
藏文字符的向量模型及构件特征分析
2016-05-04 02:56才智杰才让卓玛
中文信息学报 2016年2期
才智杰, 才让卓玛,2
(1. 青海师范大学 藏文信息处理省部共建教育部重点实验室,青海 西宁 810008; 2. 陕西师范大学 计算机科学学院, 陕西 西安 710062)
藏文字符的向量模型及构件特征分析
才智杰1, 才让卓玛1,2
(1. 青海师范大学 藏文信息处理省部共建教育部重点实验室,青海 西宁 810008; 2. 陕西师范大学 计算机科学学院, 陕西 西安 710062)
藏文字属性分析是藏文信息处理的一项基础性工作,对藏文信息处理的研究和藏语文教学具有重要的参考价值及指导意义。藏文字是一种特殊的拼音文字,由1~7个基本构件横向和纵向拼接而成。因而藏文字符的属性包括其组成的构件及其构件的位置特征,以及藏文字的使用频度、结构、字长等属性特征。该文通过分析藏文字的结构,分别建立了藏文字及藏文字符串的向量模型VMTT、VMTS和藏文字符串的稀疏域模型SLM,并在向量模型和稀疏域模型上研究了藏文字符的构件特征。
中文信息处理;向量模型;稀疏域模型;构件
1 引言
藏文字创制至今进行了三次较大规模的厘定,制定了现代藏文文法,使藏语言文字步入了规范化的轨道[1-2]。符合现代藏文文法的藏文字称作现代藏文字(没有特殊说明时本文所提藏文字都指现代藏文字)。现代藏文字是由30个辅音字母和四个元音字母构成的拼音文字,结构上由基本辅音(基字)、前加字、上加字、下加字、后加字、再后加字及元音组成,其中前加字、基字、后加字与再后加字横向拼写,而在基字所在的竖直方向上还可能有上加字、基字、下加字和元音的纵向拼写[3-5]。因而藏文字的属性分析包括:(1)藏文字构件分解[6-7];(2)藏文字符串或藏文字所含构件数;(3)藏文字构件位置特征[8-9];(4)藏文字的使用频度、结构、字长等属性特征[10-12]。向量模型将文本信息转换成易于数学处理的向量方式[13],使得文本的各种运算和操作简化。本文通过分析藏文字的结构,建立了藏文字及字符串的向量模型和藏文字符串的稀疏域模型,在此基础上研究了藏文字符(藏文字及藏文字符串)所含构件数及构件位置特征。
2 藏文字符的向量模型及构件特征分析
2.1 藏文字的向量模型(VMTT)

定义1(藏文字的向量模型) 藏文字可用向量集A={ 2.2 藏文字符串的向量模型(VMTS)及构件特征分析 藏文字符串主要由藏文字和字分隔符组成,字分隔符是一个确定不变的符号“-”,只是用来分隔串中的字。字符串的所有藏文字都确定时,不需要存储分隔符,此时藏文字符串可以看作由若干个藏文字组成。藏文字的向量模型VMTT中每个藏文字对应一个含七个分量的一维向量,将字符串中的每个藏文字的一维向量作为列可得到藏文字符串向量模型。 (1) (2) 由定义2可知,藏文字符串的向量模型由行数、列数和元素值确定,因而将其数据结构定义为: TypedefStruct {intmu,nu; //描述向量的行数和列数 inta[M][N]; //描述向量中元素 }Matrix; 由此可得VMTS模型下藏文字符所含构件数及构件位置特征属性。 (1) 藏文字符串所含藏文字个数等于M.nu; (2) 藏文字符串中第j个字所含构件数等于第j列中非零元素的个数; (3) 藏文字符串所含构件总数等于其VMTS模型中非零元素个数,即 For(i=0;i For(j=0;j If(a[i][j]<>0)s++; (4) 构件位置特征可通过如下算法确定: Void VMTS - CPFA (Matrix M) {for(j=0;j {printf("
第%d个藏文字的",j+1); For(i=0;i If(M.a[i][j]!=0) Switch(i){ Case 0:printf("
前加字代号为:%d", M.a[i][j]);break; Case 1:printf("
上加字代号为:%d", M.a[i][j]);break; Case 2:printf("
基字代号为:%d", M.a[i][j]);break; Case 3:printf("
