
Petri网在留学生汉语语音评价系统中的应用
2016-05-09 09:47陈展
现代语文 2016年3期
关键词:形式化

摘 要:本文介绍了Petri网在留学生汉语语音评价系统中的应用实例,提出了该系统的形式化的定义和语音评价过程的执行规则,结合汉语发音评价体系的特点,利用Petri网实现了留学生汉语语音评价的基本过程,降低了时间成本,提高了留学生汉语语音评价的效率。
关键词:Petri网 汉语语音评价 形式化 语音信号
一、引言
汉语发音在留学生汉语学习及交流中起着举足轻重的作用,语音评价是第二语言习得过程中的基础内容和重要环节,而汉语发音数据则是语音评价的主体和前提,是语音库的重要来源。如何对留学生的发音做出科学、有效的评价,一直是语音评价研究的热点。近年来,随着信息技术的不断发展,国内对汉语语音识别、语音评价系统做了大量研究,主要成果如下:袁毅、吴晨[1]提出了柔性可扩展体系结构非特定人语音识别系统的框架模型,验证了在该模型指导下所开发出的语音识别系统的实用性和稳定性;施伟[2]提出了对外汉语教学中的发音自动评价系统,通过分析输入语音数据,提取语音特征并与参考标准进行匹配比较,由评分机制根据相似程度大小给出相应的评价;潘志松等[3]提出了Petri网原理在语音识别中的基础应用方法,并以简单实例加以研证。
以上研究均采用了不用的技术和方法来实现汉语语音数据评价过程,产生了一系列的应用结果,取得了一些进步和成果。本文在前人研究的基础上,提出了一种用Petri网实现留学生汉语语音数据识别、评价及偏误分析的方法,大大降低了汉语语音数据评价成本,提高了评价过程的效率和留学生习得汉语语音的效率,使语音评价过程具有一定的兼容性、扩展性和适应性,符合当代汉语语音数据评价发展的特点及要求。
二、Petri网与留学生汉语语音评价体系
(一)Petri网简介
Petri网起源于1962年Carl Adam Petri的博士论文,它是一种可以用网状图形表示的系统模型,其概念是在尊重自然规律的前提下定义的,以确保以其为模型描述的系统都是可以实现的[4]。Petri网有丰富的系统描述手段和系统行为分析技术,最初主要应用于系统的建模、分布式系统的设计、并行处理等领域,经过50多年的研究发展,Petri网理论日益完善,被广泛应用于实现各类流程和系统行为过程问题。
按研究对象(过程),Petri网的模型可分为网、网系统、库所/变迁系统、高级网系统等模型系统,每类模型均有不同的层次结构。本文涉及到的是高级网系统中的有色自控系统[5],它的一个库所中可以包含多种资源(汉语语音信号),一个变迁代表一种流动关系,涵盖因资源差异而发生的不同变化和特征。
Petri网最基本的构成单元为:库所(Place)圆形节点(下文以S代替),变迁(Transition)方形节点(下文以P代替);有向弧(Connection)是库所和变迁之间的有向弧;托肯(Token)是库所中的动态对象(如为完成某个语音输入的识别或备份需要调用到的资源个数),可以从一个库所移动到另一个库所。Petri网的运行规则视具体情况而定,但基本规则是:有向弧是有方向的;两个库所或变迁之间不允许有库所;库所可以拥有任意数量的托肯。
(二)留学生汉语语音评价体系
留学生汉语语音评价体系[6][7]是根据留学生发音特征和汉语发音偏误建立的一个衡量和评价汉语语音习得程度和发音质量高低的智能化系统,使留学生能利用该系统对发音进行测评,该系统可在第一时间反馈汉语发音评价结果、错误类型和改进建议,能有效地提高留学生汉语发音的正确率,使其能更好地掌握汉语发音。
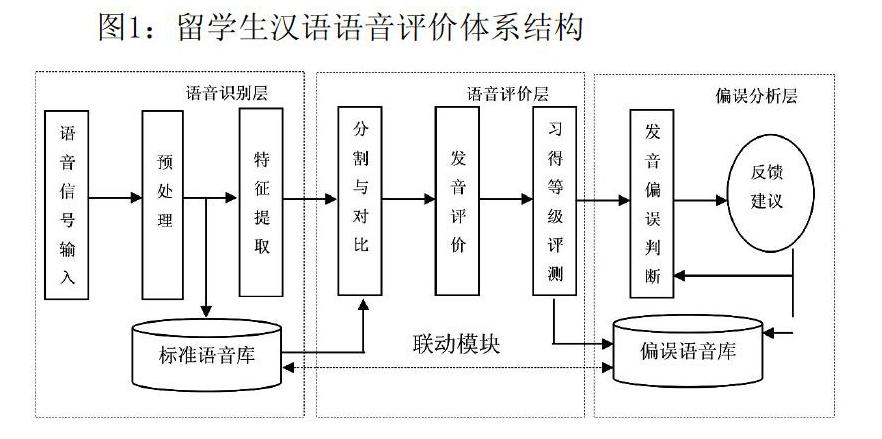
