟踪模块和检测模块的结合所得。最初的TLD算法的跟踪模块的权重高于检测模块的权重,很容易丢失跟踪目标[20]。
图9实验的跟踪目标是与背景有相似性的篮球。在第198帧,普通的TLD算法跟踪目标变成篮球筐,从而后面的所有帧都是一致跟踪篮球筐。通过添加预测模块, PTLD算法提高了检测速度,所增加的检测模块提高跟踪效果并减少跟踪错误。即使PTLD算法也在第201帧跟踪失败,但第214帧又重新跟踪到正确的目标,如图9(b)所示。

图8 传统TLD算和PLTD跟踪小球第30帧结果Fig.8 Results from TLD and PLTD algorithms tracking ball in 30 frame

图9 传统TLD算和PTLD跟踪篮球结果Fig.9 Results from TLD and PLTD tracking basketball
图10实验的跟踪目标是摩托车。由于现实生活的跟踪目标的运动肯定是一个光滑的运动[21]。因为从前一帧到下一帧只有10 ms,目标在视频序列中的平移是平滑的,而不会出现瞬间移动。但是普通的TLD算法会出现瞬间移动,如图10(a)所示。在26帧之前,跟踪目标一直是摩托车。但是在第26帧跟踪对象瞬间变成了旁边的石头,从而导致跟踪失败。PTLD算法利用优先检测来预测下一帧的位置。前一帧的位置和下一帧的位置,当像素,便认为跟踪失败,不再显示矩形框。这样做,可以减少帧的跟踪失败,也减少错误的样本添加到模板库的概率,如图10(b) 所示。

图10 传统TLD和PTLD跟踪摩托车第27帧结果Fig.10 Results from TLD and PLTD algorithms tracking motocross in 27 frame
图11实验的跟踪目标是篮球运动员。跟踪目标周围明显的亮度变化使得TLD算法不能继续跟踪篮球运动员[22]。但PTLD算法开始搜索找到周围位置能匹配的特征点。如图11(b)所示,通过检测运动员腿上的特征点,PTLD算法跟踪再次回到正确的跟踪目标。

图11 传统TLD算和PTLD跟踪篮球运动员第140帧结果Fig.11 Results from TLD and PLTD algorithms tracking basketball player in 140 frame
表1是关于视频跟踪的定量结果分析。本文的评估方法是计算篮球运动员、乒乓球、篮球、摩托车和人等5组实验的成功跟踪帧数。为了验证方法的有效性,添加与经典TLD算法的比较。
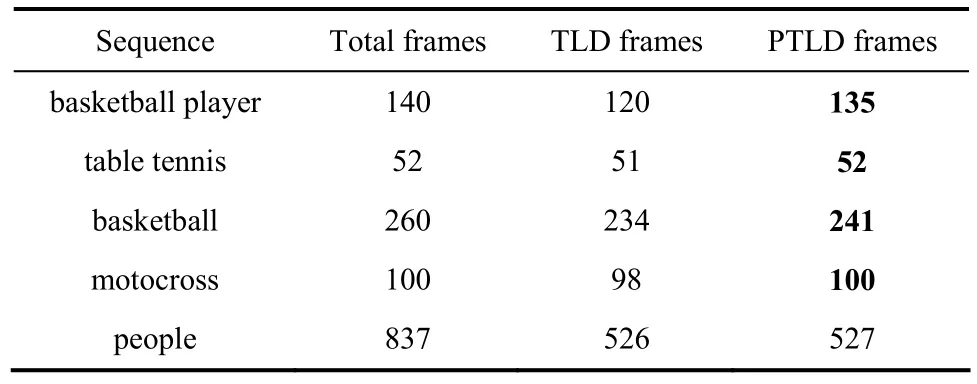
表1 成功跟踪帧数的数目Table 1 Number of successful tracking frames
5 结 论
为了实现化工厂、电厂等安全生产的监控,把视频目标跟踪应用到现实生活生产中。与传统的目标检测和视频跟踪问题不同,在实际应用中待跟踪目标和背景的表观特征经常会发生目标长时间遮挡、跟踪目标与背景相似、目标快速且剧烈的运动变化等情况。这些现象对跟踪算法的鲁棒性和快速适应能力提出了极高的要求。实验结果表明,所提出的PTLD算法提供了一种鲁棒的实时视觉跟踪系统。下一阶段计划添加颜色特征和纹理特征用于视频跟踪。此外,计划把单一摄像机跟踪目标扩展到摄像机网络进行更全面的跟踪。
References
[1] SUN X. Active-matting-based object tracking with color cues [J]. Signal Image and Video Processing, 2014, 8: 85-94.