下加字代号为%d", M.a[i][j]);break; Case 4:printf("
元音代号为:%d", M.a[i][j]);break; Case 5:printf("
后加字代号为:%d", M.a[i][j]);break; Case 6:printf("
再后加字代号为:%d", M.a[i][j]);break;}} } 3.1 藏文字分布统计 一个完整的现代藏文字由1~7个构件组成,对1.5G藏语语料的构件分布情况进行统计得表1所示分布表。 表1 藏文字分布表 由表1可见,在藏字中含一个构件的藏文字占13.52%,含两个构件的藏文字占28.22%,含三个构件的藏文字占30.59%,含四个构件的藏文字占21.43%,含五个构件的藏文字占5.61%,含六个构件的藏文字占0.37%,含七个构件的藏文字占0.04%,说明藏文字符串中的大多数藏文字由2~4个构件组成[17]。因而用VMTS模型表示藏文字符串得到的是稀疏矩阵,显然直接用VMTS模型存储藏文字符串不但需较大的存储空间,而且算法时间复杂度也较大。如果只存储藏文字符向量模型VMTS中的非0元素,从而建立藏文字符的稀疏域模型Sparse-Land Model(SLM),不但可以压缩存储空间,还能提高算法效率。 3.2 藏文字符串的稀疏域模型(SLM)及构件特征分析 设矩阵Am×n中有s个非零元素,若s远远小于矩阵元素的总数(即s< Typedef Struct {inti,j;//分别描述非零元素的行号和列号 Eemtypee;//描述非零元素的值 }SLM;//三元组类型 Typedef Struct {SLM data[MAXSIZE];//三元组表 int mu,nu,tu;//稀疏矩阵的行数、列数和非零元个数 }TMatrix; 图1 SLM模型存储实例图 由此可得SLM模型下藏文字及字符串所含构件数及构件位置特征属性。 (1) 藏文字符串所含字的个数等于其对应SLM的列数,即藏文字的个数等于T.nu; (2) 藏文字符串的第i个字所含构件数等于所有T.data[0..T.nu-1].j=i的个数,即 for(k=0;k (3) 藏文字符串所含构件总数等于T.tu; (4) 构件位置特征可通过如下算法确定: Void SLM- CPFA (TMatrix T) {for(k=0;k Case 1:ptintf("前加字代号为:%d",T.data[k].e);break; Case 2:ptintf("上加字代号为:%d",T.data[k].e);break; Case 3:ptintf("基字代号为:%d",T.data[k].e);break; Case 4:ptintf("下加字代号为%d",T.data[k].e);break; Case 5:ptintf("元音代号为:%d",T.data[k].e);break; Case 6:ptintf("后加字代号为:%d",T.data[k].e);break; Case 7:ptintf("再后加字代号为:%d",T.data[k].e);break;}} } 算法VMTS-CPFA的时间复杂度为O(M.m×M.n),算法SLM- CPFA的时间复杂度为O(T.tu);用VMTS模型存储藏文字符串所用的空间规模为M.m×M.n,用SLM模型存储藏文字符串的空间规模为T.tu;T.tu << M.m×M.n,所以基于SLM的藏文字符属性分析性能比VMTS高。但在VMTS模型下分析藏文字符的属性比SLM模型简单。 本文对现代藏文字符存储结构进行了深入研究,提出了藏文字的向量存储模型(VMTT)及藏文字符的向量模型(VMTS)和稀疏域存储模型(SLM),并分别在VMTS模型和SLM模型下对藏文字符构件特征进行了分析。在VMTS模型下M.mu恒等于7,藏文字符串所含字个数等于其行数M.nu,串中第j个藏文字所含构件个数等于该列非零元素个数,串所含构件数等于向量模型中非零元素个数,构件位置特征由VMTS - CPFA算法确定;在SLM模型下mu恒等于7,藏文字符串所含字的个数等于其列数T.nu,串中第i个藏文字所含构件数等于所有T.data[0..T.nu-1].j=i的个数,藏文字符串所含构件总数等于T.tu,构件位置特征由SLM- CPFA算法确定。