根据留学生汉语发音特点以及现有语音识别技术,汉语语音评价体系由语音识别层、语音评价层及偏误分析层三大功能模块构成,在每一个功能模块下又设有子模块,如图1所示。三个主要功能模块之间相互依存、相互影响和相互作用,通过联动和反馈机制不断地在其间传递语音及语音评价信息,构成了一个完备的汉语语音评价体系。
(三)评价测试
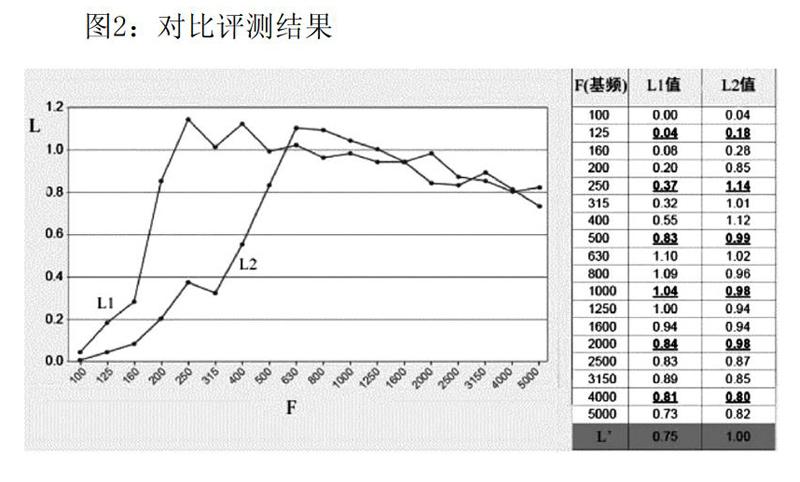
项目组利用矢量化编码VQF技术[8]进行汉语语音数据采集,通过对普通的汉语语音评价实现方案和基于Petri网的语音评价实现方案做出了测试和对比,结果如图2所示。
假设L为留学生汉语发音习得等级,它是一个五元组L=(L1,L2,L3,L4,H),其中:L1为元音习得等级,L2为辅音习得等级,L3为声调习得等级,L4为语调习得等级,H为权重因子[7],F为基频参数。L值越高,证明发音偏误率越低,发音更加接近标准,发音质量高;L值越低,证明发音偏误率越高,发音偏离标准,发音质量低。图2中L1为普通的汉语语音评价实现方案对应的语音评价等级,L2为利用Petri网实现方案对应的语音评价等级;右侧测试数据则为某个汉字发音单元(本研究仅限于单音节词)在两种方案下得出的等级值。由图可知,L2实现方案较为合理,大体上符合汉语发音规律,评价值接近预设的汉语发音习得等级值(L)。
(四)留学生汉语语音评价体系与Petri网的关系
从理论意义上讲,二者在形式上是一一对应的关系,只是涵盖的内容不同,Petri网及网系统发生记录也是语音评价体系的执行结果。经过以上测试可发现:以Petri网为工具能有效实现留学生汉语语音评价系统的模型化,以网络图形方式描述语音评价系统模块之间的关系和语音评价的全过程,从而使抽象的语音评价过程具体化。此外,Petri网语音执行记录还能有效地反馈发音偏误、缺陷和系统异常情况,有利于针对某一个(组)语音的分析和处理,为整个留学生汉语语音系统的运行提供有效的支持和保障。
三、Petri网在汉语语音识别系统中的应用
Petri网是研究和模拟汉语语音评价并行发生,依次发生和循环发生最理想的工具,与其他智能化系统一样,留学生汉语语音评价系统有一套完备的实现程序,系统中各模块间通过联动机制有机地联系在一起,这是利用Petri网对其形式化描述的物质基础。下面是一个用Petri网来描述留学生汉语语音评价系统中语音识别层的实例。
(一)图形化的汉语语音识别过程
语音识别层由语音信号输入模块、预处理模块、特征提取模块及标准语音数据库构成,如图1所示,当某个语音信号产生时,语音信号输入模块首先将语音转换为计算机能读取的数字信号,随后通过预处理模块分辨出语音信号及非语音信号。经预处理后的音频数据一方面会被传送到标准语音库进行备份,另一方面作为特征提取模块的输入数据。
将以上汉语语音识别过程以Petri网描述如下:
S1、S2、S3、S4为不同状态下的汉语语音信号;P1为语音识别功能模块,P2为预处理功能模块,P3为特征提取功能模块;s0为经预处理后的音频数据;p0为标准语音库和偏误语音库之间的联动功能模块。
图3是对一个典型的形式化的语音识别过程:汉语语音在处理过程中移动,每个处理环节再调用相关的函数及算法,直至语音识别过程结束。显然,语音处理环节对应着Petri网系统中的变迁元素“T”,而不同状态下的汉语语音数据则对应库所元素“S”。图3是整个汉语语音评价过程中截取出来的一个语音识别片段∑s,其中库所中的黑点个数代表该种语音识别资源的个数,箭头代表系统中资源流动的方向,弧上的数字代表语音处理需要调用到的资源的个数,也称为权值,没有数字的弧,其权值为1。例如,语音识别环节P1需要输入1个汉语语音,调用1个语音识别资源后完成识别,S2中语音资源个数显然少于预处理需要调用的资源总数,就上模型片段而言,不能继续进行语音数据的预处理,P2将等待系统具备充分的资源数后,方可执行。另一方面,s0中已经有足够资源对识别后的语音进行备份和比对,从而p0过程得以进行。