[2] COMANICIU D. Mean shift: a robust approach toward feature space analysis [J]. Pattern Analysis and Machine Intelligence, 2002, 24 (5): 603-619.
[3] HAN H, DING Y S, HAO K R. An evolutionary particle filter with the immune genetic algorithm for intelligent video target tracking [J]. Computers and Mathematics with Applications, 2011, 62 (7): 2685-2695.
[4] HAN H, DING Y S, HAO K R. Particle filter for state estimation of jump Markov nonlinear system with application to multi-targets tracking [J]. International Journal of Systems Science, 2013, 44 (7): 1333-1343.
[5] KALAL Z. P-N learning: bootstrapping binary classifiers by structural constraints [C]//Proc. 23rd Intern. IEEE Computer Vision and Pattern Recognition. San Francisco, 2010.
[6] KALAL Z. Tracking-learning-detection [J]. The IEEE Pattern Analysis and Machine Intelligence, 2012, 34 (7): 1409-1422.
[7] ZHAO L Q, WANG J L, Y T. Nonlinear state estimation for fermentation process using cubature Kalman filter to incorporate delayed measurements [J]. Chinese Journal of Chemical Engineering, 2015, 23 (11): 1801-1810.
[8] LI L L, ZHOU D H, WANG Y Q, et al. Unknown input extended Kalman filter and applications in nonlinear fault diagnosis [J]. Chinese Journal of Chemical Engineering, 2005, 13 (6): 783-790.
[9] BERNARDIN K. Evaluating multiple object tracking performance: the CLEAR MOT metrics [J]. EURASIP Journal on Image and Video Processing, 2008: 1-10.
[10] GAO L. Communication mechanisms in ecological network-based grid middleware for service emergence [J]. Information Sciences, 2007, 177 (3): 722-733.
[11] GAO L. A web service trust evaluation model based on small-world networks [J]. Knowledge-Based Systems, 2014, 57: 146-162.
[12] GRAY D, BRENNAN S, TAO H. Evaluating appearance models for recognition, reacquisition, and tracking [C]//Proc. 11th Intern. IEEE Performance Evaluation of Tracking and Surveillance. Rio de Janeiro, 2007.
[13] JAVED O, SHAFIQUE K, RASHEED Z. Modeling inter-camera space time and appearance relationships for tracking across non-overlapping views [J]. Computer Vision and Image Understanding, 2008, 109 (2): 146-162.
[14] REDDY V, SANDERSON C, LOVELL B C. Improved foreground detection via block-based classifier cascade with probabilistic decision integration [J]. Circuits and Systems for Video Technology, 2013, 23 (1): 83-93.
[15] CHEN W, WANG X, WANG H, et al. A hybrid approach using map-based estimation and class-specific hough forest for pedestrian counting and detection [J]. IET Image Process, 2014, 8 (12): 771-781.
[16] MADDEN C, CHENG E D, PICCARDI M. Tracking people across disjoint camera views by an illumination-tolerant appearance representation [J]. Machine Vision and Applications, 2007, 18: 233-247.
[17] SHITRIT H B. Tracking multiple people under global appearance constraints [J]. Computer Vision, 2011: 137-144.