通过一系列的实验表明,藏文字符使用SLM存储模型不但节省空间开销,而且属性分析效率也很高,但在VMTS模型下研究藏文字属性非常简单。今后在该研究成果的基础上将进一步研究藏文字符稀疏域存储模型下藏文句型结构。 [1] 百度百科.藏文[EB/OL].http://baike.baidu.com/view/230052.htm,2013-01-12. [2] 才旦夏茸.藏文文法详解[M].西宁:青海民族出版社,1988. [3] 才智杰,才让卓玛.基于语料库的藏文字属性分析系统设计[J].计算机工程,2011,37(22):270-272. [4] 才智杰.藏文自动切分系统中紧缩词的识别[J].中文信息学报,2009,23(1):35-37. [5] 黄鹤鸣,契嘎·德熙嘉措(赵晨星).基于DUCET的藏文排序方法[J].中文信息学报,2008,22(4):109-113. [6] 才让卓玛,才智杰.藏文字频统计系统中字构件分解算法[J].计算机工程与科学,2011,33(3):159-162. [7] 才让卓玛,才智杰.现代藏文字构件分解方法[J].青海大学学报,2010,28(4):83-86. [8] CaiZhijie,CaiRangzhuoma.Statistical Analysis for Frequency of the Corpus-based Modern Tibetan Basic Components[C]//Proceedings of 2011 4th International Conference on Intelligent Networks and Intelligent Systems (ICINIS), Kunming, China, Nov. 1-3,2011: 214-217. [9] 陈玉忠,俞士汶.藏文信息处理的研究现状与展望[J].中国藏学,2003,(4):97-107. [10] 扎西次仁.《中华大藏经·丹珠尔》藏文对勘本字频统计分析[J].中国藏学,1997,(2):122-133. [11] 高定国,龚育昌.现代藏文字全集的属性统计研究[J].中文信息学报,2005,19(1):71-75. [12] 江荻,董颖红.藏文信息处理属性统计研究[J].中文信息学报,1994,2(9):37-44. [13] 张晓艳,王挺,陈火旺.基于多向量和实体模糊匹配的话题关联识别[J].中文信息学报,2008,22(1):9-14. [14] 林河水,程伟等.藏语的序性及排序方法[J].中文信息学报,2004,18(5):36-41. [15] 江荻等.书面藏语排序的数学模型及算法[J].计算机学报,2004,27(4):524-529. [16] 江荻,周季文.论藏文的序性及排序方法[J].中文信息学报,2000,14(1):56-64. [17] 才智杰,才让卓玛.班智达藏文标注词典设计[J].中文信息学报,2010,24(5):46-49. Vector Space Models and Component Features Analysis of Tibetan Characters CAI Zhi-jie1CAI rang-zhuoma1,2 (1. Key Laboratory of Tibetan Information Processing, Ministry of Education, Qinghai Normal University, Xining,Qinghai 810008,China; 2. School of Computer Science, Shaanxi Normal University, Xi’an, Shaanxi 710062, China) Tibetan characters property is essential for Tibetan information