当语音识别系统中存在资源竞争时,经常出现以下情况:某个语音在识别后备份到标准语音库中,占用到一定的资源个数,与此同时,偏误分析功能模块也要调用标准语音库中的数据或资源进行比对,资源情况不满足既定操作,即语音识别层和偏误分析层在同时对标准语音库和偏误语音库中的资源进行调用时存在资源竞争现象,有向弧上的权值不允许操作继续,语音识别系统将会反馈异常处理记录,系统将重新分配现有资源,寻求其他途径解决冲突。
就汉语语音资源来说,存放它们的库所S(语音信号)具有语音库存贮数据的性质,它只能存放一定种类的语音资源,并且有一定的数量限制。但S和语音库又不完全一样,语音库在语音评价网系统中有固定的位置,而S在网中的位置毫无意义,不管它们处于何种位置,语音识别系统(网)的含义是不变的。
(二)基于Petri网的留学生汉语语音评价网系统
1.留学生汉语语音评价网系统的形式化定义
结合留学生汉语语音评价过程与Petri网中有色自控系统的特点和性质,可得出∑:
∑=(S,P;F,W,R)为留学生汉语语音评价网系统的条件是:
(1)(S,P;F)为有向网,它为∑的基本网;
(2)W:S×P∪P×S→{0,1,2…}∪S,且W(x,y)≠0,当且仅当(x,y)∈F,也成为∑的语音权函数;
(3)R:S→{0,1,2…}为∑的资源标记。
该定义假设每个语音信号(S)的容量为无穷(因为考虑到本文设计的语音评价系统对象是无穷尽的汉语语音数据,故做上述假设),有向弧的权值可以作为库所名,定义中(S;P;F)可映射到留学生汉语语音评价的各个环节。例如:W(x,y)=sn,则可从库所画一个以小圆圈为箭头的有向弧指向弧(x,y),如图3所示。
由于该网系统没有可变的权值,故设S={s0,s1,s2…sn},P={p0,p1,p2…pn},由∑的权函数W可产生模糊矩阵R,R的第i行第j列的矩阵元素即W(pj,si)-W(si,pj),可依此计算出所需资源标记(个数)。
2.留学生汉语语音评价网系统的运行规则
(1)映射R:S→{0,1,2…}为∑的资源标记;
(2)表示R下的权值函数Wr定义为:(x,y)∈S×P∪P×S;
若W(x,y)S,则Wr(x,y)=W(x,y);若W(x,y)=s′∧s′∈S,则Wr(x,y)=R(s′);
(3)变迁p∈P满足R的发生权,即R[p>的条件是:s∈S:R(s)≥Wr(s,p),且有s∈S,使Wr(s,p)>0,则p至少有一个输入权值;
(4)若R[p>,则p可以发生,后继标识R′(s)为R′(s)=R(s)+Wr(p,s)-Wr(s,p),有R[p>R
以上就是留学生汉语语音评价网系统的运行规则,权函数Wr随着标识R的改变而改变,体现了该系统的缺陷跟踪能力和语音修正能力。从严格意义上讲,“∑”只是语音评价系统中各子系统的总和,运行规则里也指出了“p”的输入弧上的权值必须大于0方可执行,以避免无中生有的变迁发生,如只要有语音信号,语音评价系统中有无语音数据都可完成语音评价,这种情况是不允许的。
根据定义和运行规则,可对照图3,∑s中语音识别过程P1、特征提取过程P3均可发生,假若S2(识别后的语音)中没有足够的托肯,预处理过程P2永远都不会发生,则语音评价系统中的语音输入识别功能无法完成,这也将造成之后语音评价系统功能的紊乱和终止。从另外一方面看,Wr函数体现了语音评价过程的自我修正和反馈意见功能,可针对因资源竞争,产生死锁而造成系统瘫痪、运行异常等情况做出反应,并重新配置语音处理资源,使系统在第一时间里回复正常运行,保证了该系统智能、稳定和高效的特点。
3.语音评价结果