[18] POLIKAR R, DEPASQUALE J, SYED H. Learn++. MF: a randomsubspace approach for the missing feature problem [J]. Pattern Recognition, 2010, 43 (11): 3817-3832.
[19] BOUKHAROUBA K, BAKO L, LECOEUCHE S. Incremental and decremental multi-category classification by support vector machines [J]. Machine Learning and Applications, 2009: 294-300.
[20] KARAMI A H. Online adaptive motion model-based target tracking using local search algorithm [J]. Engineering Applications of Artificial Intelligence, 2014, 37: 307-318.
[21] GILBERT A, BOWDEN R. Incremental, scalable tracking of objects inter camera [J]. Computer Vision and Image Understanding, 2008, 111 (1): 43-58.
[22] YU Y, HARWOOD D. Human appearance modeling for matching across video sequences [J]. Machine Vision Applications, 2007, 18 (3): 139-149.
研究论文
Received date: 2016-01-03.
Foundation item: supported by the Key Project of the National Natural Science Foundation of China (61134009), the National Natural Science Foundation of China (61473077, 61473078, 61503075), the Cooperative Research Funds of the National Natural Science Funds Overseas and Hong Kong and Macao Scholars (61428302), the Program for Changjiang Scholars from the Ministry of Education, the Specialized Research Fund for Shanghai Leading Talents, the Project of the Shanghai Committee of Science and Technology (13JC1407500), the Innovation Program of Shanghai Municipal Education Commission (14ZZ067), Shanghai Pujiang Program (15PJ1400100) and the Fundamental Research Funds for the Central Universities (15D110423, 2232015D3-32).
Long-term visual tracking using PTLD algorithm
LIU Jian1, HAO Kuangrong1,2, DING Yongsheng1,2, YANG Shiyu1
(1College of Information Sciences and Technology, Donghua University, Shanghai 201620, China;2Engineering Research Center of Digitized Textile & Apparel Technology, Ministry of Education, Shanghai 201620, China)
Abstract:Along with such dangerous sources as big fire, explosion and toxic matter leak in the chemical plants,the visual tracking technology is a simple yet effective solution. As an effective real-time visual target tracking algorithm, the tracking-learning-detection (TLD) has drawn wide attention around the world. In this paper, we propose a prediction-tracking-learning-detection (PTLD) based visual target tracking algorithm, which is obtained by making several improvements based on the original TLD algorithm. The improvements include employing Kalman filter in the detector of TLD for estimating the location of the target to reduce the scanning region of the detector and improve the speed of the detector; adding Markov model based target moving direction predictor in the detector of TLD to increase the discretion for target with similar appearance. In addition to ascending in the tracking speed by increasing the position and speed prediction, we use the spatiotemporal analysis that also greatly
improves the tracking precision. Experimental results show that the proposed PTLD algorithm provides a means for robust real-time visual tracking.
Key words:prediction; model; algorithm; spatiotemporal analysis; real-time
DOI:10.11949/j.issn.0438-1157.20160001
中图分类号:O 235;TQ 086
文献标志码:A
文章编号:0438—1157(2016)03—0967—07
基金项目:国家自然科学基金重点项目(61134009);国家自然科学基金项目(61473077,61473078,61503075);国家自然科学基金海外及港澳学者合作研究基金项目(61428302);教育部长江学者奖励计划项目;上海领军人才专项资金;上海市科学技术委员会重点基础研究项目(13JC1407500);上海市教育委员会科研创新项目(14ZZ067);上海市浦江人才计划项目(15PJ1400100);中央高校基本科研业务费专项资金(15D110423,2232015D3-32)。
Corresponding author:Prof. HAO Kuangrong, krhao@dhu.edu.cn
猜你喜欢
黄河之声(2022年10期)2022-09-27
网络安全与数据管理(2022年1期)2022-08-29
导航定位学报(2022年4期)2022-08-15
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化(高中版.高考数学)(2020年12期)2021-01-13
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
数学物理学报(2020年2期)2020-06-02