processing, and it is substantial significance in education and scientific research. Because Tibetan characters writing is directed by both horizontal and vertical 1-7 Tibetan characters, the properties of Tibetan characters include the structure, length, frequency of Tibetan characters and the locality features of each characters. This paper establishes vector model (VMTT) of Tibetan characters, vector model (VMTS) and sparse-land model (SLM) of Tibetan character string, and conducts the component feature analysis of Tibetan characters based on these models. Chinese information processing; vector space model; sparse-land model; components 才智杰(1970—),教授,博士,主要研究领域为藏文信息处理,藏语自然语言处理。E⁃mail:Czjqhsd@163.com才让卓玛(1970—),教授,博士,主要研究领域为自然语言处理,藏文信息处理。E⁃mail:cr⁃zhuoma@163.com 1003-0077(2016)02-0202-05 2013-10-21 定稿日期: 2014-04-14 国家自然科学基金(61163018, 61262051, 61363055);教育部“春晖计划”合作科研项目(Z2012093);国家社科基金(13BYY141);“长江学者和创新团队发展计划”创新团队资助项目(IRT1068);青海省科技厅应用基础研究计划基金(2011-Z-755,2011-Z-754);青海师范大学科研创新计划基金 TP A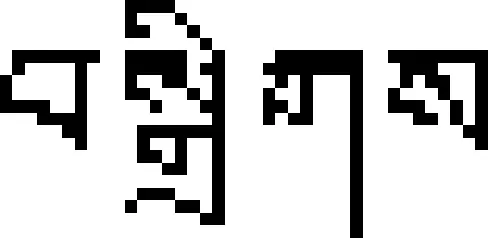
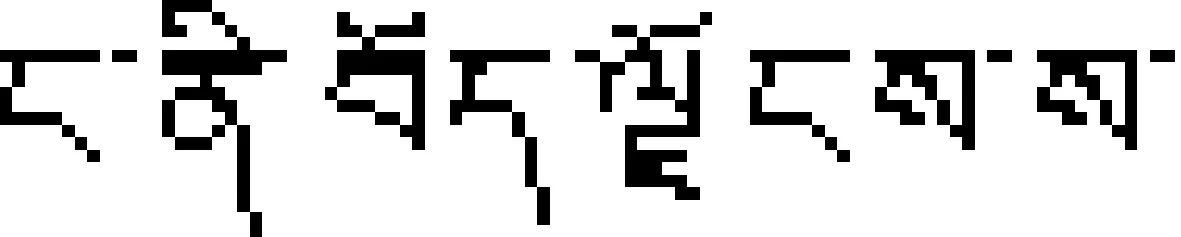

3 藏文字符串的稀疏域模型(SLM)及构件特征分析

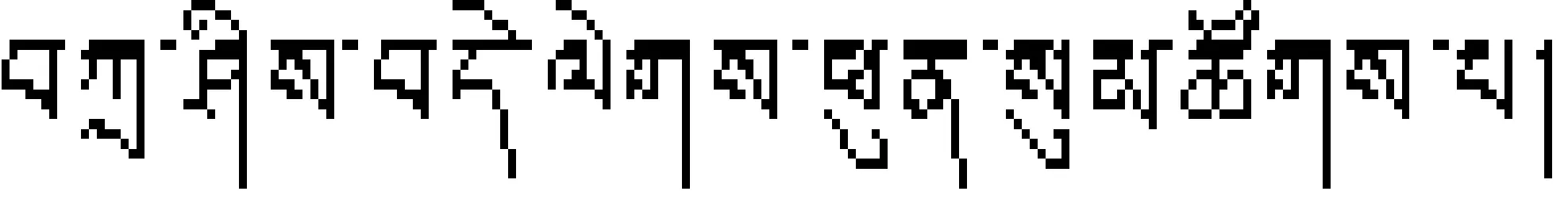
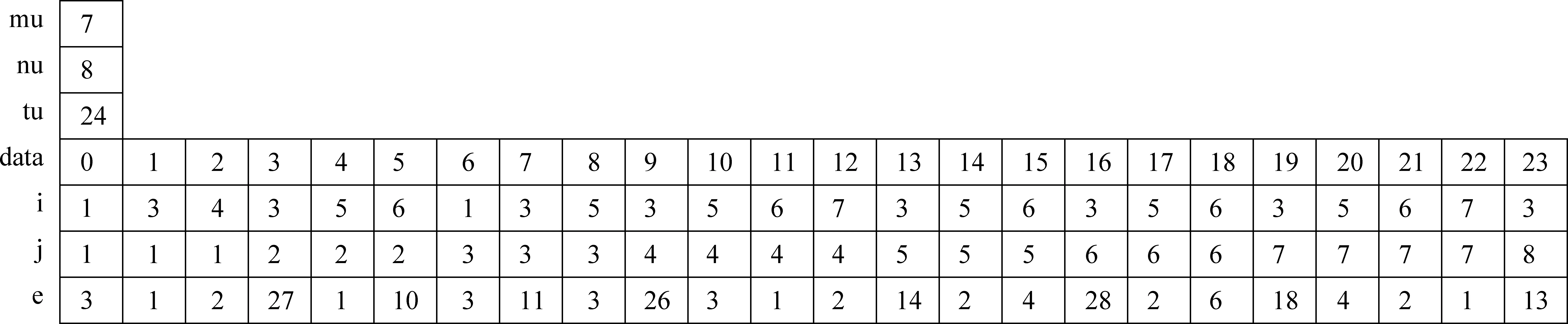

4 结束语
 猜你喜欢
西藏研究(2021年1期)2021-06-09无线互联科技(2020年11期)2020-12-01汉字汉语研究(2020年2期)2020-08-13布达拉(2020年3期)2020-04-13小学生学习指导(低年级)(2019年12期)2019-12-04电子制作(2019年19期)2019-11-23电脑爱好者(2019年8期)2019-10-30西夏学(2019年1期)2019-02-10中央民族大学学报(自然科学版)(2018年1期)2018-06-27科教导刊·电子版(2016年30期)2016-12-26
猜你喜欢
西藏研究(2021年1期)2021-06-09无线互联科技(2020年11期)2020-12-01汉字汉语研究(2020年2期)2020-08-13布达拉(2020年3期)2020-04-13小学生学习指导(低年级)(2019年12期)2019-12-04电子制作(2019年19期)2019-11-23电脑爱好者(2019年8期)2019-10-30西夏学(2019年1期)2019-02-10中央民族大学学报(自然科学版)(2018年1期)2018-06-27科教导刊·电子版(2016年30期)2016-12-26