本研究前期预测效果显著,项目组利用以上方法对测试汉语语音评价系统以来的所有汉语语音评价记录做了相关统计。抽样调查中,95%的留学生参与了语音评价的各个环节,语音评价系统成功识别汉语语音数据共计15891条(按单个音节计算),其中有效数据13936条,占87.69%。
在执行语音评价的指令中,同时执行多条语音处理指令称为指令并行。图4中的并行度是指在语音评价关系网中,指令并行执行的最大条数。经测算,该留学生汉语语音评价系统在完成所有语音处理指令和不出现异常的情况下,各模块语音指令总数为:分割与对比功能模块,124条;发音评价功能模块,298条;习得等级测评功能模块,21条;联动模块,9条。根据上表数据,可见本文设计的留学生汉语语音评价系统中的指令并行程度较高,大大提高了语音处理和评价的速度,降低了时间成本,有利于在同一时间处理和分析多条汉语语音数据。
4.语音数据的保存
为建立留学生汉语标准语音库和偏误语音库,为语音识别、对比研究奠定数据技术基础,为最大程度的保证语音评价的准确性和扩展性,应做好标准汉语语音的采集和偏误语音的收集。项目组在对产生的每一个汉语语音(或多个语音)评价结果后都要对其进行备存和入库管理,这是Petri网技术做不到的。
四、结语
人类处于一个信息技术迅猛发展的时代,语言学和计算机科学越来越紧密地结合在一起,这也是当今跨学科发展的必然结果。对于研究人员来说,留学生汉语语音评价是由一系列复杂的活动组成的,对其进行形式化的定义不仅需要将语言学和计算机技术基础理论和实践经验相结合,还需进行大量的测试和技术研发。本文介绍的基于Petri网的留学生汉语语音评价系统实现方法只是语音评价技术中的一种,以期能够给业内人士提供有效参考。
(本文是云南省社科规划办项目“基于东盟国家语言政策的云南汉语国际推广策略研究——以GMS五国为例”,[项目编号:KKSK201335026];云南省教育厅本科教学质量与教学改革工程项目“东南亚语种人才培养示范点”[项目编号:10968258]。)
参考文献:
[1]袁毅,吴晨.柔性可扩展体系结构非特定人语音识别系统[J].计算机应用研究,2006,(12):203-206.
[2]施伟,谢湘.一种基于语音识别的汉语发音评价系统[A].第七届中文信息处理国际会议[C].2007,32-36.
[3]潘志松,王全来,陈哲.Petri网理论及其在语音识别中的应用[J].电子技术学院学报,1998,(1):21-26.
[4]袁崇义.Petri网原理与应用[M].北京:电子工业出版社,2005:1-2.
[5]吴亚雄.基于高级Petri网的电网故障诊断[D].广州:华南理工大学硕士学位论文,2015,11-21.
[6]CHEN ZHAN,etc.A Study on the Architecture of Chinese Phonetic Evaluating System Based on the Chinese Pronunciation
of Thai Students[A].The 9th Cross-Strait Academic Conference.[C].2014,(10):528-529.
[7]陈展.基于老挝留学生发音特征的汉语语音评价体系研究[J].现代语文(语言研究版),2015,(3):81-82.
[8]陈展.基于微格矢量编码与缺陷跟踪的汉语语音数据采集研究[J].价值工程,2016,(1):149-151.
(陈展 云南昆明 昆明理工大学国际学院 650093)
猜你喜欢
课程教育研究·中(2016年12期)2017-02-27
课程教育研究·中(2016年12期)2017-02-27
课程教育研究·中(2016年12期)2017-02-27
东方教育(2016年6期)2017-01-16
